") NOP+:追求連續(xù)的點到點駕駛體驗
NOP+:追求連續(xù)的點到點駕駛體驗

智能駕駛時代離不開“規(guī)控”,但對用戶而言,“規(guī)控”可能是一個既陌生,卻又帶有很強技術感知的詞語。
本期Tech Talk,由蔚來自動駕駛研發(fā)部門規(guī)控團隊的Blake FAN、Eason QIN,以及全域智能駕駛體驗團隊的Simon WANG,為我們解讀“規(guī)控”的開發(fā)邏輯,揭秘NOP+增強領航輔助是如何“開車”的。
什么是決策規(guī)劃控制算法?
規(guī)控的全稱——決策規(guī)劃控制算法,對外簡稱“規(guī)控”,它是智能駕駛系統(tǒng)的核心組成部分之一。
Aquila蔚來超感系統(tǒng),
擁有包括超遠距高精度激光雷達
在內的33個高性能感知硬件
如果把Aquila蔚來超感系統(tǒng)比喻為智能駕駛系統(tǒng)的眼睛,那么規(guī)控就是智能駕駛系統(tǒng)大腦一般的存在。它的職責,是負責安全且平穩(wěn)地駕駛車輛,讓用戶享受輕松、愉悅的出行體驗。
簡單而言,規(guī)控算法決定了自車應該何時讓行切入車輛、何時變道,以及何時進出匝道;這些駕駛行為指令會傳遞給車輛控制端,實現(xiàn)細膩的、毫秒級的方向盤轉角以及加減速控制。
因此,規(guī)控的聰明程度也決定了智能駕駛系統(tǒng)的舒適性和通行效率的平衡。
如何成為一個優(yōu)秀的規(guī)控算法?
智能駕駛系統(tǒng)能夠像人一樣實現(xiàn)自如地開車,至少需要滿足兩個條件。
第一,是否能夠像人一樣獲取周圍的環(huán)境信息;第二,則是構建像人一樣的思考方式和駕駛行為。
NOP+增強領航輔助功能開啟狀態(tài)
關于智能駕駛系統(tǒng)對自車周圍環(huán)境的感知,可以在《蔚來眼中的世界,有多特別?》這篇文章里找到答案。不過要讓其構建像人一樣的思考方式,就需要投入研發(fā)精力,至少做到以下兩點。
第一,理解什么是優(yōu)秀的駕駛行為。
優(yōu)秀的駕駛行為由諸多要素組成,其中最重要的就是安全。智能駕駛狀態(tài)下的車輛,需要在復雜的環(huán)境中保持和其他交通參與者安全的交互,盡可能地平穩(wěn)駕駛,并且高效的到達終點。因此,安全、平穩(wěn)和高效,這三點就成為了智能駕駛規(guī)控模塊的開發(fā)目標。
第二,構建類人的駕駛思考方式。
這一點尤為重要。智能駕駛系統(tǒng)需要模仿人類駕駛員的思維方式,比如在獲知駕駛目的地信息(導航),當前所處位置(定位),和周圍環(huán)境信息(地圖,感知)后,要進行分層級思考。
這個思考的過程可以分為三個階段,比如思考是否該進行超車、讓行、換道的決策規(guī)劃階段;思考安全、舒適、高效的運行軌跡規(guī)劃階段;以及車輛如何執(zhí)行指令的控制階段。
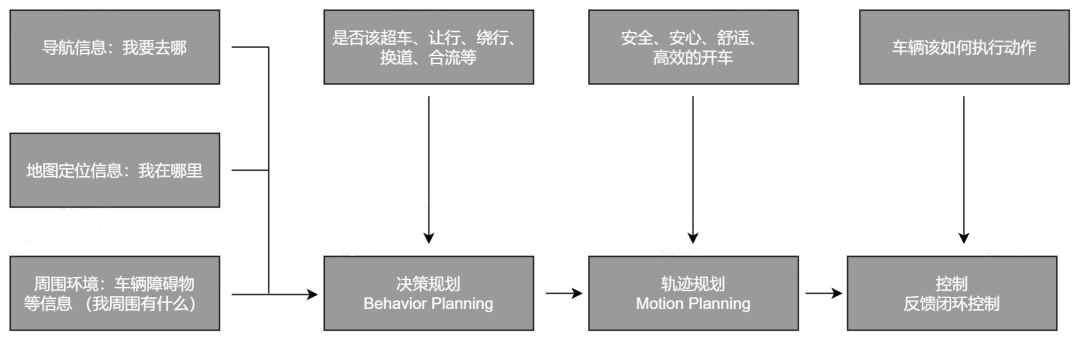
智能駕駛系統(tǒng)規(guī)控工作流
基于上述三個層級的思考,接下來為大家展開詳細聊一聊。
首先,我們來拆解決策規(guī)劃(Behavior Planning)。NOP+的決策規(guī)劃不僅包含對周圍其他交通參與者行為的預測,也包含自車行為對周圍環(huán)境造成的影響。對所有這些自身和其他因素進行整體建模,便構成了NOP+的決策預測一體化。
好比棋手對弈,我們無法百分百精確預測對手下一步到底會怎么走,但通過對棋局當前形勢的推演,優(yōu)秀的棋手知道怎么出手會獲得更高的勝率。因此,智能駕駛系統(tǒng)的決策目標就是更加細致、深入地判斷“棋盤的‘勢’”,即形勢和收益。
為了能得到更高的勝率,智能駕駛車輛需要精確的識別與認知周圍環(huán)境——類似棋盤中棋子的擺放位置;以及和障礙物之間的博弈關系——下這步棋后對手會怎么落子;在思考完成后需要在有限時間里選擇合適的響應行為——下棋的策略。
在下面這個換道場景中,NOP+的算法在識別到前方慢車以及左方、右方和后方的車輛、環(huán)境信息后,會“觀察形勢”,推演執(zhí)行不同駕駛行為可能發(fā)生的結果。

這就是“博弈推演”,權衡利弊后,最后以安全、舒適的方式完成換道。
NOP+的決策算法需要考慮環(huán)境中所有可能發(fā)生交互的障礙物,當環(huán)境發(fā)生變化時,交互決策需要考慮的因素將會以指數(shù)級別增加。
比如在當前時刻,有10個障礙物需要考慮是否避讓,那么決策的復雜度是2^10=1,024;在接下來(1秒、2秒......5秒)的每一個時刻是否要進行避讓時,復雜度將會變成1,024^5,大約是10^15。
優(yōu)秀的司機往往能夠通過預判性駕駛來降低風險,提高通行效率和舒適性。因此,思考得越深,NOP+的駕駛行為預判就越好。
一個優(yōu)秀的棋手,每次落子前大約會推演5-8個回合的“博弈”,而智能駕駛需要在<0.1秒的時間內完成更復雜的推演。為了能在超過10^15量級的策略中快速找到最優(yōu)解決方案,除了更強的硬件算力,更重要的是NOP+規(guī)控算法的設計與提升。
事實上,NOP+的決策算法用百萬量級的自動駕駛數(shù)據(jù)進行不斷的訓練學習,總結出“定勢”并記錄下來,從而在決策樹中實現(xiàn)快速精準的搜索。我們將這個過程稱為:價值網絡學習(Deep Learning Policy Network),即通過深度學習網絡,去學習優(yōu)秀司機對于駕駛交互的判斷邏輯。
隨著系統(tǒng)硬件能力的提升和數(shù)據(jù)的積累,在NOP+決策系統(tǒng)中考慮的因素也會更加的細化,從而能在千變萬化的世界中尋找出最優(yōu)的決策。
在拆解決策規(guī)劃后,我們來看看運動軌跡規(guī)劃(Motion Planning)是如何工作的。
當車輛得到最優(yōu)決策后,運動軌跡規(guī)劃模塊需要將其轉化為車輛可以執(zhí)行的行駛路徑。一個好的行駛路徑需要在安全的條件下盡量優(yōu)化路徑的安全度,平滑性以及通行效率。
比如以下?lián)矶聢鼍案5膱鼍爸校囕v在規(guī)劃合理的剎車力度時,不僅需要考慮前車的距離,也要盡可能的優(yōu)化減速度的變化幅度,做到安全平穩(wěn)舒適的剎停和起步(如Gif圖中左下方平滑的藍色加減速曲線)。

優(yōu)秀的駕駛是在安全、遵守交通規(guī)則的前提下,盡量在效率和舒適中達到平衡。但是在不同場景中,效率和舒適的平衡又是不一樣的。
比如北京、上海的道路和鄉(xiāng)村道路就很不一樣。在擁堵環(huán)境下,普通的城市道路和環(huán)路、高架又有很大區(qū)別。因此需要通過數(shù)據(jù)分析更深層次地理解周圍環(huán)境,在諸多因素中自適應地去調節(jié)平衡關系。
例如,在Banyan 2.0.0的擁堵跟車場景中,系統(tǒng)通過大量數(shù)據(jù)學習老司機開車的駕駛方式,從而獲得安全、平穩(wěn)、舒適的駕駛體驗,隨著數(shù)據(jù)的積累,體驗還可以不斷進化。
最后一個層級,則是對指令的控制(Control)。在系統(tǒng)做出運動軌跡規(guī)劃后,需要控制讓車輛按照預判完成相應的動作。“控制”會系統(tǒng)性閉環(huán)考慮車輛的運動狀態(tài),以便更好地執(zhí)行指令,達到“手腦一致”。
NOP+:追求連續(xù)的點到點駕駛體驗
傳統(tǒng)的輔助駕駛研發(fā),往往以單一功能為原點(例如大家熟悉的ACC自適應巡航,LKA車道保持輔助,LCC車道居中輔助等),實現(xiàn)特定場景下的輔助駕駛。
但是,做好每一個單點功能,是否就能夠算智能駕駛?答案是否定的,現(xiàn)實遠比想象的更難!
首先,現(xiàn)實中的場景往往更復雜,要求有多個單點功能的組合。試想一下人類的駕駛行為,變道時目標車道有前后車的情況下,不僅僅要考慮變道的空間是否足夠,還需要考慮前后車未來的運動軌跡和速度變化。

除了思考復雜的道路場景,
NOP+還會根據(jù)天氣因素來控制車速,
安全始終是擺在首位的
如果此時第三車道也同時有車變道匯入呢?如果變道發(fā)生在匯入口附近呢?多種場景組合在一起會讓功能開發(fā)的復雜度呈現(xiàn)指數(shù)型的上升。
其次,場景變化存在連續(xù)性。單點開發(fā)的功能往往存在功能或狀態(tài)的離散變化,在適配體驗的過程中銜接并不連續(xù)。比如,單點開發(fā)上下匝道會由于狀態(tài)的切換導致成功率下降。
NOP+通過整體開發(fā)統(tǒng)一建模的方式克服了上述痛點。就好像2000年初的手機智能化,廠商往往以某一個功能,如發(fā)短信、打電話、玩游戲、發(fā)郵件的角度進行功能開發(fā),而今天大家顯然聚焦在打造一個高效互通的平臺系統(tǒng)上。
實際上,我們就致力于將規(guī)劃控制模塊打造成類似的平臺。它能夠覆蓋更多的功能,接受不同的感知源輸入,在硬件不斷迭代和數(shù)據(jù)不斷積累的基礎上,還能讓規(guī)劃控制算法自主進化和學習,為適配更復雜的駕駛場景提供底層原子化的能力和操作系統(tǒng)。
通過解讀“規(guī)控”的開發(fā)邏輯,不難發(fā)現(xiàn),一套優(yōu)秀的規(guī)控算法能為智能駕駛系統(tǒng)賦予思考邏輯,這也是NOP+能夠脫穎而出的關鍵。
最后,再分享一組數(shù)據(jù)給大家。截至2023年8月,NOP+累計使用里程超過8,300萬公里,當下它正以每周超過500萬公里的速度快速“成長”。
NOP+的目標很清晰,就是為用戶在日常通勤及長途出行中,提供更安全、輕松、愉悅的駕駛體驗。
審核編輯:彭菁
-
硬件
+關注
關注
11文章
3481瀏覽量
67442 -
智能駕駛
+關注
關注
4文章
2805瀏覽量
49912 -
激光雷達
+關注
關注
971文章
4231瀏覽量
192716 -
蔚來
+關注
關注
1文章
534瀏覽量
14912
原文標題:NOP+是如何“開車”的?
文章出處:【微信號:NIO-Wechat,微信公眾號:蔚來】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
MAX9169/MAX9170 4端口LVDS和LVTTL至LVDS轉發(fā)器技術手冊
ADRF6780 5.9 至23.6GHz、寬帶微波上變頻器技術手冊
HMC1131 GaAs、pHEMT、MMIC、中等功率放大器,24GHz至35GHz技術手冊

蔚來輔助駕駛連續(xù)兩個月單月里程破1億公里
ADRF6780 5.9 GHz至23.6GHz、寬帶微波上變頻器技術手冊
接收方數(shù)據(jù)解封裝解析
使用PIC的32位單片機控制ADS8361,連續(xù)采集ADS8361的輸出其中有好幾對一模一樣的數(shù)據(jù),為什么?
工程師必須掌握的PCB專業(yè)術語

阿爾泰科技DAM-3220隔離RS-485中繼模塊






 工商網監(jiān)
工商網監(jiān)
評論