一、引言 隨著深度學習技術的快速發展,其在語音識別領域的應用也日益廣泛。深度學習技術可以有效地提高語音識別的精度和效率,并且被廣泛應用于各種應用場景。本文將探討深度學習在語音識別中的應用及所面臨
2023-10-10 18:14:53 129
129 深度學習作為機器學習的一個分支,其學習方法可以分為監督學習和無監督學習。兩種方法都具有其獨特的學習模型:多層感知機 、卷積神經網絡等屬于監 督學習;深度置信網 、自動編碼器 、去噪自動編碼器 、稀疏編碼等屬于無監督學習。
2023-10-09 10:23:4256 
深度學習這幾年特別火,就像5年前的大數據一樣,不過深度學習其主要還是屬于機器學習的范疇領域內,所以這篇文章里面我們來嘮一嘮機器學習和深度學習的算法流程區別。
2023-09-06 12:48:40230 
機器學習和深度學習是當今最流行的人工智能(AI)技術之一。這兩種技術都有助于在不需要人類干預的情況下讓計算機自主學習和改進預測模型。本文將探討機器學習和深度學習的概念以及二者之間的區別。
2023-08-28 17:31:09249 機器學習和深度學習的區別 隨著人工智能技術的不斷發展,機器學習和深度學習已經成為大家熟知的兩個術語。雖然它們都屬于人工智能技術的研究領域,但它們之間有很大的差異。本文將詳細介紹機器學習和深度學習
2023-08-17 16:11:40880 深度學習服務器怎么做 深度學習服務器diy 深度學習服務器主板用什么? 隨著人工智能的飛速發展,越來越多的人開始投身于深度學習領域。但是,隨著深度學習的算法越來越復雜,需要更大的計算能力才能運行
2023-08-17 16:11:29227 深度學習框架和深度學習算法教程 深度學習是機器學習領域中的一個重要分支,多年來深度學習一直在各個領域的應用中發揮著極其重要的作用,成為了人工智能技術的重要組成部分。許多深度學習算法和框架提供了
2023-08-17 16:11:26281 深度學習cntk框架介紹? 深度學習是最近幾年來非常熱門的話題,它正在徹底改變我們生活和工作的方式。隨著越來越多的創新和發展,人工智能和機器學習的應用范圍正在大大擴展。而對于深度學習這個領域來說
2023-08-17 16:11:23313 深度學習框架連接技術 深度學習框架是一個能夠幫助機器學習和人工智能開發人員輕松進行模型訓練、優化及評估的軟件庫。深度學習框架連接技術則是需要使用深度學習模型的應用程序必不可少的技術,通過連接技術
2023-08-17 16:11:16193 深度學習框架對照表? 隨著人工智能技術的發展,深度學習正在成為當今最熱門的研究領域之一。而深度學習框架作為執行深度學習算法的最重要的工具之一,也隨著深度學習的發展而越來越成熟。本文將介紹一些常見
2023-08-17 16:11:13199 深度學習算法庫框架學習 深度學習是一種非常強大的機器學習方法,它可以用于許多不同的應用程序,例如計算機視覺、語言處理和自然語言處理。然而,實現深度學習技術需要使用一些算法庫框架。在本文中,我們將探討
2023-08-17 16:11:07182 深度學習算法的選擇建議 隨著深度學習技術的普及,越來越多的開發者將它應用于各種領域,包括圖像識別、自然語言處理、聲音識別等等。對于剛開始學習深度學習的開發者來說,選擇適合自己的算法和框架是非
2023-08-17 16:11:05187 深度學習框架tensorflow介紹 深度學習框架TensorFlow簡介 深度學習框架TensorFlow由Google開發,是一個開放源代碼的深度學習框架,可用于構建人工智能應用程序
2023-08-17 16:11:02484 的任務,需要使用深度學習框架。 深度學習框架是對深度學習算法和神經網絡模型進行構建、調整和優化的軟件工具集。這些框架不僅能夠提高深度學習的效率,還能使開發者更好地理解和操作深度學習。 以下是深度學習框架的作用:
2023-08-17 16:10:57421 深度學習框架區分訓練還是推理嗎 深度學習框架是一個非常重要的技術,它們能夠加速深度學習的開發與部署過程。在深度學習中,我們通常需要進行兩個關鍵的任務,即訓練和推理。訓練是指使用訓練數據訓練神經網絡
2023-08-17 16:03:11283 深度學習框架是什么?深度學習框架有哪些?? 深度學習框架是一種軟件工具,它可以幫助開發者輕松快速地構建和訓練深度神經網絡模型。與手動編寫代碼相比,深度學習框架可以大大減少開發和調試的時間和精力,并提
2023-08-17 16:03:09541 深度學習框架pytorch入門與實踐 深度學習是機器學習中的一個分支,它使用多層神經網絡對大量數據進行學習,以實現人工智能的目標。在實現深度學習的過程中,選擇一個適用的開發框架是非常關鍵
2023-08-17 16:03:06315 什么是深度學習算法?深度學習算法的應用 深度學習算法被認為是人工智能的核心,它是一種模仿人類大腦神經元的計算模型。深度學習是機器學習的一種變體,主要通過變換各種架構來對大量數據進行學習以及分類處理
2023-08-17 16:03:04469 醫療、金融、自然語言處理、智能交通等等。 作為深度學習算法工程師,他們需要具備一定的技能和知識,包括數學基礎(如線性代數、微積分、概率論等)、編程語言(如Python、C++、Matlab等)、機器學習算法、深度學習算法(如神
2023-08-17 16:03:01312 深度學習是什么領域? 深度學習是機器學習的一種子集,由多層神經網絡組成。它是一種自動學習技術,可以從數據中學習高層次的抽象模型,以進行推斷和預測。深度學習廣泛應用于計算機視覺、語音識別、自然語言處理
2023-08-17 16:02:59335 深度學習算法簡介 深度學習算法是什么?深度學習算法有哪些?? 作為一種現代化、前沿化的技術,深度學習已經在很多領域得到了廣泛的應用,其能夠不斷地從數據中提取最基本的特征,從而對大量的信息進行機器學習
2023-08-17 16:02:562739 ,需要執行一些策略。在本文中,我們將討論七種深度學習策略,這些策略可以幫助人們更好地發掘深度學習的潛力。 1. 找到更多的數據 深度學習的核心就是數據,它需要足夠多的數據才能發揮最大的效果。因此,深度學習的第一項策
2023-08-17 16:02:53396 深度學習基本概念? 深度學習是人工智能(AI)領域的一個重要分支,它模仿人類神經系統的工作方式,使用大量數據訓練神經網絡,從而實現自動化的模式識別和決策。在科技發展的今天,深度學習已經成為了計算機
2023-08-17 16:02:49272 和層次,分析人工智能需要學習的內容。 1. 數據學習 人工智能最根本的就是數據,只有通過數據的學習和處理,才能讓機器更智能。在數據學習中,包含了很多重要的方面,如機器學習和深度學習等。機器學習是為了讓機器從數據中
2023-08-12 17:12:21252 深度學習和神經網絡的區別在于隱藏層的深度。一般來說,神經網絡的隱藏層要比實現深度學習的系統淺得多,而深度學習的在隱藏層可以有很多層。
2023-07-28 10:44:27207 
可擴展且保密的深度學習
2023-06-28 16:09:14121 
深度學習是機器學習的一個類型,該類型的模型直接從圖像、文本或聲音中學習執行分類任務。通常使用神經網絡架構實現深度學習。“深度”一詞是指網絡中的層數 — 層數越多,網絡越深。傳統的神經網絡只包含 2 層或 3 層,而深度網絡可能有幾百層。
2023-05-29 09:16:00 1
1 今天我想要與大家分享的是深度神經網絡的工作方式,以及深度神經與“傳統”機器學習模型的不同之處。
2023-05-25 15:13:54163 
深度學習可以學習視覺輸入的模式,以預測組成圖像的對象類。用于圖像處理的主要深度學習架構是卷積神經網絡(CNN),或者是特定的CNN框架,如AlexNet、VGG、Inception和ResNet。計算機視覺的深度學習模型通常在專門的圖形處理單元(GPU)上訓練和執行,以減少計算時間。
2023-05-05 11:35:28367 智造之眼?科學設計深度學習各應用流程,在盡量簡化前期準備工作的基礎上為客戶提供穩定且準確的深度學習解決方案。
2023-05-04 16:55:52216 
人工智能包含了機器學習和深度學習。你可以在圖中看到,機器學習是人工智能的子集,深度學習是機器學習的子集。所以人工智能、機器學習和深度學習這三者的關系就像爺爺、父親與兒子。
2023-03-29 11:04:10680 
這是新的系列教程,在本教程中,我們將介紹使用 FPGA 實現深度學習的技術,深度學習是近年來人工智能領域的熱門話題。
2023-03-03 09:52:13860 是示波器所能存儲的采樣點多少的量度。如果您需要不間斷的捕捉一個脈沖串,則要求示波器有足夠的存儲器以便捕捉整個事件。將所要捕捉的時間長度除以精確重現信號所須的取樣速度,可以計算出所要求的存儲深度,也稱記錄
2012-05-07 10:46:58
與傳統機器學習相比,深度學習是從數據中學習,而大模型則是通過使用大量的模型來訓練數據。深度學習可以處理任何類型的數據,例如圖片、文本等等;但是這些數據很難用機器完成。大模型可以訓練更多類別、多個級別的模型,因此可以處理更廣泛的類型。另外:在使用大模型時,可能需要一個更全面或復雜的數學和數值計算的支持。
2023-02-16 11:32:371299 也許現在正是討論人工智能(AI)的好時候,自 2012 年深度學習「革命」以來,距今正好過去了 10 年時間。
2023-02-07 09:49:17174 人工智能的概念在1956年就被提出,如今終于走入現實,離不開一種名為“深度學習”的技術。深度學習的運作模式,如同一場傳話游戲。給神經網絡輸入數據,對數據的特征進行描述,在神經網絡中層層傳遞,最終再
2023-01-14 23:34:43427 
GPU 引領的深度學習
2023-01-04 11:17:16342 與此同時,Boaz Barak 通過展示擬合統計模型和學習數學這兩個不同的場景案例,探討其與深度學習的匹配性;他認為,雖然深度學習的數學和代碼與擬合統計模型幾乎相同,但在更深層次上,深度學習中的極大部分都可在“向學生傳授技能”場景中被捕獲。
2022-08-09 10:01:10777 深度學習是機器學習的一個子集,它使用神經網絡來執行學習和預測。深度學習在各種任務中都表現出了驚人的表現,無論是文本、時間序列還是計算機視覺。
2022-04-07 10:17:051186 ? 本文將帶您了解深度學習的工作原理與相關案例。 什么是深度學習? 深度學習是機器學習的一個子集,與眾不同之處在于,DL 算法可以自動從圖像、視頻或文本等數據中學習表征,無需引入人類領域的知識。深度
2022-04-01 10:34:107383 , GBRT)等簡單機器學習模型,而且增強了這樣一種預期,即機器學習領域的時間序列預測模型需要以深度學習工作為基礎,才能得到 SOTA 結果。
2022-03-24 13:59:241263 本文大致介紹將深度學習算法模型移植到海思AI芯片的總體流程和一些需要注意的細節。海思芯片移植深度學習算法模型,大致分為模型轉換,...
2022-01-26 19:42:3511 到準備模型,然后再在邊緣的嵌入式系統上運行。訓練深度學習模型是過程的工作量和時間密集型部分,其中通過提供需要時間和
2021-10-20 19:05:5842 Python深度學習教材資料下載。
2021-06-01 14:40:3236 諸如大數據和人工智能之類的新興技術正以驚人的速度發展,并且在深度學習方面取得了令人難以置信的進步,這在一定程度上使其成為可能。
2021-04-14 17:20:082319 深度學習算法現在是圖像處理軟件庫的組成部分。在他們的幫助下,可以學習和訓練復雜的功能;但他們的應用也不是萬能的。 “機器學習”和“深度學習”有什么區別? 在機器視覺和深度學習中,人類視覺的力量和對視
2021-03-12 16:11:007322 
繼系列上一篇 所以,機器學習和深度學習的區別是什么?淺談后,今天繼續深入探討兩者的更多區別。
2021-03-01 15:44:4215545 Abstract 主動學習試圖通過標記最少量的樣本使得模型的性能收益最大化。而深度學習則對數據比較貪婪,需要大量的數據供給來優化海量的參數,從而使得模型學會如何提取高質量的特征。近年來,由于互聯網
2021-02-17 11:55:002889 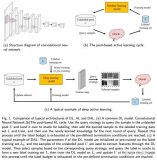
回顧深度學習框架的演變,我們可以清楚地看到深度學習框架和深度學習算法之間的緊密耦合關系。這種相互依賴的良性循環推動了深度學習框架和工具的快速發展。
2021-01-21 13:46:552318 深度學習是機器學習與神經網絡、人工智能、圖形化建模、優化、模式識別和信號處理等技術融合后產生的一個領域。
2020-11-05 09:31:194448 前言 做深度學習加速器已經兩年了,從RTL設計到仿真驗證,以及相應的去了解了Linux驅動,深度學習壓縮方法等等。今天來捋一捋AI加速器都涉及到哪些領域,需要哪些方面的知識。可以用于AI加速器
2020-10-10 16:25:433168 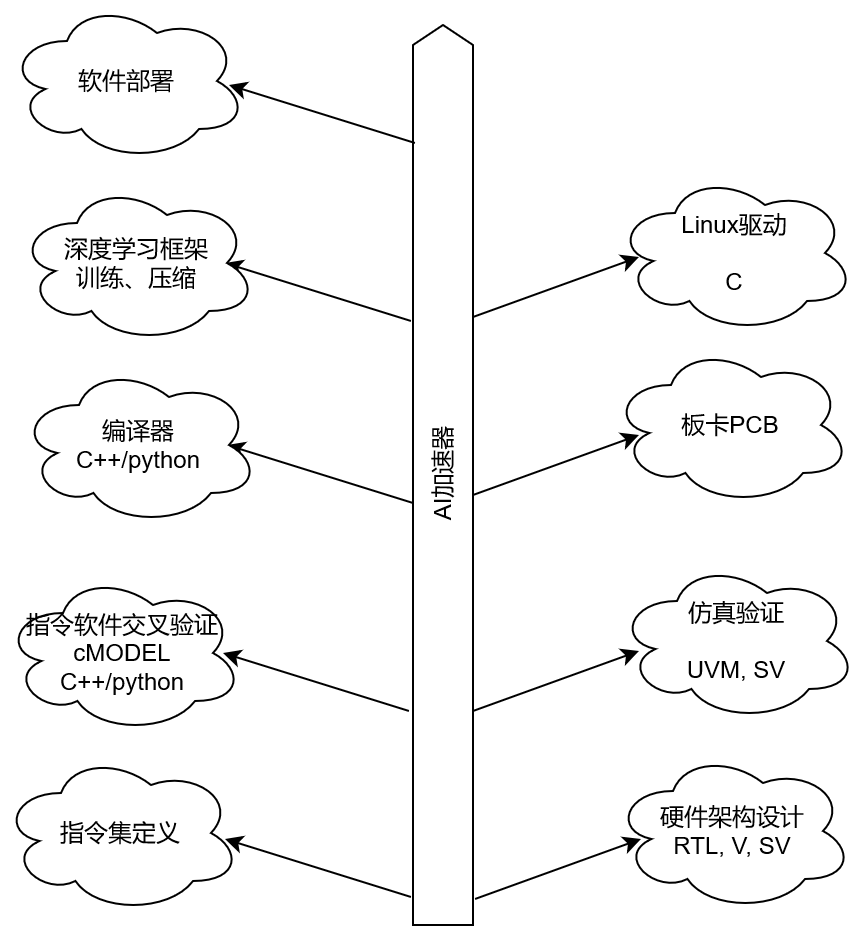
不過,深度神經網絡系統往往需要大量的訓練數據,以及已知答案的帶標簽樣本,才能正常地工作。并且,它們目前尚無法完全模仿人類學習和運用智慧的方式。
2020-08-28 14:21:065229 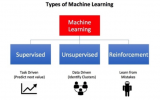
如果你需要深度學習模型,那么 PyTorch 和 TensorFlow 都是不錯的選擇。
并非每個回歸或分類問題都需要通過深度學習來解決。甚至可以說,并非每個回歸或分類問題都需要通過機器學習來解決。畢竟,許多數據集可以用解析方法或簡單的統計過程進行建模。
2019-09-14 10:57:002992 本文從硬件加速的視角考察深度學習與FPGA,指出有哪些趨勢和創新使得這些技術相互匹配,并激發對FPGA如何幫助深度學習領域發展的探討。
2019-06-28 17:31:466298 近年來,隨著科技的快速發展,人工智能不斷進入我們的視野中。作為人工智能的核心技術,機器學習和深度學習也變得越來越火。一時間,它們幾乎成為了每個人都在談論的話題。那么,機器學習和深度學習到底是什么,它們之間究竟有什么不同呢?
2019-05-11 10:13:133054 ACM剛剛公布2018年圖靈獎獲得者,深度學習三巨頭:Yoshua Bengio、Geoffrey Hinton、Yann LeCun獲獎,深度學習獲得了最高榮譽。三巨頭獲獎的背后,是一段經歷了寒冬的艱辛之路。
2019-04-03 09:45:143281 深度學習到底有多熱,這里我就不再強調了,也因此有很多人關心這樣的幾個問題,“適不適合轉行深度學習(機器學習)”,“怎么樣轉行深度學習(機器學習)”,“轉行深度學習需要哪些入門材料?”等等。
2018-10-19 14:07:192332 本深度學習是什么?了解深度學習難嗎?讓你快速了解深度學習的視頻講解本文檔視頻讓你4分鐘快速了解深度學習
深度學習的概念源于人工智能的人工神經網絡的研究。含多隱層的多層感知器就是一種深度學習結構。深度學習通過組合低層特征形成更加抽象的高層表示屬性類別或特征,以發現數據的分布式特征表示。
2018-08-23 14:36:1616 谷歌技術人員、MIT博士Ali Rahimi受光學的啟發,從功能模塊化和層級的角度討論了一種解釋深度學習的新思路。
2018-07-10 08:46:092021 大數據人工智能技術,在應用層面包括機器學習、神經網絡、深度學習等,它們都是現代人工智能的核心技術。在大數據背景下,這些技術均得到了質的提升,人工智能、機器學習和深度學習的包含關系如下圖。
2018-07-01 10:17:001648 深度強化學習DRL自提出以來, 已在理論和應用方面均取得了顯著的成果。尤其是谷歌DeepMind團隊基于深度強化學習DRL研發的AlphaGo,將深度強化學習DRL成推上新的熱點和高度,成為人工智能歷史上一個新的里程碑。因此,深度強化學習DRL非常值得研究。
2018-06-29 18:36:0027300 近年來,深度學習作為機器學習中比較火的一種方法出現在我們面前,但是和非深度學習的機器學習相比(我將深度學習歸于機器學習的領域內),還存在著幾點很大的不同,具體來說,有以下幾點.
2018-05-02 10:30:004008 深度學習框架是幫助使用者進行深度學習的工具,它的出現降低了深度學習入門的門檻,你不需要從復雜的神經網絡開始編代碼,就可以根據需要使用現有的模型。 做個比喻,一套深度學習框架就像是一套積木,各個組件就是某個模型或算法的一部分,使用者可以自己設計和組裝符合相關數據集需求的積木。
2018-02-13 03:43:002813 淺談深度學習的架構,主要可分為訓練(Training)與推論(Inference)兩個階段。簡單來說,就是訓練機器學習,以及讓機器展現學習成果。再進一步談深度學習的運算架構,NVIDIA解決方案架構經理康勝閔簡單統整,定義出幾個步驟。
2018-02-09 08:48:312695 《理解深度學習需要重新思考泛化》論文引起了人們的深思,也有很多人表示不解。也曾在Quora上討論過。Google Brain工程師Eric Jang認為深度學習的工作機制,能促進深度學習在生活周圍的應用,Zhang et al.2016可能會成為一個重要的風向標。
2018-01-06 09:31:09836 深度學習與傳統的機器學習最主要的區別在于隨著數據規模的增加其性能也不斷增長。當數據很少時,深度學習算法的性能并不好。這是因為深度學習算法需要大量的數據來完美地理解它。另一方面,在這種情況下,傳統的機器學習算法使用制定的規則,性能會比較好。
2017-10-27 16:50:181583 
深度學習技術 這一輪AI的技術突破,主要源于深度學習技術,而關于AI和深度學習的發展歷史我們這里不重復講述,可自行查閱。我用了一個多月的業務時間,去了解和學習了深度學習技術,在這里,我嘗試以一名業務
2017-09-30 14:35:192 項目組基于深度學習實現了視頻風格化和人像摳圖的功能,但這是在PC/服務端上跑的,現在需要移植到移動端,因此需要一個移動端的深度學習的計算框架。 同類型的庫 caffe-Android-lib 目前
2017-09-28 20:02:260 本文我們就來分析目前主流的深度學習芯片的優缺點。 CPU 不適合深度學習 深度學習與傳統計算模式最大的區別就是不需要編程,它是從輸入的大量數據中自發地總結出規律,而傳統計算模式更多都需要人為提取所需
2017-09-27 15:24:592 深度學習在這十年,甚至是未來幾十年內都有可能是最熱門的話題。雖然深度學習已是廣為人知了,但它并不僅僅包含數學、建模、學習和優化。算法必須在優化后的硬件上運行,因為學習成千上萬的數據可能需要長達幾周的時間。因此,深度學習網絡亟需更快、更高效的硬件。接下來,讓我們重點來看深度學習的硬件架構。
2016-11-18 16:00:375472 FPGA是深度學習的未來,學習資料,感興趣的可以看看。
2016-10-26 15:29:0415 為幫助數據科學家和開發人員充分利用深度學習領域中的機遇,NVIDIA為其深度學習軟件平臺發布了三項重大更新,它們分別是NVIDIA DIGITS 4、CUDA深度神經網絡庫(cuDNN)5.1和全新的GPU推理引擎(GIE)。
NVIDIA深度學習軟件平臺推三項重大更新
2016-08-06 15:00:261739
 電子發燒友App
電子發燒友App









 工商網監
工商網監
評論