") 芯片設計挑戰(zhàn):SRAM縮放速度變慢
芯片設計挑戰(zhàn):SRAM縮放速度變慢

如果 SRAM 縮放不可行,未來的芯片性能可能會受到阻礙。
幾乎所有處理器都依賴某種形式的 SRAM 緩存。緩存作為一種高速存儲解決方案,由于其緊鄰處理核心的戰(zhàn)略位置,訪問時間非常快。擁有快速且可訪問的存儲可以顯著提高處理性能,并減少核心工作所浪費的時間。 在第 68 屆年度 IEEE 國際 EDM 會議上,臺積電揭示了 SRAM 縮放方面的巨大問題。該公司正在為 2023 年開發(fā)的下一個節(jié)點 N3B 將包括與其前身 N5 相同的 SRAM 晶體管密度,后者用于 AMD 的Ryzen 7000 系列等 CPU 。 目前正在為 2024 年開發(fā)的另一個節(jié)點 N3E 并沒有好多少,其 SRAM 晶體管尺寸僅減少了 5%。
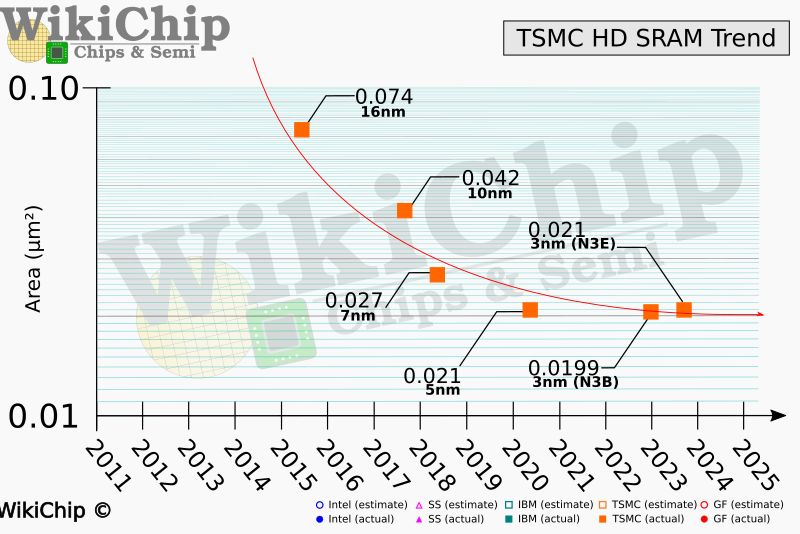
根據(jù) WikiChip 的一份報告,討論了半導體行業(yè)中 SRAM 收縮問題的嚴重性。臺積電的 SRAM Scaling 已經(jīng)大幅放緩。臺積電報告說,盡管邏輯晶體管密度繼續(xù)縮小,但其 SRAM 晶體管的縮放比例已經(jīng)完全趨于平穩(wěn),以至于 SRAM 緩存在多個節(jié)點上保持相同的大小。它會迫使處理器 SRAM 緩存在微芯片芯片上占用更多空間。這反過來可能會增加芯片的制造成本,并阻止某些微芯片架構(gòu)變得盡可能小。 對于未來的 CPU、GPU 和 SoC 來說,這是一個主要問題,由于 SRAM 單元面積縮放緩慢,它們可能會變得更加昂貴。
SRAM 縮放速度變慢
臺積電在今年早些時候正式推出其 N3 制造技術時表示,與其 N5(5 納米級)工藝相比,新節(jié)點的邏輯密度將提高 1.6 倍和 1.7 倍。它沒有透露的是,與 N5 相比,新技術的 SRAM 單元幾乎無法縮放。根據(jù) WikiChip,它從臺積電在國際電子設備會議 (IEDM) 上發(fā)表的一篇論文中獲得信息TSMC 的 N3 具有 0.0199μm2 的 SRAM 位單元尺寸,與 N5 的 0.021μm2SRAM 位單元相比僅小約 5%。改進后的 N3E 變得更糟,因為它配備了 0.021 μm2 SRAM 位單元(大致相當于 31.8 Mib/mm2),這意味著與 N5 相比根本沒有縮放。 同時,英特爾的 Intel 4(最初稱為 7nm EUV)將 SRAM 位單元大小從 0.0312μm2 減少到 0.024μm2,對于 Intel 7(以前稱為 10nm Enhanced SuperFin),我們?nèi)栽谡務?27.8 Mib/mm 2,這有點落后于 TSMC 的 HD SRAM 密度。 此外, WikiChip 回憶起 Imec 的演示文稿,該演示文稿顯示在帶有分支晶體管的“超過 2nm 節(jié)點”上的 SRAM 密度約為 60 Mib/mm2。這種工藝技術還需要數(shù)年時間,從現(xiàn)在到那時,芯片設計人員將不得不開發(fā)具有英特爾和臺積電宣傳的 SRAM 密度的處理器。
現(xiàn)代芯片中的 SRAM 負載
現(xiàn)代 CPU、GPU 和 SoC 在處理大量數(shù)據(jù)時將大量 SRAM 用于各種緩存,從內(nèi)存中獲取數(shù)據(jù)效率極低,尤其是對于各種人工智能 (AI) 和機器學習 (ML) 工作負載。但是現(xiàn)在即使是智能手機的通用處理器、圖形芯片和應用處理器也帶有巨大的緩存:AMD 的 Ryzen 9 7950X 總共帶有 81MB 的緩存,而 Nvidia 的 AD102 使用至少 123MB 的 SRAM 用于 Nvidia 公開披露的各種緩存。 展望未來,對緩存和 SRAM 的需求只會增加,但對于 N3(將僅用于少數(shù)產(chǎn)品)和 N3E,將無法減少 SRAM 占用的裸片面積并降低新的更高成本節(jié)點與 N5 相比。從本質(zhì)上講,這意味著高性能處理器的裸片尺寸將會增加,它們的成本也會增加。同時,就像邏輯單元一樣,SRAM 單元也容易出現(xiàn)缺陷。在某種程度上,芯片設計人員將能夠通過 N3 的 FinFlex 創(chuàng)新(在一個塊中混合和匹配不同種類的 FinFET 以優(yōu)化其性能、功率或面積)來減輕更大的 SRAM 單元。 臺積電計劃推出其密度優(yōu)化的 N3S 工藝技術,與 N5 相比,該技術有望縮小 SRAM 位單元的尺寸,但這將在 2024 年左右發(fā)生,我們想知道這是否會為 AMD、Apple 設計的芯片提供足夠的邏輯性能,英偉達和高通。
緩解措施
在成本方面緩解 SRAM 區(qū)域擴展放緩的方法之一是采用多小芯片設計,并將較大的緩存分解為在更便宜的節(jié)點上制造的單獨裸片。這是 AMD 對其 3D V-Cache 所做的事情,盡管原因略有不同。另一種方法是使用替代內(nèi)存技術,如 eDRAM 或 FeRAM 用于緩存,盡管后者有其自身的特點。 無論如何,在未來幾年,基于 FinFET 節(jié)點的 3nm 及更高節(jié)點的 SRAM 縮放速度放緩似乎是芯片設計人員面臨的主要挑戰(zhàn)。
編輯:黃飛
-
臺積電
+關注
關注
44文章
5755瀏覽量
169807 -
cpu
+關注
關注
68文章
11080瀏覽量
217090 -
gpu
+關注
關注
28文章
4948瀏覽量
131244 -
sram
+關注
關注
6文章
786瀏覽量
115962
原文標題:停止SRAM微縮,意味著更昂貴的CPU和GPU
文章出處:【微信號:ICViews,微信公眾號:半導體產(chǎn)業(yè)縱橫】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
AI推理的存儲,看好SRAM?
季豐推出SRAM錯誤地址定位黑科技
S32K312無法使用int_sram_shareable SRAM存儲數(shù)據(jù)怎么解決?
全球驅(qū)動芯片市場機遇與挑戰(zhàn)
在i.MX RT處理器上使用PXP實現(xiàn)縮放和旋轉(zhuǎn)組合操作
增加通道信號的時候,ADS1298的轉(zhuǎn)換數(shù)據(jù)的速度變慢,這是為什么?
影響25Q20D閃存芯片寫入速度和使用壽命的因素有哪些?

高帶寬Chiplet互連的技術、挑戰(zhàn)與解決方案

開源芯片系列講座第24期:基于SRAM存算的高效計算架構(gòu)

CV3600數(shù)字+模擬轉(zhuǎn)數(shù)字+模擬帶幀率和分辨率縮放的音視頻轉(zhuǎn)換芯片
SRAM和DRAM有什么區(qū)別
使用DSPLIB FFT實現(xiàn)實現(xiàn)實際輸入,無需數(shù)據(jù)縮放






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論