 基于深度學習的3D分割綜述(RGB-D/點云/體素/多目)
基于深度學習的3D分割綜述(RGB-D/點云/體素/多目)
摘要
3D目標分割是計算機視覺中的一個基本且具有挑戰性的問題,在自動駕駛、機器人、增強現實和醫學圖像分析等領域有著廣泛的應用。它受到了計算機視覺、圖形和機器學習社區的極大關注。傳統上,3D分割是用人工設計的特征和工程方法進行的,這些方法精度較差,也無法推廣到大規模數據上。在2D計算機視覺巨大成功的推動下,深度學習技術最近也成為3D分割任務的首選。近年來已涌現出大量相關工作,并且已經在不同的基準數據集上進行了評估。本文全面調研了基于深度學習的3D分割的最新進展,涵蓋了150多篇論文。論文總結了最常用的范式,討論了它們的優缺點,并分析了這些分割方法的對比結果。并在此基礎上,提出了未來的研究方向。
如圖1第二行所示,3D分割可分為三種類型:語義分割、實例分割和部件分割。

論文的主要貢獻如下:
本文是第一篇全面涵蓋使用不同3D數據表示(包括RGB-D、投影圖像、體素、點云、網格和3D視頻)進行3D分割的深度學習綜述論文;
論文對不同類型的3D數據分割方法的相對優缺點進行了深入分析;
與現有綜述不同,論文專注于專為3D分割設計的深度學習方法,并討論典型的應用領域;
論文對幾種公共基準3D數據集上的現有方法進行了全面比較,得出了有趣的結論,并確定了有前景的未來研究方向。
圖2顯示了論文其余部分的組織方式:
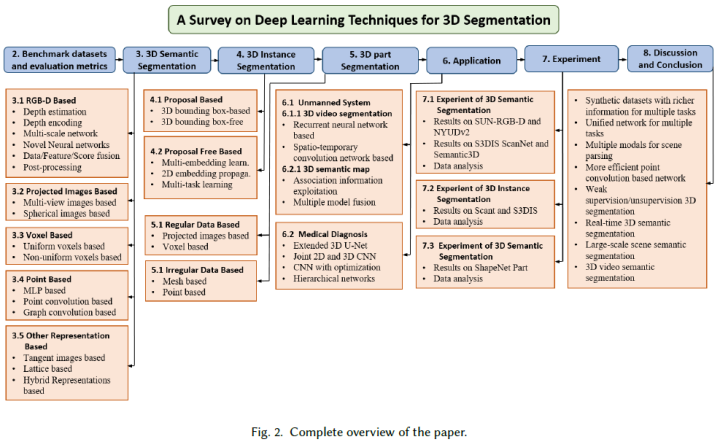
基準數據集和評估指標
3D分割數據集
數據集對于使用深度學習訓練和測試3D分割算法至關重要。然而,私人收集和標注數據集既麻煩又昂貴,因為它需要領域專業知識、高質量的傳感器和處理設備。因此,構建公共數據集是降低成本的理想方法。遵循這種方式對社區有另一個好處,它提供了算法之間的公平比較。表1總結了關于傳感器類型、數據大小和格式、場景類別和標注方法的一些最流行和典型的數據集。
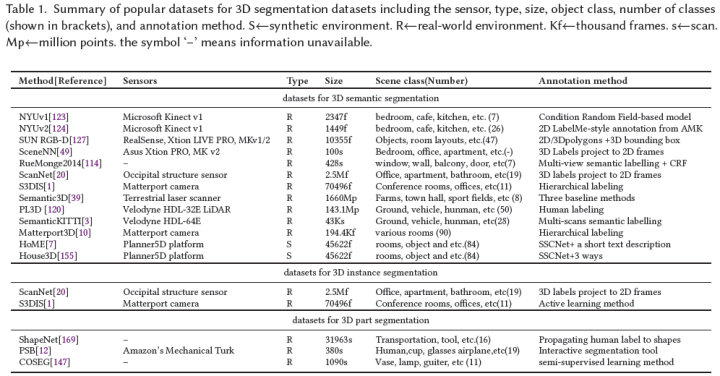
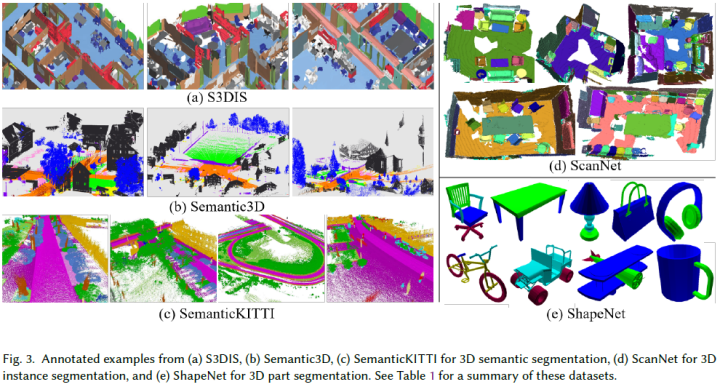
這些數據集是通過不同類型的傳感器(包括RGB-D相機[123]、[124]、[127]、[49]、[20]、移動激光掃描儀[120]、[3]、靜態地面掃描儀[39]和非真實引擎[7]、[155]和其他3D掃描儀[1]、[10])用于3D語義分割而獲取的。其中,從非真實引擎獲得的數據集是合成數據集[7][155],不需要昂貴的設備或標注時間。這些物體的種類和數量非常豐富。與真實世界數據集相比,合成數據集具有完整的360度3D目標,沒有遮擋效果或噪聲,真實世界數據集中有噪聲且包含遮擋[123]、[124]、[127]、[49]、[20]、[120]、[12]、[3]、[1]、[39]、[10]。對于3D實例分割,只有有限的3D數據集,如ScanNet[20]和S3DIS[1]。這兩個數據集分別包含RGB-D相機或Matterport獲得的真實室內場景的掃描數據。對于3D部件分割,普林斯頓分割基準(PSB)[12]、COSEG[147]和ShapeNet[169]是三個最流行的數據集。圖3中顯示了這些數據集的標注示例:
評價指標
不同的評估指標可以評價分割方法的有效性和優越性,包括執行時間、內存占用和準確性。然而,很少有作者提供有關其方法的執行時間和內存占用的詳細信息。本文主要介紹精度度量。對于3D語義分割,常用的有Overall Accuracy(OAcc)、mean class Accuracy(mAcc)、mean class Intersection over Union(mIoU)。
OAcc:
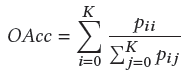
mAcc:
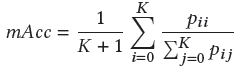
mIoU:
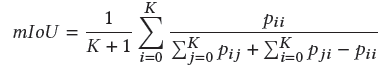
對于3D實例分割,常用的有Average Precision(AP)、mean class Average Precision(mAP)。
AP:
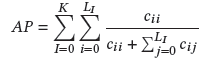
mAP:
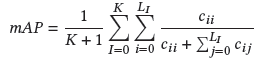
對于3D部件分割,常用的指標是overall average category Intersection over Union(Cat.mIoU)和overall average instance Intersection over Union(Ins.mIoU)。
Cat.mIoU:
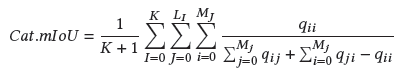
Ins.mIoU:
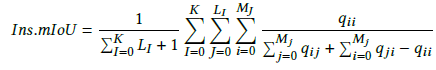
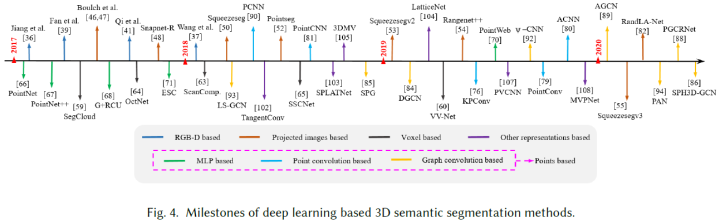
3D語義分割
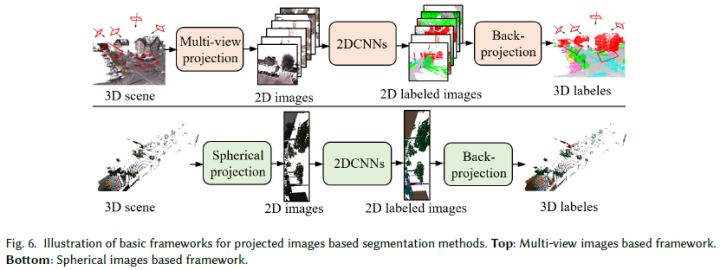
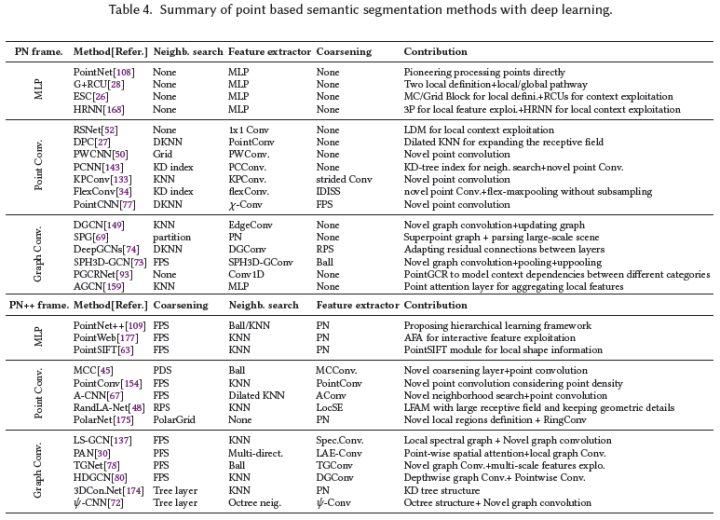
文獻中提出了許多關于3D語義分割的深度學習方法。根據使用的數據表示,這些方法可分為五類,即基于RGB-D圖像、基于投影圖像、基于體素、基于點云和其他表示。基于點云的方法可以根據網絡架構進一步分類為基于多層感知器(MLP)的方法、基于點云卷積的方法和基于圖卷積的。圖4顯示了近年來3D語義分割深度學習的里程碑。
基于RGB-D
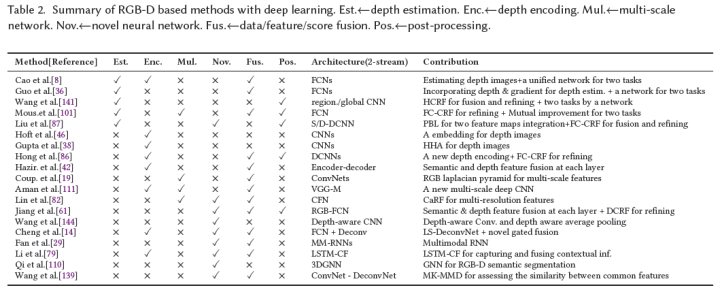
RGB-D圖像中的深度圖包含關于真實世界的幾何信息,這有助于區分前景目標和背景,從而提供提高分割精度的可能。在這一類別中,通常使用經典的雙通道網絡分別從RGB和深度圖像中提取特征。然而框架過于簡單,無法提取豐富而精細的特征。為此,研究人員將幾個附加模塊集成到上述簡單的雙通道框架中,通過學習對語義分割至關重要的豐富上下文和幾何信息來提高性能。這些模塊大致可分為六類:多任務學習、深度編碼、多尺度網絡、新型神經網絡結構、數據/特征/得分級融合和后處理(見圖5)。表2中總結了基于RGB-D圖像的語義分割方法。
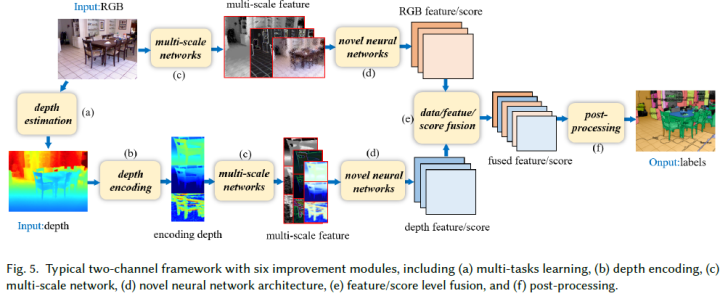
多任務學習:深度估計和語義分割是計算機視覺中兩個具有挑戰性的基本任務。這些任務也有一定的相關性,因為與不同目標之間的深度變化相比,目標內的深度變化較小。因此,許多研究者選擇將深度估計任務和語義分割任務結合起來。從兩個任務的關系來看,多任務學習框架主要有兩種類型:級聯式和并行式。級聯式的工作有[8]、[36],級聯框架分階段進行深度估計和語義分割,無法端到端訓練。因此,深度估計任務并沒有從語義分割任務中獲得任何好處。并行式的工作有[141]、[101]、[87],讀者具體可以參考相關論文。
深度編碼:傳統的2D CNN無法利用原始深度圖像的豐富幾何特征。另一種方法是將原始深度圖像編碼為適合2D-CNN的其他表示。Hoft等人[46]使用定向梯度直方圖(HOG)的簡化版本來表示RGB-D場景的深度通道。Gupta等人[38]和Aman等人[82]根據原始深度圖像計算了三個新通道,分別為水平視差、地面高度和重力角(HHA)。Liu等人[86]指出了HHA的局限性,即某些場景可能沒有足夠的水平和垂直平面。因此,他們提出了一種新的重力方向檢測方法,通過擬合垂直線來學習更好的表示。Hazirbas等人[42]還認為,HHA表示具有較高的計算成本,并且包含比原始深度圖像更少的信息。并提出了一種稱為FuseNet的架構,該架構由兩個編碼器-解碼器分支組成,包括一個深度分支和一個RGB分支,且以較低的計算負載直接編碼深度信息。
多尺度網絡:由多尺度網絡學習的上下文信息對于小目標和詳細的區域分割是有用的。Couprie等人[19]使用多尺度卷積網絡直接從RGB圖像和深度圖像中學習特征。Aman等人[111]提出了一種用于分割的多尺度deep ConvNet,其中VGG16-FC網絡的粗預測在scale-2模塊中被上采樣。然而,這種方法對場景中的雜波很敏感,導致輸出誤差。Lin等人[82]利用了這樣一個事實:較低場景分辨率區域具有較高的深度,而較高場景分辨率區域則具有較低的深度。他們使用深度圖將相應的彩色圖像分割成多個場景分辨率區域,并引入context-aware receptive field(CaRF),該感知場專注于特定場景分辨率區域的語義分割。這使得他們的管道成為多尺度網絡。
新型神經網絡結構:由于CNN的固定網格計算,它們處理和利用幾何信息的能力有限。因此,研究人員提出了其他新穎的神經網絡架構,以更好地利用幾何特征以及RGB和深度圖像之間的關系。這些架構可分為四大類:改進2D CNN,相關工作有[61]、[144];逆卷積神經網絡(DeconvNets),相關工作有[87]、[139]、[14];循環神經網絡(RNN),相關工作有[29]、[79];圖神經網絡(GNN),相關工作有[110]。
數據/特征/得分融合:紋理(RGB通道)和幾何(深度通道)信息的最優融合對于準確的語義分割非常重要。融合策略有三種:數據級、特征級和得分級,分別指早期、中期和晚期融合。數據融合最簡單的方式是將RGB圖像和深度圖像concat為4通道輸入CNN[19]中,這種方式比較粗暴,沒有充分利用深度和光度通道之間的強相關性。特征融合捕獲了這些相關性,相關工作有[79]、[139]、[42]、[61]。得分級融合通常使用簡單的平均策略進行。然而,RGB模型和深度模型對語義分割的貢獻是不同的,相關工作有[86]、[14]。
后處理:用于RGB-D語義分割的CNN或DCNN的結果通常非常粗糙,導致邊緣粗糙和小目標消失。解決這個問題的一個常見方法是將CNN與條件隨機場(CRF)耦合。Wang等人[141]通過分層CRF(HCRF)的聯合推斷進一步促進了兩個通道之間的相互作用。它加強了全局和局部預測之間的協同作用,其中全局用于指導局部預測并減少局部模糊性,局部結果提供了詳細的區域結構和邊界。Mousavian等人[101]、Liu等人[87]和Long等人[86]采用了全連接CRF(FC-CRF)進行后處理,其中逐像素標記預測聯合考慮幾何約束,如逐像素法線信息、像素位置、強度和深度,以促進逐像素標記的一致性。類似地,Jiang等人[61]提出了將深度信息與FC-CRF相結合的密集敏感CRF(DCRF)。
基于投影圖像
基于投影圖像的語義分割的核心思想是使用2D CNN從3D場景/形狀的投影圖像中提取特征,然后融合這些特征用于標簽預測。與單目圖像相比,該范式不僅利用了來自大規模場景的更多語義信息,而且與點云相比,減少了3D場景的數據大小。投影圖像主要包括多目圖像或球形圖像。表3總結了基于投影圖像的語義分割方法。
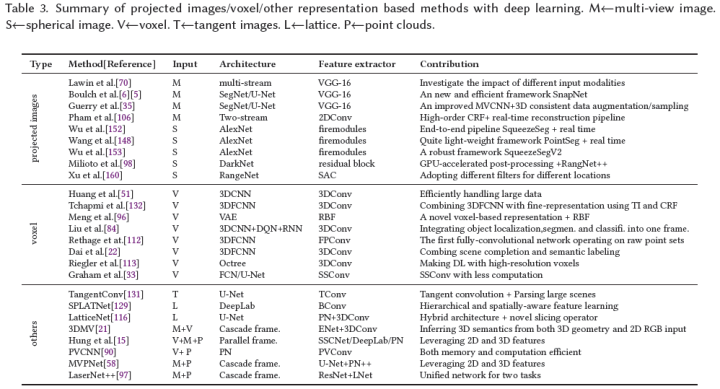
基于多目圖像
MV-CNN[130]使用統一網絡將由虛擬相機形成的3D形狀的多個視圖中的特征組合到單個緊湊的形狀描述子中,以獲得更好的分類性能。這促使研究人員將同樣的想法應用于3D語義分割(見圖6)。例如,Lawin等人[70]將點云投影到多目合成圖像中,包括RGB、深度和表面法線圖像。將所有多目圖像的預測分數融合到單個表示中,并將其反向投影到每個點云中。然而,如果點云的密度較低,圖像可能會錯誤地捕捉到觀測結構背后的點云,這使得深度網絡誤解了多目圖像。為此,SnapNet[6]、[5]對點云進行預處理,以計算點云特征(如正常或局部噪聲)并生成網格,這與點云密度化類似。從網格和點云中,它們通過適當的快照生成RGB和深度圖像。然后使用FCN對2D快照進行逐像素標記,并通過高效緩沖將這些標記快速重投影回3D點云。其他相關算法[35]、[106]可參考具體論文。
基于球形圖像
從3D場景中選擇快照并不直接。必須在適當考慮視點數量、視距和虛擬相機角度后拍攝快照,以獲得完整場景的最優表示。為了避免這些復雜性,研究人員將整個點云投影到一個球體上(見圖6底部)。例如,Wu等人[152]提出了一個名為SqueezeSeg的端到端管道,其靈感來自SqueezeNet[53],用于從球形圖像中學習特征,然后由CRF將其細化為循環層。類似地,PointSeg[148]通過整合特征和通道注意力來擴展SqueezeNet,以學習魯棒表示。其他相關算法還有[153]、[98]、[160]。
基于體素
與像素類似,體素將3D空間劃分為具有特定大小和離散坐標的許多體積網格。與投影圖像相比,它包含更多的場景幾何信息。3D ShapeNets[156]和VoxNet[94]將體積占用網格表示作為用于目標識別的3D CNN的輸入,該網絡基于體素指導3D語義分割。根據體素大小的統一性,基于體素的方法可分為均勻體素方法和非均勻體素法。表3總結了基于體素的語義分割方法。
均勻體素
3D CNN是用于處理標簽預測的統一體素的通用架構。Huang等人[51]提出了用于粗體素水平預測的3D FCN。他們的方法受到預測之間空間不一致性的限制,并提供了粗略的標記。Tchapmi等人[132]引入了一種新的網絡SEGCloud來產生細粒度預測。其通過三線性插值將從3D FCN獲得的粗體素預測上采樣到原始3D點云空間分辨率。對于固定分辨率的體素,計算復雜度隨場景比例的增加而線性增長。大體素可以降低大規模場景解析的計算成本。Liu等人[84]介紹了一種稱為3DCNN-DQN-RNN的新型網絡。與2D語義分割中的滑動窗口一樣,該網絡在3D-CNN和deep Q-Network(DQN)的控制下,提出了遍歷整個數據的眼睛窗口,用于快速定位和分割目標。3D-CNN和殘差RNN進一步細化眼睛窗口中的特征。該流水線有效地學習感興趣區域的關鍵特征,以較低的計算成本提高大規模場景解析的準確性。其他相關工作[112]、[22]、[96]可以參考論文。
非均勻體素
在固定比例場景中,隨著體素分辨率的增加,計算復雜度呈立方增長。然而,體素表示自然是稀疏的,在對稀疏數據應用3D密集卷積時會導致不必要的計算。為了緩解這個問題,OcNet[113]使用一系列不平衡的八叉樹將空間分層劃分為非均勻體素。樹結構允許內存分配和計算集中于相關的密集體素,而不犧牲分辨率。然而,empty space仍然給OctNet帶來計算和內存負擔。相比之下,Graham等人[33]提出了一種新的子流形稀疏卷積(SSC),它不在empty space進行計算,彌補了OcNet的缺陷。
基于點云
點云在3D空間中不規則地散布,缺乏任何標準順序和平移不變性,這限制了傳統2D/3D卷積神經網絡的使用。最近,一系列基于點云的語義分割網絡被提出。這些方法大致可分為三類:基于多層感知器(MLP)的、基于點云卷積的和基于圖卷積。表4總結了這些方法。
基于MLP
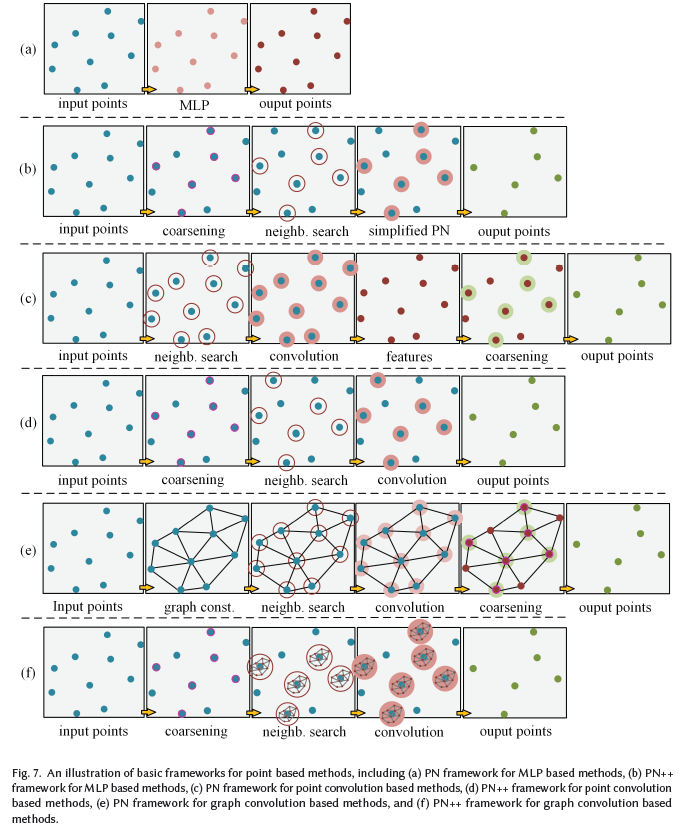
這些方法直接使用MLP學習點云特征。根據其框架,可進一步分為兩類:基于PN和基于PN++框架的方法,如圖7(a)和(b)所示。
基于PN框架
PointNet[108](PN)是一項直接處理點云的開創性工作。它使用共享MLP來挖掘逐點云特征,并采用max-pooling等對稱函數來將這些特征聚合到全局特征表示中。由于max-pooling僅捕獲全局點云的最大激活,因此PN無法學習利用局部特征。基于PN框架,一些網絡開始定義局部區域以增強局部特征學習,并利用遞歸神經網絡(RNN)來增加上下文特征的利用。例如,Engelmann等人[28]通過KNN聚類和K-means聚類定義局部區域,并使用簡化PN提取局部特征。ESC[26]將全局區域點云劃分為多尺度/網格塊。連接的(局部)塊特征附加到逐點云特征,并通過遞歸合并單元(RCU)進一步學習全局上下文特征。其他相關算法[168]可以參考論文。
基于PN++框架
基于PointNet,PointNet++[109](PN++)定義了分層學習架構。它使用最遠點采樣(FPS)對點云進行分層采樣,并使用k個最近鄰搜索和球搜索對局部區域進行聚類。逐步地,簡化的PointNet在多個尺度或多個分辨率下利用局部區域的功能。PN++框架擴展了感受野以共同利用更多的局部特征。受SIFT[91]的啟發,PointSIFT[63]在采樣層之前插入一個PointSIFT模塊層,以學習局部形狀信息。該模塊通過對不同方向的信息進行編碼,將每個點云轉換為新的形狀表示。類似地,PointWeb[177]在聚類層之后插入自適應特征調整(AFA)模塊層,以將點云之間的交互信息嵌入到每個點云中。這些策略增強了學習到的逐點云特征的表示能力。然而,MLP仍然單獨處理每個局部點云,并且不注意局部點云之間的幾何連接。此外,MLP是有效的,但缺乏捕捉更廣泛和更精細的局部特征的復雜性。
基于點云卷積
基于點云卷積的方法直接對點云進行卷積運算。與基于MLP的分割類似,這些網絡也可以細分為基于PN框架的方法和基于PN++框架的方法,如圖7(c)、(d)所示。
基于PN
基于PN框架的方法對每個點云的相鄰點云進行卷積。例如,RSNet[52]使用1x1卷積利用逐點云特征,然后將它們傳遞給local dependency module(LDM),以利用局部上下文特征。但是,它并沒有為每個點云定義鄰域以了解局部特征。另一方面,PointwiseCNN[50]按照特定的順序對點云進行排序,例如XYZ坐標或Morton曲線[100],并動態查詢最近鄰,并將它們放入3x3x3 kernel中,然后使用相同的內核權重進行卷積。DPC[27]在通過dilated KNN搜索確定鄰域點云的每個點云的鄰域點云上調整點卷積[154]。該方法將擴張機制整合到KNN搜索中,以擴大感受野。PCNN[143]在KD-tree鄰域上進行參數化CNN,以學習局部特征。然而,特征圖的固定分辨率使得網絡難以適應更深層次的架構。其他相關算法[133]、[34]、[77]可以參考具體論文。
基于PN++
基于PN++框架的方法將卷積層作為其關鍵層。例如,蒙特卡羅卷積近似的一個擴展叫做PointConv[154],它考慮了點云密度。使用MLP來近似卷積核的權重函數,并使用inverse density scale來重新加權學習的權重函數。類似地,MCC[45]通過依賴點云概率密度函數(PDF)將卷積表述為蒙特卡羅積分問題,其中卷積核也由MLP表示。此外,它引入了Possion Disk Sampling(PDS)[151]來構建點云層次結構,而不是FPS,這提供了一個在感受野中獲得最大樣本數的機會。A-CNN[67]通過擴展的KNN定義了一個新的局部環形區域,并將點云投影到切線平面上,以進一步排序局部區域中的相鄰點云。然后,對這些表示為閉環陣列的有序鄰域進行標準點云卷積。其他相關算法[48]、[175]可以參考具體論文。
基于圖卷積
基于圖卷積的方法對與圖結構連接的點云進行卷積。在這里,圖的構造(定義)和卷積設計正成為兩個主要挑戰。PN框架和PN++框架的相同分類也適用于圖7(e)和(f)所示的圖卷積方法。
基于PN
基于PN框架的方法從全局點云構造圖,并對每個點云的鄰域點云進行卷積。例如,ECC[125]是應用空間圖形網絡從點云提取特征的先驅方法之一。它動態生成edge-conditioned filters,以學習描述點云與其相鄰點云之間關系的邊緣特征。基于PN架構,DGCN[149]在每個點云的鄰域上實現稱為EdgeConv的動態邊緣卷積。卷積由簡化PN近似。SPG[69]將點云劃分為若干簡單的幾何形狀(稱為super-points),并在全局super-points上構建super graph。此外,該網絡采用PointNet來嵌入這些點云,并通過門控遞歸單元(GRU)細化嵌入。其他相關算法[74]、[73]、[93]、[159]可以參考具體論文。
基于PN++
基于PN++框架的方法對具有圖結構的局部點云進行卷積。圖是光譜圖或空間圖。在前一種情況下,LS-GCN[137]采用了PointNet++的基本架構,使用標準的非參數化傅立葉kernel將MLP替換為譜圖卷積,以及一種新的spectral cluster pooling替代max-pooling。然而,從空間域到頻譜域的轉換需要很高的計算成本。此外,譜圖網絡通常定義在固定的圖結構上,因此無法直接處理具有不同圖結構的數據。相關算法可以參考[30]、[78]、[80]、[174]、[72]。
基于其他表示
一些方法將原始點云轉換為投影圖像、體素和點云以外的表示。這種表示的例子包括正切圖像[131]和晶格[129]、[116]。在前一種情況下,Tatargenko等人[131]將每個點云周圍的局部曲面投影到一系列2D切線圖像,并開發基于切線卷積的U-Net來提取特征。在后一種情況下,SPLATNet[129]采用Jampani等人[56]提出的雙邊卷積層(BCL)將無序點云平滑映射到稀疏網格上。類似地,LatticeNet[116]使用了一種混合架構,它將獲得低級特征的PointNet與探索全局上下文特征的稀疏3D卷積相結合。這些特征嵌入到允許應用標準2D卷積的稀疏網格中。盡管上述方法在3D語義分割方面取得了重大進展,但每種方法都有其自身的缺點。例如,多目圖像具有更多的語義信息,但場景的幾何信息較少。另一方面,體素具有更多的幾何信息,但語義信息較少。為了獲得最優性能,一些方法采用混合表示作為輸入來學習場景的綜合特征。相關算法[21]、[15]、[90]、[58]、[97]可以參考具體論文。
3D實例分割
3D實例分割方法另外區分同一類的不同實例。作為場景理解的一項信息量更大的任務,3D實例分割越來越受到研究界的關注。3D實例分割方法大致分為兩個方向:基于Proposal和無Proposal。
基于Proposal
基于Proposal的方法首先預測目標Proposal,然后細化它們以生成最終實例mask(見圖8),將任務分解為兩個主要挑戰。因此,從Proposal生成的角度來看,這些方法可以分為基于檢測的方法和無檢測的方法。
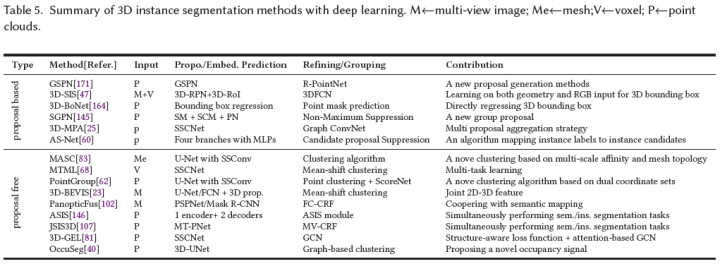
基于檢測的方法有時將目標Proposal定義為3D邊界框回歸問題。3D-SIS[47]基于3D重建的姿態對齊,將高分辨率RGB圖像與體素結合,并通過3D檢測主干聯合學習顏色和幾何特征,以預測3D目標框Proposal。在這些Proposal中,3D mask主干預測最終實例mask。其他相關算法[171]、[164]可以參考論文。
無檢測方法包括SGPN[145],它假定屬于同一目標實例的點云應該具有非常相似的特征。因此,它學習相似度矩陣來預測Proposal。這些Proposal通過置信度分數過濾,以生成高度可信的實例Proposal。然而,這種簡單的距離相似性度量學習并不能提供信息,并且不能分割同一類的相鄰目標。為此,3D-MPA[25]從投票給同一目標中心的采樣和聚類點云特征中學習目標Proposal,然后使用圖卷積網絡合并Proposal特征,從而實現Proposal之間的更高層次交互,從而優化Proposal特征。AS Net[60]使用分配模塊來分配Proposal候選,然后通過抑制網絡消除冗余候選。
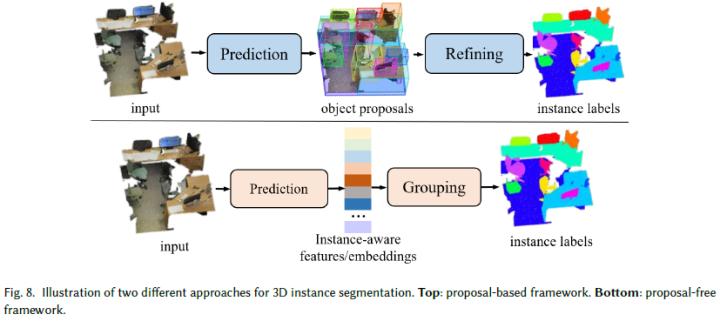
Proposal Free
無Proposal 方法學習每個點云的特征嵌入,然后使用聚類以獲得明確的3D實例標簽(見圖8),將任務分解為兩個主要挑戰。從嵌入學習的角度來看,這些方法可以大致分為三類:多嵌入學習、2D嵌入傳播和多任務學習。
多嵌入學習:MASC[83]等方法依靠SSCN[33]的高性能來預測多尺度和語義拓撲上相鄰點云之間的相似性嵌入。簡單而有效的聚類[89]適用于基于兩種類型的學習嵌入將點云分割為實例。MTML[68]學習兩組特征嵌入,包括每個實例唯一的特征嵌入和定向實例中心的方向嵌入,這提供了更強的聚類能力。類似地,PointGroup[62]基于原始坐標嵌入空間和偏移的坐標嵌入空間將點云聚類為不同的簇。
2D嵌入傳播:這些方法的一個例子是3D-BEVIS[23],它通過鳥瞰整個場景來學習2D全局實例嵌入。然后通過DGCN[149]將學習到的嵌入傳播到點云上。另一個例子是PanopticFusion[102],它通過2D實例分割網絡Mask R-CNN[43]預測RGB幀的逐像素實例標簽。
多任務聯合學習:3D語義分割和3D實例分割可以相互影響。例如,具有不同類的目標必須是不同的實例,具有相同實例標簽的目標必須為同一類。基于此,ASIS[146]設計了一個稱為ASIS的編碼器-解碼器網絡,以學習語義感知的實例嵌入,從而提高這兩個任務的性能。類似地,JSIS3D[107]使用統一網絡即MT-PNet來預測點云的語義標簽,并將點云嵌入到高維特征向量中,并進一步提出MV-CRF來聯合優化目標類和實例標簽。類似地,Liu等人[83]和3D-GEL[81]采用SSCN來同時生成語義預測和實例嵌入,然后使用兩個GCN來細化實例標簽。OccusSeg[40]使用多任務學習網絡來產生occupancy signal和空間嵌入。occupancy signal表示每個體素占用的體素數量。表5總結了3D實例分割方法。
3D部件分割
3D部件分割是繼實例分割之后的下一個更精細的級別,其目的是標記實例的不同部分。部件分割的管道與語義分割的管道非常相似,只是標簽現在是針對單個部件的。因此,一些現有的3D語義分割網絡[96]、[33]、[108]、[109]、[174]、[52]、[133]、[50]、[45]、[154]、[77]、[149]、[73]、[159]、[143]、[34]、[72]、[129]、[116]也可用于部件分割。然而,這些網絡并不能完全解決部件分割的困難。例如,具有相同語義標簽的各個部件可能具有不同的形狀,并且具有相同語義標記的實例的部件數量可能不同。我們將3D部件分割方法細分為兩類:基于規則數據的和基于不規則數據的,如下所示。
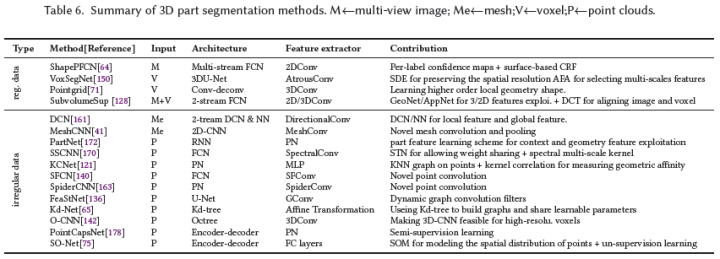
基于規則數據
規則數據通常包括投影圖像[64]、體素[150]、[71]、[128]。對于投影圖像,Kalogerakis等人[64]從多個視圖中獲得一組最佳覆蓋物體表面的圖像,然后使用多視圖全卷積網絡(FCN)和基于表面的條件隨機場(CRF)分別預測和細化部件標簽。體素是幾何數據的有效表示。然而,像部件分割這樣的細粒度任務需要具有更詳細結構信息的高分辨率體素,這導致了較高的計算成本。Wang等人[150]建議VoxSegNet利用有限分辨率的體素中更詳細的信息。它們在子采樣過程中使用空間密集提取來保持空間分辨率,并使用attention feature aggregation(AFA)模塊來自適應地選擇尺度特征。其他相關算法[71]、[128]可以參考論文。
基于不規則數據
不規則數據表示通常包括網格[161]、[41]和點云[75]、[121]、[170]、[136]、[140]、[172]、[178]。網格提供了3D形狀的有效近似,因為它捕捉到了平面、尖銳和復雜的表面形狀、表面和拓撲。Xu等人[161]將人臉法線和人臉距離直方圖作為雙流框架的輸入,并使用CRF優化最終標簽。受傳統CNN的啟發,Hanocka等人[41]設計了新穎的網格卷積和池化,以對網格邊緣進行操作。對于點云,圖卷積是最常用的管道。在頻譜圖領域,SyncSpecCNN[170]引入了同步頻譜CNN來處理不規則數據。特別地,提出了多通道卷積核和參數化膨脹卷積核,分別解決了多尺度分析和形狀信息共享問題。在空間圖域中,類似于圖像的卷積核,KCNet[121]提出了point-set kernel和nearest-neighbor-graph,以改進PointNet,使其具有高效的局部特征提取結構。其他相關算法[140]、[163]、[136]、[65]、[142]、[75]、[172]、[178]可以參考論文。3D部件的相關算法總結如下表所示。
3D分割的應用
無人駕駛系統
隨著激光雷達和深度相機的普及,價格也越來越實惠,它們越來越多地應用于無人駕駛系統,如自動駕駛和移動機器人。這些傳感器提供實時3D視頻,通常為每秒30幀(fps),作為系統的直接輸入,使3D視頻語義分割成為理解場景的主要任務。此外,為了更有效地與環境交互,無人系統通常會構建場景的3D語義圖。下面回顧基于3D視頻的語義分割和3D語義地圖構建。
3D視頻語義分割
與前文介紹的3D單幀/掃描語義分割方法相比,3D視頻(連續幀/掃描)語義分割方法考慮了幀之間連接的時空信息,這在穩健和連續地解析場景方面更為強大。傳統的卷積神經網絡(CNN)沒有被設計成利用幀之間的時間信息。一種常見的策略是自適應RNN([134]、[24])或時空卷積網絡([44]、[17]、[122])。
3D語義地圖重建
無人系統不僅需要避開障礙物,還需要建立對場景的更深理解,例如目標解析、自我定位等。3D場景重建通常依賴于同時定位和建圖系統(SLAM)來獲得沒有語義信息的3D地圖。隨后用2D-CNN進行2D語義分割,然后在優化(例如條件隨機場)之后將2D標簽轉移到3D地圖以獲得3D語義地圖[165]。這種通用管道無法保證復雜、大規模和動態場景中的3D語義地圖的高性能。研究人員已經努力使用來自多幀的關聯信息([92]、[95]、[157]、[13]、[66])、多模型融合([59]、[176])和新的后處理操作來增強魯棒性。
醫療診斷
2D U-Net[115]和3D U-Net[18]通常用于醫學圖像分割。基于這些基本思想,設計了許多改進的體系結構,主要可分為四類:擴展的3D U-Net([9]、[173]、[117])、聯合的2D-3D CNN([105]、[2]、[138]、[76])、帶優化模塊的CNN([99]、[179]、[126]、[104])和分層網絡([11]、[57]、[118]、[135]、[166]、[167]、[119])。
實驗結果
3D語義分割結果
論文報告了基于RGB-D的語義分割方法在SUN-RGB-D[127]和NYUDv2[124]數據集上的結果,使用mAcc和mIoU作為評估指標。各種方法的這些結果取自原始論文,如表7所示。下表所示。
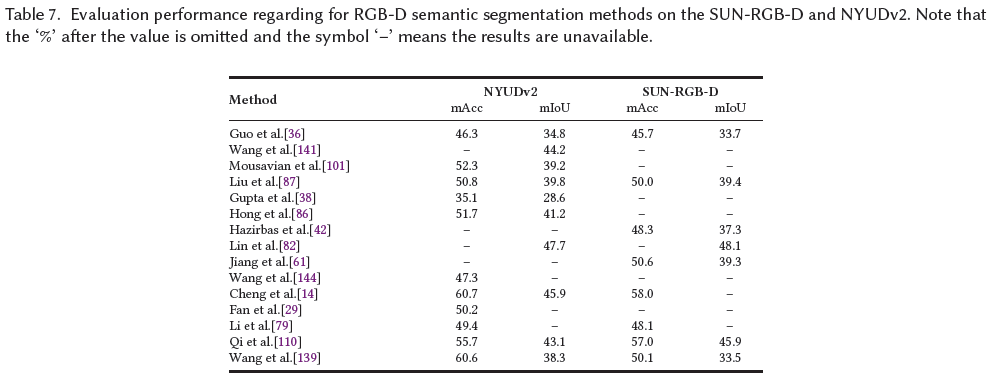
論文在S3DIS[1](5折和6折交叉驗證)、ScanNet[20](測試集)、Semantic3D[39](縮減的8個子集)和SemanticKITTI[3](僅xyz,無RGB)上報告了投影圖像/體素/點云/其他表示語義分割方法的結果。使用mAcc、oAcc和mIoU作為評估指標。這些不同方法的結果取自原始論文。表8列出了結果。
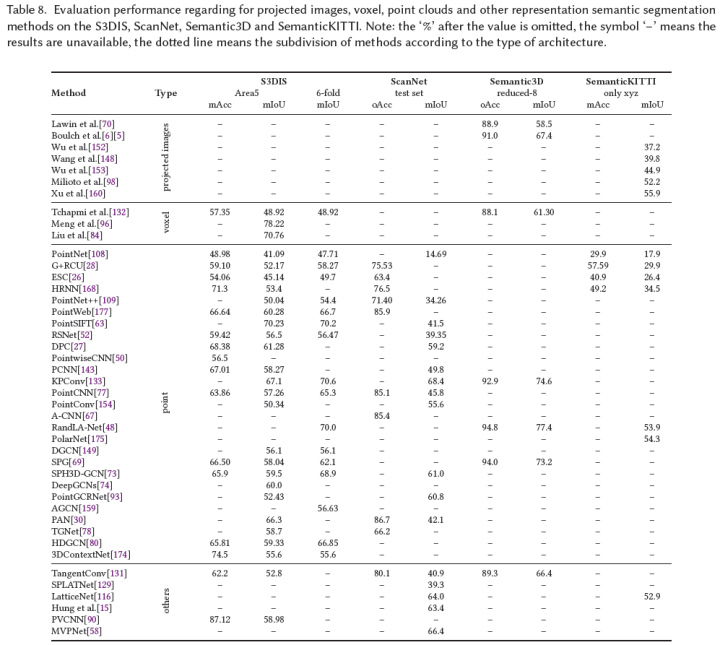
由于本文的主要興趣是基于點云的語義分割方法,因此重點對這些方法的性能進行詳細分析。為了捕獲對語義分割性能至關重要的更廣泛的上下文特征和更豐富的局部特征,在基本框架上提出了幾種專用策略。
基礎網絡是3D分割發展的主要推動力之一。一般來說,有兩個主要的基本框架,包括PointNet和PointNet++框架,它們的缺點也指出了改進的方向;
自然環境中的物體通常具有各種形狀。局部特征可以增強目標的細節分割;
3D場景中的目標可以根據與環境中的其他目標的某種關系來定位。已經證明,上下文特征(指目標依賴性)可以提高語義分割的準確性,特別是對于小的和相似的目標。
3D實例分割結果
論文報告了ScanNet[20]數據集上3D實例分割方法的結果,并選擇mAP作為評估指標。這些方法的結果取自ScanNet Benchmark Challenge網站,如表9所示,并在圖9中總結。該表和圖如下所示:
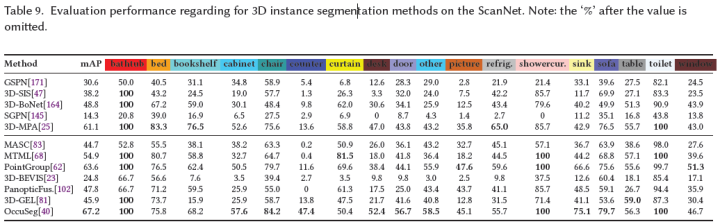
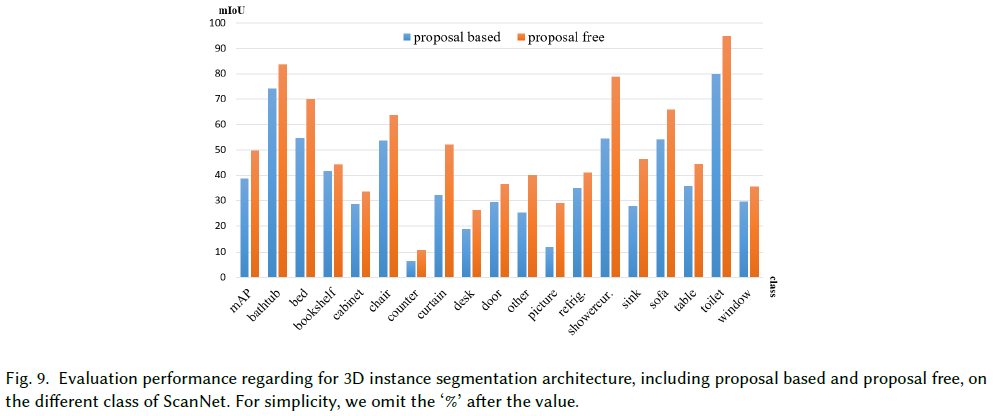
OccusSeg[40]具有最先進的性能,在本文調查時,ScanNet數據集的平均精度為67.2%;
大多數方法在諸如“浴缸”和“廁所”之類的大規模類上具有更好的分割性能,而在諸如“柜臺”、“桌子”和“圖片”之類的小規模類上具有較差的分割性能。因此,小目標的實例分割是一個突出的挑戰;
在所有類的實例分割方面,無Proposal方法比基于提案的方法具有更好的性能,尤其是對于“窗簾”、“其他”、“圖片”、“淋浴簾”和“水槽”等小目標;
在基于Proposal的方法中,基于2D嵌入傳播的方法,包括3D-BEVIS[23]、PanoticFusion[102],與其他基于無提案的方法相比,性能較差。簡單的嵌入傳播容易產生錯誤標簽。
3D部件分割結果
論文報告了ShapeNet[169]數據集上3D零件分割方法的結果,并使用了Ins.mIoU作為評估度量。各種方法的這些結果取自原始論文,如表10所示。我們可以看到:
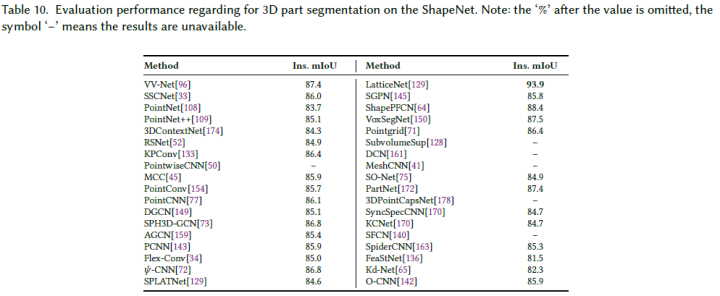
LatticeNet[40]具有最先進的性能,在本文調查時,ShapeNet數據集的平均精度為93.9%;
所有方法的部件分割性能非常相似。
討論和結論
論文使用深度學習技術,包括3D語義分割、3D實例分割和3D部件分割,對3D分割的最新發展進行了全面綜述。論文對每個類別中的各種方法進行了全面的性能比較和優點。近年來,使用深度學習技術的3D分割取得了重大進展。然而,這僅僅是一個開始,重要的發展擺在我們面前。下面,論文提出一些懸而未決的問題,并確定潛在的研究方向。
合成數據集為多個任務提供了更豐富的信息:與真實數據集相比,合成數據集成本低、場景多樣,因此在語義分割方面逐漸發揮重要作用[7]、[155]。眾所周知,訓練數據中包含的信息決定了場景解析精度的上限。現有的數據集缺少重要的語義信息,如材料和紋理信息,這對于具有相似顏色或幾何信息的分割更為關鍵。此外,大多數現有數據集通常是為單個任務設計的。目前,只有少數語義分割數據集還包含實例[20]和場景布局[127]的標簽,以滿足多任務目標。
多任務的統一網絡:對于一個系統來說,通過各種深度學習網絡來完成不同的計算機視覺任務是昂貴且不切實際的。對于場景的基本特征開發,語義分割與一些任務具有很強的一致性,例如深度估計[97]、[85]、[36]、[141]、[1141]、[87]、場景補全[22]、實例分割[146]、[107]、[81]和目標檢測[97]。這些任務可以相互協作,以提高統一網絡中的性能。語義/實例分割可以進一步與部件分割和其他計算機視覺任務相結合,用于聯合學習。
場景解析的多種模式:使用多個不同表示的語義分割,例如投影圖像、體素和點云,可能實現更高的精度。然而,由于場景信息的限制,如圖像的幾何信息較少,體素的語義信息較少,單一表示限制了分割精度。多重表示(多模態)將是提高性能的另一種方法[21],[15],[90],[58],[97]。
高效的基于點云卷積的網絡:基于點云的語義分割網絡正成為當今研究最多的方法。這些方法致力于充分探索逐點云特征和點云/特征之間的連接。然而,他們求助于鄰域搜索機制,例如KNN、ball query[109]和分層框架[154],這很容易忽略局部區域之間的低級特征,并進一步增加了全局上下文特征開發的難度。
弱監督和無監督的3D分割:深度學習在3D分割方面取得了顯著的成功,但嚴重依賴于大規模標記的訓練樣本。弱監督和無監督學習范式被認為是緩解大規模標記數據集要求的替代方法。目前,工作[162]提出了一個弱監督網絡,它只需要對一小部分訓練樣本進行標記。[75]、[178]提出了一種無監督網絡,該網絡從數據本身生成監督標簽。
大規模場景的語義分割一直是研究的熱點。現有方法僅限于極小的3D點云[108]、[69](例如,4096個點云或1x1米塊),在沒有數據預處理的情況下,無法直接擴展到更大規模的點云(例如,數百萬個點云或數百米)。盡管RandLA Net[48]可以直接處理100萬個點,但速度仍然不夠,需要進一步研究大規模點云上的有效語義分割問題。
3D視頻語義分割:與2D視頻語義分割一樣,少數作品試圖在3D視頻上利用4D時空特征(也稱為4D點云)[17],[122]。從這些工作中可以看出,時空特征可以幫助提高3D視頻或動態3D場景語義分割的魯棒性。
審核編輯 :李倩
-
3D
+關注
關注
9文章
2955瀏覽量
110156 -
數據集
+關注
關注
4文章
1223瀏覽量
25317 -
深度學習
+關注
關注
73文章
5557瀏覽量
122576
原文標題:史上最全 | 基于深度學習的3D分割綜述(RGB-D/點云/體素/多目)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一種以圖像為中心的3D感知模型BIP3D
3D IC背后的驅動因素有哪些?

對于結構光測量、3D視覺的應用,使用100%offset的lightcrafter是否能用于點云生成的應用?
SciChart 3D for WPF圖表庫
騰訊混元3D AI創作引擎正式發布
騰訊混元3D AI創作引擎正式上線
多維精密測量:半導體微型器件的2D&3D視覺方案
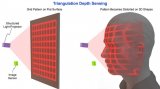
3D深度感測的原理和使用二極管激光來實現深度感測的優勢


歡創播報 騰訊元寶首發3D生成應用






 工商網監
工商網監
評論