 請問AMBA總線之AXI是如何提高性能的呢?
請問AMBA總線之AXI是如何提高性能的呢?
很多讀者對AXI是如何提高吞吐量,提高帶寬的方式還不夠Make sense。本篇文章將從概念本身,結合配圖,帶大家充分理解AXI是如何提高性能的。
1、如何評估性能?
性能中一個關鍵的指標就是延遲,什么是延遲(Latency)呢?
比如有個人,叫做小明,在上大學需要用錢,因此給父親寄信。父親收到信以后將錢寄給小明同學。整個過程一共花費了2+3=5days。這就是整個寄信加寄錢所花費的延遲。
我們假設每次寄錢只能夠寄兩萬,由此我們又可以引出帶寬(Bandwidth)的概念。所謂的帶寬即單位時間可以傳輸的數據量多少。在上述的例子中BW=2W/5days = 0.4W/day。
如果按照這樣的一個帶寬速度,寄100萬需要多久呢?我們用數據量除以帶寬:100W/(0.4W/day)=250days!
如何讓寄100萬更快呢?一種很直接的方法,就是在收到錢之前,狂發信。父親每收到一封就把錢寄回去。理論上這樣只需要5天多一點,就可以寄100W!
2、Outstanding對性能的影響
有了上面的例子,大家已經知道了什么是延遲和帶寬了。由此我們接著往下講。在之前的文章已經講過,AXI提高傳輸速度主要有三板斧,以下排名分先后順序:
Outstanding
Out-of-orde(ooo)
Interleave
最直截了當提高總線性能的方法是什么呢?首先就是提高頻率,再一個就是提高數據位寬。這兩種方式對所有的總線實際上都是成立的,但由于過于簡單粗暴,一般不能作為某個總線的優勢或者賣點所在。
因此我們重點講一下AXI的三板斧,首先是Outstanding。所謂的Outstanding就是在任務完成之前就可以下達新的任務,即“在路上”。Outstanding是上面三種方法中,提高總線性能最有效最簡單的方法!
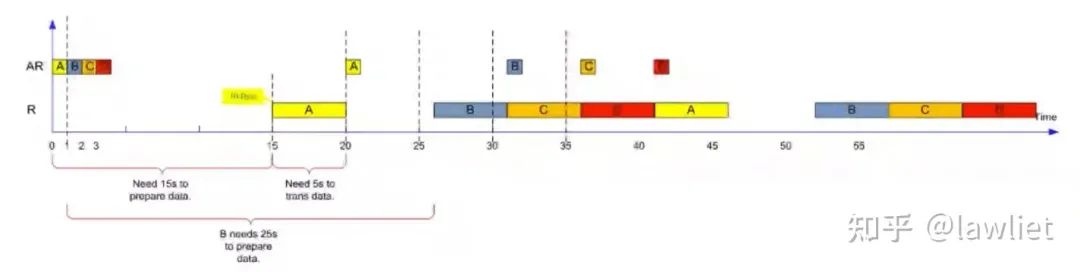
我們看一下Outstanding的延遲怎么算。下圖顯然是不支持Outstanding的例子,可以看到AR發出以后,需要15個Cycle準備數據,又需要5個Cycle傳回數據。因此總共需要20個Cycle。
這個例子中絕對延遲和平均延遲都是20s。
這個例子中帶寬BW=30B/60s=0.5Bps,然而最大的瞬時帶寬是2Bps。
有75%的時間都因為Master和Slave之間的巨大延遲而浪費掉了!
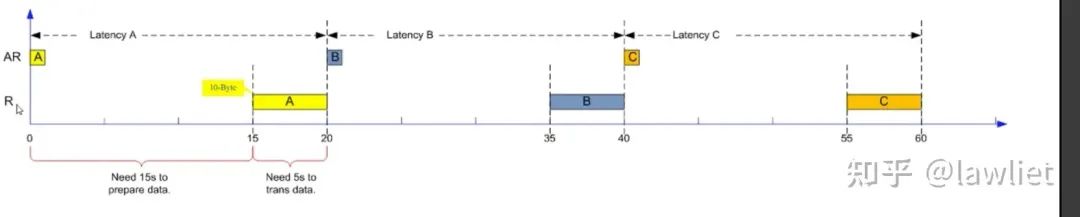
我們再看一下Outstanding做到3的時候是怎樣的結果,下圖這個例子中,絕對延遲依然是20s。但是平均延遲變為了30s/3=10s。相應的帶寬也變成了1Bps。
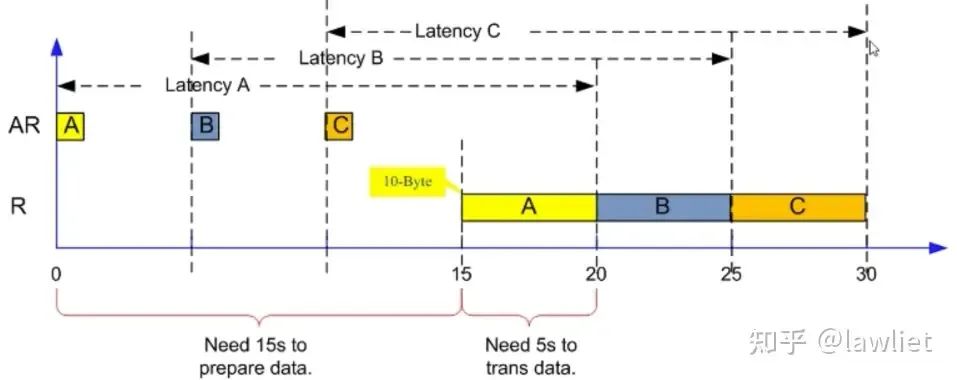
上面那個例子中,是過了5s再發出下一個Outstanding命令,實際上一般不會考慮這么多。當還沒有發滿的時候,就接著發。我們看下面這個例子:
絕對延遲分別是20/24/28s。由此可以看到Outstanding有可能還會使絕對延遲變長(當然B、C也可以向流水線一樣和A緊貼著,這個取決于具體設計。當需要維持住5個Cycle的時候,那自然就需要等待了)
平均延遲是50/6=8.33s。
BW=60B/50s=1.2Bps
也可以用平均延遲算,BW=10B/8.33=1.2Bps
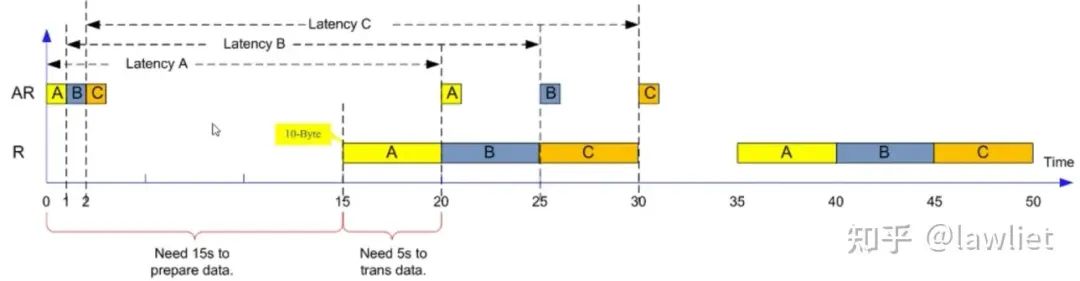
上面那個例子中,R這個信道實際上也是沒有占滿的,當Outstanding為4的時候呢?可以看看下圖這個例子:
絕對延遲分別是20/24/28/32s
平均延遲是55s/8=6.875s,極限是lim?→∞(15+??5)/?=5?
BW=80B/55s=1.45Bps,極限是lim?→∞(10??)/(15+??5)=2???
可以看到理論極限就是5s,這個時間對應于真正需要傳輸數據或者是維持住某個數據不變的時間。極限的帶寬實際上就是10/5=2Bps
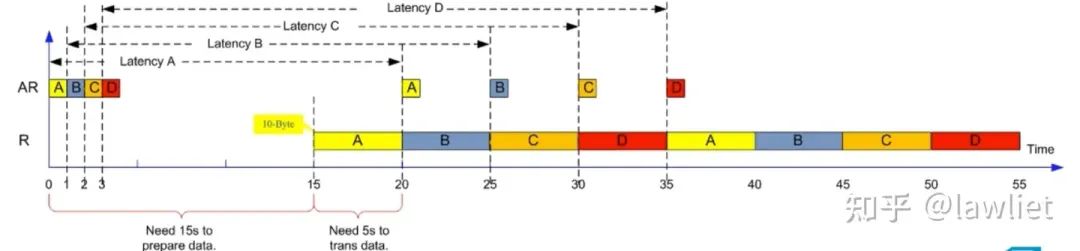
我們再來思考一個問題:Outstanding數量越多越好嗎?
答案當然是否定的,更多的Outstanding意味著更多的硬件資源開銷,比如就需要很多的Buffer去存儲已經發送的CMD。但通過上面的例子我們可以看出,當Outstanding再增加,其性能也已經飽和了,不會再增加。因此選擇一個合適的Outstanding數量,基于此進行設計很重要。
既然Outstanding不是越大越好,那我們怎么去估計Outstanding數量呢?
我們考慮一個非常簡單的例子:
假設始終頻率是500MHz,相應的周期是2ns
假設AXI cmd是基于burst-8傳輸的。即對于一個cmd,至少需要8個cycle傳輸相應的數據。
第一筆數據返回的時候,需要200ns
由此可以估算Outstanding的數量為200/(2ns*8),可以設置為8或者16(一般是用2的冪次方)。實際中會比這個例子復雜的多,該例子只是幫助大家梳理一下基本思路。
我們再看一下Outstang的優缺點:
優點:提高帶寬,減少平均延遲
缺點:可能會增加絕對延遲,一定會增加面積(需要Buffer存CMD,如果沒有亂序,這個時候額外的面積其實還不太多,如果要支持亂序,那額外的面積開銷就大了,因為還要存DATA)
此外,Outstanding是ooo和Interleave的基礎,沒有Outstanding,后面二者是無從談起的。
3、Out of Order對性能的影響
講完了Outstanding,我們來看一下亂序。在上面的例子中,大家可能會覺得:咦?不是R信道已經占滿了嗎?難道還可以提速嗎?為什么還需要亂序?
因為在上面的例子中,我們是假定各個模塊準備數據的延遲是一樣久的。但是在下面這個例子中,可以看到B需要更多的周期去準備相應的數據,又浪費了Cycle!假如B的數據是來自DDR的,此時還用這種方式且不支持亂序,那就非常Naive了,可能百分之九十多的周期都被浪費了。
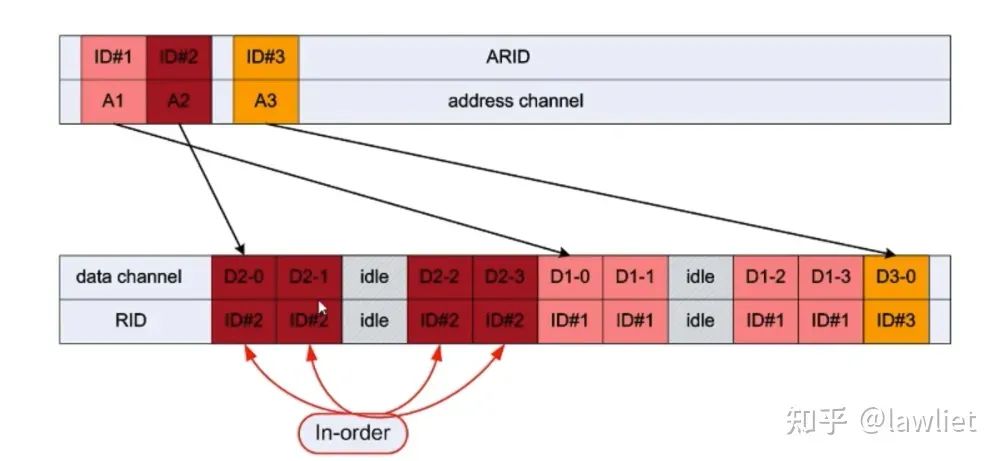
這種情況下,我們就要使出第二板斧,亂序。可以看到下圖這個例子,我們可以讓快速的Slave先傳,然后再傳慢的Buffer。

如果要做Out of Order。那么Master端就需要一個非常大的Buffer了。以上圖例子中,就需要40Byte的Buffer了。因為最差的情況,數據ABCD是倒著回給你的,但是你還是得按照順序用,那只能用額外的Buffer存儲了。因此如果不是某個Slave一定會亂序,且對性能影響很大,一般做Master是不建議支持Out of Order的。
4、Interleave對性能的影響
Interleave就是交織,在AXI中的Interleave,按照我的理解就是更加細粒度的亂序。
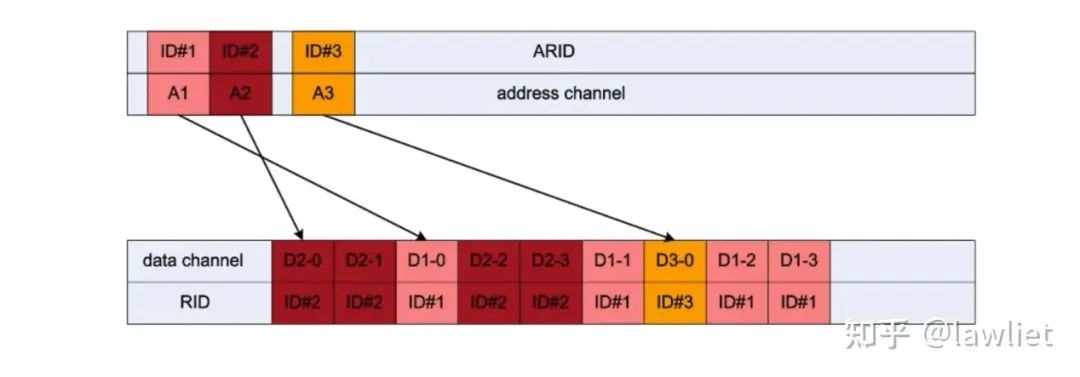
我們考慮這樣的例子,每次CMD需要4次Transfer。我們假設Slave準備數據很慢,每次只能準備2次Transfer的數據,如下圖所示。可以看到,又有Cycle浪費了(可以看到這個例子中,是Out of Order的,但是同樣有周期的浪費)。
當允許交織以后,如下圖所示:可以看到每個周期都充分利用上了,非常的棒啊。這樣性能會更加好。但是Interleave顯然,比Out of Order更麻煩。它消耗的面積和亂序實際上是差不多的,但是控制邏輯復雜的多。正因為如此,AXI4已經移除了寫交織,僅保留讀交織。
實際上很多Master壓根不支持讀交織,大家設計模塊的時候,還是要根據實際需求,確定是否需要支持這些功能。畢竟一旦支持這些功能,一個簡單的DMA Master的代碼都奔著上千行去了,還非常容易出錯。(筆者當時就做了一個可以亂序和讀交織的DMA,僅僅和驗證配合調試都花了兩個多月)。
5、其它提高AXI性能的辦法
這里主要講兩點:
QoS
數據/傳輸的重定義,優化
5.1、QoS
QoS實際上是計算機網絡的概念,QoS(Quality of Service)即服務質量。在有限的帶寬資源下,QoS為各種業務分配帶寬,為業務提供端到端的服務質量保證。例如,語音、視頻和重要的數據應用在網絡設備中可以通過配置QoS優先得到服務。
ARM基于此概念,在AXI4新增QoS相關的信號,為AxQOS,共4bit,其定義了每次傳輸的優先級。我們一般認為0xF代表最高的優先級,0x0代表最低的優先級。QoS一般有如下的作用:
QoS可以用來解決訪問沖突問題,當同時訪問先仲裁得到優先級高的;
Slave可以根據QoS來reorder或者優先考慮先回應哪筆傳輸;
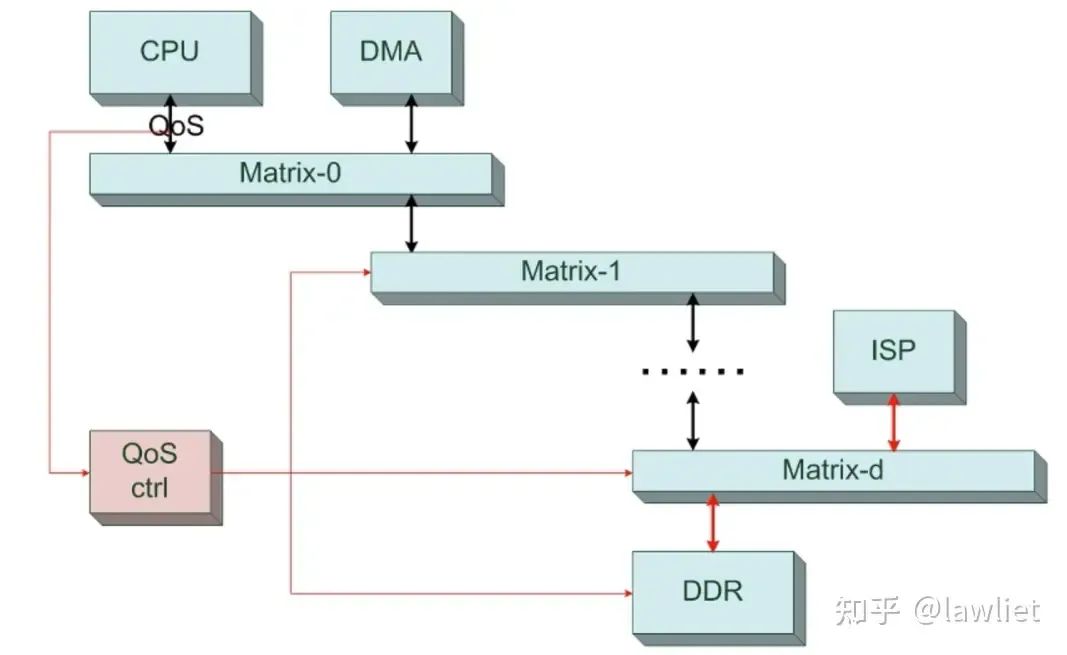
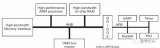
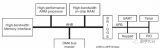
下圖是一個典型的復雜系統,這種系統就需要QoS來確定,到底哪個Master可以優先獲得總線訪問機制,因此就需要設計復雜的QoS控制系統,此系統一般是可以通過軟件實時的去改配。
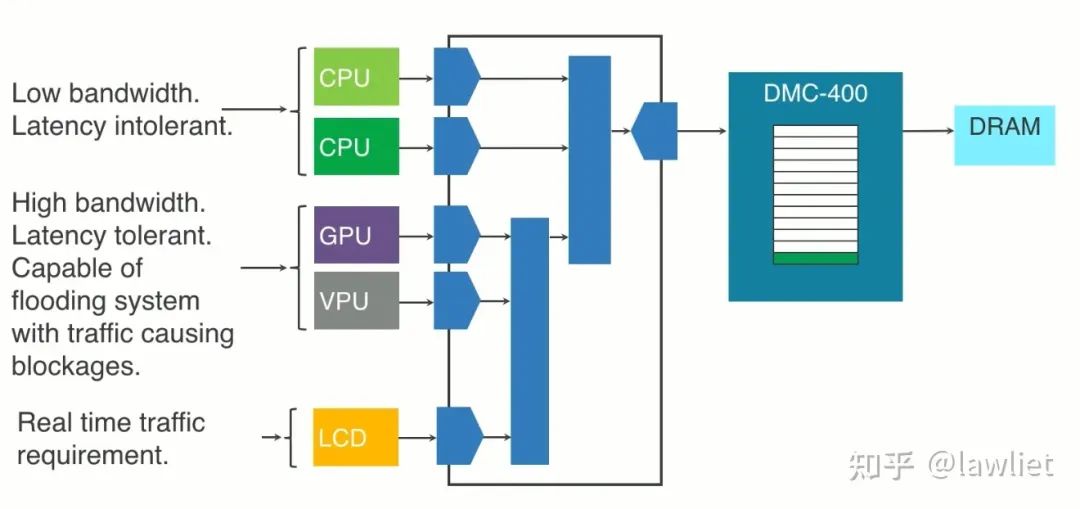
我們再思考一下,QoS主要是優化延遲還是帶寬呢?
AXI的QoS主要是為了解決延遲問題。通過此值,可以更好的仲裁,以避免延遲大的阻塞住整個總線,而嚴重影響其它模塊的訪問延遲。當然它一定程度上也會影響到帶寬。
AXI的QoS實際上我沒參與設計過,這里就不展開講具體設計了,以避免誤導大家。
5.2、Data/Transfer
上面我們講的這些AXI的優化策略,其實ARM的初衷,主要是為了DDR設計的。因為大部分Slave和Master之間都是緊耦合的,根本就不需要Out of Order和Interleave。那么如何針對DDR的讀寫去優化呢?簡單來講就是你的CMD和DATA要更加符合DDR的胃口。
地址對齊;
增加Burst Length;Burst Combine;
避免Partial Write。即WSTRB有1有0。因為很多DDR是不支持此功能的,你要讀回去再寫,非常耗時;
Read/Write Group。即不要寫一個讀一個,最好是寫一組讀一組;
避免Locked/Exclusive access;(Locked就不說了,Exclusive是一讀一寫,對DDR非常不友好)
6、AHB vs AXI
最后我們總結一下AXI和AHB的區別,再回顧一下AXI的優勢所在。
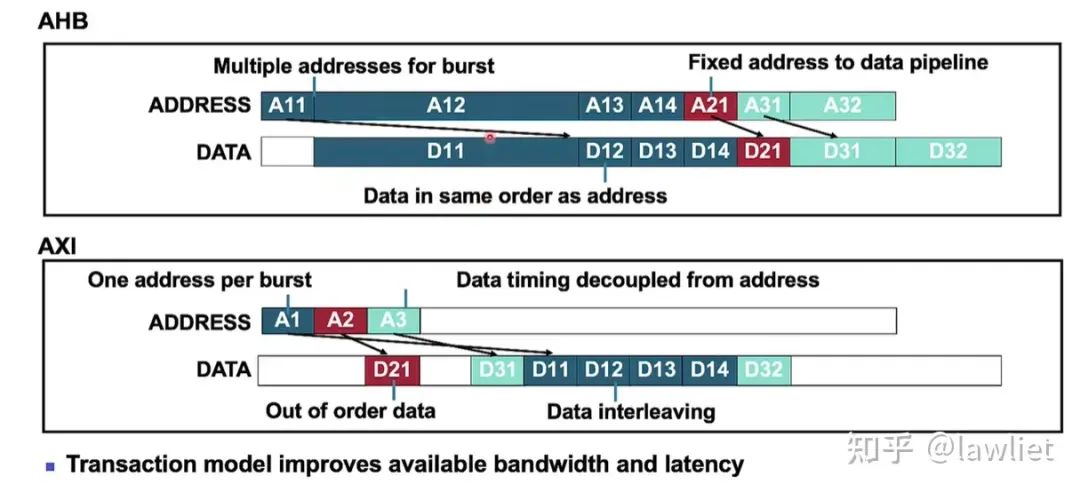
如下圖所示,是AHB和AXI的讀例子:
盡管AHB也可以突發傳輸,但是它每一次都是需要更新相應的地址,而AXI只需要給一次地址即可。后續的數據可以讓Slave自己根據首地址不停地去算。
此外AXI支持亂序,如果針對地址A1的transaction沒能及時響應,沒關系,可以先回地址A2和A3的數據。減少了可能存在的周期浪費。
此外AXI讀還支持Interleave,即更加細粒度的亂序。可以看到針對地址A3的回數據,可能回了一筆突然回不了了,沒關系,可以馬上回地址A1的數據,再回地址A3的數據。
審核編輯:劉清
-
控制系統
+關注
關注
41文章
6765瀏覽量
111876 -
DDR
+關注
關注
11文章
731瀏覽量
66502 -
QoS
+關注
關注
1文章
137瀏覽量
45300 -
AMBA總線
+關注
關注
0文章
35瀏覽量
9804 -
AHB
+關注
關注
0文章
26瀏覽量
10155
原文標題:深入理解AMBA總線之AXI是如何提高性能的
文章出處:【微信號:Rocker-IC,微信公眾號:路科驗證】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
學習架構-AMBA AXI簡介
AMBA3.0 AXI總線接口協議的研究與應用
AMBA總線AHB、APB、AXI性能對比分析及AHB詳解
AMBA總線概述(二)
AMBA3.0 AXI總線接口協議的研究與應用
AMBA 3.0 AXI總線接口協議的研究與應用
基于AMBA總線介紹?
介紹AMBA2.0總線
AXI總線協議簡介
NVMe簡介之AXI總線





 工商網監
工商網監
評論