") 混合精度訓(xùn)練的優(yōu)勢!將自動混合精度用于主流深度學(xué)習(xí)框架
混合精度訓(xùn)練的優(yōu)勢!將自動混合精度用于主流深度學(xué)習(xí)框架
傳統(tǒng)上,深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練采用的是IEEE單精度格式,但借助混合精度,可采用半精度進(jìn)行訓(xùn)練,同時保持單精度的網(wǎng)絡(luò)精度。這種同時采用單精度和半精度表示的技術(shù)被稱為混合精度技術(shù)。
混合精度訓(xùn)練的優(yōu)勢
通過使用Tensor核心,可加速數(shù)學(xué)密集型運算,如線性和卷積層。
與單精度相比,通過訪問一半的字節(jié)來加速內(nèi)存受限的運算。
降低訓(xùn)練模型的內(nèi)存要求,支持更大規(guī)模的模型或更大規(guī)模的批量訓(xùn)練。
啟用混合精度包括兩個步驟:移植模型,以適時使用半精度數(shù)據(jù)類型;以及使用損耗定標(biāo),以保留小梯度值。
僅通過添加幾行代碼,TensorFlow、PyTorch和MXNet中的自動混合精確功能就能助力深度學(xué)習(xí)研究人員和工程師基于NVIDIA Volta和Turing GPU實現(xiàn)高達(dá)3倍的AI訓(xùn)練加速。
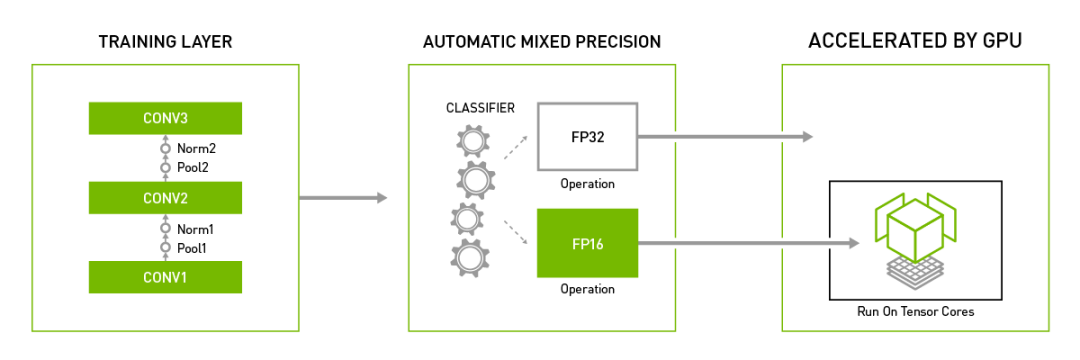
將自動混合精度用于主流深度學(xué)習(xí)框架
TensorFlow
NVIDIA NGC容器注冊表中TensorFlow容器可提供自動混合精度功能。要在容器內(nèi)啟用此功能,只需設(shè)置一個環(huán)境變量:
export TF_ENABLE_AUTO_MIXED_PRECISION=1
或者,您也可以在TensorFlow Python腳本中設(shè)置環(huán)境變量:
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
自動混合精度使用單一環(huán)境變量,在TensorFlow內(nèi)部應(yīng)用這兩個步驟,并在必要時進(jìn)行更細(xì)粒度的控制。
PyTorch
GitHub的Apex存儲庫中提供了自動混合精度功能。可將以下兩行代碼添加至當(dāng)前訓(xùn)練腳本中以啟用該功能:
model, optimizer = amp.initialize(model, optimizer)
with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()
MXNet
我們正在構(gòu)建適用于MXNet的自動混合精度功能。您可通過GitHub了解我們的工作進(jìn)展。可將以下代碼行添加至當(dāng)前訓(xùn)練腳本中以啟用該功能:
amp.init()amp.init_trainer(trainer)with amp.scale_loss(loss, trainer) as scaled_loss:autograd.backward(scaled_loss)
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4811瀏覽量
103004 -
gpu
+關(guān)注
關(guān)注
28文章
4921瀏覽量
130781 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122568
原文標(biāo)題:Tensor核心系列課 | 探究適用于深度學(xué)習(xí)的自動混合精度
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
國際巨頭重金投入,國產(chǎn)深度學(xué)習(xí)框架OneFlow有何優(yōu)勢?
混合系統(tǒng)的優(yōu)勢所在
Nanopi深度學(xué)習(xí)之路(1)深度學(xué)習(xí)框架分析
什么是深度學(xué)習(xí)?使用FPGA進(jìn)行深度學(xué)習(xí)的好處?
PyTorch 1.6即將原生支持自動混合精度訓(xùn)練
淺談字節(jié)跳動開源8比特混合精度Transformer引擎
深度學(xué)習(xí)框架是什么?深度學(xué)習(xí)框架有哪些?
深度學(xué)習(xí)框架區(qū)分訓(xùn)練還是推理嗎
深度學(xué)習(xí)框架的作用是什么
深度學(xué)習(xí)框架tensorflow介紹
深度學(xué)習(xí)算法庫框架學(xué)習(xí)
深度學(xué)習(xí)框架連接技術(shù)
深度學(xué)習(xí)框架和深度學(xué)習(xí)算法教程
視覺深度學(xué)習(xí)遷移學(xué)習(xí)訓(xùn)練框架Torchvision介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論