") 基于INTEL FPGA硬浮點DSP實現(xiàn)卷積運算詳解
基于INTEL FPGA硬浮點DSP實現(xiàn)卷積運算詳解

概述
卷積是一種線性運算,其本質(zhì)是滑動平均思想,廣泛應用于圖像濾波。而隨著人工智能及深度學習的發(fā)展,卷積也在神經(jīng)網(wǎng)絡中發(fā)揮重要的作用,如卷積神經(jīng)網(wǎng)絡。本參考設計主要介紹如何基于INTEL 硬浮點的DSP Block實現(xiàn)32位單精度浮點的卷積運算,而針對定點及低精度的浮點運算,則需要對硬浮點DSP Block進行相應的替換即可。
原理分析
設:f(x), g(x)是兩個可積函數(shù),作積分:
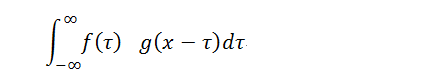
隨著x的不同取值,該積分定義了一個新的函數(shù)h(x),稱為函數(shù)f(x)與g(x)的卷積,記為h(x)=f(x)*g(x)。
如果卷積的變量是序列x(n)和h(n),則卷積的結(jié)果為
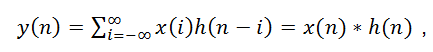
其中*表示卷積。因此兩個序列的卷積,實際上就是多項式的乘法,用個例子說明其工作原理。a = [7,5,4]; b = [6,7,9];則實現(xiàn)a和b的卷積,就是把a和b作為一個多項式的系數(shù),按多項式的升冪或降冪排列,即為:
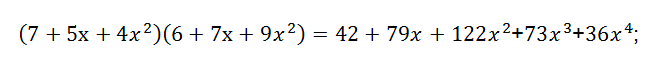
因此得到a*b=[42,79,122,73,36];與Matlab運算結(jié)果一致。而二維卷積可以采用通用多項式乘積方法實現(xiàn)卷積運算。
基于INTEL FPGA的實現(xiàn)分析
如上我們確定了兩個序列的卷積等同于兩個多項式的乘法,因此當我們需要計算序列[a0,a1,a2, …,an-1]與[b0,b1,b2, …,bn-1]的卷積結(jié)果時,可以成立a,b兩個n階多項式,如下所示:
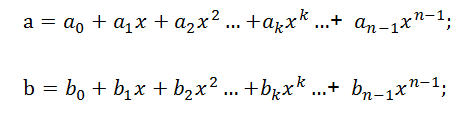
則[a0,a1,a2, …,an-1]與[b0,b1,b2, …,bn-1]的卷積結(jié)果即為由a*b得到的多項式的各項系數(shù)所組成的序列。令c=a*b,得到
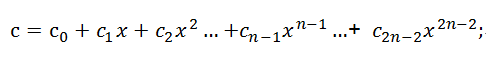
則由多項式c的各階系數(shù)所組成的新的序列[c0,c1,c2, …,c2n-1]即為[a0,a1,a2, …,an-1]與[b0,b1,b2, …,bn-1]的卷積結(jié)果。則按照高階多項式計算展開可得到:
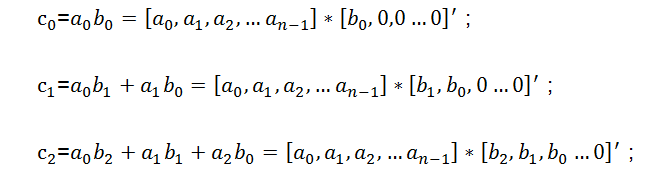
┆┆
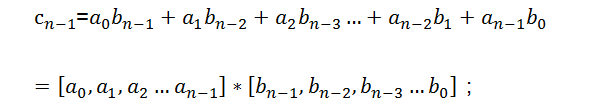
┆┆
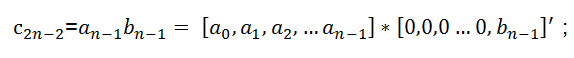
因此卷積的運算可以轉(zhuǎn)化為行向量與列向量相乘的結(jié)果,即乘累加的運算結(jié)構(gòu)。
Intel FPGA在Arria10DSP Block中首次支持了單精度硬浮點DSP block,是行業(yè)內(nèi)第一個支持單精度DSP block,硬浮點DSP block架構(gòu)如圖1所示:
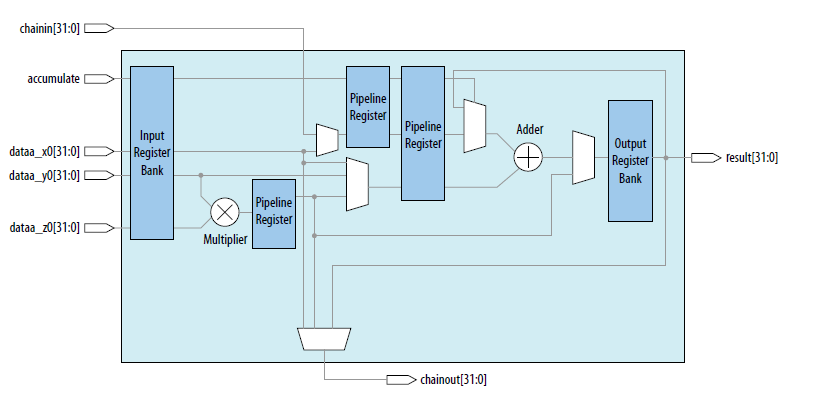
圖1 硬浮點DSPblock架構(gòu)
硬浮點DSP Block包含硬浮點乘法器,硬浮點加法器,支持乘累加運算,因此采用硬浮點DSPblock實現(xiàn)行列向量相乘是非常好的方式。下面我們針對一個實際的卷積運算,介紹如何基于INTEL硬浮點DSP block實現(xiàn)。假設我們需要求隨機數(shù)組a=[4,8,9,11]與b=[10,5,7,13]的卷積運算結(jié)果,則根據(jù)上面的分析,保持數(shù)組a順序不變,而數(shù)組b需根據(jù)上述分析結(jié)果,針對每一個卷積結(jié)果產(chǎn)生新的序列。所以整個實現(xiàn)包括數(shù)列重組模塊和硬浮點乘法器模塊及輸出處理。下面是實現(xiàn)框圖及仿真結(jié)果。
圖2 實現(xiàn)框圖
圖3 Modelsim仿真結(jié)果
仿真結(jié)果與Matlab實現(xiàn)結(jié)果一致,并且該設計中充分考慮了FPGA并行擴展特性,對于低速率要求的設計可采用DSP Block復用的方式節(jié)約DSP block數(shù)量。
-
dsp
+關注
關注
556文章
8152瀏覽量
356115 -
FPGA
+關注
關注
1644文章
22002瀏覽量
616027 -
intel
+關注
關注
19文章
3494瀏覽量
188178
原文標題:基于INTEL FPGA硬浮點DSP實現(xiàn)卷積運算
文章出處:【微信號:ALIFPGA,微信公眾號:FPGA極客空間】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
進群免費領FPGA學習資料!數(shù)字信號處理、傅里葉變換與FPGA開發(fā)等
如何使用MATLAB實現(xiàn)一維時間卷積網(wǎng)絡
FPGA圖像處理基礎----實現(xiàn)緩存卷積窗口
FPGA中的浮點四則運算是什么
FPGA中浮點四則運算的實現(xiàn)過程
卷積神經(jīng)網(wǎng)絡的基本原理與算法
FPGA加速深度學習模型的案例
如何使用高性能浮點TMS320C67x DSP立即開始開發(fā)

TMS320C6742定點和浮點DSP數(shù)據(jù)表
TMS320C6746定點和浮點DSP數(shù)據(jù)表





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論