") Ampere的192核云原生CPU首度導入Chiplet設(shè)計
Ampere的192核云原生CPU首度導入Chiplet設(shè)計
Ampere Computing以自有IP打造的192核云原生CPU——AmpereOne系列處理器的技術(shù)細節(jié)陸續(xù)曝光。其中一個大亮點,是與上一代128核Ampere Altra對比,AmpereOne系列處理器中首度采用Chiplet設(shè)計。
半導體制程不斷演進下,要實現(xiàn)復雜的芯片設(shè)計流程的門檻其實越來越高,芯片全流程設(shè)計的成本也大幅增加,這是摩爾定律放緩后出現(xiàn)的問題。因應(yīng)方式是Chiplet小芯片設(shè)計的興起,已經(jīng)開始被AMD、英特爾等處理器大芯片公司大舉采用。
Chiplet是一種模塊化芯片的技術(shù),將傳統(tǒng)片上系統(tǒng)(SoC)所需的微處理器、模擬IP核、數(shù)字IP核和存儲器等模塊分開制造,并在后道工藝中集成為一個芯片模組,可實現(xiàn)不同模塊的混用、復用,且各模塊不需要在同一制程節(jié)點制造,因此另一個優(yōu)勢是能確保芯片的良率。
在AMD、英特爾陸續(xù)導入Chiplet設(shè)計后,Ampere Computing也在最新的AmpereOne系列處理器中實現(xiàn)Chiplet。
Ampere Computing首席產(chǎn)品官Jeff Wittich指出,Ampere開始大量采用小芯片的設(shè)計帶來了許多的優(yōu)勢,像是提升靈活度,以及加快了整個芯片設(shè)計周期。再者,采用Chiplet的設(shè)計也實現(xiàn)了特定的拓撲結(jié)構(gòu),以及單一的計算裸片(里邊分布著全部的內(nèi)核),同時還有單一大網(wǎng)格結(jié)構(gòu),助力為客戶提供平衡的高性能。反之,其他設(shè)計則要求數(shù)據(jù)從一個計算的小芯片傳輸?shù)搅硪粋€小芯片,這種設(shè)計會帶來延遲問題。
Jeff Wittich強調(diào),在實現(xiàn)了最佳的Chiplet架構(gòu)之后,產(chǎn)品上市的速度就會更快,且可以提供芯片的可擴展性。
過去幾年間,Ampere Computing已經(jīng)陸續(xù)實現(xiàn)的128核的Ampere Altra系列處理器,在云環(huán)境的關(guān)鍵指標——每機架性能方面超越其他競品像是英特爾和AMD等。這次全新的AmpereOne系列處理器是采用臺積電的5nm制程技術(shù),現(xiàn)在已投產(chǎn)并交付給客戶。
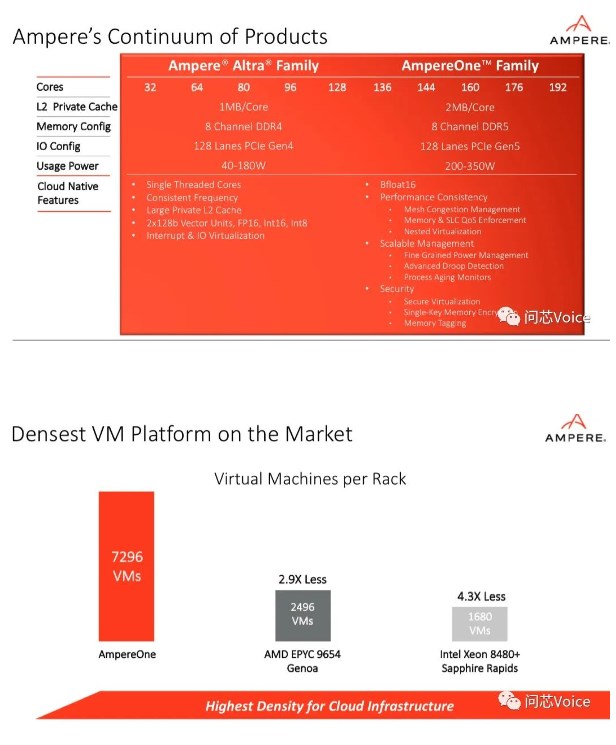
Jeff Wittich指出,AmpereOne能夠為云工作負載提供更高的性能、更高的可擴展性以及更高的密度,也是第一款基于Ampere新自研核的產(chǎn)品,由Ampere自有IP全新打造,擁有多達192個單線程Ampere核。
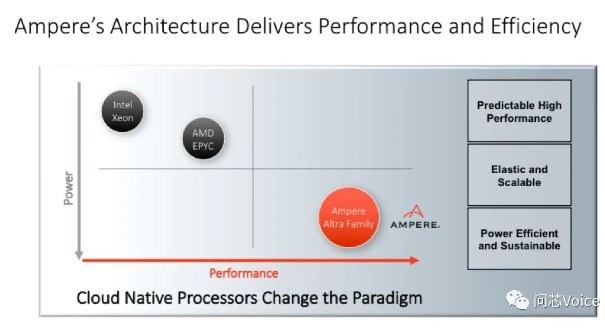
192 核是一個非常大的數(shù)字,比英特爾和 AMD 的核心數(shù)還要多。 Ampere用一個具體的場景來說明,比如在云環(huán)境中運行虛擬機(VM),用192核的AmpereOne對比96核的AMD Genoa,或者60核的英特爾Sapphire Rapids,AmpereOne每機架運行的虛擬機數(shù)量是AMD Genoa的2.9倍,是英特爾Sapphire Rapids的4.3倍。
AmpereOne推出后,與之前推出的Ampere Altra、Ampere Altra Max未來發(fā)展的差異性如何?
Jeff Wittich指出,這兩個系列服務(wù)于不同的客戶需求。目前已經(jīng)在市場上持續(xù)交付的Ampere Altra系列,里面包含了幾款不同的產(chǎn)品,核數(shù)從32核到128核不等。而全新推出的AmpereOne系列并不是要取代Ampere Altra系列,而是在它的原本的基礎(chǔ)之上,進行持續(xù)的擴張。
在未來很長一段時間里,Ampere Altra 系列處理器還會繼續(xù)銷售,而最新的AmpereOne是在Ampere Altra Max 128核的基礎(chǔ)上,將核數(shù)進一步提升到了最高可達192核。
客戶如何決定要采用AmpereOne?還是Ampere Altra?
他分析,完全是看場景應(yīng)用。在邊緣計算的場景下,可能只需要部署32核、功耗40瓦的Ampere Altra處理器就夠用了,但對于一些有更大算力需求的客戶,譬如大規(guī)模的數(shù)據(jù)中心,這時候更高的核數(shù)可以提供更好的性能,所以可能需要192核的AmpereOne系列處理器。
在AI方面,Ampere也提供了幾個參考的基準,一是在生成式AI方面,相比AMD Genoa,AmpereOne可每秒多提供2.3倍的幀數(shù)(圖像),在運行穩(wěn)定的擴散模型中勝出。此外,在運行DLRM模型的推薦系統(tǒng)中,通過AmpereOne響應(yīng)的查詢數(shù)量是AMD Genoa的每秒查詢數(shù)量的兩倍多。
此外,通過DDR5內(nèi)存技術(shù),以及128通道的PCIe 5.0的設(shè)計,AmpereOne系列處理器不僅實現(xiàn)了性能的擴展,也為云服務(wù)提供商和云工作負載提供價值。
由于新款的AmpereOne系列處理器是自研IP,是否會與上一代Ampere Altra系列有不相容的問題? Jeff Wittich表示,不會存在兼容性的問題,因為兩款處理器都是基于ARM ISA的。所有能夠在Ampere Altra系列處理器上運行的代碼,在AmpereOne上運行也沒有問題,不需要任何改動。
針對進行火爆的生成式AI對數(shù)據(jù)中心CPU市場的影響? Jeff Wittich表示,生成式AI進一步加速了市場對算力的需求。
他分析,針對AI工作負載最常見的有兩大場景,第一是AI訓練工作負載,即處理器在大量數(shù)據(jù)的基礎(chǔ)上建立模型,對于某些大模型來說,過程有時候不只需要幾個小時、幾天,甚至可能要花上數(shù)周甚至數(shù)月的時間。第二個場景就是AI推理,即在完成AI訓練的基礎(chǔ)上,在應(yīng)用上去運行模型。
雖然可能訓練AI模型只需要一次,但是運行模型還需要進行上百萬次甚至數(shù)十億次,這些工作負載需要進行非常快速的運行,以盡可能快的速度向用戶交付數(shù)據(jù)和資源。
AI訓練和AI推理的工作負載是非常不一樣的。 AI訓練發(fā)生在服務(wù)器上的CPU、GPU,但是AI推理不一樣,它擴展在整個云的部署中。這就意味著它對云的基礎(chǔ)建設(shè)提出了更高的要求。
所以AI訓練和AI推理有三個主要不同,一個是就規(guī)模而言,AI推理需要更大的規(guī)模;第二,AI推理很有可能在通用服務(wù)器上和其他工作負載同時運行;第三,AI推理對速度的要求更高,而且還需要不斷地進行大量重復,以向用戶快速交付結(jié)果。
Jeff Wittich表示,無論是Ampere Altra還是AmpereOne系列處理器都非常適用于AI推理,特別是大規(guī)模的云場景。目前,已經(jīng)有許多客戶都在使用Ampere Altra系列處理器進行AI推理,并且得到我們Library中很多軟件工具的支持,包括TensorFlow、PyTorch、ONNX常用的主流框架。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
19825瀏覽量
233779 -
片上系統(tǒng)
+關(guān)注
關(guān)注
0文章
188瀏覽量
27216 -
虛擬機
+關(guān)注
關(guān)注
1文章
963瀏覽量
29126 -
chiplet
+關(guān)注
關(guān)注
6文章
453瀏覽量
12891
原文標題:媒體視角|Ampere的192核云原生CPU首度導入Chiplet設(shè)計
文章出處:【微信號:AmpereComputing,微信公眾號:安晟培半導體】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
云原生在汽車行業(yè)的優(yōu)勢
云原生AI服務(wù)怎么樣
Ampere發(fā)布最新192核12內(nèi)存通道AmpereOne M處理器
云原生LLMOps平臺作用
如何選擇云原生機器學習平臺
構(gòu)建云原生機器學習平臺流程
什么是云原生MLOps平臺
梯度科技入選2024云原生企業(yè)TOP50榜單
軟通動力榮登2024云原生企業(yè)TOP50榜單
云原生和數(shù)據(jù)庫哪個好一些?
k8s微服務(wù)架構(gòu)就是云原生嗎?兩者是什么關(guān)系
云原生和非云原生哪個好?六大區(qū)別詳細對比
京東云原生安全產(chǎn)品重磅發(fā)布
從積木式到裝配式云原生安全
基于DPU與SmartNic的云原生SDN解決方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論