") 理解指向,說出坐標(biāo),Shikra開啟多模態(tài)大模型參考對(duì)話新維度
理解指向,說出坐標(biāo),Shikra開啟多模態(tài)大模型參考對(duì)話新維度

在人類的日常交流中,經(jīng)常會(huì)關(guān)注場(chǎng)景中不同的區(qū)域或物體,人們可以通過說話并指向這些區(qū)域來進(jìn)行高效的信息交換。這種交互模式被稱為參考對(duì)話(Referential Dialogue)。
如果 MLLM 擅長(zhǎng)這項(xiàng)技能,它將帶來許多令人興奮的應(yīng)用。例如,將其應(yīng)用到 Apple Vision Pro 等混合現(xiàn)實(shí) (XR) 眼鏡中,用戶可以使用視線注視指示任何內(nèi)容與 AI 對(duì)話。同時(shí) AI 也可以通過高亮等形式來指向某些區(qū)域,實(shí)現(xiàn)與用戶的高效交流。
本文提出的Shikra 模型,就賦予了 MLLM 這樣的參考對(duì)話能力,既可以理解位置輸入,也可以產(chǎn)生位置輸出。

-
論文地址:http://arxiv.org/abs/2306.15195
-
代碼地址:https://github.com/shikras/shikra
核心亮點(diǎn)
Shikra 能夠理解用戶輸入的 point/bounding box,并支持 point/bounding box 的輸出,可以和人類無縫地進(jìn)行參考對(duì)話。
Shikra 設(shè)計(jì)簡(jiǎn)單直接,采用非拼接式設(shè)計(jì),不需要額外的位置編碼器、前 / 后目標(biāo)檢測(cè)器或外部插件模塊,甚至不需要額外的詞匯表。

如上圖所示,Shikra 能夠精確理解用戶輸入的定位區(qū)域,并能在輸出中引用與輸入時(shí)不同的區(qū)域進(jìn)行交流,像人類一樣通過對(duì)話和定位進(jìn)行高效交流。

如上圖所示,Shikra 不僅具備 LLM 所有的基本常識(shí),還能夠基于位置信息做出推理。

如上圖所示,Shikra 可以對(duì)圖片中正在發(fā)生的事情產(chǎn)生詳細(xì)的描述,并為參考的物體生成準(zhǔn)確的定位。

盡管Shikra沒有在 OCR 數(shù)據(jù)集上專門訓(xùn)練,但也具有基本的 OCR 能力。
更多例子

其他傳統(tǒng)任務(wù)

方法
模型架構(gòu)采用 CLIP ViT-L/14 作為視覺主干,Vicuna-7/13B 作為基語言模型,使用一層線性映射連接 CLIP 和 Vicuna 的特征空間。
Shikra 直接使用自然語言中的數(shù)字來表示物體位置,使用 [xmin, ymin, xmax, ymax] 表示邊界框,使用 [xcenter, ycenter] 表示區(qū)域中心點(diǎn),區(qū)域的 xy 坐標(biāo)根據(jù)圖像大小進(jìn)行歸一化。每個(gè)數(shù)字默認(rèn)保留 3 位小數(shù)。這些坐標(biāo)可以出現(xiàn)在模型的輸入和輸出序列中的任何位置。記錄坐標(biāo)的方括號(hào)也自然地出現(xiàn)在句子中。
實(shí)驗(yàn)結(jié)果
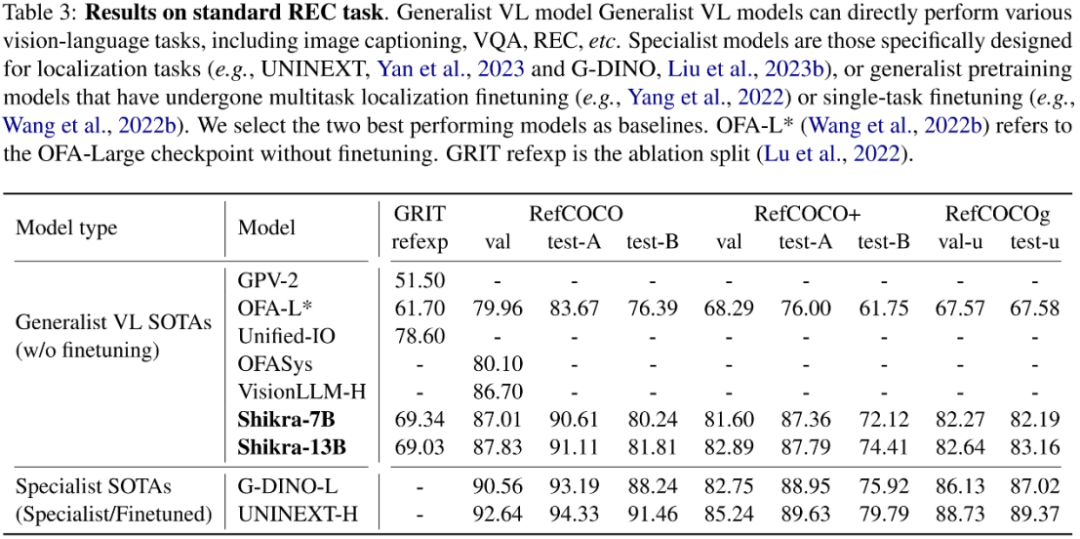
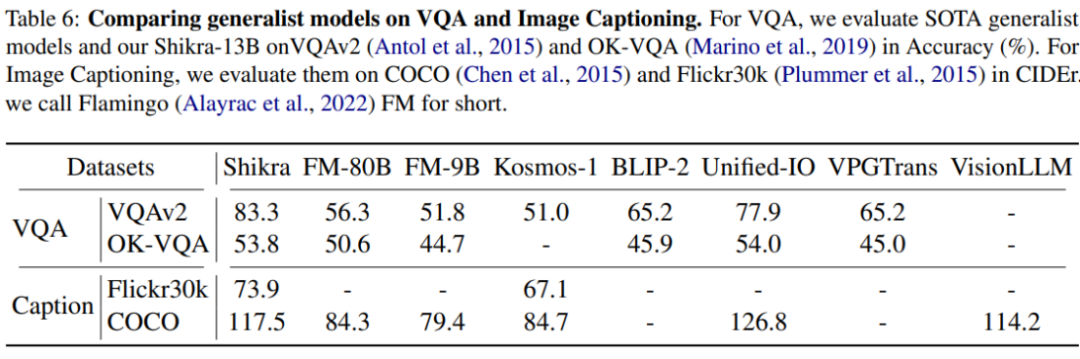
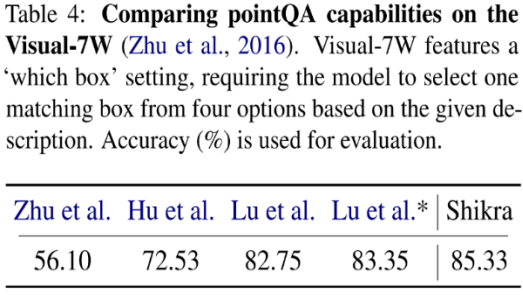
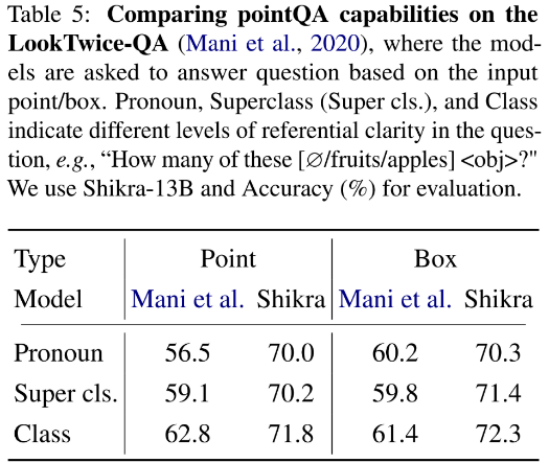
Shikra 在傳統(tǒng) REC、VQA、Caption 任務(wù)上都能取得優(yōu)良表現(xiàn)。同時(shí)在 PointQA-Twice、Point-V7W 等需要理解位置輸入的 VQA 任務(wù)上取得了 SOTA 結(jié)果。
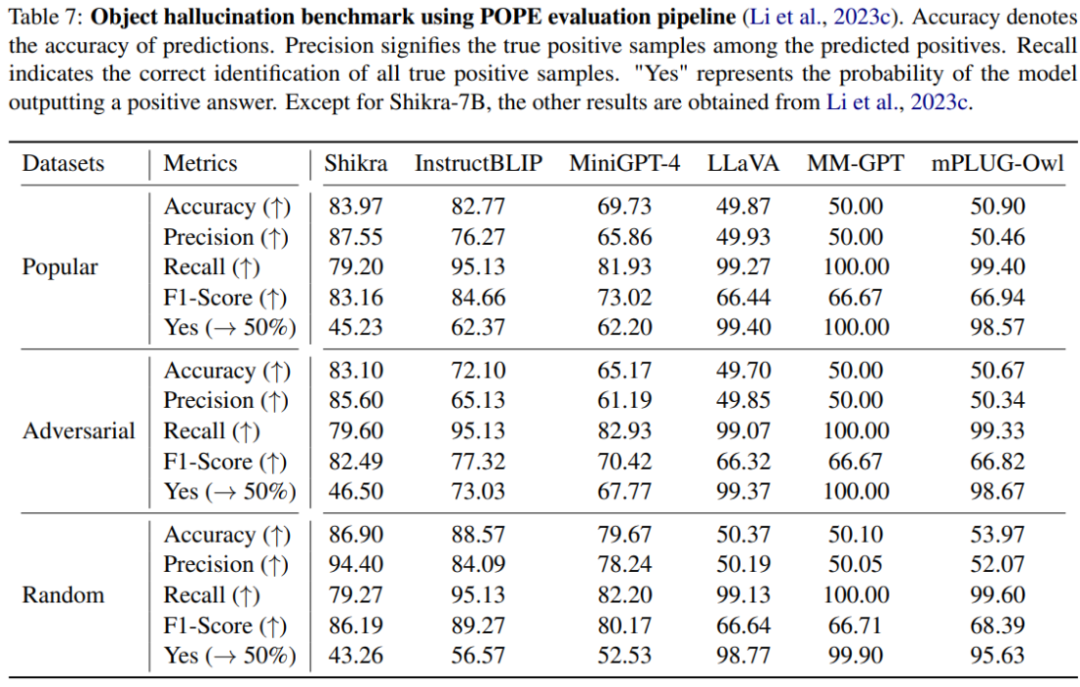
本文使用 POPE benchmark 評(píng)估了 Shikra 產(chǎn)生幻覺的程度。Shikra 得到了和 InstrcutBLIP 相當(dāng)?shù)慕Y(jié)果,并遠(yuǎn)超近期其他 MLLM。
思想鏈(CoT),旨在通過在最終答案前添加推理過程以幫助 LLM 回答復(fù)雜的 QA 問題。這一技術(shù)已被廣泛應(yīng)用到自然語言處理的各種任務(wù)中。然而如何在多模態(tài)場(chǎng)景下應(yīng)用 CoT 則尚待研究。尤其因?yàn)槟壳暗?MLLM 還存在嚴(yán)重的幻視問題,CoT 經(jīng)常會(huì)產(chǎn)生幻覺,影響最終答案的正確性。通過在合成數(shù)據(jù)集 CLEVR 上的實(shí)驗(yàn),研究發(fā)現(xiàn),使用帶有位置信息的 CoT 時(shí),可以有效減少模型幻覺提高模型性能。

結(jié)論
本文介紹了一種名為 Shikra 的簡(jiǎn)單且統(tǒng)一的模型,以自然語言的方式理解并輸出空間坐標(biāo),為 MLLM 增加了類似于人類的參考對(duì)話能力,且無需引入額外的詞匯表、位置編碼器或外部插件。
THE END
原文標(biāo)題:理解指向,說出坐標(biāo),Shikra開啟多模態(tài)大模型參考對(duì)話新維度
文章出處:【微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2930文章
46219瀏覽量
392192
原文標(biāo)題:理解指向,說出坐標(biāo),Shikra開啟多模態(tài)大模型參考對(duì)話新維度
文章出處:【微信號(hào):tyutcsplab,微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
商湯日日新SenseNova融合模態(tài)大模型 國(guó)內(nèi)首家獲得最高評(píng)級(jí)的大模型
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態(tài)大模型

基于MindSpeed MM玩轉(zhuǎn)Qwen2.5VL多模態(tài)理解模型

海康威視發(fā)布多模態(tài)大模型AI融合巡檢超腦
移遠(yuǎn)通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗(yàn)

海康威視發(fā)布多模態(tài)大模型文搜存儲(chǔ)系列產(chǎn)品

商湯日日新多模態(tài)大模型權(quán)威評(píng)測(cè)第一
一文理解多模態(tài)大語言模型——下

一文理解多模態(tài)大語言模型——上

利用OpenVINO部署Qwen2多模態(tài)模型
云知聲山海多模態(tài)大模型UniGPT-mMed登頂MMMU測(cè)評(píng)榜首






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論