") 開(kāi)發(fā)或者運(yùn)維中的性能優(yōu)化建議
開(kāi)發(fā)或者運(yùn)維中的性能優(yōu)化建議

寫(xiě)到這里,本書(shū)已經(jīng)快接近尾聲了。在本書(shū)前面幾章的內(nèi)容里,我們深入地討論了很多內(nèi)核網(wǎng)絡(luò)模塊相關(guān)的問(wèn)題。正和庖丁一樣,從今日往后我們看到的也不再是整個(gè)的 Linux (整頭牛)了,而是內(nèi)核的內(nèi)部各個(gè)模塊(筋?肌理)。我們也理解了內(nèi)核各個(gè)模塊是如何有機(jī)協(xié)作來(lái)幫我們完成任務(wù)的。
那么具備了這些深刻的理解之后,我們?cè)谛阅芊矫嬗心男﹥?yōu)化手段可用呢?我在本章中給出一些開(kāi)發(fā)或者運(yùn)維中的性能優(yōu)化建議。注意,我用的字眼是建議,而不是原則之類(lèi)的。每一種性能優(yōu)化方法都有它適用或者不適用的應(yīng)用場(chǎng)景。你應(yīng)當(dāng)根據(jù)你當(dāng)前的項(xiàng)目現(xiàn)狀靈活來(lái)選擇用或者不用。
1 網(wǎng)絡(luò)請(qǐng)求優(yōu)化
建議1:盡量減少不必要的網(wǎng)絡(luò) IO
我要給出的第一個(gè)建議就是不必要用網(wǎng)絡(luò) IO 的盡量不用。
是的,網(wǎng)絡(luò)在現(xiàn)代的互聯(lián)網(wǎng)世界里承載了很重要的角色。用戶(hù)通過(guò)網(wǎng)絡(luò)請(qǐng)求線(xiàn)上服務(wù)、服務(wù)器通過(guò)網(wǎng)絡(luò)讀取數(shù)據(jù)庫(kù)中數(shù)據(jù),通過(guò)網(wǎng)絡(luò)構(gòu)建能力無(wú)比強(qiáng)大分布式系統(tǒng)。網(wǎng)絡(luò)很好,能降低模塊的開(kāi)發(fā)難度,也能用它搭建出更強(qiáng)大的系統(tǒng)。但是這不是你濫用它的理由!
我曾經(jīng)見(jiàn)過(guò)有的同學(xué)在自己開(kāi)發(fā)的接口里要請(qǐng)求幾個(gè)第三方的服務(wù)。這些服務(wù)提供了一個(gè) C 或者 Java 語(yǔ)言的SDK,說(shuō)是 SDK 其實(shí)就是簡(jiǎn)單的一次 UPD 或者 TCP 請(qǐng)求的封裝而已。這個(gè)同學(xué)呢,不熟悉 C 和 Java 語(yǔ)言的代碼,為了省事就直接在本機(jī)上把這些 SDK 部署上來(lái),然后自己再通過(guò)本機(jī)網(wǎng)絡(luò) IO 調(diào)用這些 SDK。我們接手這個(gè)項(xiàng)目以后,分析了一下這幾個(gè) SDK 的實(shí)現(xiàn),其實(shí)調(diào)用和協(xié)議解析都很簡(jiǎn)單。我們?cè)谧约旱姆?wù)進(jìn)程里實(shí)現(xiàn)了一遍,干掉了這些本機(jī)網(wǎng)絡(luò) IO 。效果是該項(xiàng)目 CPU 整體核數(shù)削減了 20 % +。另外除了性能以外,項(xiàng)目的部署難度,可維護(hù)性也都得到了極大的提升。
原因我們?cè)诒緯?shū)第 5 章的內(nèi)容里說(shuō)過(guò),即使是本機(jī)網(wǎng)絡(luò) IO 開(kāi)銷(xiāo)仍然是很大的。先說(shuō)發(fā)送一個(gè)網(wǎng)絡(luò)包,首先得從用戶(hù)態(tài)切換到內(nèi)核態(tài),花費(fèi)一次系統(tǒng)調(diào)用的開(kāi)銷(xiāo)。進(jìn)入到內(nèi)核以后,又得經(jīng)過(guò)冗長(zhǎng)的協(xié)議棧,這會(huì)花費(fèi)不少的 CPU周期,最后進(jìn)入環(huán)回設(shè)備的“驅(qū)動(dòng)程序”。接收端呢,軟中斷花費(fèi)不少的 CPU 周期又得經(jīng)過(guò)接收協(xié)議棧的處理,最后喚醒或者通知用戶(hù)進(jìn)程來(lái)處理。當(dāng)服務(wù)端處理完以后,還得把結(jié)果再發(fā)過(guò)來(lái)。又得來(lái)這么一遍,最后你的進(jìn)程才能收到結(jié)果。你說(shuō)麻煩不麻煩。另外還有個(gè)問(wèn)題就是多個(gè)進(jìn)程協(xié)作來(lái)完成一項(xiàng)工作就必然會(huì)引入更多的進(jìn)程上下文切
換開(kāi)銷(xiāo),這些開(kāi)銷(xiāo)從開(kāi)發(fā)視角來(lái)看,做的其實(shí)都是無(wú)用功。
上面我們還分析的只是本機(jī)網(wǎng)絡(luò) IO,如果是跨機(jī)器的還得會(huì)有雙方網(wǎng)卡的 DMA 拷貝過(guò)程,以及兩端之間的網(wǎng)絡(luò)RTT 耗時(shí)延遲。所以,網(wǎng)絡(luò)雖好,但也不能隨意濫用!
建議2:盡量合并網(wǎng)絡(luò)請(qǐng)求
在可能的情況下,盡可能地把多次的網(wǎng)絡(luò)請(qǐng)求合并到一次,這樣既節(jié)約了雙端的 CPU 開(kāi)銷(xiāo),也能降低多次 RTT 導(dǎo)致的耗時(shí)。
我們舉個(gè)實(shí)踐中的例子可能更好理解。假如有一個(gè) redis,里面存了每一個(gè) App 的信息(應(yīng)用名、包名、版本、截圖等等)。你現(xiàn)在需要根據(jù)用戶(hù)安裝應(yīng)用列表來(lái)查詢(xún)數(shù)據(jù)庫(kù)中有哪些應(yīng)用比用戶(hù)的版本更新,如果有則提醒用戶(hù)更新。
那么最好不要寫(xiě)出如下的代碼:
get(包名)...}
上面這段代碼功能上實(shí)現(xiàn)上沒(méi)問(wèn)題,問(wèn)題在于性能。據(jù)我們統(tǒng)計(jì)現(xiàn)代用戶(hù)平均安裝 App 的數(shù)量在 60 個(gè)左右。那這段代碼在運(yùn)行的時(shí)候,每當(dāng)用戶(hù)來(lái)請(qǐng)求一次,你的服務(wù)器就需要和 redis 進(jìn)行 60 次網(wǎng)絡(luò)請(qǐng)求。總耗時(shí)最少是 60個(gè) RTT 起。更好的方法是應(yīng)該使用 redis 中提供的批量獲取命令,如 hmget、pipeline等,經(jīng)過(guò)一次網(wǎng)絡(luò) IO 就獲取到所有想要的數(shù)據(jù),如圖 1.1。
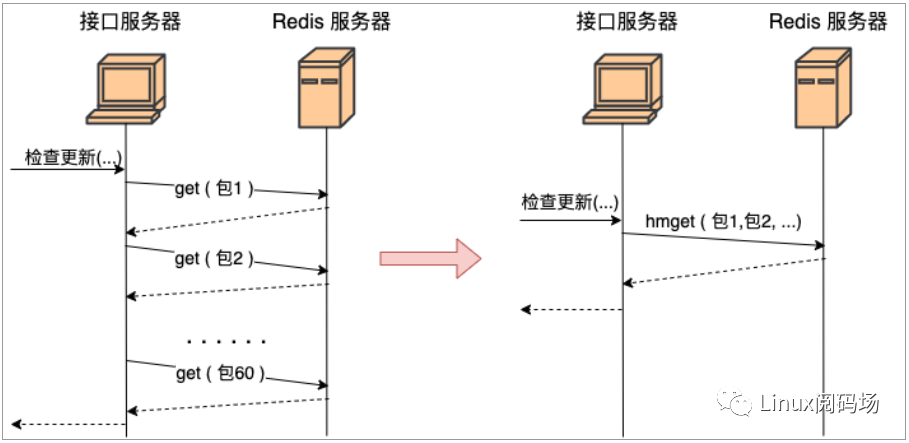
圖1.1 網(wǎng)絡(luò)請(qǐng)求合并
建議3:調(diào)用者與被調(diào)用機(jī)器盡可能部署的近一些
在前面的章節(jié)中我們看到在握手一切正常的情況下, TCP 握手的時(shí)間基本取決于兩臺(tái)機(jī)器之間的 RTT 耗時(shí)。雖然我們沒(méi)辦法徹底去掉這個(gè)耗時(shí),但是我們卻有辦法把 RTT 降低,那就是把客戶(hù)端和服務(wù)器放的足夠地近一些。盡量把每個(gè)機(jī)房?jī)?nèi)部的數(shù)據(jù)請(qǐng)求都在本地機(jī)房解決,減少跨地網(wǎng)絡(luò)傳輸。
舉例,假如你的服務(wù)是部署在北京機(jī)房的,你調(diào)用的 mysql、redis最好都位于北京機(jī)房?jī)?nèi)部。盡量不要跨過(guò)千里萬(wàn)里跑到廣東機(jī)房去請(qǐng)求數(shù)據(jù),即使你有專(zhuān)線(xiàn),耗時(shí)也會(huì)大大增加!在機(jī)房?jī)?nèi)部的服務(wù)器之間的 RTT 延遲大概只有零點(diǎn)幾毫秒,同地區(qū)的不同機(jī)房之間大約是 1 ms 多一些。但如果從北京跨到廣東的話(huà),延遲將是 30 - 40 ms 左右,幾十倍的上漲!
建議4:內(nèi)網(wǎng)調(diào)用不要用外網(wǎng)域名
假如說(shuō)你所在負(fù)責(zé)的服務(wù)需要調(diào)用兄弟部門(mén)的一個(gè)搜索接口,假設(shè)接口是:"http://www.sogou.com/wq?key=開(kāi)發(fā)內(nèi)功修煉"。
那既然是兄弟部門(mén),那很可能這個(gè)接口和你的服務(wù)是部署在一個(gè)機(jī)房的。即使沒(méi)有部署在一個(gè)機(jī)房,一般也是有專(zhuān)線(xiàn)可達(dá)的。所以不要直接請(qǐng)求 www.sogou.com, 而是應(yīng)該使用該服務(wù)在公司對(duì)應(yīng)的內(nèi)網(wǎng)域名。在我們公司內(nèi)部,每一個(gè)外網(wǎng)服務(wù)都會(huì)配置一個(gè)對(duì)應(yīng)的內(nèi)網(wǎng)域名,我相信你們公司也有。
為什么要這么做,原因有以下幾點(diǎn)
1)外網(wǎng)接口慢。本來(lái)內(nèi)網(wǎng)可能過(guò)個(gè)交換機(jī)就能達(dá)到兄弟部門(mén)的機(jī)器,非得上外網(wǎng)兜一圈再回來(lái),時(shí)間上肯定會(huì)慢。
2)帶寬成本高。在互聯(lián)網(wǎng)服務(wù)里,除了機(jī)器以外,另外一塊很大的成本就是 IDC 機(jī)房的出入口帶寬成本。兩臺(tái)機(jī)器在內(nèi)網(wǎng)不管如何通信都不涉及到帶寬的計(jì)算。但是一旦你去外網(wǎng)兜了一圈回來(lái),行了,一進(jìn)一出全部要繳帶寬費(fèi),你說(shuō)虧不虧!!
3)NAT 單點(diǎn)瓶頸。一般的服務(wù)器都沒(méi)有外網(wǎng) IP,所以要想請(qǐng)求外網(wǎng)的資源,必須要經(jīng)過(guò) NAT 服務(wù)器。但是一個(gè)公司的機(jī)房里幾千臺(tái)服務(wù)器中,承擔(dān) NAT 角色的可能就那么幾臺(tái)。它很容易成為瓶頸。我們的業(yè)務(wù)就遇到過(guò)好幾次 NAT 故障導(dǎo)致外網(wǎng)請(qǐng)求失敗的情形。NAT 機(jī)器掛了,你的服務(wù)可能也就掛了,故障率大大增加。
2 接收過(guò)程優(yōu)化
建議1:調(diào)整網(wǎng)卡 RingBuffer 大小
當(dāng)網(wǎng)線(xiàn)中的數(shù)據(jù)幀到達(dá)網(wǎng)卡后,第一站就是 RingBu??er。網(wǎng)卡在 RingBuffer 中尋找可用的內(nèi)存位置,找到后 DMA引擎會(huì)把數(shù)據(jù) DMA 到 RingBuffer 內(nèi)存里。因此我們第一個(gè)要監(jiān)控和調(diào)優(yōu)的就是網(wǎng)卡的 RingBuffer,我們使用ethtool 來(lái)來(lái)查看一下 Ringbuffer 的大小。
#ethtool-geth0Ringparametersforeth0:Pre-setmaximums:RX:4096RXMini:0RXJumbo:0TX:4096Currenthardwaresettings:RX:512RXMini:0RXJumbo:0TX: 512
這里看到我手頭的網(wǎng)卡設(shè)置 RingBuffer 最大允許設(shè)置到 4096 ,目前的實(shí)際設(shè)置是 512。
這里有一個(gè)小細(xì)節(jié),ethtool查看到的是實(shí)際是Rx bd的大小。Rx bd位于網(wǎng)卡中,相當(dāng)于一個(gè)指針。
RingBu??er在內(nèi)存中,Rx bd指向RingBuffer。Rx bd和RingBuffer中的元素是一一對(duì)應(yīng)的關(guān)系。在網(wǎng)卡啟
動(dòng)的時(shí)候,內(nèi)核會(huì)為網(wǎng)卡的Rx bd在內(nèi)存中分配RingBu??er,并設(shè)置好對(duì)應(yīng)關(guān)系。
在 Linux 的整個(gè)網(wǎng)絡(luò)棧中,RingBuffer 起到一個(gè)任務(wù)的收發(fā)中轉(zhuǎn)站的角色。對(duì)于接收過(guò)程來(lái)講,網(wǎng)卡負(fù)責(zé)往RingBuffer 中寫(xiě)入收到的數(shù)據(jù)幀,ksoftirqd 內(nèi)核線(xiàn)程負(fù)責(zé)從中取走處理。只要 ksoftirqd 線(xiàn)程工作的足夠快,RingBuffer 這個(gè)中轉(zhuǎn)站就不會(huì)出現(xiàn)問(wèn)題。但是我們?cè)O(shè)想一下,假如某一時(shí)刻,瞬間來(lái)了特別多的包,而 ksoftirqd處理不過(guò)來(lái)了,會(huì)發(fā)生什么?這時(shí) RingBuffer 可能瞬間就被填滿(mǎn)了,后面再來(lái)的包網(wǎng)卡直接就會(huì)丟棄,不做任何處理!
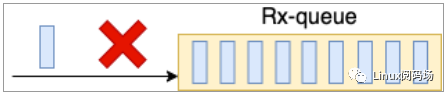
圖2.1RingBuffer 溢出
那我們?cè)趺礃幽芸匆幌拢覀兊姆?wù)器上是否有因?yàn)檫@個(gè)原因?qū)е碌膩G包呢?前面我們介紹的四個(gè)工具都可以查看
這個(gè)丟包統(tǒng)計(jì),拿 ethtool 來(lái)舉例:
#ethtool-Seth0......rx_fifo_errors:0tx_fifo_errors: 0
rx_fifo_errors 如果不為 0 的話(huà)(在 ifconfig 中體現(xiàn)為 overruns 指標(biāo)增長(zhǎng)),就表示有包因?yàn)?RingBuffer 裝不下而被丟棄了。那么怎么解決這個(gè)問(wèn)題呢?很自然首先我們想到的是,加大 RingBuffer 這個(gè)“中轉(zhuǎn)倉(cāng)庫(kù)”的大小,如圖2.2通過(guò) ethtool 就可以修改。
# ethtool -G eth1 rx 4096 tx 4096

圖2.2RingBuffer 擴(kuò)容
這樣網(wǎng)卡會(huì)被分配更大一點(diǎn)的”中轉(zhuǎn)站“,可以解決偶發(fā)的瞬時(shí)的丟包。不過(guò)這種方法有個(gè)小副作用,那就是排隊(duì)的包過(guò)多會(huì)增加處理網(wǎng)絡(luò)包的延時(shí)。所以應(yīng)該讓內(nèi)核處理網(wǎng)絡(luò)包的速度更快一些更好,而不是讓網(wǎng)絡(luò)包傻傻地在RingBuffer 中排隊(duì)。我們后面會(huì)再介紹到 RSS ,它可以讓更多的核來(lái)參與網(wǎng)絡(luò)包接收。
建議2:多隊(duì)列網(wǎng)卡 RSS 調(diào)優(yōu)
硬中斷的情況可以通過(guò)內(nèi)核提供的偽文件 /proc/interrupts 來(lái)進(jìn)行查看。拿飛哥手頭的一臺(tái)虛機(jī)來(lái)舉例:
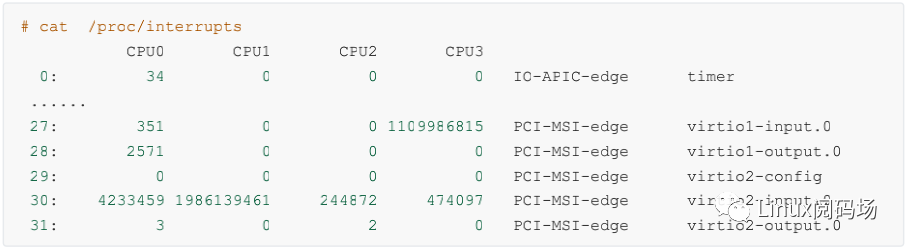
上述結(jié)果是我手頭的一臺(tái)虛機(jī)的輸出結(jié)果。上面包含了非常豐富的信息。網(wǎng)卡的輸入隊(duì)列 virtio1-input.0 的中斷號(hào)是 27,總的中斷次數(shù)是 1109986815,并且 27 號(hào)中斷都是由 CPU3 來(lái)處理的。
那么為什么這個(gè)輸入隊(duì)列的中斷都在 CPU3 上呢?這是因?yàn)閮?nèi)核的一個(gè)中斷親和性配置,在我機(jī)器的偽文件系統(tǒng)中可以查看到。
#cat/proc/irq/27/smp_affinity8
smp_affinity 里是CPU的親和性的綁定,8 是二進(jìn)制的 1000, 第4位為 1。代表的就是當(dāng)前的第 27 號(hào)中斷的都由第 4 個(gè) CPU 核心 - CPU3 來(lái)處理。
現(xiàn)在的主流網(wǎng)卡基本上都是支持多隊(duì)列的。通過(guò) ethtool 工具可以查看網(wǎng)卡的隊(duì)列情況。
#ethtool-leth0Channelparametersforeth0:Pre-setmaximums:RX:0TX:0Other:1Combined:63Currenthardwaresettings:RX:0TX:0Other:1Combined: 8
上述結(jié)果表示當(dāng)前網(wǎng)卡支持的最大隊(duì)列數(shù)是 63 ,當(dāng)前開(kāi)啟的隊(duì)列數(shù)是 8 。這樣當(dāng)有數(shù)據(jù)到達(dá)的時(shí)候,可以將接收進(jìn)來(lái)的包分散到多個(gè)隊(duì)列里。另外每一個(gè)隊(duì)列都有自己的中斷號(hào)。比如我手頭另外一臺(tái)多隊(duì)列的機(jī)器上看到結(jié)果(為了方便展示我刪除了部分不相關(guān)內(nèi)容):
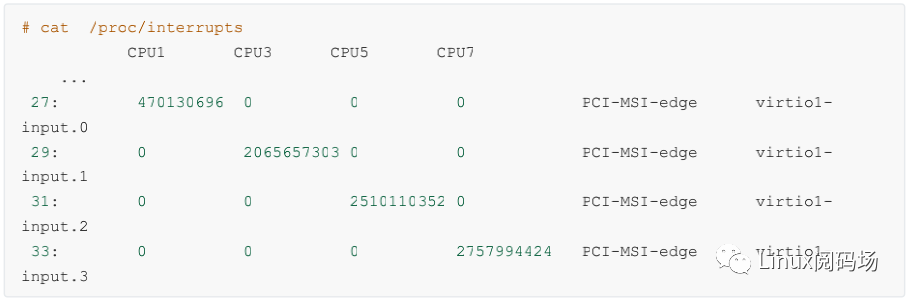
這臺(tái)機(jī)器上 virtio 這塊虛擬網(wǎng)卡上有四個(gè)輸入隊(duì)列,其硬中斷號(hào)分別是 27、29、31 和 33。有獨(dú)立的中斷號(hào)就可以獨(dú)立向某個(gè) CPU 核心發(fā)起硬中斷請(qǐng)求,讓對(duì)應(yīng) CPU 來(lái) poll 包。中斷和 CPU 的對(duì)應(yīng)關(guān)系還是通過(guò) cat/proc/irq/{中斷號(hào)}/smp_affinity 來(lái)查看。通過(guò)將不同隊(duì)列的 CPU 親和性打散到多個(gè) CPU 核上,就可以讓多核同時(shí)并行處理接收到的包了。這個(gè)特性叫做 RSS(Receive Side Scaling,接收端擴(kuò)展),如圖 2.3。這是加快 Linux內(nèi)核處理網(wǎng)絡(luò)包的速度非常有用的一個(gè)優(yōu)化手段。
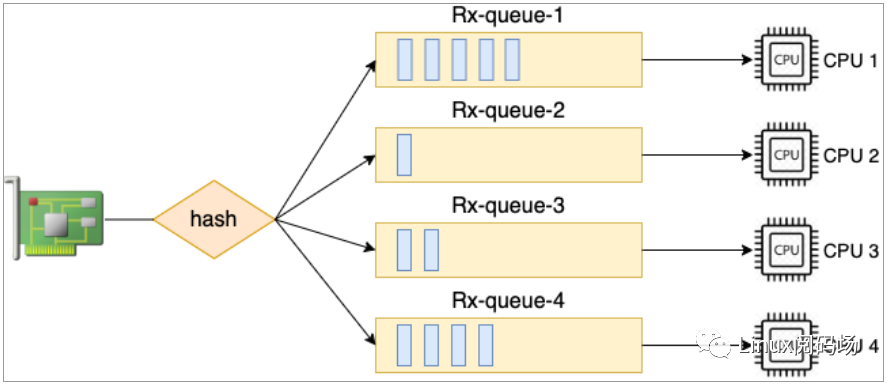
圖2.3多隊(duì)列網(wǎng)卡
在網(wǎng)卡支持多隊(duì)列的服務(wù)器上,想提高內(nèi)核收包的能力,直接簡(jiǎn)單加大隊(duì)列數(shù)就可以了,這比加大 RingBuffer 更為有用。因?yàn)榧哟?RingBuffer 只是給個(gè)更大的空間讓網(wǎng)絡(luò)幀能繼續(xù)排隊(duì),而加大隊(duì)列數(shù)則能讓包更早地被內(nèi)核處理。ethtool 修改隊(duì)列數(shù)量方法如下:
#ethtool -L eth0 combined 32
不過(guò)在一般情況下,由一個(gè)叫隊(duì)列中斷號(hào)和 CPU 之間的親和性并不需要手工維護(hù),有一個(gè) irqbalance的服務(wù)來(lái)自動(dòng)管理。通過(guò) ps 命令可以查看到這個(gè)進(jìn)程。
#ps-ef|grepirqbroot 29805 1 0 18:57 ? 0000 /usr/sbin/irqbalance --foreground
Irqbalance 會(huì)根據(jù)系統(tǒng)中斷負(fù)載的情況,自動(dòng)維護(hù)和遷移各個(gè)中斷的 CPU 親和性,以保持各個(gè) CPU 之間的中斷開(kāi)銷(xiāo)均衡。如果有必要,irqbalance 也會(huì)自動(dòng)把中斷從一個(gè) CPU 遷移到另一個(gè) CPU 上。如果確實(shí)想自己維護(hù)親和性,那得先關(guān)掉 irqbalance,然后再修改中斷號(hào)對(duì)應(yīng)的 smp_affinity。
#serviceirqbalancestop# echo 2 > /proc/irq/30/smp_affinity
建議3:硬中斷合并
在第 1 章中我們看到,當(dāng)網(wǎng)絡(luò)包接收到 RingBuffer 后,接下來(lái)通過(guò)硬中斷通知 CPU。那么你覺(jué)得從整體效率上來(lái)講,是有包到達(dá)就發(fā)起中斷好呢,還是攢一些數(shù)據(jù)包再通知 CPU 更好。
先允許我來(lái)引用一個(gè)實(shí)際工作中的例子,假如你是一位開(kāi)發(fā)同學(xué),和你對(duì)口的產(chǎn)品經(jīng)理一天有10 個(gè)小需求需要讓你幫忙來(lái)處理。她對(duì)你有兩種中斷方式:
第一種:產(chǎn)品經(jīng)理想到一個(gè)需求,就過(guò)來(lái)找你,和你描述需求細(xì)節(jié),然后讓你幫你來(lái)改。
第二種:產(chǎn)品經(jīng)理想到需求后,不來(lái)打擾你,等攢夠 5 個(gè)來(lái)找你一次,你集中處理。
我們現(xiàn)在不考慮及時(shí)性,只考慮你的工作整體效率,你覺(jué)得那種方案下你的工作效率會(huì)高呢?或者換句話(huà)說(shuō),你更喜歡哪一種工作狀態(tài)呢?只要你真的有過(guò)工作經(jīng)驗(yàn),一定都會(huì)覺(jué)得第二種方案更好。對(duì)人腦來(lái)講,頻繁的中斷會(huì)打亂你的計(jì)劃,你腦子里剛才剛想到一半技術(shù)方案可能也就廢了。當(dāng)產(chǎn)品經(jīng)理走了以后,你再想撿起來(lái)剛被中斷之的工作的時(shí)候,很可能得花點(diǎn)時(shí)間回憶一會(huì)兒才能繼續(xù)工作。
對(duì)于CPU來(lái)講也是一樣,CPU要做一件新的事情之前,要加載該進(jìn)程的地址空間,load進(jìn)程代碼,讀取進(jìn)程數(shù)據(jù),各級(jí)別 cache 要慢慢熱身。因此如果能適當(dāng)降低中斷的頻率,多攢幾個(gè)包一起發(fā)出中斷,對(duì)提升 CPU 的整體工作效率是有幫助的。所以,網(wǎng)卡允許我們對(duì)硬中斷進(jìn)行合并。
現(xiàn)在我們來(lái)看一下網(wǎng)卡的硬中斷合并配置。
#ethtool-ceth0Coalesceparametersforeth0:AdaptiveRX:offTX:off......rx-usecs:1rx-frames:0rx-usecs-irq:0rx-frames-irq:0......
我們來(lái)說(shuō)一下上述結(jié)果的大致含義
Adaptive RX::自適應(yīng)中斷合并,網(wǎng)卡驅(qū)動(dòng)自己判斷啥時(shí)候該合并啥時(shí)候不合并
rx-usecs:當(dāng)過(guò)這么長(zhǎng)時(shí)間過(guò)后,一個(gè) RX interrupt 就會(huì)被產(chǎn)生
rx-frames:當(dāng)累計(jì)接收到這么多個(gè)幀后,一個(gè) RX interrupt 就會(huì)被產(chǎn)生
如果你想好了修改其中的某一個(gè)參數(shù)了的話(huà),直接使用 ethtool -C 就可以,例如:
# ethtool -C eth0 adaptive-rx on
不過(guò)需要注意的是,減少中斷數(shù)量雖然能使得 Linux 整體網(wǎng)絡(luò)包吞吐更高,不過(guò)一些包的延遲也會(huì)增大,所以用的時(shí)候得適當(dāng)注意。
建議4:軟中斷 budget 調(diào)整
再舉個(gè)日常工作相關(guān)的例子,不知道你有沒(méi)有聽(tīng)說(shuō)過(guò)番茄工作法這種高效工作方法。它的大致意思就是你在工作的時(shí)候,要有一整段的不被打擾的時(shí)間,集中精力處理某一項(xiàng)工作。這一整段時(shí)間時(shí)長(zhǎng)被建議是 25 分鐘。對(duì)于我們的Linux的處理軟中斷的 ksoftirqd 來(lái)說(shuō),它也和番茄工作法思路類(lèi)似。一旦它被硬中斷觸發(fā)開(kāi)始了工作,它會(huì)集中精力處理一波兒網(wǎng)絡(luò)包(絕不只是1個(gè)),然后再去做別的事情。
我們說(shuō)的處理一波兒是多少呢,策略略復(fù)雜。我們只說(shuō)其中一個(gè)比較容易理解的,那就是net.core.netdev_budget 內(nèi)核參數(shù)。
#sysctl-a|grepnet.core.netdev_budget = 300
這個(gè)的意思說(shuō)的是,ksoftirqd 一次最多處理300個(gè)包,處理夠了就會(huì)把 CPU 主動(dòng)讓出來(lái),以便 Linux 上其它的任務(wù)可以得到處理。那么假如說(shuō),我們現(xiàn)在就是想提高內(nèi)核處理網(wǎng)絡(luò)包的效率。那就可以讓 ksoftirqd 進(jìn)程多干一會(huì)兒網(wǎng)絡(luò)包的接收,再讓出 CPU。至于怎么提高,直接修改這個(gè)參數(shù)的值就好了。
#sysctl -w net.core.netdev_budget=600
如果要保證重啟仍然生效,需要將這個(gè)配置寫(xiě)到/etc/sysctl.conf
建議5:接收處理合并
硬中斷合并是指的攢一堆數(shù)據(jù)包后再通知一次 CPU,不過(guò)數(shù)據(jù)包仍然是分開(kāi)的。Lro(Large Receive Offload) /Gro(Generic Receive Offload) 還能把數(shù)據(jù)包合并起來(lái)后再往上層傳遞。
如果應(yīng)用中是大文件的傳輸,大部分包都是一段數(shù)據(jù),不用 LRO / GRO 的話(huà),會(huì)每次都將一個(gè)小包傳送到協(xié)議棧(IP接收函數(shù)、TCP接收)函數(shù)中進(jìn)行處理。開(kāi)啟了的話(huà),內(nèi)核或者網(wǎng)卡會(huì)進(jìn)行包的合并,之后將一個(gè)大包傳給協(xié)議處理函數(shù),如圖 2.4。這樣 CPU 的效率也就提高了。
圖2.4 接收處理合并
Lro 和 Gro 的區(qū)別是合并包的位置不同。Lro 是在網(wǎng)卡上就把合并的事情給做了,因此要求網(wǎng)卡硬件必須支持才行。而 Gso 是在內(nèi)核源碼中用軟件的方式實(shí)現(xiàn)的,更加通用,不依賴(lài)硬件。
那么如何查看你的系統(tǒng)內(nèi)是否打開(kāi)了 LRO / GRO 呢?
#ethtool-keth0generic-receive-offload:onlarge-receive-offload:on...
如果你的網(wǎng)卡驅(qū)動(dòng)沒(méi)有打開(kāi) GRO 的話(huà),可以通過(guò)如下方式打開(kāi)。
#ethtool-Keth0groon# ethtool -K eth0 lro on
3 發(fā)送過(guò)程優(yōu)化
建議1:控制數(shù)據(jù)包大小
在第四章中我們看到,在發(fā)送協(xié)議棧執(zhí)行的過(guò)程中到了 IP 層如果要發(fā)送的數(shù)據(jù)大于 MTU 的話(huà),會(huì)被分片。這個(gè)分片會(huì)有哪些影響呢?首先就是在分片的過(guò)程中我們看到多了一次的內(nèi)存拷貝。其次就是分片越多,在網(wǎng)絡(luò)傳輸?shù)倪^(guò)程中出現(xiàn)丟包的風(fēng)險(xiǎn)也越大。當(dāng)丟包重傳出現(xiàn)的時(shí)候,重傳定時(shí)器的工作時(shí)間單位是秒,也就是說(shuō)最快 1 秒以后才能開(kāi)始重傳。所以,如果在你的應(yīng)用程序里可能的話(huà),可以嘗試將數(shù)據(jù)大小控制在一個(gè) MTU 內(nèi)部來(lái)極致地提高性能。我所知道的是在早期的 QQ 后臺(tái)服務(wù)中應(yīng)用過(guò)這個(gè)技巧,不知道現(xiàn)在還有沒(méi)有在用。
建議2:減少內(nèi)存拷貝
假如你要發(fā)送一個(gè)文件給另外一臺(tái)機(jī)器上,那么比較基礎(chǔ)的做法是先調(diào)用 read 把文件讀出來(lái),再調(diào)用 send 把數(shù)據(jù)把數(shù)據(jù)發(fā)出去。這樣數(shù)據(jù)需要頻繁地在內(nèi)核態(tài)內(nèi)存和用戶(hù)態(tài)內(nèi)存之間拷貝,如圖 3.1。
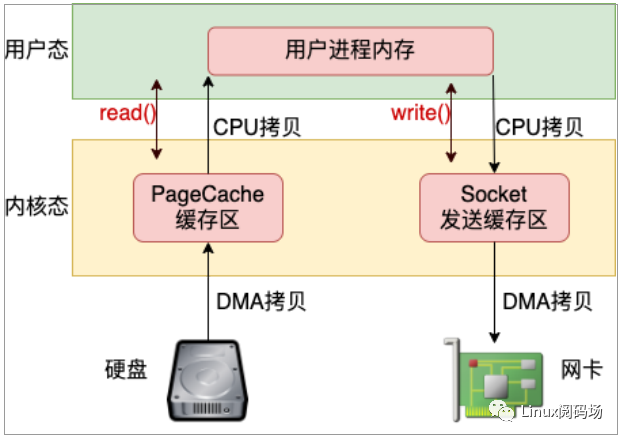
圖3.1 read + write 發(fā)送文件
目前減少內(nèi)存拷貝主要有兩種方法,分別是使用 mmap 和 sendfile 兩個(gè)系統(tǒng)調(diào)用。使用 mmap 系統(tǒng)調(diào)用的話(huà),映射進(jìn)來(lái)的這段地址空間的內(nèi)存在用戶(hù)態(tài)和內(nèi)核態(tài)都是可以使用的。如果你發(fā)送數(shù)據(jù)是發(fā)的是 mmap 映射進(jìn)來(lái)的數(shù)據(jù),則內(nèi)核直接就可以從地址空間中讀取,如圖 3.2,這樣就節(jié)約了一次從內(nèi)核態(tài)到用戶(hù)態(tài)的拷貝過(guò)程。
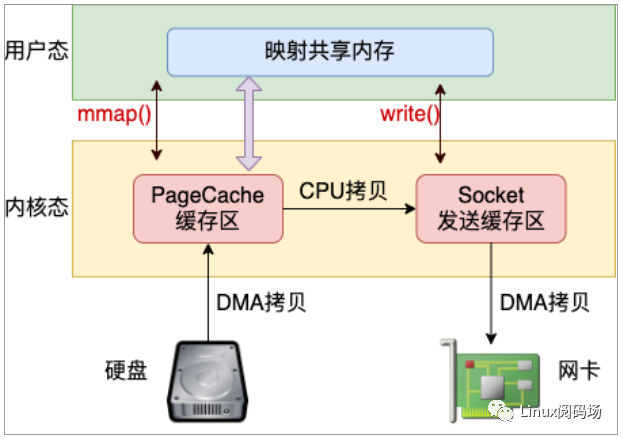
圖3.2 mmap + write 發(fā)送文件
不過(guò)在 mmap 發(fā)送文件的方式里,系統(tǒng)調(diào)用的開(kāi)銷(xiāo)并沒(méi)有減少,還是發(fā)生兩次內(nèi)核態(tài)和用戶(hù)態(tài)的上下文切換。如果你只是想把一個(gè)文件發(fā)送出去,而不關(guān)心它的內(nèi)容,則可以調(diào)用另外一個(gè)做的更極致的系統(tǒng)調(diào)用 - sendfile。在這個(gè)系統(tǒng)調(diào)用里,徹底把讀文件和發(fā)送文件給合并起來(lái)了,系統(tǒng)調(diào)用的開(kāi)銷(xiāo)又省了一次。再配合絕大多數(shù)網(wǎng)卡都支持的"分散-收集"(Scatter-gather)DMA 功能。可以直接從 PageCache 緩存區(qū)中 DMA 拷貝到網(wǎng)卡中,如圖3.3。這樣絕大部分的 CPU 拷貝操作就都省去了。
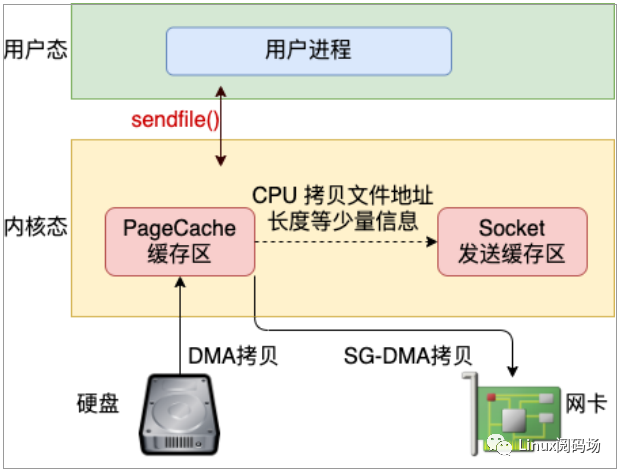
圖3.3 sendfile 發(fā)送文件
建議3:發(fā)送處理合并
在建議 1 中我們說(shuō)到過(guò)發(fā)送過(guò)程在 IP 層如果要發(fā)送的數(shù)據(jù)大于 MTU 的話(huà),會(huì)被分片。但其實(shí)是有一個(gè)例外情況,那就是開(kāi)啟了 TSO(TCP Segmentation Offload)/ GSO(Generic Segmentation Offload)。我們來(lái)回顧和跟進(jìn)
一下發(fā)送過(guò)程中的相關(guān)源碼:
//file:net/ipv4/ip_output.cstaticintip_finish_output(structsk_buff*skb){......//大于mtu的話(huà)就要進(jìn)行分片了if(skb->len>ip_skb_dst_mtu(skb)&&!skb_is_gso(skb))returnip_fragment(skb,ip_finish_output2)?elsereturnip_finish_output2(skb)?}
ip_finish_output 是協(xié)議層中的函數(shù)。skb_is_gso 判斷是否使用 gso,如果使用了的話(huà),就可以把分片過(guò)程推遲到更下面的設(shè)備層去做。
//file:net/core/dev.cintdev_hard_start_xmit(structsk_buff*skb,structnet_device*dev,structnetdev_queue*txq){......if(netif_needs_gso(skb,features)){if(unlikely(dev_gso_segment(skb,features)))gotoout_kfree_skb?if(skb->next)gotogso?}}
dev_hard_start_xmit 位于設(shè)備層,和物理網(wǎng)卡離得更近了。netif_needs_gso 來(lái)判斷是否需要進(jìn)行 GSO 切分。在這個(gè)函數(shù)里會(huì)判斷網(wǎng)卡硬件是不是支持 TSO,如果支持則不進(jìn)行 GSO 切分,將大包直接傳給網(wǎng)卡驅(qū)動(dòng),切分工作推遲到網(wǎng)卡硬件中去做。如果硬件不支持,則調(diào)用 dev_gso_segment 開(kāi)始切分。
推遲分片的好處是可以省去大量包的協(xié)議頭的計(jì)算工作量,減輕 CPU 的負(fù)擔(dān)。
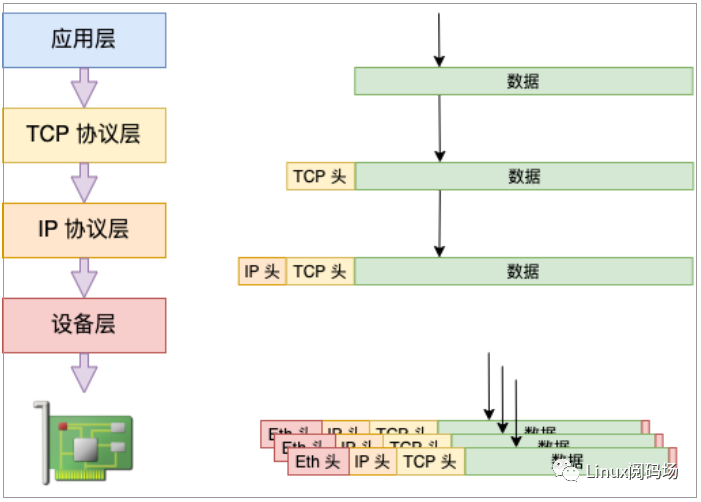
圖3.4 發(fā)送處理合并
使用 ethtool 工具可以查看當(dāng)前 tso 和 gso 的開(kāi)啟狀況。
#ethtool-keth0tcp-segmentation-offload:ontx-tcp-segmentation:ontx-tcp-ecn-segmentation:off[fixed]tx-tcp6-segmentation:onudp-fragmentation-offload:off[fixed]generic-segmentation-offload: off
如果沒(méi)有開(kāi)啟,可以使用 ethtool 打開(kāi)。
#ethtool-Keth0tsoon# ethtool -K eth0 gso on
建議4:多隊(duì)列網(wǎng)卡 XPS 調(diào)優(yōu)
在第四章的發(fā)送過(guò)程中 4.4.5 小節(jié),我們看到在 __netdev_pick_tx 函數(shù)中,要選擇一個(gè)發(fā)送隊(duì)列出來(lái)。如果存在XPS (Transmit Packet Steering)配置,就以 XPS 配置為準(zhǔn)。過(guò)程是根據(jù)當(dāng)前 CPU 的 id 號(hào)去到 XPS 中查看是要用哪個(gè)發(fā)送隊(duì)列,來(lái)看下源碼。
//file:net/core/flow_dissector.cstatic inline int get_xps_queue(struct net_device *dev, struct sk_buff *skb){//獲取xps配置dev_maps=rcu_dereference(dev->xps_maps)?if(dev_maps){map=rcu_dereference(map=rcu_dereference(//raw_smp_processor_id()是獲取當(dāng)前cpuiddev_maps->cpu_map[raw_smp_processor_id()])?if(map){if(map->len==1)queue_index=map->queues[0]?...}
源碼中 raw_smp_processor_id 是在獲取當(dāng)前執(zhí)行的 CPU id。用該 CPU 號(hào)查看對(duì)應(yīng)的 CPU 核是否有配置。XPS配置在 /sys/class/net//queues/tx-/xps_cpus 這個(gè)偽文件里。例如對(duì)于我手頭的一臺(tái)服務(wù)器來(lái)說(shuō),配置是這樣的。
#cat/sys/class/net/eth0/queues/tx-0/xps_cpus00000001#cat/sys/class/net/eth0/queues/tx-1/xps_cpus00000002#cat/sys/class/net/eth0/queues/tx-2/xps_cpus00000004#cat/sys/class/net/eth0/queues/tx-3/xps_cpus00000008......
上述結(jié)果中 xps_cpus 是一個(gè) CPU 掩碼,表示當(dāng)前隊(duì)列對(duì)應(yīng)的 CPU 號(hào)。從上面輸出看對(duì)于 eth0 網(wǎng)卡 下的 tx-0 隊(duì)列來(lái)說(shuō),是和 CPU0 綁定的。00000001 表示 CPU0,00000002 表示 CPU1,...,以此類(lèi)推。假如當(dāng)前 CPU 核是CPU0,那么找到的隊(duì)列就是 eth0 網(wǎng)卡 下的 tx-0。
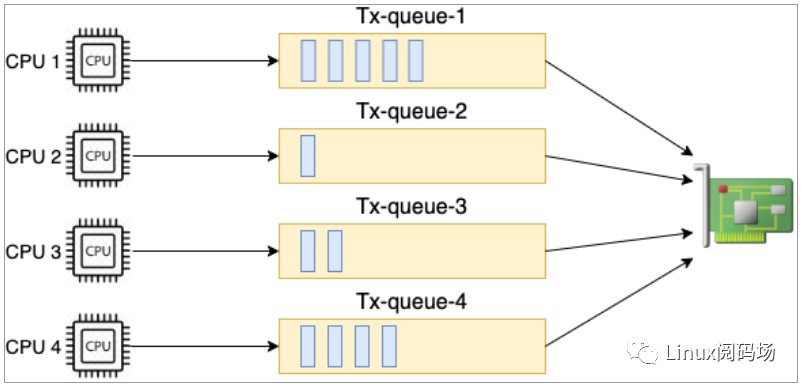
圖3.5多隊(duì)列網(wǎng)卡發(fā)送
那么通過(guò) XPS 指定了當(dāng)前 CPU 要使用的發(fā)送隊(duì)列有什么好處呢。好處大致是有兩個(gè):
第一,因?yàn)楦俚?CPU 爭(zhēng)用同一個(gè)隊(duì)列,所以設(shè)備隊(duì)列鎖上的沖突大大減少。如果進(jìn)一步配置成每個(gè) CPU都有自己獨(dú)立的隊(duì)列用,則會(huì)完全消除隊(duì)列鎖的開(kāi)銷(xiāo)。
第二,CPU 和發(fā)送隊(duì)列一對(duì)一綁定以后能提高傳輸結(jié)構(gòu)的局部性,從而進(jìn)一步提升效率。
關(guān)于RSS、RPS、RFS、aRFS、XPS等網(wǎng)絡(luò)包收發(fā)過(guò)程中的優(yōu)化手段可用參考源碼中
Documentation/networking/scaling.txt這個(gè)文檔。里面有關(guān)于這些技術(shù)的詳細(xì)官方說(shuō)明。
建議5:使用 eBPF 繞開(kāi)協(xié)議棧的本機(jī) IO
如果你的業(yè)務(wù)中涉及到大量的本機(jī)網(wǎng)絡(luò) IO 可以考慮這個(gè)優(yōu)化方案。
在第 5 章中我們看到,本機(jī)網(wǎng)絡(luò) IO 和跨機(jī) IO 比較起來(lái),確實(shí)是節(jié)約了驅(qū)動(dòng)上的一些開(kāi)銷(xiāo)。發(fā)送數(shù)據(jù)不需要進(jìn)RingBuffer 的驅(qū)動(dòng)隊(duì)列,直接把 skb 傳給接收協(xié)議棧(經(jīng)過(guò)軟中斷)。但是在內(nèi)核其它組件上,可是一點(diǎn)都沒(méi)少,系統(tǒng)調(diào)用、協(xié)議棧(傳輸層、網(wǎng)絡(luò)層等)、設(shè)備子系統(tǒng)整個(gè)走 了一個(gè)遍。連“驅(qū)動(dòng)”程序都走了(雖然對(duì)于回環(huán)設(shè)備來(lái)說(shuō)這個(gè)驅(qū)動(dòng)只是一個(gè)純軟件的虛擬出來(lái)的東東)。
如果想用本機(jī)網(wǎng)絡(luò) IO,但是又不想頻繁地在協(xié)議棧中繞來(lái)繞去。那么你可以試試 eBPF。使用 eBPF 的 sockmap和 sk redirect 可以繞過(guò) TCP/IP 協(xié)議棧,而被直接發(fā)送給接收端的 socket,業(yè)界已經(jīng)有公司在這么做了。
4 內(nèi)核與進(jìn)程協(xié)作優(yōu)化
建議1:盡量少用 recvfrom 等進(jìn)程阻塞的方式
在 3.3 節(jié)我們看到,在使用了 recvfrom 阻塞方式來(lái)接收 socket 上數(shù)據(jù)的時(shí)候。每次一個(gè)進(jìn)程專(zhuān)?為了等一個(gè)socket 上的數(shù)據(jù)就得被從 CPU 上拿下來(lái)。然后再換上另一個(gè) 進(jìn)程。等到數(shù)據(jù) ready 了,睡眠的進(jìn)程又會(huì)被喚醒。總共兩次進(jìn)程上下文切換開(kāi)銷(xiāo)。如果我們服務(wù)器上需要有大量的用戶(hù)請(qǐng)求需要處理,那就需要有很多的進(jìn)程存在,而且不停地切換來(lái)切換去。這樣的缺點(diǎn)有如下這么幾個(gè):
因?yàn)槊總€(gè)進(jìn)程只能同時(shí)等待一條連接,所以需要大量的進(jìn)程。
進(jìn)程之間互相切換的時(shí)候需要消耗很多 CPU 周期,一次切換大約是 3 - 5 us 左右。
頻繁的切換導(dǎo)致 L1、L2、L3 等高速緩存的效果大打折扣
大家可能以為這種網(wǎng)絡(luò) IO 模型很少見(jiàn)了。但其實(shí)在很多傳統(tǒng)的客戶(hù)端 SDK 中,比如 mysql、redis 和 kafka 仍然是沿用了這種方式。
建議2:使用成熟的網(wǎng)絡(luò)庫(kù)
使用 epoll 可以高效地管理海量的 socket。在服務(wù)器端。我們有各種成熟的網(wǎng)絡(luò)庫(kù)進(jìn)行使用。這些網(wǎng)絡(luò)庫(kù)都對(duì)epoll 使用了不同程度的封裝。
首先第一個(gè)要給大家參考的是 Redis。老版本的 Redis 里單進(jìn)程高效地使用 epoll 就能支持每秒數(shù)萬(wàn) QPS 的高性能。如果你的服務(wù)是單進(jìn)程的,可以參考 Redis 在網(wǎng)絡(luò) IO 這塊的源碼。
如果是多線(xiàn)程的,線(xiàn)程之間的分工有很多種模式。那么哪個(gè)線(xiàn)程負(fù)責(zé)等待讀 IO 事件,那個(gè)線(xiàn)程負(fù)責(zé)處理用戶(hù)請(qǐng)求,哪個(gè)線(xiàn)程又負(fù)責(zé)給用戶(hù)寫(xiě)返回。根據(jù)分工的不同,又衍生出單 Reactor、多 Reactor、以及 Proactor 等多種模式。大家也不必頭疼,只要理解了這些原理之后選擇一個(gè)性能不錯(cuò)的網(wǎng)絡(luò)庫(kù)就可以了。比如 PHP 中的 Swoole、Golang 的 net 包、Java 中的 netty 、C++ 中的 Sogou Workflow 都封裝的非常的不錯(cuò)。
建議3:使用 Kernel-ByPass 新技術(shù)
如果你的服務(wù)對(duì)網(wǎng)絡(luò)要求確實(shí)特別特特別的高,而且各種優(yōu)化措施也都用過(guò)了,那么現(xiàn)在還有終極優(yōu)化大招 --Kernel-ByPass 技術(shù)。在本書(shū)我們看到了內(nèi)核在接收網(wǎng)絡(luò)包的時(shí)候要經(jīng)過(guò)很?的收發(fā)路徑。在這期間牽涉到很多內(nèi)核組件之間的協(xié)同、協(xié)議棧的處理、以及內(nèi)核態(tài)和用戶(hù)態(tài)的拷貝和切換。Kernel-ByPass 這類(lèi)的技術(shù)方案就是繞開(kāi)內(nèi)核協(xié)議棧,自己在用戶(hù)態(tài)來(lái)實(shí)現(xiàn)網(wǎng)絡(luò)包的收發(fā)。這樣不但避開(kāi)了繁雜的內(nèi)核協(xié)議棧處理,也減少了頻繁了內(nèi)核態(tài)用戶(hù)態(tài)之間的拷貝和切換,性能將發(fā)揮到極致!
目前我所知道的方案有 SOLARFLARE 的軟硬件方案、DPDK 等等。如果大家感興趣,可以多去了解一下!
5 握手揮手過(guò)程優(yōu)化
建議1:配置充足的端口范圍
客戶(hù)端在調(diào)用 connect 系統(tǒng)調(diào)用發(fā)起連接的時(shí)候,需要先選擇一個(gè)可用的端口。內(nèi)核在選用端口的時(shí)候,是采用從可用端口范圍中某一個(gè)隨機(jī)位置開(kāi)始遍歷的方式。如果端口不充足的話(huà),內(nèi)核可能需要循環(huán)撞很多次才能選上一個(gè)可用的。這也會(huì)導(dǎo)致花費(fèi)更多的 CPU 周期在內(nèi)部的哈希表查找以及可能的自旋鎖等待上。因此不要等到端口用盡報(bào)錯(cuò)了才開(kāi)始加大端口范圍,而且應(yīng)該一開(kāi)始的時(shí)候就保持一個(gè)比較充足的值。
#vi/etc/sysctl.confnet.ipv4.ip_local_port_range=500065000# sysctl -p //使配置生效
如果端口加大了仍然不夠用,那么可以考慮開(kāi)啟端口 reuse 和 recycle。這樣端口在連接斷開(kāi)的時(shí)候就不需要等待2MSL 的時(shí)間了,可以快速回收。開(kāi)啟這個(gè)參數(shù)之前需要保證 tcp_timestamps 是開(kāi)啟的。
#vi/etc/sysctl.confnet.ipv4.tcp_timestamps=1net.ipv4.tcp_tw_reuse=1net.ipv4.tw_recycle=1# sysctl -p
建議2:客戶(hù)端最好不要使用 bind
如果不是業(yè)務(wù)有要求,建議客戶(hù)端不要使用 bind。因?yàn)槲覀冊(cè)?6.3 節(jié)看到過(guò),connect 系統(tǒng)調(diào)用在選擇端口的時(shí)候,即使一個(gè)端口已經(jīng)被用過(guò)了,只要和已經(jīng)有的連接四元組不完全一致,那這個(gè)端口仍然可以被用于建立新連接。但是 bind 函數(shù)會(huì)破壞 connect 的這段端口選擇邏輯,直接綁定一個(gè)端口,而且一個(gè)端口只能被綁定一次。如果使用了 bind,則一個(gè)端口只能用于發(fā)起一條連接上。總體上來(lái)看,你的機(jī)器的最大并發(fā)連接數(shù)就真的受限于65535 了。
建議3:小心連接隊(duì)列溢出
服務(wù)器端使用了兩個(gè)連接隊(duì)列來(lái)響應(yīng)來(lái)自客戶(hù)端的握手請(qǐng)求。這兩個(gè)隊(duì)列的長(zhǎng)度是在服務(wù)器 listen 的時(shí)候就確定好了的。如果發(fā)生溢出,很可能會(huì)丟包。所以如果你的業(yè)務(wù)使用的是短連接且流量比較大,那么一定得學(xué)會(huì)觀察這兩個(gè)隊(duì)列是否存在溢出的情況。因?yàn)橐坏┏霈F(xiàn)因?yàn)檫B接隊(duì)列導(dǎo)致的握手問(wèn)題,那么 TCP 連接耗時(shí)都是秒級(jí)以上了。
對(duì)于半連接隊(duì)列, 有個(gè)簡(jiǎn)單的辦法。那就是只要保證 tcp_syncookies 這個(gè)內(nèi)核參數(shù)是 1 就能保證不會(huì)有因?yàn)榘脒B接隊(duì)列滿(mǎn)而發(fā)生的丟包。對(duì)于全連接隊(duì)列來(lái)說(shuō),可以通過(guò) netstat -s 來(lái)觀察。netstat -s 可查看到當(dāng)前系統(tǒng)全連接隊(duì)列滿(mǎn)導(dǎo)致的丟包統(tǒng)計(jì)。但該數(shù)字記錄的是總丟包數(shù),所以你需要再借助 watch 命令動(dòng)態(tài)監(jiān)控。
#watch'netstat--s|grepoverflowed'160 times the listen queue of a socket overflowed //全連接隊(duì)列滿(mǎn)導(dǎo)致的丟包
如果輸出的數(shù)字在你監(jiān)控的過(guò)程中變了,那說(shuō)明當(dāng)前服務(wù)器有因?yàn)槿B接隊(duì)列滿(mǎn)而產(chǎn)生的丟包。你就需要加大你的全連接隊(duì)列的?度了。全連接隊(duì)列是應(yīng)用程序調(diào)用 listen時(shí)傳入的 backlog 以及內(nèi)核參數(shù) net.core.somaxconn 二者之中較小的那個(gè)。如果需要加大,可能兩個(gè)參數(shù)都需要改。如果你手頭并沒(méi)有服務(wù)器的權(quán)限,只是發(fā)現(xiàn)自己的客戶(hù)端機(jī)連接某個(gè) server 出現(xiàn)耗時(shí)長(zhǎng),想定位一下是否是因?yàn)槲帐株?duì)列的問(wèn)題。那也有間接的辦法,可以 tcpdump 抓包查看是否有 SYN 的 TCP Retransmission。如果有偶發(fā)的 TCP Retransmission, 那就說(shuō)明對(duì)應(yīng)的服務(wù)端連接隊(duì)列可能有問(wèn)題了。
建議4:減少握手重試
在 6.5 節(jié)我們看到如果握手發(fā)生異常,客戶(hù)端或者服務(wù)端就會(huì)啟動(dòng)超時(shí)重傳機(jī)制。這個(gè)超時(shí)重試的時(shí)間間隔是翻倍地增長(zhǎng)的,1 秒、3 秒、7 秒、15 秒、31 秒、63 秒 ......。對(duì)于我們提供給用戶(hù)直接訪問(wèn)的接口來(lái)說(shuō),重試第一次耗時(shí) 1 秒多已經(jīng)是嚴(yán)重影響用戶(hù)體驗(yàn)了。如果重試到第三次以后,很有可能某一個(gè)環(huán)節(jié)已經(jīng)報(bào)錯(cuò)返回 504 了。所以在這種應(yīng)用場(chǎng)景下,維護(hù)這么多的超時(shí)次數(shù)其實(shí)沒(méi)有任何意義。倒不如把他們?cè)O(shè)置的小一些,盡早放棄。其中客戶(hù)端的 syn 重傳次數(shù)由 tcp_syn_retries 控制,服務(wù)器半連接隊(duì)列中的超時(shí)次數(shù)是由 tcp_synack_retries 來(lái)控制。把它們兩個(gè)調(diào)成你想要的值。
建議5:打開(kāi) TFO( TCP Fast Open)
我們第 6 章的時(shí)候沒(méi)有介紹一個(gè)細(xì)節(jié),那就是 fastopen 功能。在客戶(hù)端和服務(wù)器端都支持該功能的前提下,客戶(hù)端的第三次握手 ack 包就可以攜帶要發(fā)送給服務(wù)器的數(shù)據(jù)。這樣就會(huì)節(jié)約一個(gè) RTT 的時(shí)間開(kāi)銷(xiāo)。如果支持,可以嘗試啟用。
#vi/etc/sysctl.confnet.ipv4.tcp_fastopen=3//服務(wù)器和客戶(hù)端兩種角色都啟用#sysctl--p
建議6:保持充足的文件描述符上限
在 Linux 下一切皆是文件,包括我們網(wǎng)絡(luò)連接中的 socket。如果你的服務(wù)進(jìn)程需要支持海量的并發(fā)連接。那么調(diào)整和加大文件描述符上限是很關(guān)鍵的。否則你的線(xiàn)上服務(wù)將會(huì)收到 “Too many open files”這個(gè)錯(cuò)誤。
相關(guān)的限制機(jī)制請(qǐng)參考 8.2 節(jié),這里我們給出一套推薦的修改方法。例如你的服務(wù)需要在單進(jìn)程支持 100 W 條并發(fā),那么建議:
#vi/etc/sysctl.conffs.file-max=1100000//系統(tǒng)級(jí)別設(shè)置成110W,多留點(diǎn)buffer。fs.nr_open=1100000//進(jìn)程級(jí)別也設(shè)置成110W,因?yàn)橐WC比hardnofile大#sysctl--p#vi/etc/security/limits.conf//用戶(hù)進(jìn)程級(jí)別都設(shè)置成100W*softnofile1000000* hard nofile 1000000
建議7:如果請(qǐng)求頻繁,請(qǐng)棄用短連接改用長(zhǎng)連接
如果你的服務(wù)器頻繁請(qǐng)求某個(gè) server,比如 redis 緩存。和建議 1 比起來(lái),一個(gè)更好一點(diǎn)的方法是使用長(zhǎng)連接。這樣的好處有
1)節(jié)約了握手開(kāi)銷(xiāo)。短連接中每次請(qǐng)求都需要服務(wù)和緩存之間進(jìn)行握手,這樣每次都得讓用戶(hù)多等一個(gè)握手的時(shí)間開(kāi)銷(xiāo)。
2)規(guī)避了隊(duì)列滿(mǎn)的問(wèn)題。前面我們看到當(dāng)全連接或者半連接隊(duì)列溢出的時(shí)候,服務(wù)器直接丟包。而客戶(hù)端呢并不知情,所以傻傻地等 3 秒才會(huì)重試。要知道 tcp 本身并不是專(zhuān)門(mén)為互聯(lián)網(wǎng)服務(wù)設(shè)計(jì)的。這個(gè) 3 秒的超時(shí)對(duì)于互聯(lián)網(wǎng)用戶(hù)的體驗(yàn)影響是致命的。
3)端口數(shù)不容易出問(wèn)題。端連接中,在釋放連接的時(shí)候,客戶(hù)端使用的端口需要進(jìn)入 TIME_WAIT 狀態(tài),等待 2MSL的時(shí)間才能釋放。所以如果連接頻繁,端口數(shù)量很容易不夠用。而長(zhǎng)連接就固定使用那么幾十上百個(gè)端口就夠用了。
建議8:TIME_WAIT 的優(yōu)化
很多線(xiàn)上服務(wù)如果使用了短連接的情況下,就會(huì)出現(xiàn)大量的 TIME_WAIT。
首先,我想說(shuō)的是沒(méi)有必要見(jiàn)到兩三萬(wàn)個(gè) TIME_WAIT 就恐慌的不行。從內(nèi)存的?度來(lái)考慮,一條 TIME_WAIT 狀態(tài)的連接僅僅是 0.5 KB 的內(nèi)存而已。從端口占用的角度來(lái)說(shuō),確實(shí)是消耗掉了一個(gè)端口。但假如你下次再連接的是不同的 Server 的話(huà),該端口仍然可以使用。只有在所有 TIME_WAIT 都聚集在和一個(gè) Server 的連接上的時(shí)候才會(huì)有問(wèn)題。
那怎么解決呢? 其實(shí)辦法有很多。第一個(gè)辦法是按上面建議 1 中的開(kāi)啟端口 reuse 和 recycle。第二個(gè)辦法是限制TIME_WAIT 狀態(tài)的連接的最大數(shù)量。
#vi/etc/sysctl.confnet.ipv4.tcp_max_tw_buckets=32768# sysctl --p
如果再?gòu)氐滓恍部梢愿纱嗖捎媒ㄗh 7 ,直接用?連接代替頻繁的短連接。連接頻率大大降低以后,自然也就沒(méi)有 TIME_WAIT 的問(wèn)題了。
原文標(biāo)題:深入理解Linux網(wǎng)絡(luò)之網(wǎng)絡(luò)性能優(yōu)化建議
文章出處:【微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
cpu
+關(guān)注
關(guān)注
68文章
11067瀏覽量
216635 -
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3915瀏覽量
66031
原文標(biāo)題:深入理解Linux網(wǎng)絡(luò)之網(wǎng)絡(luò)性能優(yōu)化建議
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【深圳】誠(chéng)聘運(yùn)維開(kāi)發(fā)工程師
【上海】高級(jí)運(yùn)維工程師
為何運(yùn)維人員要學(xué)Python?
學(xué)習(xí)Linux運(yùn)維發(fā)展方向
Linux運(yùn)維都要會(huì)哪些shell技能
運(yùn)維人員到底要不要學(xué)習(xí)開(kāi)發(fā)
虛擬化故障怎么辦?虛擬化運(yùn)維怎么解決?
何為智能運(yùn)維?
開(kāi)啟運(yùn)維新時(shí)代:WOT2016互聯(lián)網(wǎng)運(yùn)維與開(kāi)發(fā)者峰會(huì)內(nèi)容回顧
邊緣運(yùn)維架構(gòu)是怎樣的
云計(jì)算運(yùn)維管理的優(yōu)化與改進(jìn)

制氫機(jī)遠(yuǎn)程監(jiān)控運(yùn)維方案
光伏電站智能運(yùn)維管理系統(tǒng)三大核心功能
Acrel-1200安科瑞光伏運(yùn)維平臺(tái)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論