 基于Transformer架構的文檔圖像自監督預訓練技術
基于Transformer架構的文檔圖像自監督預訓練技術
本文簡要介紹ACM MM 2022錄用論文“DiT: Self-supervised Pre-training for Document Image Transformer”[1]的主要工作。該論文是2022年微軟亞研院發表的LayoutLM V3[2]的前身工作,主要解決了文檔領域中標注數據稀少和以視覺為中心的文檔智能任務骨干網絡的預訓練問題。
一、研究背景
近年來自監督預訓練技術已在文檔智能領域進行了許多的實踐,大多數技術是將圖片、文本、布局結構信息一起輸入統一的Transformer架構中。在這些技術中,經典的流程是先經過一個視覺模型提取額外文檔圖片信息,例如OCR引擎或版面分析模型,這些模型通常依賴于有標注數據訓練的視覺骨干網絡。已有的工作已經證明一些視覺模型在實際應用中的性能經常受到域遷移、數據分布不一致等問題的影響。而且現有的文檔有標注數據集稀少、樣式單一,訓練出來的骨干網絡并非最適用于文檔任務。因此,有必要研究如何利用自監督預訓練技術訓練一個專用于文檔智能領域的骨干網絡。本文針對上述問題,利用離散變分編碼器和NLP領域的常用預訓練方式實現了文檔圖像的預訓練。

圖1具有不同布局和格式的視覺豐富的業務文檔,用于預培訓DiT
二、DiT原理簡述
2.1總體結構
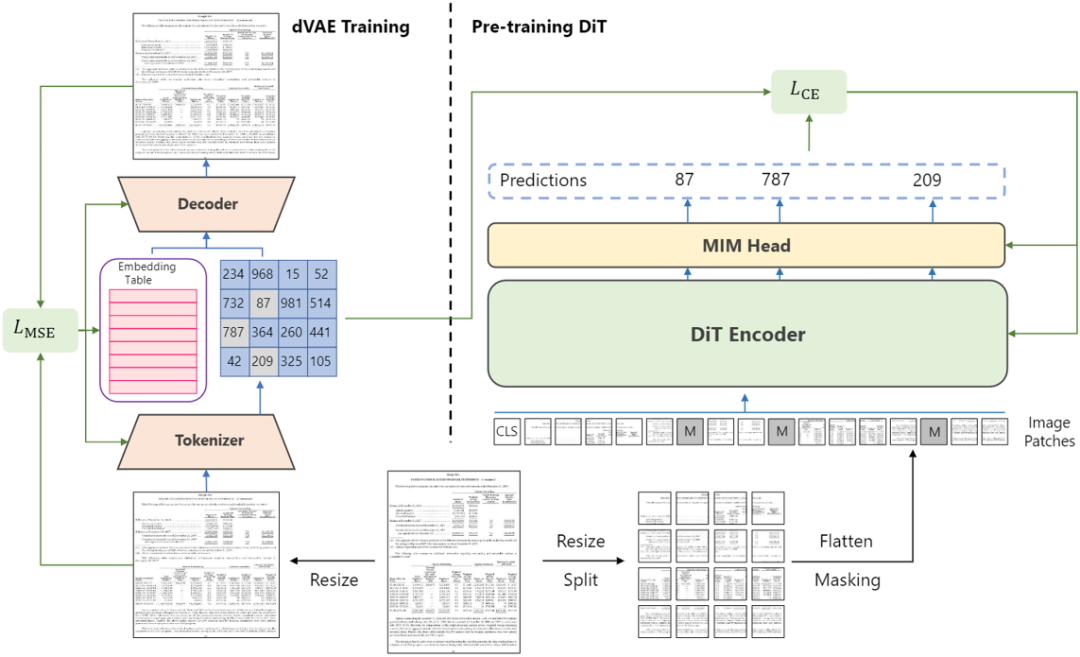
圖2 DiT的總體架構
Fig 2是DiT的整體結構。DiT使用ViT[3]作為預訓練的骨干網絡,模型的輸入是圖像Patch化后的Embedding特征向量,Patch的數量和離散變分編碼器的下采樣比例有關。輸入經過ViT后輸出到線性層進行圖像分類,分類層的大小是8192。預訓練任務和NLP領域的完型填空任務一致,先對輸入的Patch隨機掩膜,在模型輸出處預測被遮蓋的Patch對應的Token,Token由Fig 2 中左側的離散變分編碼器生成,作為每個Patch的Label,預訓練過程使用CE Loss監督。
2.2 離散變分編碼器dVAE
離散變分編碼器作為Image Tokenizer,將輸入的Patch Token化,來源于論文DALL-E[4],在預訓練任務開始前需要額外訓練。本文使用數據集IIT-CDIP[5]重新訓練了DALL-E中的離散變分編碼器以適用于文檔任務。在預訓練任務中只使用到編碼器的部分,解碼器不參與預訓練,編碼器將輸入圖片下采樣到原來的1/8,例如輸入尺度為112*112,那編碼后的Token Map為14*14,此時的Map大小,應與ViT輸入Patch數保持一致。
2.3 模型微調
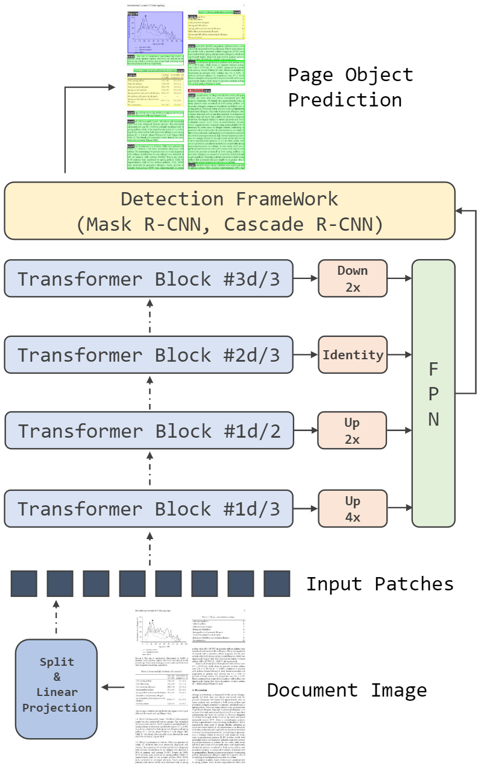
圖3在不同檢測框架中應用DiT作為骨干網絡的圖示
模型預訓練完成后,需針對下游任務進行微小的結構改動,針對分類任務,輸入經過平均池化和線性層進行分類。針對檢測任務,如Fig 3所示,在ViT的特定層進行下采樣或上采樣,然后輸入到FPN和后續的檢測框架中。
三、主要實驗結果及可視化效果
表1.RVL-CDIP上的文檔圖像分類精度(%),其中所有模型都使用224×224分辨率的純圖像信息(無文本信息)。
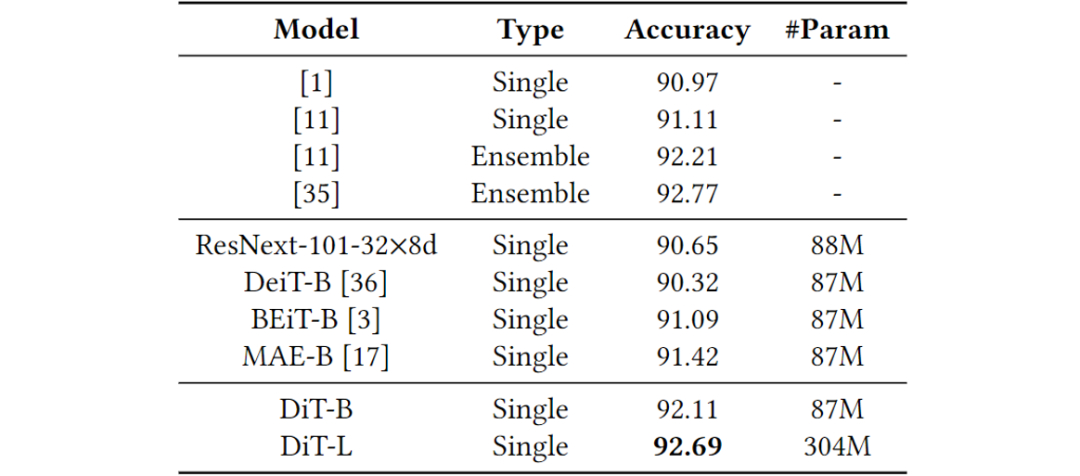
表2.PubLayNet驗證集上的文檔布局分析mAP@IOU[0.50:0.95]。ResNext-101-32×8d縮短為ResNext,級聯為C。
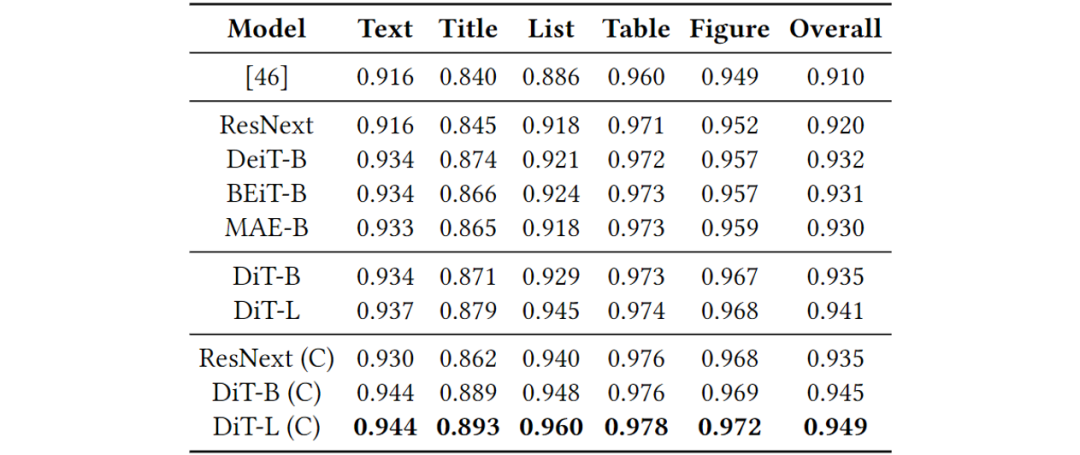
表3.ICDAR 2019 cTDaR的表檢測精度(F1)
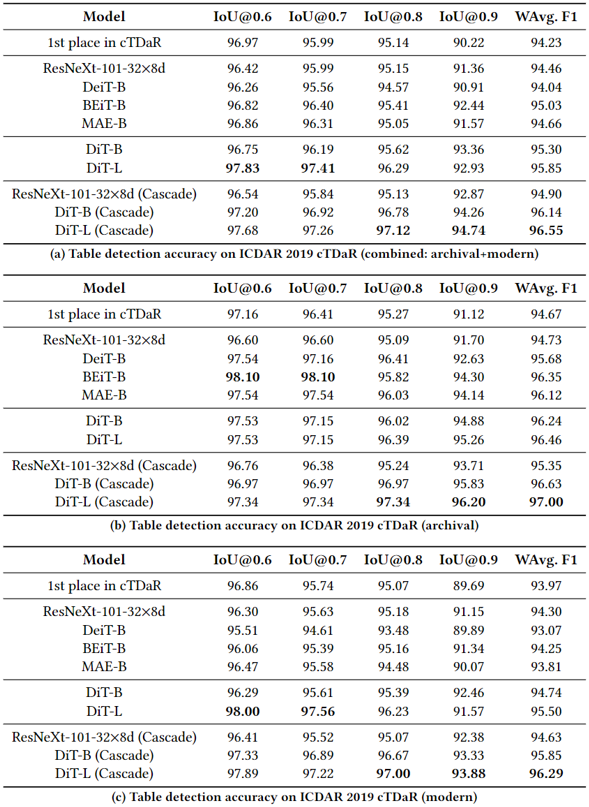
表4.文本檢測精度(IoU@0.5)在FUNSD任務#1中,掩碼R-CNN與不同的主干(ResNeXt、DeiT、BEiT、MAE和DiT)一起使用。“+syn”表示使用包含1M文檔圖像的合成數據集訓練DiT,然后使用FUNSD訓練數據進行微調。

圖4使用不同標記器進行圖像重建
從左到右:原始文檔圖像,使用自訓練dVAE標記器進行圖像重建,使用DALL-E標記器進行的圖像重建從表1、表2、表3、表4
來看,文章所提方法在各種下游任務中取得了state-of-the-art的結果,驗證了該方法在文檔領域的有效性。Fig 4中展示了重新訓練的離散變分編碼器的可視化輸出,結果顯示本文中的離散變分編碼器效果更好。
四、總結及討論
本文設計了一個利用大量無標簽文檔圖像預訓練ViT的自監督方法,該方法的核心是利用離散變分編碼器對圖像Patch進行Token化,再使用NLP領域的掩碼重建任務進行預訓練。從實驗結果可以看出,該方法在多個下游任務的有效性,探索了自監督任務在文檔領域的可能性。
審核編輯:郭婷
-
編碼器
+關注
關注
45文章
3780瀏覽量
137321 -
數據
+關注
關注
8文章
7246瀏覽量
91213
原文標題:上交&微軟提出DiT:一種基于Transformer的文檔圖像自監督預訓練方法 | ACM MM 2022
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Transformer架構概述

用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

用PaddleNLP在4060單卡上實踐大模型預訓練技術

Transformer是機器人技術的基礎嗎
時空引導下的時間序列自監督學習框架






 工商網監
工商網監
評論