 電子發燒友App
電子發燒友App


小米業務線眾多,從信息流,電商,廣告到金融等覆蓋了眾多領域,小米流式平臺為小米集團各業務提供一體化的流式數據解決方案,主要包括數據采集,數據集成和流式計算三個模塊。目前每天數據量達到 1.2 萬億條,實時同步任務 1.5 萬,實時計算的數據 1 萬億條。
伴隨著小米業務的發展,流式平臺也經歷三次大升級改造,滿足了眾多業務的各種需求。最新的一次迭代基于 Apache Flink,對于流式平臺內部模塊進行了徹底的重構,同時小米各業務也在由 Spark Streaming 逐步切換到 Flink。
背景介紹
小米流式平臺的愿景是為小米所有的業務線提供流式數據的一體化、平臺化解決方案。具體來講包括以下三個方面:
流式數據存儲:流式數據存儲指的是消息隊列,小米開發了一套自己的消息隊列,其類似于 Apache kafka,但它有自己的特點,小米流式平臺提供消息隊列的存儲功能;
流式數據接入和轉儲:有了消息隊列來做流式數據的緩存區之后,繼而需要提供流式數據接入和轉儲的功能;
流式數據處理:指的是平臺基于 Flink、Spark Streaming 和 Storm 等計算引擎對流式數據進行處理的過程。

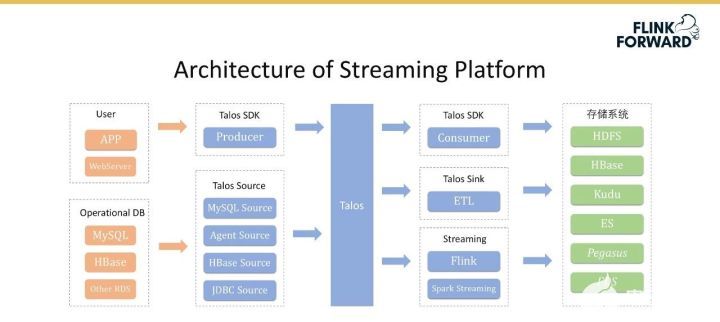
下圖展示了流式平臺的整體架構。從左到右第一列橙色部分是數據源,包含兩部分,即 User 和 Database。
User 指的是用戶各種各樣的埋點數據,如用戶 APP 和 WebServer 的日志,其次是 Database 數據,如 MySQL、HBase 和其他的 RDS 數據。
中間藍色部分是流式平臺的具體內容,其中 Talos 是小米實現的消息隊列,其上層包含 Consumer SDK 和 Producer SDK。
此外小米還實現了一套完整的 Talos Source,主要用于收集剛才提到的用戶和數據庫的全場景的數據。
Talos Sink 和 Source 共同組合成一個數據流服務,主要負責將 Talos 的數據以極低的延遲轉儲到其他系統中;Sink 是一套標準化的服務,但其不夠定制化,后續會基于 Flink SQL 重構 Talos Sink 模塊。
下圖展示了小米的業務規模。在存儲層面小米每天大概有 1.2 萬億條消息,峰值流量可以達到 4300 萬條每秒。轉儲模塊僅 Talos Sink 每天轉儲的數據量就高達 1.6 PB,轉儲作業目前將近有 1.5 萬個。每天的流式計算作業超過 800 個,Flink 作業超過 200 個,Flink 每天處理的消息量可以達到 7000 億條,數據量在 1 PB 以上。

小米流式平臺發展歷史
小米流式平臺發展歷史分為如下三個階段:
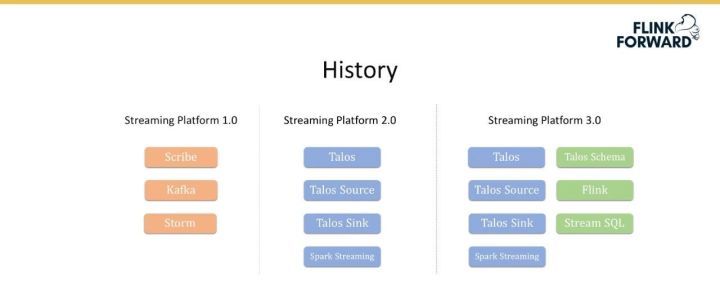
Streaming Platform 1.0:小米流式平臺的 1.0 版本構建于 2010 年,其最初使用的是 Scribe、Kafka 和 Storm,其中 Scribe 是一套解決數據收集和數據轉儲的服務。
Streaming Platform 2.0:由于 1.0 版本存在的種種問題,我們自研了小米自己的消息隊列 Talos,還包括 Talos Source、Talos Sink,并接入了 Spark Streaming。
Streaming Platform 3.0:該版本在上一個版本的基礎上增加了 Schema 的支持,還引入了 Flink 和 Stream SQL。
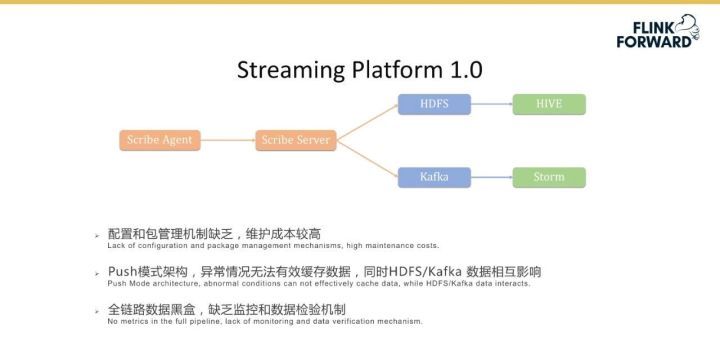
Streaming Platform 1.0 整體是一個級聯的服務,前面包括 Scribe Agent 和 Scribe Server 的多級級聯,主要用于收集數據,然后滿足離線計算和實時計算的場景。離線計算使用的是 HDFS 和 Hive,實時計算使用的是 Kafka 和 Storm。雖然這種離線加實時的方式可以基本滿足小米當時的業務需求,但也存在一系列的問題。
首先是 Scribe Agent 過多,而配置和包管理機制缺乏,導致維護成本非常高;
Scribe 采用的 Push 架構,異常情況下無法有效緩存數據,同時 HDFS / Kafka 數據相互影響;
最后數據鏈級聯比較長的時候,整個全鏈路數據黑盒,缺乏監控和數據檢驗機制。
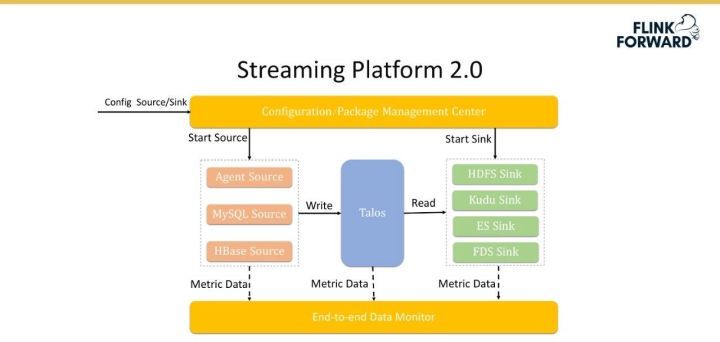
為了解決 Streaming Platform 1.0 的問題,小米推出了 Streaming Platform 2.0 版本。該版本引入了 Talos,將其作為數據緩存區來進行流式數據的存儲,左側是多種多樣的數據源,右側是多種多樣的 Sink,即將原本的級聯架構轉換成星型架構,優點是方便地擴展。
由于 Agent 自身數量及管理的流較多(具體數據均在萬級別),為此該版本實現了一套配置管理和包管理系統,可以支持 Agent 一次配置之后的自動更新和重啟等。
此外,小米還實現了去中心化的配置服務,配置文件設定好后可以自動地分發到分布式結點上去。
最后,該版本還實現了數據的端到端監控,通過埋點來監控數據在整個鏈路上的數據丟失情況和數據傳輸延遲情況等。
Streaming Platform 2.0 的優勢主要有:
引入了 Multi Source & Multi Sink,之前兩個系統之間導數據需要直接連接,現在的架構將系統集成復雜度由原來的 O(M*N) 降低為 O(M+N);
引入配置管理和包管理機制,徹底解決系統升級、修改和上線等一系列問題,降低運維的壓力;
引入端到端數據監控機制,實現全鏈路數據監控,量化全鏈路數據質量;
產品化解決方案,避免重復建設,解決業務運維問題。

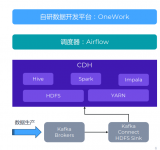
下圖詳細介紹一下 MySQL 同步的案例,場景是將 MySQL 的一個表通過上述的機制同步到消息隊列 Talos。具體流程是 Binlog 服務偽裝成 MySQL 的 Slave,向 MySQL 發送 Dump binlog 請求;MySQL 收到 Dump 請求后,開始推動 Binlog 給 Binlog 服務;Binlog 服務將 binlog 以嚴格有序的形式轉儲到 Talos。之后會接入 Spark Streaming 作業,對 binlog 進行解析,解析結果寫入到 Kudu 表中。目前平臺支持寫入到 Kudu 中的表的數量級超過 3000 個。
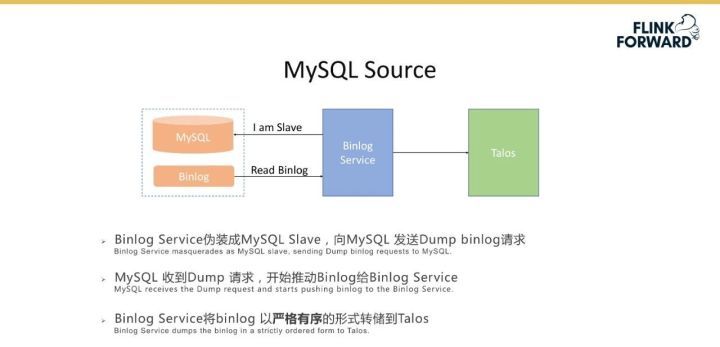
Agent Source 的功能模塊如下圖所示。其支持 RPC、Http 協議,并可以通過 File 來監聽本地文件,實現內存和文件雙緩存,保證數據的高可靠。平臺基于 RPC 協議實現了 Logger Appender 和 RPC 協議的 SDK;對于 Http 協議實現了 HttpClient;對于文件實現了 File Watcher 來對本地文件進行自動地發現和掃描,Offset Manager 自動記錄 offset;Agent 機制與 K8S 環境深度整合,可以很容易地和后端的流式計算等相結合。
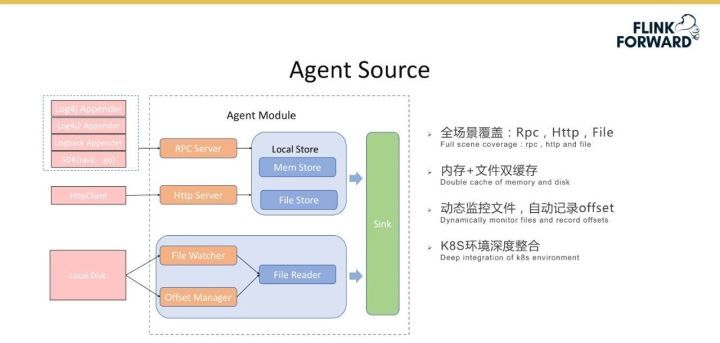
下圖是 Talos Sink 的邏輯流程圖,其基于 Spark Streaming 來實現一系列流程。最左側是一系列 Talos Topic 的 Partition 分片,基于每個 batch 抽象公共邏輯,如 startProcessBatch() 和 stopProcessBatch(),不同 Sink 只需要實現 Write 邏輯;不同的 Sink 獨立為不同的作業,避免相互影響;Sink 在 Spark Streaming 基礎上進行了優化,實現了根據 Topic 流量進行動態資源調度,保證系統延遲的前提下最大限度節省資源。
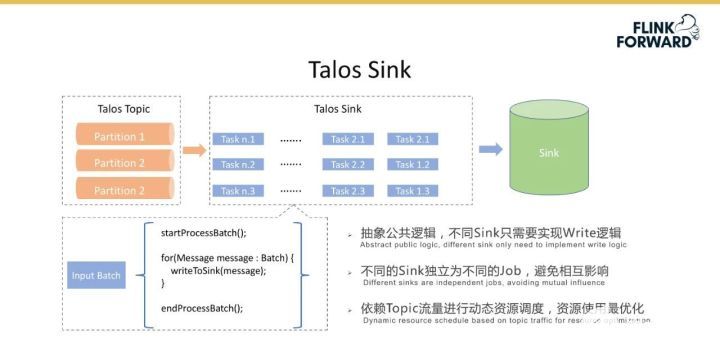
下圖是平臺實現的端到端數據監控機制。具體實現是為每個消息都有一個時間戳 EventTime,表示這個消息真正生成的時間,根據 EventTime 來劃分時間窗口,窗口大小為一分鐘,數據傳輸的每一跳統計當前時間窗口內接受到的消息數量,最后統計出消息的完整度。延遲是計算某一跳 ProcessTime 和 EventTime 之間的差值。
Streaming Platform 2.0 目前的問題主要有三點:
Talos 數據缺乏 Schema 管理,Talos 對于傳入的數據是不理解的,這種情況下無法使用 SQL 來消費 Talos 的數據;
Talos Sink 模塊不支持定制化需求,例如從 Talos 將數據傳輸到 Kudu 中,Talos 中有十個字段,但 Kudu 中只需要 5 個字段,該功能目前無法很好地支持;
Spark Streaming 自身問題,不支持 Event Time,端到端 Exactly Once 語義。

基于 Flink 的實時數倉
為了解決 Streaming Platform 2.0 的上述問題,小米進行了大量調研,也和阿里的實時計算團隊做了一系列溝通和交流,最終決定將使用 Flink 來改造平臺當前的流程,下面具體介紹小米流式計算平臺基于Flink的實踐。
使用 Flink 對平臺進行改造的設計理念如下:
全鏈路 Schema 支持,這里的全鏈路不僅包含 Talos 到 Flink 的階段,而是從最開始的數據收集階段一直到后端的計算處理。需要實現數據校驗機制,避免數據污染;字段變更和兼容性檢查機制,在大數據場景下,Schema 變更頻繁,兼容性檢查很有必要,借鑒 Kafka 的經驗,在 Schema 引入向前、向后或全兼容檢查機制。
借助 Flink 社區的力量全面推進 Flink 在小米的落地,一方面 Streaming 實時計算的作業逐漸從 Spark、Storm 遷移到 Flink,保證原本的延遲和資源節省,目前小米已經運行了超過 200 個 Flink 作業;另一方面期望用 Flink 改造 Sink 的流程,提升運行效率的同時,支持 ETL,在此基礎上大力推進 Streaming SQL;
實現 Streaming 產品化,引入 Streaming Job 和 Streaming SQL 的平臺化管理;
基于 Flink SQL 改造 Talos Sink,支持業務邏輯定制化

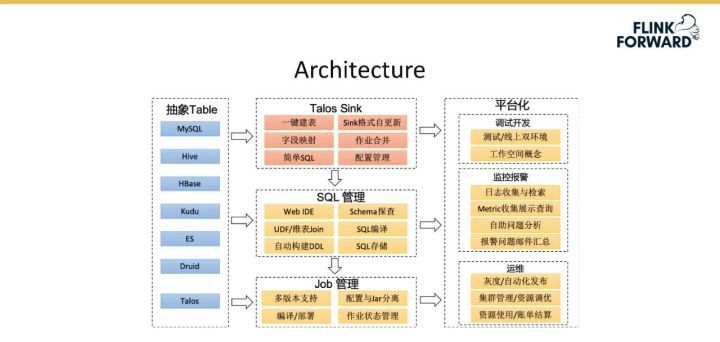
下圖是 Streaming Platform 3.0 版本的架構圖,與 2.0 版本的架構設計類似,只是表達的角度不同。具體包含以下幾個模塊:
抽象 Table:該版本中各種存儲系統如 MySQL 和 Hive 等都會抽象成 Table,為 SQL 化做準備。
Job 管理:提供 Streaming 作業的管理支持,包括多版本支持、配置與Jar分離、編譯部署和作業狀態管理等常見的功能。
SQL 管理:SQL 最終要轉換為一個 Data Stream 作業,該部分功能主要有 Web IDE 支持、Schema 探查、UDF/維表 Join、SQL 編譯、自動構建 DDL 和 SQL 存儲等。
Talos Sink:該模塊基于 SQL 管理對 2.0 版本的 Sink 重構,包含的功能主要有一鍵建表、Sink 格式自動更新、字段映射、作業合并、簡單 SQL 和配置管理等。前面提到的場景中,基于 Spark Streaming 將 Message 從 Talos 讀取出來,并原封不動地轉到 HDFS 中做離線數倉的分析,此時可以直接用 SQL 表達很方便地實現。未來希望實現該模塊與小米內部的其他系統如 ElasticSearch 和 Kudu 等進行深度整合,具體的場景是假設已有 Talos Schema,基于 Talos Topic Schema 自動幫助用戶創建 Kudu 表。
平臺化:為用戶提供一體化、平臺化的解決方案,包括調試開發、監控報警和運維等。
Job 管理
Job 管理提供 Job 全生命周期管理、Job 權限管理和 Job 標簽管理等功能;支持Job 運行歷史展示,方便用戶追溯;支持 Job 狀態與延遲監控,可以實現失敗作業自動拉起。

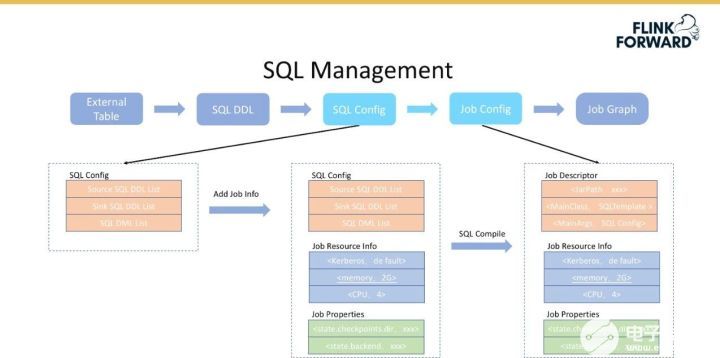
SQL 管理
主要包括以下四個環節:
將外部表轉換為 SQL DDL,對應 Flink 1.9 中標準的 DDL 語句,主要包含 Table Schema、Table Format 和 Connector Properities。
基于完整定義的外部 SQL 表,增加 SQL 語句,既可以得到完成的表達用戶的需求。即 SQL Config 表示完整的用戶預計表達,由 Source Table DDL、Sink Table DDL 和 SQL DML語句組成。
將 SQL Config 轉換成 Job Config,即轉換為 Stream Job 的表現形式。
將 Job Config 轉換為 JobGraph,用于提交 Flink Job。

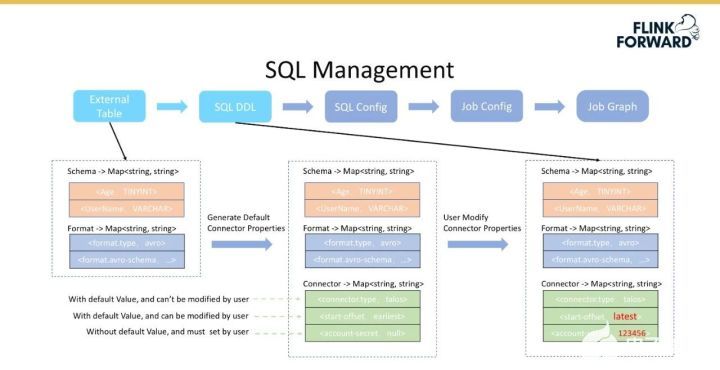
外部表轉換成 SQL DDL 的流程如下圖所示。
首先根據外部表獲取 Table Schema 和 Table Format 信息,后者用于反解數據,如對于 Hive 數據反序列化;
然后再后端生成默認的 Connector 配置,該配置主要分為三部分,即不可修改的、帶默認值的用戶可修改的、不帶默認值的用戶必須配置的。
不可修改的配置情況是假設消費的是 Talos 組件,那么 connector.type 一定是 talos,則該配置不需要改;而默認值是從 Topic 頭部開始消費,但用戶可以設置從尾部開始消費,這種情況屬于帶默認值但是用戶可修改的配置;而一些權限信息是用戶必須配置的。
之所以做三層配置管理,是為了盡可能減少用戶配置的復雜度。Table Schema、Table Format 和 Connector 1 其他配置信息,組成了SQL DDL。將 SQL Config 返回給用戶之后,對于可修改的需要用戶填寫,這樣便可以完成從外部表到 SQL DDL 的轉換,紅色字體表示的是用戶修改的信息。
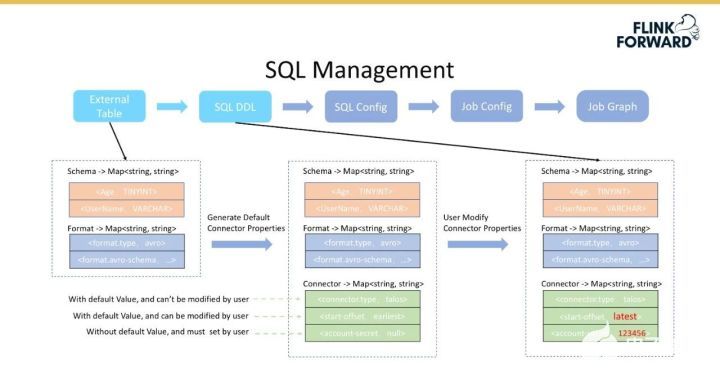
SQL 管理引入了一個 External Table 的特性。假設用戶在平臺上選擇消費某個 Topic 的時候,該特性會自動地獲取上面提到的 Table 的 Schema 和 Format 信息,并且顯示去掉了注冊 Flink Table 的邏輯;獲取 Schema 時,該特性會將外部表字段類型自動轉換為 Flink Table 字段類型,并自動注冊為 Flink Tab 了。同時將 Connector Properties 分成三類,參數帶默認值,只有必須項要求用戶填寫;所有參數均采用 Map 的形式表達,非常便于后續轉化為 Flink 內部的 TableDescriptor。
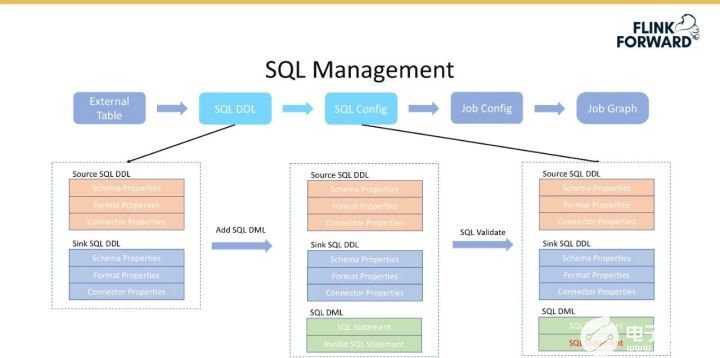
上面介紹了 SQL DDL 的創建過程,在已經創建的 SQL DDL 的基礎上,如 Source SQL DDL 和 Sink SQL DDL,要求用戶填寫 SQL query 并返回給后端,后端會對 SQL 進行驗證,然后會生成一個 SQL Config,即一個 SQL 語句的完整表達。
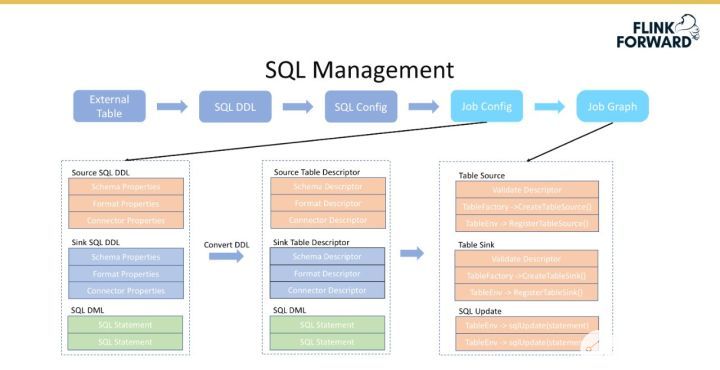
SQL Config 轉換為 Job Config 的流程如下圖所示。
首先在 SQL Config 的基礎上增加作業所需要的資源、Job 的相關配置(Flink 的 state 參數等);
然后將 SQLConfig 編譯成一個 Job Descriptor,即 Job Config 的描述,如 Job 的 Jar 包地址、MainClass 和 MainArgs 等。

下圖展示了 Job Config 轉換為 Job Graph 的過程。對于 DDL 中的 Schema、Format 和 Property 是和 Flink 中的 Table Descriptor 是一一對應的,這種情況下只需要調用 Flink 的相關內置接口就可以很方便地將信息轉換為 Table Descriptor,如 CreateTableSource()、RegistorTableSource() 等。通過上述過程,DDL 便可以注冊到 Flink 系統中直接使用。對于 SQL 語句,可以直接使用 TableEnv 的 sqlUpdate() 可以完成轉換。
SQL Config 轉換為一個 Template Job 的流程如下所示。前面填寫的 Jar 包地址即該 Template 的 Jar 地址,MainClass 是該 Template Job。假設已經有了 SQL DDL,可以直接轉換成 Table Descriptor,然后通過 TableFactorUtil 的 findAndCreateTableSource() 方法得到一個 Table Source,Table Sink 的轉換過程類似。完成前兩步操作后,最后進行 sqlUpdate() 操作。這樣便可以將一個 SQL Job 轉換為最后可執行的 Job Graph 提交到集群上運行。
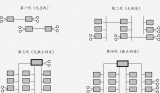
Talos Sink 采用了下圖所示的三種模式:
Row:Talos 的數據原封不動地灌到目標系統中,這種模式的好處是數據讀取和寫入的時候無需進行序列化和反序列化,效率較高;
ID mapping:即左右兩邊字段進行 mapping,name 對應 field_name,timestamp 對應 timestamp,其中 Region 的字段丟掉;
SQL:通過 SQL 表達來表示邏輯上的處理。
未來規劃
小米流式平臺未來的計劃主要有以下幾點:
在 Flink 落地的時候持續推進 Streaming Job 和平臺化建設;
使用 Flink SQL 統一離線數倉和實時數倉;






























 工商網監
工商網監
評論