 電子發(fā)燒友App
電子發(fā)燒友App


機器學(xué)習和深度學(xué)習變得越來越火。突然之間,不管是了解的還是不了解的,所有人都在談?wù)摍C器學(xué)習和深度學(xué)習。無論你是否主動關(guān)注過數(shù)據(jù)科學(xué),你應(yīng)該已經(jīng)聽說過這兩個名詞了。
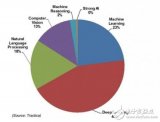
為了展示他們的火熱程度,我在 Google trend 上搜索了這些關(guān)鍵字:

?
如果你想讓自己弄清楚機器學(xué)習和深度學(xué)習的區(qū)別,請閱讀本篇文章,我將用通俗易懂的語言為你介紹他們之間的差別。下文詳細解釋了機器學(xué)習和深度學(xué)習中的術(shù)語。并且,我比較了他們兩者的不同,別說明了他們各自的使用場景。
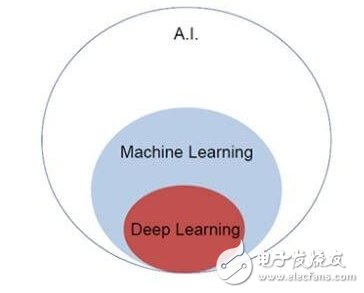
什么是機器學(xué)習和深度學(xué)習?
讓我們從基礎(chǔ)知識開始:什么是機器學(xué)習?和什么是深度學(xué)習?如果你對此已有所了解,隨時可以跳過本部分。
一、什么是機器學(xué)習?
一言以蔽之,由 Tom Mitchell 給出的被廣泛引用的機器學(xué)習的定義給出了最佳解釋。下面是其中的內(nèi)容:
“計算機程序可以在給定某種類別的任務(wù) T 和性能度量 P 下學(xué)習經(jīng)驗 E ,如果其在任務(wù) T 中的性能恰好可以用 P 度量,則隨著經(jīng)驗 E 而提高。”
是不是讀起來很繞口呢?讓我們用簡單的例子來分解下這個描述。
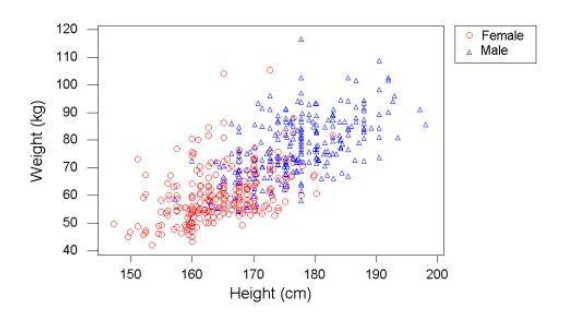
示例 1:機器學(xué)習和根據(jù)人的身高估算體重
假設(shè)你想創(chuàng)建一個能夠根據(jù)人的身高估算體重的系統(tǒng)(也許你出自某些理由對這件事情感興趣)。那么你可以使用機器學(xué)習去找出任何可能的錯誤和數(shù)據(jù)捕獲中的錯誤,首先你需要收集一些數(shù)據(jù),讓我們來看看你的數(shù)據(jù)是什么樣子的:
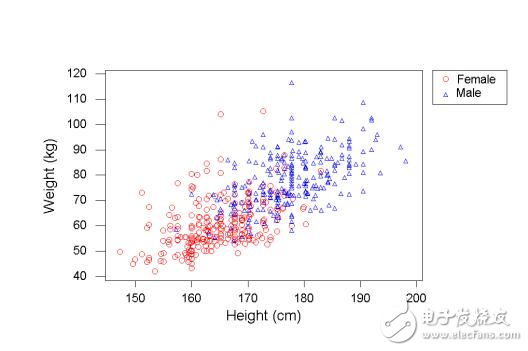
圖中的每一個點對應(yīng)一個數(shù)據(jù),我們可以畫出一條簡單的斜線來預(yù)測基于身高的體重
例如這條斜線:
Weight (in kg) = Height (in cm) - 100
這些斜線能幫助我們作出預(yù)測,盡管這些斜線表現(xiàn)得很棒,但是我們需要理解它是怎么表現(xiàn)的,我們希望去減少預(yù)測和實際之間的誤差,這也是衡量其性能的方法。
深遠一點地說,我們收集更多的數(shù)據(jù) (experience),模型就會變得更好。我們也可以通過添加更多變量(例如性別)和添加不同的預(yù)測斜線來完善我們的模型。
示例2:颶風預(yù)測系統(tǒng)
我們找一個復(fù)雜一點的例子。假如你要構(gòu)建一個颶風預(yù)測系統(tǒng)。假設(shè)你手里有所有以前發(fā)生過的颶風的數(shù)據(jù)和這次颶風產(chǎn)生前三個月的天氣信息。
如果要手動構(gòu)建一個颶風預(yù)測系統(tǒng),我們應(yīng)該怎么做?
?
首先我們的任務(wù)是清洗所有的數(shù)據(jù)找到數(shù)據(jù)里面的模式進而查找產(chǎn)生颶風的條件。
我們既可以將模型條件數(shù)據(jù)(例如氣溫高于40度,濕度在80-100等)輸入到我們的系統(tǒng)里面生成輸出;也可以讓我們的系統(tǒng)自己通過這些條件數(shù)據(jù)產(chǎn)生合適的輸出。
我們可以把所有以前的數(shù)據(jù)輸入到系統(tǒng)里面來預(yù)測未來是否會有颶風。基于我們系統(tǒng)條件的取值,評估系統(tǒng)的性能(系統(tǒng)正確預(yù)測颶風的次數(shù))。我們可以將系統(tǒng)預(yù)測結(jié)果作為反饋繼續(xù)多次迭代以上步驟。
讓我們根據(jù)前邊的解釋來定義我們的預(yù)測系統(tǒng):我們的任務(wù)是確定可能產(chǎn)生颶風的氣象條件。性能P是在系統(tǒng)所有給定的條件下有多少次正確預(yù)測颶風。經(jīng)驗E是我們的系統(tǒng)的迭代次數(shù)。
二、什么是深度學(xué)習?
深度學(xué)習的概念并不新穎。它已經(jīng)存在好幾年了。但伴隨著現(xiàn)有的所有的炒作,深度的學(xué)習越來越受到重視。正如我們在機器學(xué)習中所做的那樣,先來看看深度學(xué)習的官方定義,然后用一個例子來解釋。
“深度學(xué)習是一種特殊的機器學(xué)習,通過學(xué)習將世界使用嵌套的概念層次來表示并實現(xiàn)巨大的功能和靈活性,其中每個概念都定義為與簡單概念相關(guān)聯(lián),而更為抽象的表示則以較不抽象的方式來計算。”
這也有點讓人混亂。下面使用一個簡單示例來分解下此概念。
示例1: 形狀檢測
先從一個簡單的例子開始,從概念層面上解釋究竟發(fā)生了什么的事情。我們來試試看如何從其他形狀中識別的正方形。
?
我們眼中的第一件事是檢查圖中是否有四條的線(簡單的概念)。如果我們找到這樣的四條線,我們進一步檢查它們是相連的、閉合的和相互垂直的,并且它們是否是相等的(嵌套的概念層次結(jié)構(gòu))。
所以,我們完成了一個復(fù)雜的任務(wù)(識別一個正方形),并以簡單、不太抽象的任務(wù)來完成它。深度學(xué)習本質(zhì)上在大規(guī)模執(zhí)行類似邏輯。
示例2: 貓 vs狗
我們舉一個動物辨識的例子,其中我們的系統(tǒng)必須識別給定的圖像中的動物是貓還是狗。閱讀下此文,以了解深度學(xué)習在解決此類問題上如何比機器學(xué)習領(lǐng)先一步。
機器學(xué)習和深度學(xué)習的對比
現(xiàn)在的你應(yīng)該已經(jīng)對機器學(xué)習和深度學(xué)習有所了解,接下來我們將會學(xué)習其中一些重點,并比較兩種技術(shù)。
數(shù)據(jù)依賴性
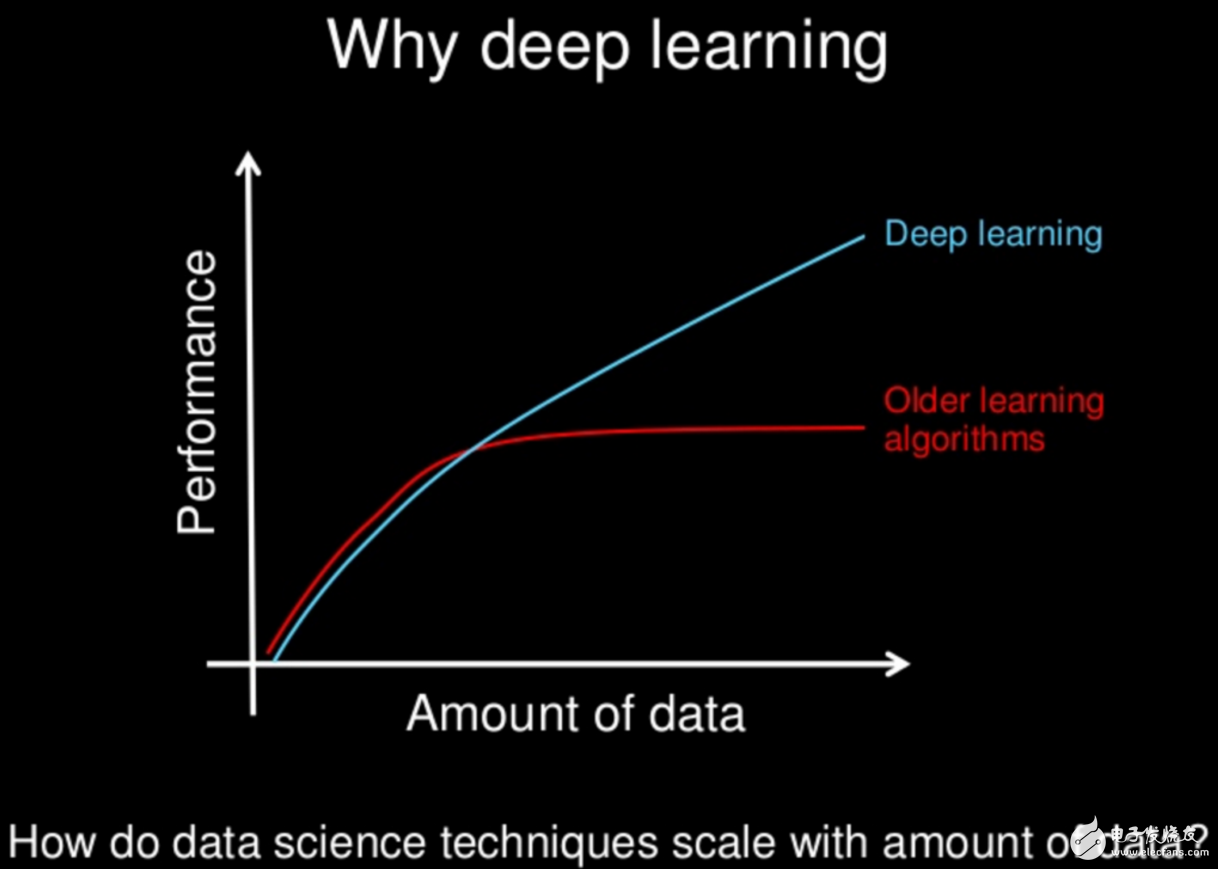
深度學(xué)習與傳統(tǒng)的機器學(xué)習最主要的區(qū)別在于隨著數(shù)據(jù)規(guī)模的增加其性能也不斷增長。當數(shù)據(jù)很少時,深度學(xué)習算法的性能并不好。這是因為深度學(xué)習算法需要大量的數(shù)據(jù)來完美地理解它。另一方面,在這種情況下,傳統(tǒng)的機器學(xué)習算法使用制定的規(guī)則,性能會比較好。下圖總結(jié)了這一事實。
?
硬件依賴
深度學(xué)習算法需要進行大量的矩陣運算,GPU 主要用來高效優(yōu)化矩陣運算,所以 GPU 是深度學(xué)習正常工作的必須硬件。與傳統(tǒng)機器學(xué)習算法相比,深度學(xué)習更依賴安裝 GPU 的高端機器。
特征處理
特征處理是將領(lǐng)域知識放入特征提取器里面來減少數(shù)據(jù)的復(fù)雜度并生成使學(xué)習算法工作的更好的模式的過程。特征處理過程很耗時而且需要專業(yè)知識。
在機器學(xué)習中,大多數(shù)應(yīng)用的特征都需要專家確定然后編碼為一種數(shù)據(jù)類型。
特征可以使像素值、形狀、紋理、位置和方向。大多數(shù)機器學(xué)習算法的性能依賴于所提取的特征的準確度。
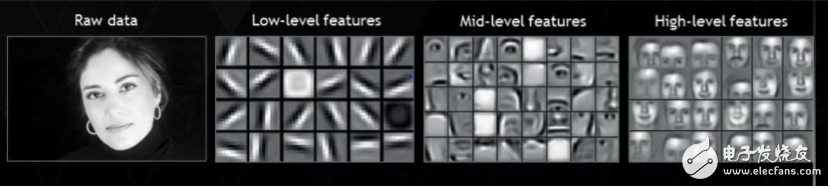
深度學(xué)習嘗試從數(shù)據(jù)中直接獲取高等級的特征,這是深度學(xué)習與傳統(tǒng)機器學(xué)習算法的主要的不同。基于此,深度學(xué)習削減了對每一個問題設(shè)計特征提取器的工作。例如,卷積神經(jīng)網(wǎng)絡(luò)嘗試在前邊的層學(xué)習低等級的特征(邊界,線條),然后學(xué)習部分人臉,然后是高級的人臉的描述。更多信息可以閱讀神經(jīng)網(wǎng)絡(luò)機器在深度學(xué)習里面的有趣應(yīng)用。
?
問題解決方式
當應(yīng)用傳統(tǒng)機器學(xué)習算法解決問題的時候,傳統(tǒng)機器學(xué)習通常會將問題分解為多個子問題并逐個子問題解決最后結(jié)合所有子問題的結(jié)果獲得最終結(jié)果。相反,深度學(xué)習提倡直接的端到端的解決問題。
舉例說明:
假設(shè)有一個多物體檢測的任務(wù)需要圖像中的物體的類型和各物體在圖像中的位置。

?
傳統(tǒng)機器學(xué)會將問題分解為兩步:物體檢測和物體識別。首先,使用一個邊界框檢測算法掃描整張圖片找到可能的是物體的區(qū)域;然后使用物體識別算法(例如 SVM 結(jié)合 HOG )對上一步檢測出來的物體進行識別。
相反,深度學(xué)習會直接將輸入數(shù)據(jù)進行運算得到輸出結(jié)果。例如可以直接將圖片傳給 YOLO 網(wǎng)絡(luò)(一種深度學(xué)習算法),YOLO 網(wǎng)絡(luò)會給出圖片中的物體和名稱。
執(zhí)行時間
通常情況下,訓(xùn)練一個深度學(xué)習算法需要很長的時間。這是因為深度學(xué)習算法中參數(shù)很多,因此訓(xùn)練算法需要消耗更長的時間。最先進的深度學(xué)習算法 ResNet完整地訓(xùn)練一次需要消耗兩周的時間,而機器學(xué)習的訓(xùn)練會消耗的時間相對較少,只需要幾秒鐘到幾小時的時間。
但兩者測試的時間上是完全相反。深度學(xué)習算法在測試時只需要很少的時間去運行。如果跟 k-nearest neighbors(一種機器學(xué)習算法)相比較,測試時間會隨著數(shù)據(jù)量的提升而增加。不過這不適用于所有的機器學(xué)習算法,因為有些機器學(xué)習算法的測試時間也很短。
可解釋性
至關(guān)重要的一點,我們把可解釋性作為比較機器學(xué)習和深度學(xué)習的一個因素。
我們看個例子。假設(shè)我們適用深度學(xué)習去自動為文章評分。深度學(xué)習可以達到接近人的標準,這是相當驚人的性能表現(xiàn)。但是這仍然有個問題。深度學(xué)習算法不會告訴你為什么它會給出這個分數(shù)。當然,在數(shù)學(xué)的角度上,你可以找出來哪一個深度神經(jīng)網(wǎng)絡(luò)節(jié)點被激活了。但是我們不知道神經(jīng)元應(yīng)該是什么模型,我們也不知道這些神經(jīng)單元層要共同做什么。所以無法解釋結(jié)果是如何產(chǎn)生的。
另一方面,為了解釋為什么算法這樣選擇,像決策樹(decision trees)這樣機器學(xué)習算法給出了明確的規(guī)則,所以解釋決策背后的推理是很容易的。因此,決策樹和線性/邏輯回歸這樣的算法主要用于工業(yè)上的可解釋性。




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論