 小身板大能量:樹莓派玩轉 Phi-2、Mistral 和 LLaVA 等AI大模型~
小身板大能量:樹莓派玩轉 Phi-2、Mistral 和 LLaVA 等AI大模型~


你是否想過在自己的設備上運行自己的大型語言模型(LLMs)或視覺語言模型(VLMs)?你可能有過這樣的想法,但是一想到要從頭開始設置、管理環境、下載正確的模型權重,以及你的設備是否能處理這些模型的不確定性,你可能就猶豫了。
讓我們更進一步。想象一下,在自己的信用卡大小的設備上——比如Raspberry Pi ——運行自己的LLM或VLM。不可能嗎?完全不是。畢竟,我正在寫這篇帖子,所以這肯定是可能的。
確實可能,但為什么要這么做呢?
目前,在邊緣設備上運行LLM似乎有些牽強。但這個特定的利基用例應該會隨著時間的推移而成熟,我們肯定會看到一些很酷的邊緣解決方案,這些解決方案采用完全本地的生成式AI解決方案,在邊緣設備上運行。
這也是為了探索可能性的極限。如果能在計算規模的這一極端實現,那么在Raspberry Pi 和大型強大服務器GPU之間的任何級別上都可以實現。
傳統上,邊緣AI與計算機視覺緊密相連。探索在邊緣部署LLMs和VLMs為這個新興領域增添了一個令人興奮的維度。
最重要的是,我只是想用我最近購買的Raspberry Pi 5做一些有趣的事情。
那么,我們如何在Raspberry Pi 上實現這一切呢?使用Ollama!
什么是Ollama?
Ollama已經成為在個人電腦上運行本地LLMs的最佳解決方案之一,而無需處理從頭開始設置的麻煩。只需幾條命令,就可以毫無問題地設置好一切。在我的經驗中,它完全自給自足,并且在多個設備和模型上都能完美運行。它甚至提供了一個用于模型推理的REST API,因此你可以讓它在Raspberry Pi 上運行,并從你的其他應用程序和設備中調用它(如果你愿意的話)。
還有Ollama Web UI,這是一個與Ollama無縫運行的漂亮的人工智能用戶界面(UI)/用戶體驗(UX),適合那些對命令行界面感到不安的人。如果你愿意的話,它基本上是一個本地的ChatGPT界面。
Ollama和Ollama Web UI還支持VLM,如LLaVA,這為邊緣生成式AI用例打開了更多的大門。
技術要求
你只需要以下設備:
Raspberry Pi 5(或速度較慢的Raspberry Pi 4)——選擇8GB RAM版本以容納7B模型。
SD卡——至少16GB,容量越大,可容納的模型越多。預先加載有合適的操作系統,如Raspbian Bookworm或Ubuntu。
互聯網連接
就像我之前提到的,在Raspberry Pi 上運行Ollama已經接近硬件譜系的極端。理論上,任何比Raspberry Pi 更強大的設備(只要它運行Linux發行版并具有類似的內存容量),都應該能夠運行Ollama和本文中討論的模型。
1. 安裝Ollama
為了在Raspberry Pi 上安裝Ollama,我們將避免使用Docker以節省資源。
在終端中運行
curl https://ollama.ai/install.sh | sh
運行上述命令后,你應該會看到與下面類似的圖像。
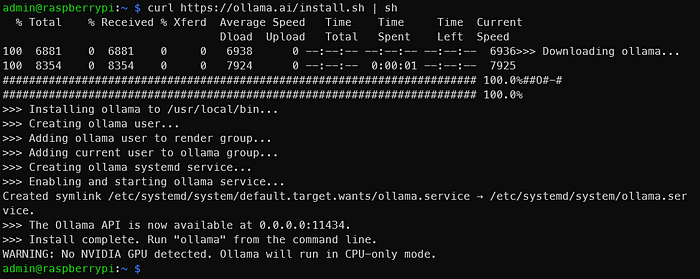
就像輸出所說的那樣,轉到0.0.0.0:11434以驗證Ollama是否正在運行。由于我們使用的是Raspberry Pi ,所以看到“WARNING: No NVIDIA GPU detected. Ollama will run in CPU-only mode.”(警告:未檢測到NVIDIA GPU。Ollama將以僅CPU模式運行。)是正常的。但是,如果你在這些說明中看到的是應該具有NVIDIA GPU的設備,那么可能出現了問題。
2. 通過命令行運行LLMs
查看官方the official Ollama model library,了解可以使用Ollama運行的模型列表。在8GB的Raspberry Pi 上,大于7B的模型將無法容納。讓我們使用Phi-2,一個來自微軟推出的2.7B LLM,現在在MIT許可下。
在終端中運行
ollama run phi
一旦你看到與下面類似的輸出,你就已經在Raspberry Pi 上運行了一個LLM!就是這么簡單。
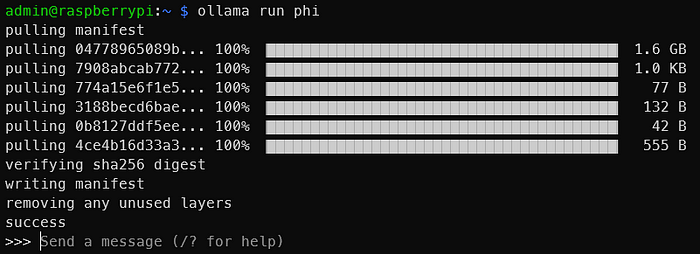
以下是與Phi-2 2.7B的交互。顯然,你不會得到相同的輸出,但你應該明白了

你可以嘗試其他模型,如Mistral、Llama-2等,只需確保SD卡上有足夠的空間存儲模型權重。
當然,模型越大,輸出速度就越慢。在Phi-2 2.7B上,我可以獲得大約每秒4個令牌的速度。但是,使用Mistral 7B,生成速度下降到大約每秒2個令牌。一個令牌大致相當于一個單詞。
以下是與Mistral 7B的交互
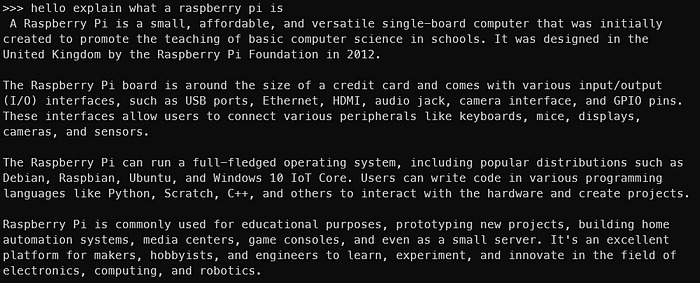
現在我們已經在Raspberry Pi 上運行了LLMs,但還沒有結束。終端并不適合所有人。讓我們也讓Ollama Web UI運行起來!
3. 安裝和運行Ollama Web UI
我們將遵循Ollama Web UI GitHub存儲庫official Ollama Web UI GitHub Repository(https://github.com/open-webui/open-webui)上的說明,在不使用Docker的情況下進行安裝。它建議Node.js版本至少為20.10,因此我們將遵循這一建議。它還建議Python版本至少為3.11,但Raspbian OS已經為我們安裝了該版本。
我們必須先安裝Node.js。在終端中運行
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash - &&\sudo apt-get install -y nodejs
對于未來的讀者,如果需要,可以將20.x更改為更合適的版本。
然后運行下面的代碼塊。
git clone https://github.com/ollama-webui/ollama-webui.gitcd ollama-webui/
# Copying required .env filecp -RPp example.env .env
# Building Frontend Using Nodenpm inpm run build
# Serving Frontend with the Backendcd ./backendpip install -r requirements.txt --break-system-packages sh start.sh
這是對GitHub上提供的內容的輕微修改。請注意,為了簡潔和方便,我們沒有遵循最佳實踐,比如使用虛擬環境,并且我們使用了--break-system-packages標志。如果遇到找不到uvicorn之類的錯誤,請重新啟動終端會話。
如果一切順利,你應該能夠通過Raspberry Pi 上的http://0.0.0.0:8080或同一網絡上的另一臺設備通過http://:8080/訪問Ollama Web UI。
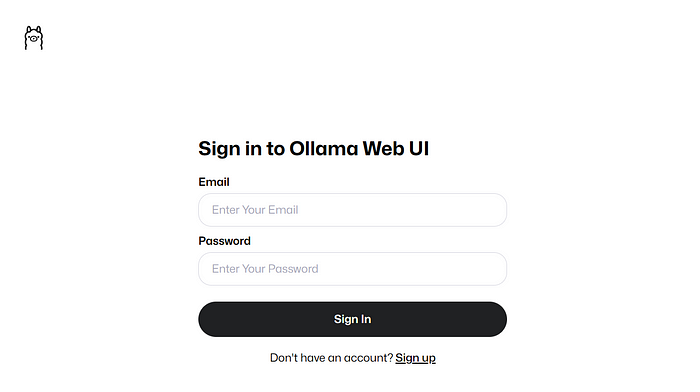
創建賬戶并登錄后,你應該會看到與下面類似的圖像。
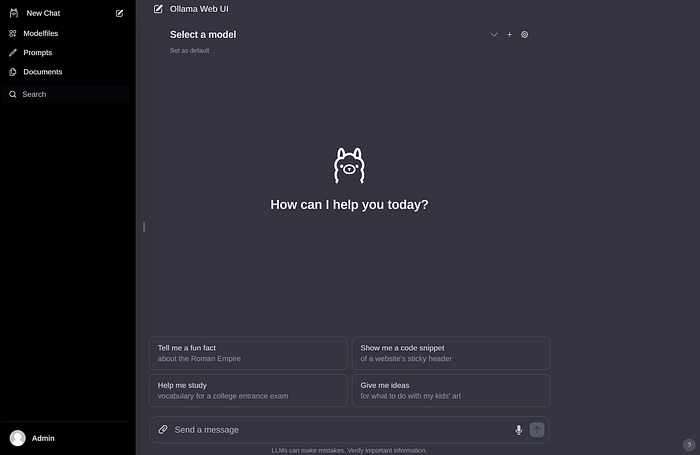
如果你之前下載了一些模型權重,你應該會在下面的下拉菜單中看到它們。如果沒有,你可以轉到設置以下載模型。可能的模型會出現在這里

如果你想要下載新的模型,去Settings > Models to pull models
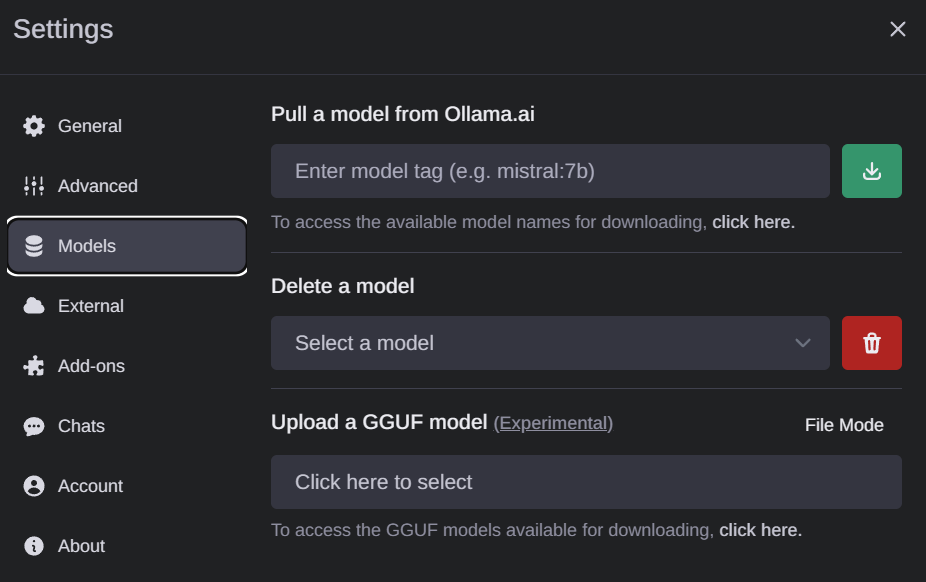
整個界面非常簡潔直觀,因此我不會過多解釋。這確實是一個非常出色的開源項目。
以下是通過Ollama Web UI與Mistral 7B的交互示例

4. 通過Ollama Web UI運行視覺語言模型(VLMs)
就像我在本文開頭提到的那樣,我們還可以運行VLMs。讓我們運行一個流行的開源VLM——LLaVA,它恰好也被Ollama支持。為此,請通過界面拉取“llava”以下載其權重。
不幸的是,與大型語言模型(LLMs)不同,Raspberry Pi 上的設置需要相當長的時間來解釋圖像。下面的示例大約需要6分鐘來處理。大部分時間可能是因為圖像方面的處理尚未得到適當優化,但這種情況在未來肯定會改變。令牌生成速度約為每秒2個令牌。
總結
至此,我們已經基本完成了本文的目標。回顧一下,我們已經成功使用Ollama和Ollama Web UI在Raspberry Pi 上運行了Phi-2、Mistral和LLaVA等LLMs和VLMs。
我完全可以想象出幾個在Raspberry Pi (或其他小型邊緣設備)上托管本地LLMs的用例,特別是如果我們使用Phi-2等大小的模型,每秒4個令牌的速度對于某些用例中的流式傳輸來說似乎是可接受的速度。
“小型”LLMs和VLMs領域(考慮到其“大型”的指定,這一名稱有些自相矛盾)是一個活躍的研究領域,最近發布了相當多的模型。希望這一新興趨勢能夠繼續下去,并發布更多高效且緊湊的模型!在未來幾個月里,這無疑是值得關注的。
免責聲明:作者與Ollama或Ollama Web UI沒有關聯。所有觀點均為作者個人的看法,不代表任何組織。
-
AI
+關注
關注
88文章
34990瀏覽量
278651 -
樹莓派
+關注
關注
121文章
1993瀏覽量
107354 -
大模型
+關注
關注
2文章
3119瀏覽量
4032
發布評論請先 登錄
樹莓派分類器:用樹莓派識別不同型號的樹莓派!

用樹莓派“揪出”家里的耗電怪獸!
樹莓派“吉尼斯世界記錄”:將樹莓派的性能發揮到極致的項目!
用 樹莓派 Zero 打造的智能漫游車!
4臺樹莓派5跑動大模型!DeepSeek R1分布式實戰!
樹莓派傳感器使用方法 樹莓派 Raspberry Pi 4優缺點
樹莓派gpio有什么用,樹莓派gpio接口及編程方法
什么是樹莓派?樹莓派是什么架構的
樹莓派和單片機的優缺點是什么
樹莓派的功能用途是什么
在英特爾酷睿Ultra7處理器上優化和部署Phi-3-min模型





 工商網監
工商網監
評論