 如何破解GPU集群集合通信路徑的“黑盒”難題?
如何破解GPU集群集合通信路徑的“黑盒”難題?

在分布式AI訓練場景中,GPU集合通信路徑是支撐多節點協同計算的核心基礎設施。通過集合通信庫(如NVIDIA NCCL、華為HCCL等),跨GPU的數據交換(AllReduce、Broadcast等操作)得以高效執行,從而實現大規模模型參數的同步與梯度聚合。
然而,隨著智算集群規模的擴展,通信路徑的復雜性呈指數級增長,暴露出以下技術難題。
路徑黑盒化:現有集合通信庫(Collective Communication Libraries, CCLs)對用戶屏蔽底層通信細節(如物理拓撲、網卡綁定策略、路由選擇),導致性能瓶頸難以定位。
異構環境兼容性:多廠商CCLs(如ACCL、TCCL)的差異化實現,增加了跨平臺部署與調優的復雜度。
動態資源適配不足:傳統靜態路由規劃無法適應動態負載變化,易造成網絡擁塞與帶寬利用率低下。
故障溯源低效:訓練中斷時,需人工排查模型、硬件、網絡多層級問題,MTTR(平均修復時間)顯著增加。
集合通信路徑的架構解析
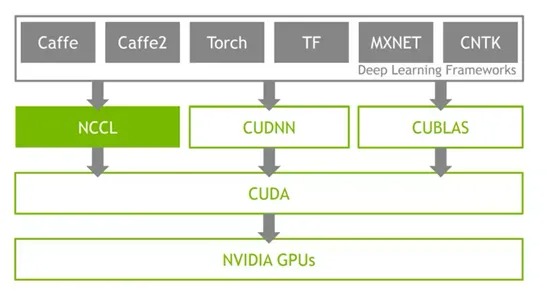
通信路徑的層級劃分
GPU集合通信路徑涵蓋以下核心層級:
- 節點內通信:通過NVLink/PCIe實現多GPU間P2P直連,依賴CUDA驅動層優化。
- 跨節點通信:基于RDMA(如RoCEv2)協議,通過智能網卡(如ConnectX系列)與交換機構建低延遲、高吞吐的數據通道。
- 邏輯通信環:NCCL等庫根據硬件拓撲自動構建邏輯環形/樹形結構,優化數據流并行性。
現有方案的局限性
盡管NCCL通過拓撲感知算法優化通信效率,但其運行時仍存在以下缺陷:
- 路徑不可觀測:用戶無法獲取通信環的實際物理路徑(如交換機端口映射、QoS策略)。
- 配置僵化:缺少動態路由調整機制,無法感知網絡擁塞或鏈路故障。
- 診斷信息碎片化:日志分散于各節點,缺乏全局視圖與關聯分析能力。
EPS(E2E Path Scheduler,端到端路徑規劃)的技術實現
架構設計目標
EPS旨在打破集合通信的“黑盒”狀態,提供以下核心能力:
- 全路徑可視化:實時映射邏輯通信環至物理網絡拓撲。
- 智能路由優化:基于實時流量狀態生成最優路徑配置。
- 自動化運維:通過API驅動網絡設備策略下發,減少人工干預。
關鍵技術模塊
通信環解析與拓撲重構
EPS通過解析NCCL日志中的ncclTopoGraph結構,提取邏輯GPU通信組(如Ring、Tree),并關聯物理設備信息(GPU UUID、網卡端口號)。結合LLDP協議與交換機CLI查詢,動態構建端到端路徑拓撲圖(如圖1)。
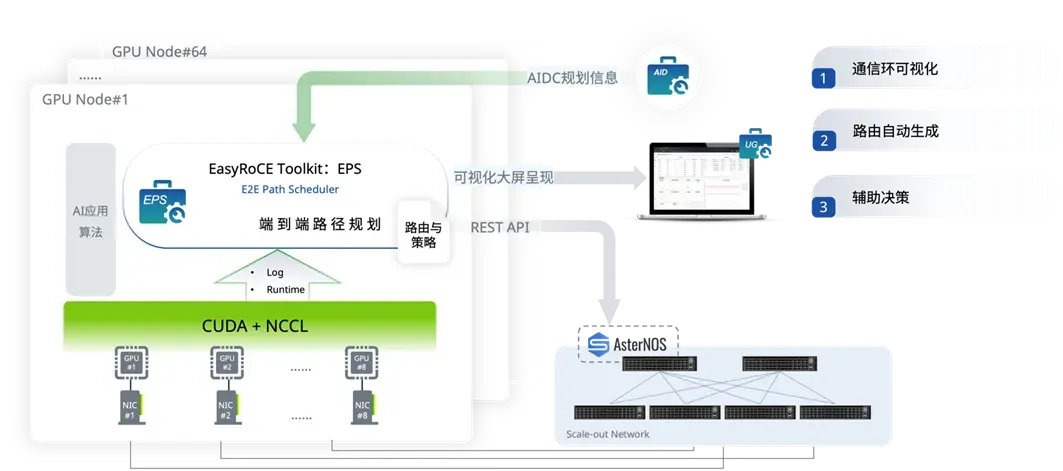 圖1:EPS通信環與物理拓撲的映射示意圖
圖1:EPS通信環與物理拓撲的映射示意圖路由規劃算法
采用混合式路徑選擇策略:
- 靜態權重分配:基于鏈路帶寬、延遲、丟包率構建代價模型。
- 動態負載均衡:集成Prometheus監控數據,實時感知隊列深度與ECN標記,觸發路徑重計算。
- 容災路由:預設多路徑冗余,在鏈路故障時自動切換至備份路徑。
如何使用 EPS?
安裝配置
演示環境中的 Master 節點為一臺獨立的 CentOS 服務器,項目指定的工作目錄為 /home/admin/EPS
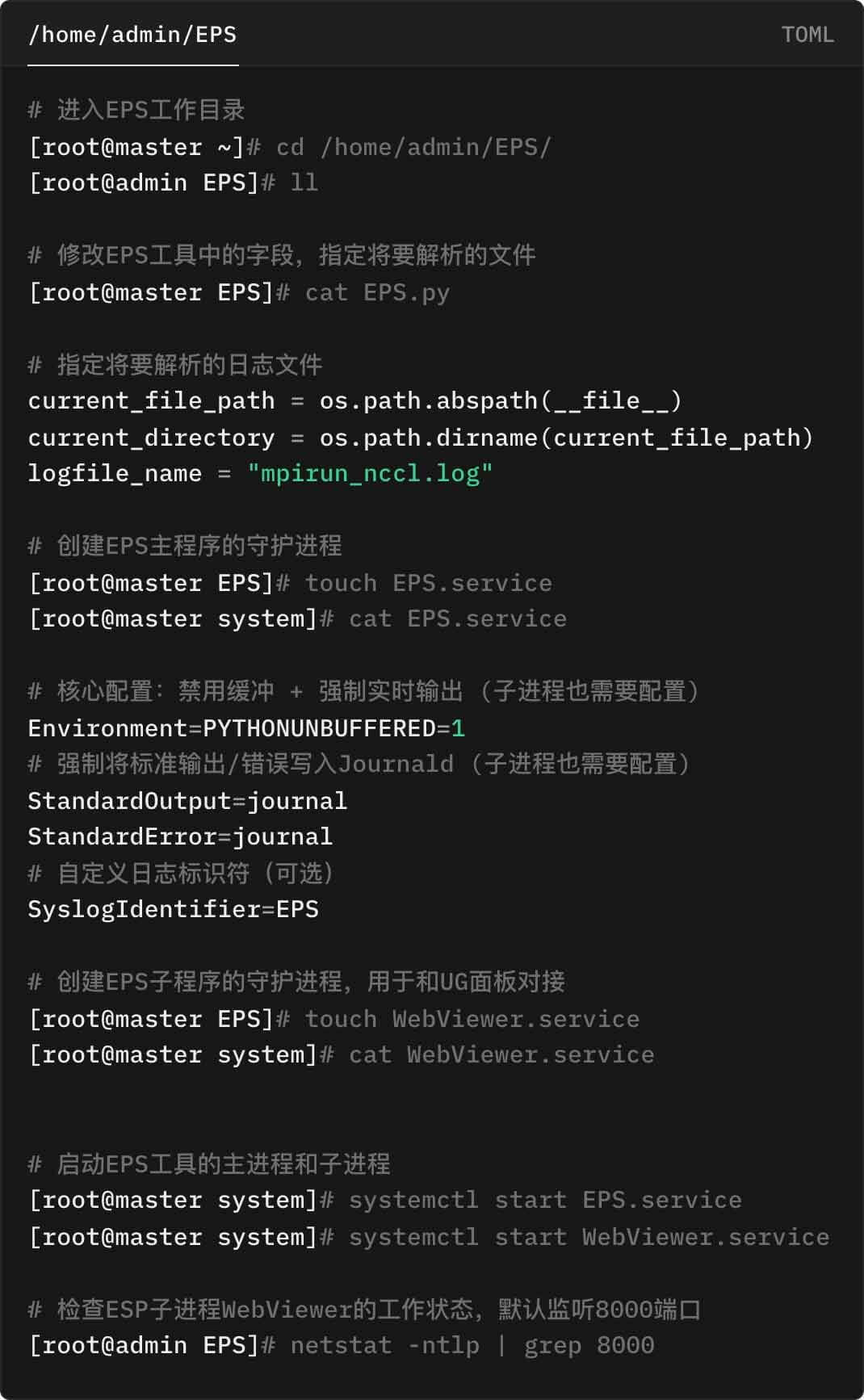
配置控制面板
演示使用 EasyRoCE Toolkit 內的統一監控面板(UG,Unified Glancer),在此之前需要提前完成該平臺的部署,請參閱:一文解讀開源開放生態下的RDMA網絡監控實踐 中的“監控平臺配置”部分。
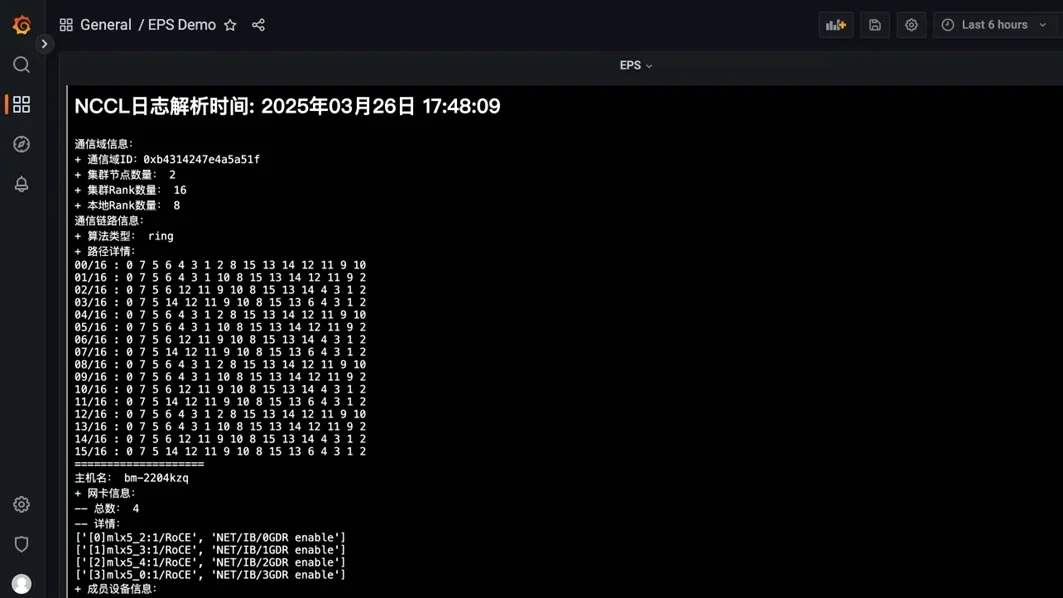
我們只需要為 UG 再添加一個呈現 HTML 的 Pannel,并完成 HTML 源的配置(如下圖所示),EPS 解析出來的集合通信環信息就將作為各類 RDMA 網絡相關監控指標信息的補充,輔助集群設施調優決策。
完成以上所有步驟,我們就可以在 UG 看到實時更新的集合通信庫運行信息,手動更新NCCL 日志文件,可以看到 UG 中呈現的解析信息也同步刷新。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
gpu
+關注
關注
28文章
4936瀏覽量
131107 -
AI
+關注
關注
88文章
34969瀏覽量
278550 -
分布式
+關注
關注
1文章
996瀏覽量
75355
發布評論請先 登錄
相關推薦
熱點推薦
搭建萬卡GPU集群,小米AI大模型即將全力啟動
電子發燒友網報道(文/黃山明)近日,有媒體報道,小米正在著手搭建自家的GPU萬卡集群,將對AI大模型加大投入。該計劃已進行數月,據悉小米大模型團隊在成立之初便已擁有6500張GPU資源,小米創始人兼

羅德與施瓦茨示波器RTO2014破解信號完整性難題的全面指南
的測試儀器,為解決這些信號完整性難題提供了強大的支持。以下是利用RTO2014破解信號完整性難題的詳細方法。 ? 一、了解信號完整性難題 信號完整性指的是信號在傳輸過程中保持其原有特征
云翎智能巡檢終端:以“北斗+”破解森林巡檢“最后一公里”難題
終端通過集成單北斗高精度定位、多模態感知融合、自主可控通信等技術,構建起“空天地一體化”巡檢體系,為破解這一難題提供了智能化解決方案。云翎智能單北斗巡檢終端一、技術

AGV通信第2期 AGV集群智能路徑規劃解決方案
在智能制造加速發展的背景下,AGV作為智慧物流的核心載體,其路徑規劃的智能化水平直接影響工廠的運作效率。在工廠物流升級過程中,企業面臨以下技術挑戰: ? 動態環境適應:復雜工況下需實時避障并保持最優

高校宿舍改造指南:智能水電計費系統如何破解管理難題?
安科瑞解決方案,校園管理難題一應俱全,全方位破解。采用智能硬件+云平臺,實現高效管理閉環精準計量,安全防控,一鍵拉合閘,多支付,后付費模式,能耗分析,賦能綠色校園實時監測,成功案例,降低管理難度,提高學生滿意度。

商業綜合體到智慧園區:ADW600 如何破解多場景用電難題
在數字化能源管理需求日益增長的背景下,安科瑞 ADW600 多回路計量模塊憑借模塊化設計、精準監測與高效通信能力,成為破解商業、工業、園區等多場景用電難題的關鍵方案。其靈活部署、安全預警及數據驅動

電力行業應用案例:頂堅防爆巡檢記錄儀如何破解高危場景取證難題
在電力行業中,高危場景取證一直是一個重要而困難的問題。防爆巡檢記錄儀作為一種專門設計用于高危環境的記錄設備,能夠有效破解這一難題。頂堅防爆巡檢記錄儀通過以下創新設計和功能,有效破解取證難題

中興通訊AiCube:破解AI模型部署難題
,成為制約技術價值釋放的新痛點。 異構算力適配困難、算力資源利用率低以及數據安全風險高等問題,讓許多企業在AI技術的實際應用中遇到了瓶頸。這些問題不僅增加了部署的難度,還可能導致資源的浪費和潛在的安全威脅。 為了破解這一難題,中興通訊推
GPU 性能原理拆解
「迷思」是指經由人們口口相傳,但又難以證明證偽的現象。由于GPU硬件實現、驅動實現是一個黑盒,我們只能通過廠商提供的API、經過抽象的架構來了解并猜測其原理。因此坊間流傳著各種關于與GPU打交道

集合通信與AI基礎架構
人工智能集群的性能,尤其是機器學習訓練集群,受到神經網絡處理單元NPUs(即GPU或TPU)之間并行計算能力的顯著影響。在我們稱為縱向擴展scale-up和橫向擴展scale-out設計中,NPUs

小米加速布局AI大模型,搭建GPU萬卡集群
近日,有消息稱小米正在緊鑼密鼓地搭建自己的GPU萬卡集群,旨在加大對AI大模型的投入力度。據悉,小米的大模型團隊在成立之初就已經擁有了6500張GPU資源,而現在他們正在進一步擴大這一規模。 針對
案例驗證:分析NCCL-Tests運行日志優化Scale-Out網絡拓撲
GPU并行計算中需要大規模地在計算節點之間同步參數梯度,產生了大量的集合通信流量。為了優化集合通信性能,業界開發了不同的集合通信庫(xCCL),其核心都是實現 All-Reduce,這






 工商網監
工商網監
評論