") Ravi Munde利用強(qiáng)化學(xué)習(xí),實(shí)現(xiàn)了對(duì)Dino Run的控制
Ravi Munde利用強(qiáng)化學(xué)習(xí),實(shí)現(xiàn)了對(duì)Dino Run的控制
Chrome 瀏覽器里面有一個(gè)小彩蛋,當(dāng)你沒(méi)有網(wǎng)絡(luò)時(shí),打開(kāi)任意的 URL 都會(huì)出現(xiàn)一個(gè)恐龍小游戲(Dino Run),按空格鍵就可以跳躍。當(dāng)然,直接打開(kāi) chrome://dino 也可以玩這個(gè)小游戲。近期,一名來(lái)自東北大學(xué)(美國(guó))的研究生 Ravi Munde 利用強(qiáng)化學(xué)習(xí),實(shí)現(xiàn)了對(duì) Dino Run 的控制。
以下內(nèi)容來(lái)自 Ravi Munde 博客,人工智能頭條編譯:
本文將從強(qiáng)化學(xué)習(xí)的基礎(chǔ)開(kāi)始,并詳細(xì)介紹以下幾個(gè)步驟:
在瀏覽器(JavaScript)和模型(Python)之間構(gòu)建雙向接口
捕獲和預(yù)處理圖像
訓(xùn)練模型
評(píng)估
▌強(qiáng)化學(xué)習(xí)
對(duì)許多人來(lái)說(shuō),強(qiáng)化學(xué)習(xí)可能是一個(gè)新詞,但其實(shí)小孩學(xué)步利用的就是強(qiáng)化學(xué)習(xí)(RL)的概念,這也是我們的大腦仍然工作的方式。獎(jiǎng)勵(lì)系統(tǒng)是任何 RL 算法的基礎(chǔ),就像小孩學(xué)步的階段,積極的獎(jiǎng)勵(lì)將是來(lái)自父母的鼓掌或糖果,而負(fù)面獎(jiǎng)勵(lì)則是沒(méi)有糖果。孩子在開(kāi)始走路之前首先學(xué)會(huì)站起來(lái)。就人工智能而言,智能體(Agent)的主要目標(biāo)(在我們的案例中是 Dino)是通過(guò)在環(huán)境中執(zhí)行特定的操作序列來(lái)最大化某個(gè)數(shù)字獎(jiǎng)勵(lì)。RL 中最大的挑戰(zhàn)是缺乏監(jiān)督(標(biāo)記數(shù)據(jù))來(lái)指導(dǎo)智能體,它必須自己探索和學(xué)習(xí)。智能體從隨機(jī)行動(dòng)開(kāi)始,觀察每個(gè)行動(dòng)帶來(lái)的回報(bào),并學(xué)習(xí)如何在面臨類(lèi)似環(huán)境狀況時(shí)預(yù)測(cè)最佳行動(dòng)。
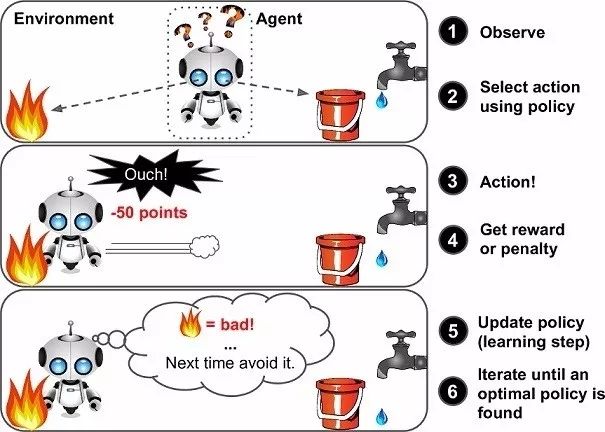
圖注:vanilla 強(qiáng)化學(xué)習(xí)框架
▌Q-learning
我們使用 Q-Learning(RL 中的一種)來(lái)嘗試逼近一個(gè)特殊函數(shù),這個(gè)函數(shù)可以驅(qū)動(dòng)任何環(huán)境狀態(tài)序列的動(dòng)作選擇策略。Q-Learning 是 RL 的一種無(wú)模型實(shí)現(xiàn),針對(duì)每個(gè)狀態(tài)、采取的行動(dòng)和得到的獎(jiǎng)勵(lì)來(lái)更新 Q-table,它能讓我們了解數(shù)據(jù)的結(jié)構(gòu)。在我們的例子中,狀態(tài)是游戲的截圖、行動(dòng)、不動(dòng)、跳[0,1]。
我們通過(guò)回歸方法來(lái)解決這個(gè)問(wèn)題,并選擇具有最高預(yù)測(cè) Q 值的動(dòng)作。

圖注:Q-table 樣本
▌設(shè)置
首先設(shè)置環(huán)境:
1、選擇虛擬機(jī)
我們需要一個(gè)完整的桌面環(huán)境,在這里我們可以捕獲和利用屏幕截圖對(duì)模型進(jìn)行訓(xùn)練。我選擇了 Paperspace ML-in-a-box(MLIAB)Ubuntu 鏡像。MLIAB 的優(yōu)勢(shì)在于它預(yù)裝了Anaconda 和許多其他 ML 庫(kù)。
2、設(shè)置和安裝 Keras 以使用GPU
Paperspace 的虛擬機(jī)已經(jīng)預(yù)先安裝了,如果沒(méi)有的話(huà),可以按照下面的方式:
pip install keraspip install tensorflow
另外,為了確保 GPU 可以被設(shè)置識(shí)別,執(zhí)行下面的 python 代碼,你應(yīng)該看到可用的 GPU 設(shè)備:
from keras import backend as KK.tensorflow_backend._get_available_gpus()
3、安裝 Dependencies
Selenium:
pip install selenium
OpenCV:
pip install opencv-python
下載 Chromedrive:
http://chromedriver.chromium.org
▌?dòng)螒蚩蚣?/p>
打開(kāi) chrome://dino,按空格鍵就可以玩這個(gè)游戲了。如果需要修改游戲代碼,就要 chromium 的開(kāi)源庫(kù)中提取游戲了。
由于這個(gè)游戲是用 JavaScript 寫(xiě)的,而我們的模型是用 Python 寫(xiě)的,因此我們需要運(yùn)用到一些接口工具。
Selenium 是一個(gè)比較流行的瀏覽器自動(dòng)化工具,用于向?yàn)g覽器發(fā)送操作,并獲取當(dāng)前分?jǐn)?shù)等不同的游戲參數(shù)。
在有了發(fā)送操作的接口之后,我們還需要一種捕獲游戲畫(huà)面的機(jī)制:
Selenium 和 OpenCV 分別為屏幕捕獲和圖像預(yù)處理提供了最佳性能,可實(shí)現(xiàn) 6-7 fps 的幀率。
游戲模塊
我們使用這個(gè)模塊實(shí)現(xiàn)了 Python 和 JavaScript 之間的接口,下面的代碼可以讓你知道模塊的實(shí)現(xiàn)原理:
class Game: def __init__(self): self._driver = webdriver.Chrome(executable_path = chrome_driver_path) self._driver.set_window_position(x=-10,y=0) self._driver.get(game_url) def restart(self): self._driver.execute_script("Runner.instance_.restart()") def press_up(self): self._driver.find_element_by_tag_name("body").send_keys(Keys.ARROW_UP) def get_score(self): score_array = self._driver.execute_script("return Runner.instance_.distanceMeter.digits") score = ''.join(score_array). return int(score)
智能體模塊
我們使用智能體模塊來(lái)封裝所有接口。我們使用此模塊控制 Dino,并獲取智能體在環(huán)境中的狀態(tài)。
class DinoAgent: def __init__(self,game): #takes game as input for taking actions self._game = game; self.jump(); #to start the game, we need to jump once def is_crashed(self): return self._game.get_crashed() def jump(self): self._game.press_up()
游戲狀態(tài)模塊
為了將動(dòng)作發(fā)送到模塊并獲得相應(yīng)的結(jié)果狀態(tài),我們使用了 Game-State 模塊。它通過(guò)接收和執(zhí)行操作來(lái)簡(jiǎn)化流程,決定獎(jiǎng)勵(lì)并返回經(jīng)驗(yàn)元組。
class Game_sate: def __init__(self,agent,game): self._agent = agent self._game = game def get_state(self,actions): score = self._game.get_score() reward = 0.1 #survival reward is_over = False #game over if actions[1] == 1: #else do nothing self._agent.jump() image = grab_screen(self._game._driver) if self._agent.is_crashed(): self._game.restart() reward = -1 is_over = True return image, reward, is_over #return the Experience tuple
▌圖像通道
圖像捕捉
我們可以通過(guò)多種方式捕獲游戲畫(huà)面,例如使用 PIL 和 MSS python 庫(kù)截取整個(gè)屏幕,并裁剪感興趣區(qū)域(RegionofInterest, ROI)。然而,這個(gè)方法最大的缺點(diǎn)是對(duì)屏幕分辨率和窗口位置的敏感度問(wèn)題。幸運(yùn)的是,該游戲使用了 HTML Canvas,我們可以使用 JavaScript 輕松獲得 base64 格式的圖像。現(xiàn)在,我們使用 selenium 來(lái)運(yùn)行這個(gè)腳本。
#javascript code to get the image data from canvasvar canvas = document.getElementsByClassName('runner-canvas')[0];var img_data = canvas.toDataURL()return img_data
def grab_screen(_driver = None): image_b64 = _driver.execute_script(getbase64Script) screen = np.array(Image.open(BytesIO(base64.b64decode(image_b64)))) image = process_img(screen)#processing image as required return image
圖像處理
捕捉到的原始圖像的分辨率為 600x150,具有 3 通道(RGB)。我們打算使用 4 個(gè)連續(xù)的屏幕截圖作為模型的單個(gè)輸入,這使得我們單個(gè)輸入的尺寸為 600x150x3x4。輸入太大,需要消耗大量的計(jì)算力,而且并不是所有的特征都是有用的,所以我們使用 OpenCV 庫(kù)來(lái)調(diào)整、裁剪和處理圖像。最終處理后的輸入僅為 80x80 像素,而且是單通道(灰度,grey scale)。
def process_img(image): image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) image = image[:300, :500] return image
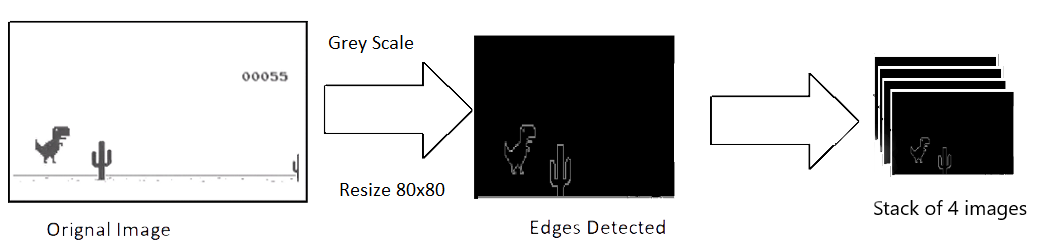
圖注:圖像處理
模型架構(gòu)
現(xiàn)在讓我們看看模型架構(gòu)。我們使用一系列的三個(gè)卷積層,然后將它們展平為密集層和輸出層。針對(duì) CPU 的模型不包括池化層,因?yàn)槲乙呀?jīng)刪除了許多特征,添加池化層會(huì)導(dǎo)致本已稀疏的特征大量丟失。但有了 GPU 之后,我們的模型可以容納更多的特征,而不用降低幀率。
最大池化圖層顯著改善了密集要素集的處理過(guò)程。
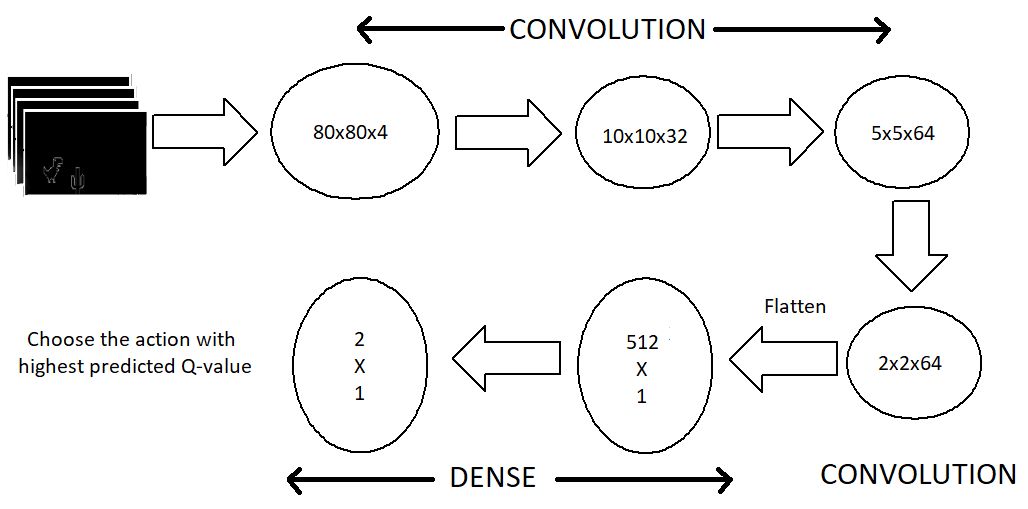
圖注:模型架構(gòu)
輸出層由兩個(gè)神經(jīng)元組成,每個(gè)神經(jīng)元代表每個(gè)動(dòng)作的最大預(yù)測(cè)回報(bào)。然后我們選擇具有最大回報(bào)( Q值)的動(dòng)作。
def buildmodel():
print("Now we build the model")
model = Sequential()
model.add(Conv2D(32, (8, 8), padding='same',strides=(4, 4),input_shape=(img_cols,img_rows,img_channels))) #80*80*4
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Activation('relu'))
model.add(Conv2D(64, (4, 4),strides=(2, 2), padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3),strides=(1, 1), padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dense(ACTIONS))
adam = Adam(lr=LEARNING_RATE)
model.compile(loss='mse',optimizer=adam)
print("We finish building the model")
return model
▌?dòng)?xùn)練
以靜止開(kāi)始,并獲得初始狀態(tài)(s_t)
觀察步驟數(shù)量
預(yù)測(cè)并執(zhí)行操作
在 Replay Memory 中存儲(chǔ)經(jīng)驗(yàn)
從 Replay Memory 中隨機(jī)選擇一個(gè)批次并在此基礎(chǔ)上訓(xùn)練模型
游戲結(jié)束后重新開(kāi)始
def trainNetwork(model,game_state):
# store the previous observations in replay memory
D = deque() #experience replay memory
# get the first state by doing nothing
do_nothing = np.zeros(ACTIONS)
do_nothing[0] =1 #0 => do nothing,
#1=> jump x_t, r_0, terminal = game_state.get_state(do_nothing) # get next step after performing the action
s_t = np.stack((x_t, x_t, x_t, x_t), axis=2).reshape(1,20,40,4) # stack 4 images to create placeholder input reshaped 1*20*40*4
OBSERVE = OBSERVATION epsilon = INITIAL_EPSILON t = 0 while (True): #endless running
loss = 0
Q_sa = 0
action_index = 0
r_t = 0 #reward at t
a_t = np.zeros([ACTIONS]) # action at t
q = model.predict(s_t)
#input a stack of 4 images, get the prediction
max_Q = np.argmax(q)
# chosing index with maximum q value
action_index = max_Q
a_t[action_index] = 1
# o=> do nothing, 1=> jump
#run the selected action and observed next state and reward
x_t1, r_t, terminal = game_state.get_state(a_t)
x_t1 = x_t1.reshape(1, x_t1.shape[0], x_t1.shape[1], 1) #1x20x40x1
s_t1 = np.append(x_t1, s_t[:, :, :, :3], axis=3) # append the new image to input stack and remove the first one
D.append((s_t, action_index, r_t, s_t1, terminal))# store the transition
#only train if done observing; sample a minibatch to train on
trainBatch(random.sample(D, BATCH)) if t > OBSERVE else 0
s_t = s_t1
t += 1
請(qǐng)注意,我們正在從 replay memory 中抽樣 32 個(gè)隨機(jī)經(jīng)驗(yàn)重放,并使用分批訓(xùn)練的方法。這樣做的原因是游戲結(jié)構(gòu)中的動(dòng)作分布不平衡以及避免過(guò)度擬合。
def trainBatch(minibatch): for i in range(0, len(minibatch)):
loss = 0
inputs = np.zeros((BATCH, s_t.shape[1], s_t.shape[2], s_t.shape[3])) #32, 20, 40, 4
targets = np.zeros((inputs.shape[0], ACTIONS))
#32, 2
state_t = minibatch[i][0] # 4D stack of images
action_t = minibatch[i][1] #This is action index
reward_t = minibatch[i][2] #reward at state_t due to action_t
state_t1 = minibatch[i][3] #next state
terminal = minibatch[i][4] #wheather the agent died or survided due the action
inputs[i:i + 1] = state_t
targets[i] = model.predict(state_t) # predicted q values
Q_sa = model.predict(state_t1)
#predict q values for next step
if terminal:
targets[i, action_t] = reward_t # if terminated, only equals reward
else:
targets[i, action_t] = reward_t + GAMMA * np.max(Q_sa)
loss += model.train_on_batch(inputs, targets)
結(jié)果
我們通過(guò)使用這種架構(gòu)獲得了良好的結(jié)果。下圖顯示了訓(xùn)練開(kāi)始時(shí)的平均分?jǐn)?shù),訓(xùn)練結(jié)束時(shí),每 10 場(chǎng)比賽的平均得分遠(yuǎn)遠(yuǎn)高于 1000 。
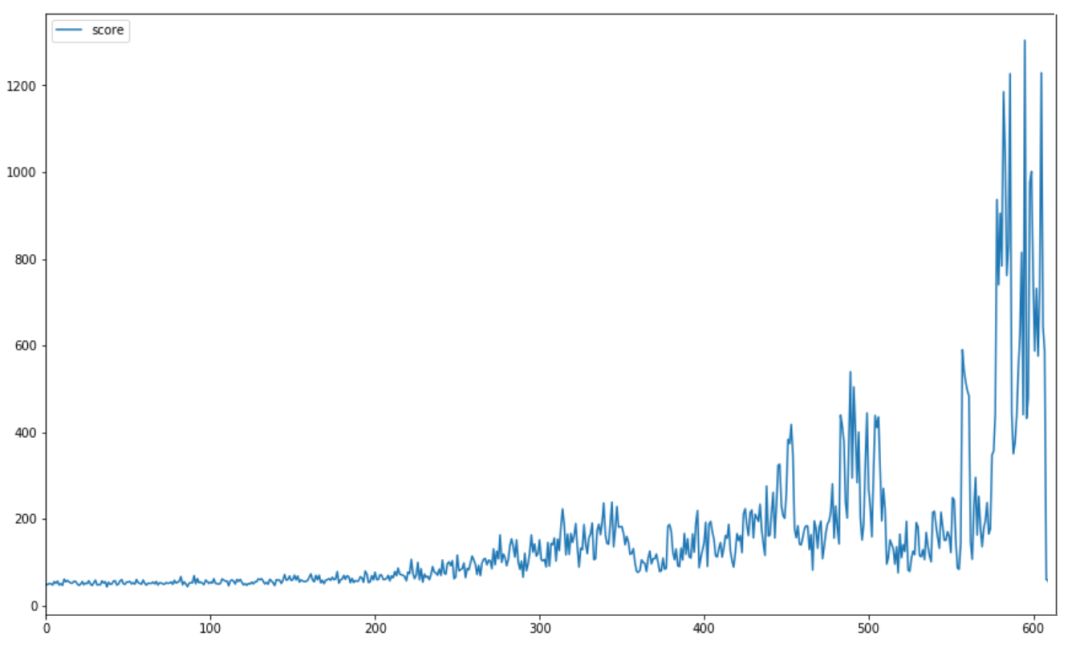
最高分?jǐn)?shù)記錄是 4000 +,遠(yuǎn)遠(yuǎn)超過(guò)了之前模型的的 250 分(也遠(yuǎn)遠(yuǎn)超過(guò)了大多數(shù)人所能做到的!) 。下圖顯示了訓(xùn)練期間比賽最高得分的進(jìn)度。
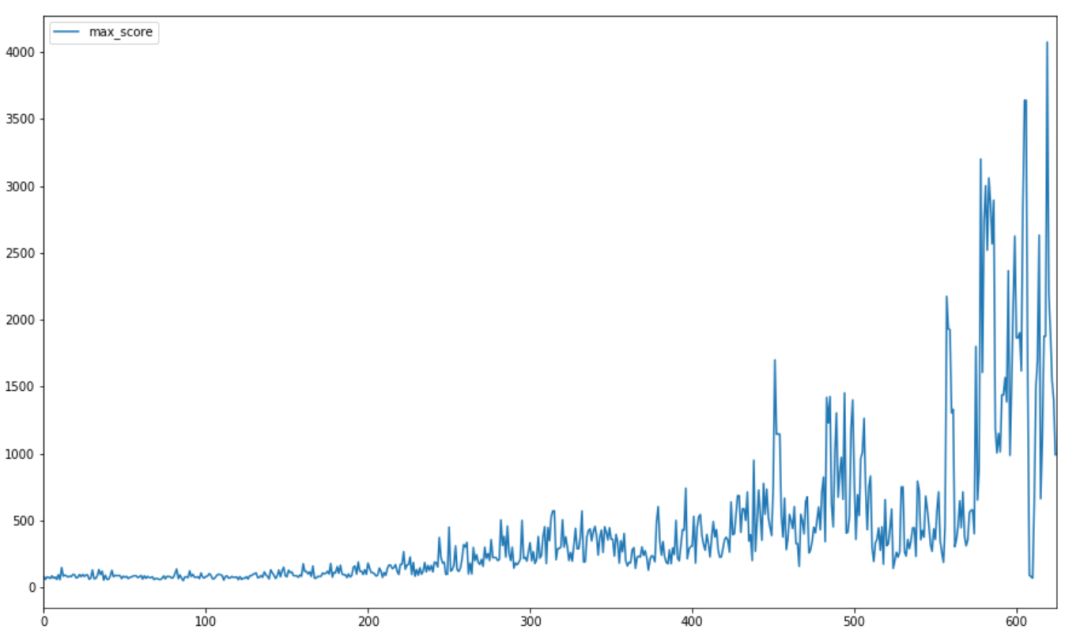
Dino 的速度與分?jǐn)?shù)成正比,這使得在更高的速度下檢測(cè)和決定一個(gè)動(dòng)作更加困難。因此,整個(gè)游戲都是以恒定速度訓(xùn)練的。
-
人工智能
+關(guān)注
關(guān)注
1799文章
47959瀏覽量
241172 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
268瀏覽量
11323
原文標(biāo)題:東北大學(xué)研究生:用強(qiáng)化學(xué)習(xí)玩Chrome里的恐龍小游戲
文章出處:【微信號(hào):AI_Thinker,微信公眾號(hào):人工智能頭條】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是深度強(qiáng)化學(xué)習(xí)?深度強(qiáng)化學(xué)習(xí)算法應(yīng)用分析

深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
將深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)相結(jié)合的深度強(qiáng)化學(xué)習(xí)DRL
薩頓科普了強(qiáng)化學(xué)習(xí)、深度強(qiáng)化學(xué)習(xí),并談到了這項(xiàng)技術(shù)的潛力和發(fā)展方向
人工智能機(jī)器學(xué)習(xí)之強(qiáng)化學(xué)習(xí)
什么是強(qiáng)化學(xué)習(xí)?純強(qiáng)化學(xué)習(xí)有意義嗎?強(qiáng)化學(xué)習(xí)有什么的致命缺陷?

基于強(qiáng)化學(xué)習(xí)的MADDPG算法原理及實(shí)現(xiàn)
深度強(qiáng)化學(xué)習(xí)你知道是什么嗎
83篇文獻(xiàn)、萬(wàn)字總結(jié)強(qiáng)化學(xué)習(xí)之路
基于深度強(qiáng)化學(xué)習(xí)的路口單交叉信號(hào)控制
基于深度強(qiáng)化學(xué)習(xí)仿真集成的壓邊力控制模型
基于深度強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)控制律設(shè)計(jì)方法
《自動(dòng)化學(xué)報(bào)》—多Agent深度強(qiáng)化學(xué)習(xí)綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論