") 什么是多模態(tài)?多模態(tài)的難題是什么?
什么是多模態(tài)?多模態(tài)的難題是什么?

作者:Peter,北京郵電大學(xué) · 計(jì)算機(jī)
什么是多模態(tài)?
如果把LLM比做關(guān)在籠子里的AI,那么它和世界交互的方式就是通過(guò)“遞文字紙條”。文字是人類對(duì)世界的表示,存在著信息提煉、損失、冗余、甚至錯(cuò)誤(曾經(jīng)的地心說(shuō))。而多模態(tài)就像是讓AI繞開(kāi)了人類的中間表示,直接接觸世界,從最原始的視覺(jué)、聲音、空間等開(kāi)始理解這個(gè)世界,改變世界。
好像并沒(méi)有對(duì)多模態(tài)的嚴(yán)謹(jǐn)定義。通常見(jiàn)到的多模態(tài)是聯(lián)合建模Language、Vision、Audio。而很多時(shí)候拓展到3d, radar, point cloud, structure (e.g. layout, markup language)。
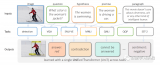
模型經(jīng)歷了從傳統(tǒng)單模態(tài)模型,到通用單模態(tài),再到通用多模態(tài)的一個(gè)大致的發(fā)展,大致如下圖:
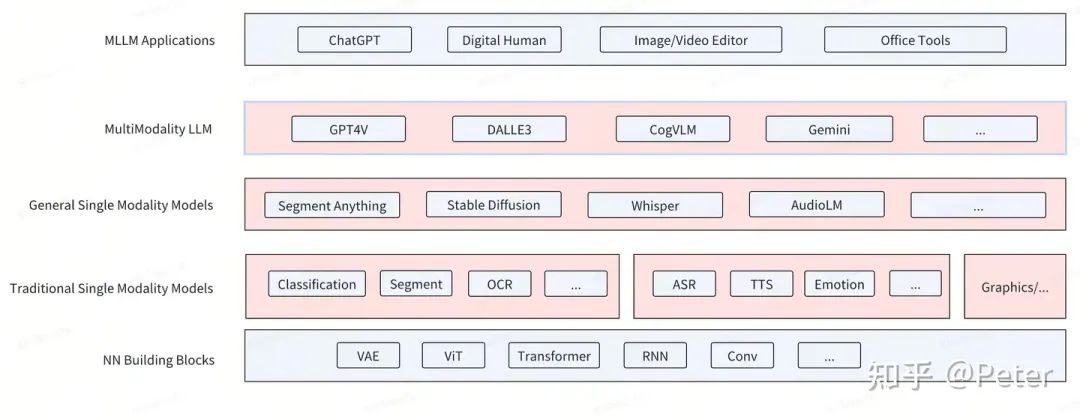
?NN Building Blocks: 相對(duì)通用的NN模型組件。
?Traditional Single Modality Models: 傳統(tǒng)的垂類小模型,通常小于100M~1B參數(shù),只在某個(gè)垂直場(chǎng)景上有效。雖然不通用,但是具有一些獨(dú)特優(yōu)勢(shì):顯著的性能和成本優(yōu)勢(shì),常常能夠在移動(dòng)端設(shè)備部署,離線可用。在很多場(chǎng)景和大模型組合使用,依然扮演重要角色。
?General Single Modality Models: 單模態(tài)大模型,通常大于100M~1B參數(shù)。具有較強(qiáng)的通用性,比如對(duì)圖片中任意物體進(jìn)行分割,或者生成任意內(nèi)容的圖片或聲音。極大降低了場(chǎng)景的定制成本。
?MLLM:多模態(tài)大模型。以LLM為核心(>1B參數(shù)),端到端的具備多種模態(tài)輸入,多種模態(tài)輸出的大模型。某種程度上看見(jiàn)了AGI的曙光。
?MLLM Application: 靈活的結(jié)合LLM、MLLM、General/Traditional Single Modality Models等能力形成新的產(chǎn)品形態(tài)。
多模態(tài)的價(jià)值?
文字發(fā)展了數(shù)千年,似乎已經(jīng)能精確的表達(dá)任意事物,僅憑文字就可以產(chǎn)生智能。數(shù)學(xué)物理公式、代碼等更是從某種程度上遠(yuǎn)遠(yuǎn)超越了世界的表象,體現(xiàn)了人類智慧的偉大。
然而,人的一切依然依托于物理世界,包括人本身的物理屬性。人們能毫不費(fèi)力的處理十個(gè)小時(shí)的視覺(jué)信號(hào)(比如刷視頻、看風(fēng)景),十年如一日,但是一般人無(wú)法長(zhǎng)時(shí)間的進(jìn)行文字閱讀理解。美麗的風(fēng)景、優(yōu)美的旋律能輕易的讓大部分感受到愉悅,而復(fù)雜的文字或代碼則需要更大的精力。
其他的各種人類社會(huì)的生產(chǎn)、消費(fèi)、溝通等都離不開(kāi)對(duì)世界自然信號(hào)的直接處理。難以想象這一切如果都需要通過(guò)中間的文字轉(zhuǎn)化,才能被接受和反饋。(想象司機(jī)通過(guò)閱讀文字,決定方向和油門(mén))
AGI需要對(duì)自然信號(hào)的直接處理與反饋。
多模態(tài)技術(shù)
當(dāng)前多模態(tài)大模型通常都會(huì)經(jīng)過(guò)三個(gè)步驟:
?編碼:類比人的眼睛和耳朵,自然信號(hào)先要通過(guò)特定的器官轉(zhuǎn)換成大腦可以處理的信號(hào)。
?把每一個(gè)image切成多個(gè)patch,然后通過(guò)vit, siglip等vision encoder編碼成一串vision embedding。考慮到視覺(jué)信號(hào)的冗余,可以再通過(guò)resampler, qformer等結(jié)構(gòu)進(jìn)行壓縮,減少輸入。
?或者也可能是通過(guò)VAE編碼成一個(gè)(h, w, c)shape的latent feature。或者是通過(guò)VQ編碼成類似上文中l(wèi)anguage“詞”的序號(hào)(integer),然后通過(guò)embedding table lookup轉(zhuǎn)化成embedding。
?對(duì)于language而言,通常就是文字的向量化。比如用bpe或者sentencepiece等算法把長(zhǎng)序列的文字切成有限個(gè)數(shù)的“詞”,從詞表(vocabulary)中找到對(duì)應(yīng)的序號(hào),然后再通過(guò)embedding table lookup,把這些“詞”轉(zhuǎn)化成模型能理解的embedding。
?vision有一些不同的處理方式,比如:
?audio也需要進(jìn)行編碼,將傳統(tǒng)的waveform通過(guò)fft處理成mel-spectrum。也有EnCodec或SoundStream等neural encoder可以把a(bǔ)udio編碼成一系列的token。
?處理(思考):完成編碼的信號(hào)就如同人們大腦接收到的視覺(jué)、聲音、文字信號(hào)。可以通過(guò)“思考“的過(guò)程后,給出反饋。
?基于diffusion的處理過(guò)程是近幾年新出現(xiàn)的一類有趣的方法。在vision, audio生成中有卓越的表現(xiàn)。
?基于llm的處理過(guò)程似乎更值得期待。llm本身已經(jīng)具備相當(dāng)?shù)闹悄艹潭龋峁┝撕芨叩奶旎ò濉H绻鹟lm能夠很好的綜合處理多模態(tài)信號(hào),或許能接近AGI的目標(biāo)。
?解碼:編碼的反向過(guò)程,把模型內(nèi)部的表示轉(zhuǎn)化成物理世界的自然信號(hào)。就類似人們通過(guò)嘴巴說(shuō)話,或者手繪畫(huà)。
以下面兩個(gè)多模態(tài)模型為例子:
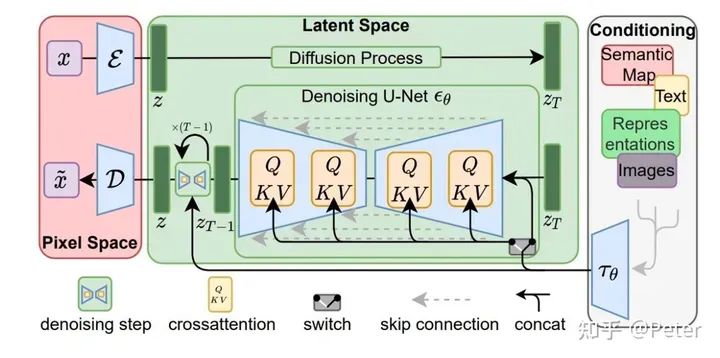
StableDiffusion:
?編碼:image通過(guò)VAE encoder變成latent z。
?處理:核心的處理過(guò)程在Unet中,通過(guò)多步denoise,對(duì)z進(jìn)行去噪。
?解碼:z最終通過(guò)VAE decoder解碼成image。
stable diffusion
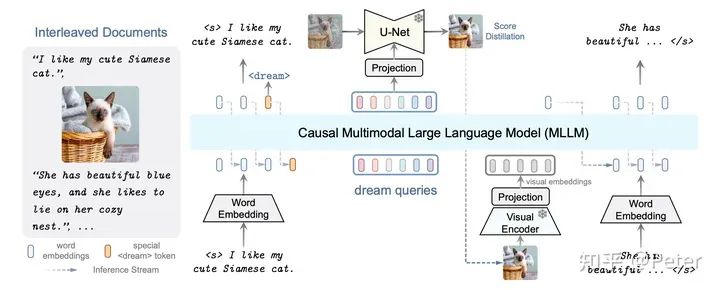
DreamLLM:
?編碼:text通過(guò)word embedding,而圖片通過(guò)visual encoder。
?處理:casual llm對(duì)編碼后的的語(yǔ)言和文字信號(hào)進(jìn)行聯(lián)合處理,預(yù)測(cè)需要生成的語(yǔ)言和文字信號(hào)。
?解碼:將預(yù)測(cè)結(jié)果還原成text和image。
DreamLLM
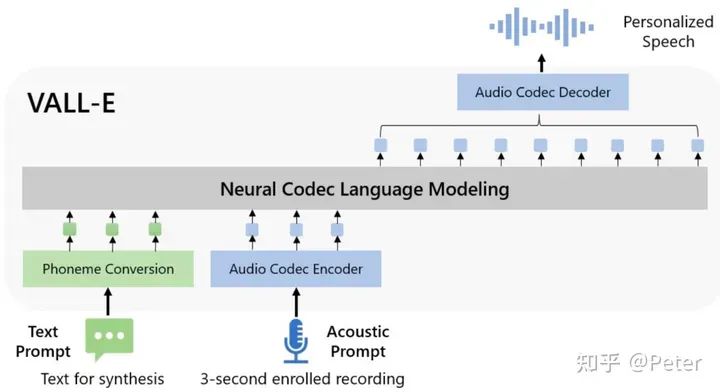
類似的架構(gòu)還在語(yǔ)音生成的模型結(jié)構(gòu)中出現(xiàn),比如VALL-E,有對(duì)應(yīng)的semantic, acoustic編碼和解碼,以及diffusion or llm的處理過(guò)程。
多模態(tài)的難題
目前我還有些多模態(tài)相關(guān)的問(wèn)題沒(méi)太想明白。
多模態(tài)scaling law
目前Meta, Google有放出一些多模態(tài)的實(shí)驗(yàn),比如PALI對(duì)于ViT的scaling。但是還缺少一些理論性的支持和疑點(diǎn)。
?ViT在多模態(tài)理解中扮演了什么角色,需要如此大的參數(shù)規(guī)模?這部份參數(shù)是否可以轉(zhuǎn)移到LLM上?
?數(shù)據(jù)scale時(shí),如何分配圖片和文字的比例是比較好的實(shí)踐?
如果做個(gè)思想實(shí)驗(yàn):
?一個(gè)網(wǎng)頁(yè)上有500個(gè)字,需要800個(gè)token表示。
?一個(gè)screenshot截圖了這個(gè)網(wǎng)頁(yè),用vision encoder編碼后得到400個(gè)token。
如果使用LLM分別處理兩種輸入,能夠完成同樣的任務(wù)。那么似乎就不需要用text作為L(zhǎng)LM的輸入了。
?對(duì)于text, vision, audio信號(hào)編碼的最佳實(shí)踐是什么?每類信號(hào)需要使用多少的參數(shù)量才能無(wú)損的壓縮原始信號(hào)?
從簡(jiǎn)單主義出發(fā),scaling is all you need。
但是no profit, no scaling。所以還是得回到上面那個(gè)問(wèn)題。
多模態(tài)生成的路徑
Diffusion在生成上取得了不俗的效果,比如繪畫(huà)。LLM同樣可以完成視覺(jué)和音頻的生成。
?最終是LLM replace Diffusion, 還是Diffusion as decoder for LLM,還是通過(guò)別的方式?
?Diffusion的multi-step denoise是否可以通過(guò)llm的multi-layer transformer + iterative sampling來(lái)隱式模擬?
?或許diffusion就像是convolution,是人們發(fā)明的inductive bias,最終會(huì)被general learnable method取代。
LLM end2end many2many是否是個(gè)偽需求?
?是否有一種無(wú)損(或者近似)的信息傳遞方式,讓多個(gè)LLM互相協(xié)作?
審核編輯:黃飛
-
AI
+關(guān)注
關(guān)注
88文章
35168瀏覽量
280136 -
大模型
+關(guān)注
關(guān)注
2文章
3147瀏覽量
4079 -
LLM
+關(guān)注
關(guān)注
1文章
325瀏覽量
848
原文標(biāo)題:聊聊:什么是多模態(tài)?有什么價(jià)值以及難題
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄

多文化場(chǎng)景下的多模態(tài)情感識(shí)別
Transformer模型的多模態(tài)學(xué)習(xí)應(yīng)用
中文多模態(tài)對(duì)話數(shù)據(jù)集
VisCPM:邁向多語(yǔ)言多模態(tài)大模型時(shí)代

更強(qiáng)更通用:智源「悟道3.0」Emu多模態(tài)大模型開(kāi)源,在多模態(tài)序列中「補(bǔ)全一切」

基于Transformer多模態(tài)先導(dǎo)性工作

基于視覺(jué)的多模態(tài)觸覺(jué)感知系統(tǒng)
探究編輯多模態(tài)大語(yǔ)言模型的可行性
大模型+多模態(tài)的3種實(shí)現(xiàn)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論