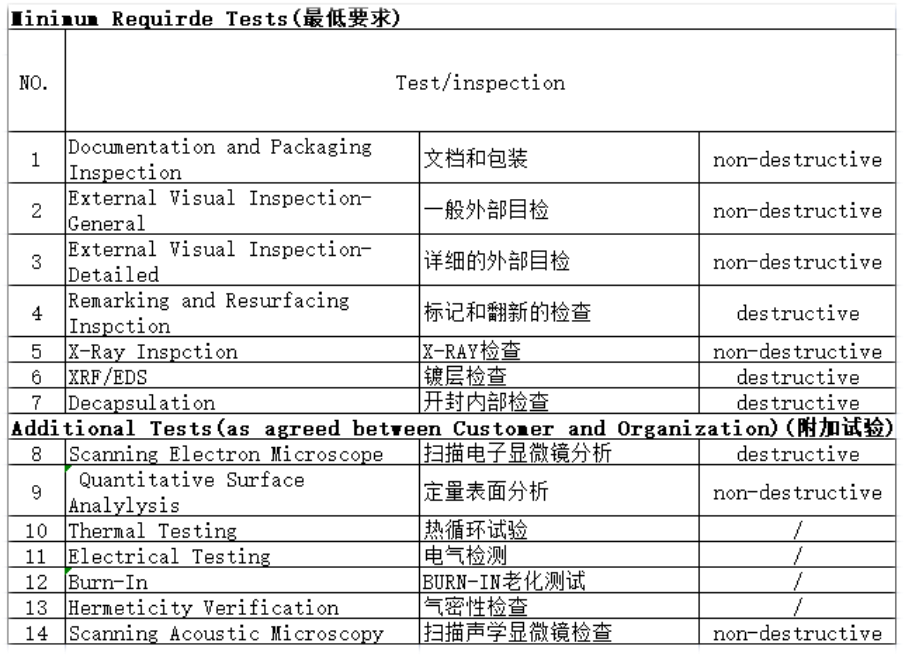
 電子發燒友App
電子發燒友App


引 言
近年來國內大米市場混亂,各種低檔、劣質稻米冒充品牌稻米銷售,嚴重侵犯了消費者的利益,甚至危及生命安全。而目前,稻米品質與品種的鑒別方法主要為感覺法與化學分析法。感覺法通過形狀、色澤以及氣味對大米品質進行鑒定,主要依賴鑒別者的經驗,缺乏嚴格的科學依據;常規化學分析法則存在耗時長、耗資大以及操作復雜等缺點而難以滿足市場經營中快速鑒別的需要.而可見/近紅外反射光譜技術因其快速、高效以及無損的特點,已被廣泛地應用于石油化工、探礦、制藥以及紡織等領域。近年來,可見/近紅外光譜結合模式識別技術,進一步在楊梅、燕麥等農產品的分類中獲得了成功的應用,對丹參、白術、蛇床子等中藥材產地與真偽鑒別也取得了滿意的結果。在稻谷的相關研究中,可見/近紅外光譜技術也已用于其直鏈淀粉、蛋白質、脂肪以及氨基酸含量與稻谷儲存年份的分析。本文將采用可見/近紅外反射光譜技術對稻米的品種與真偽進行鑒別,為稻米品種的快速無損鑒別提供新的方法。
1 材料與方法
1.1樣本來源與數據采集
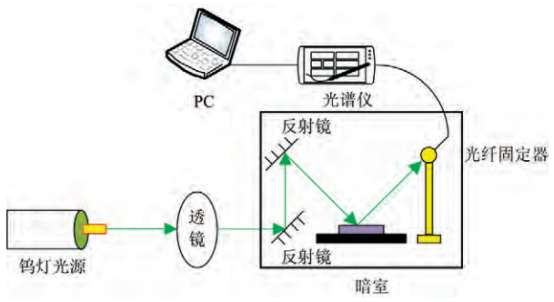
于超市購買了泰國香米、夜郎貢米、珍珠米、泰國糯米四種稻米樣本;于湘西質量技術監督局獲得劣質米(珍珠米偽品)樣本。每種稻米采集樣本35份,合計175份。隨機抽取150份(每種30份)作為訓練集,其余25份(每種5份)作為預測集。樣本于45℃下恒溫烘干24h后,于玻璃皿中進行光譜掃描,米樣上表面均與玻璃皿上端保持平齊。測樣于暗室中進行,以鹵素燈為唯一光源.光纖探測器頭部與樣本之間保持垂直,下部距離樣本0.5cm,每一樣本重復測量30次取其均值。
1.2 光譜預處理
由于光譜在小于400nm與大于2300nm的波段噪聲較大,因此本研究選用400~ 2300nm波段作為有效光譜數據進行分析。將有效光譜經S.Golay平滑后,采用標準歸一化(SNV)方法進行除噪。
1.3 數據降維與波段選擇
如果將光譜數據直接作為變量輸入進行建模,不但會因變量太多而增加建模難度,而且會引入噪聲而降低模型的預測精度。為了避免這一問題,本研究采用主成分分析(PCA)以實現光譜數據的降維。同時,如能選用特征波段進行建模,將信噪比低的波段刪除,可能會獲得比全波段建模更好的結果。因此,本研究將對全波段與特征波段兩種建模方法進行比較分析以獲得較優模型。
1.4 人工神經網絡模型
在光譜分析中,人工神經網絡是一種重要的模式識別方法,其中多層誤差反向傳播神經網絡方法(back-propagation,BP)應用尤廣,具有強大的非線性建模能力,特別適合解決復雜的映射問題。而作為一種有機物,稻米內部的理化性質與其可見/近紅外反射光譜之間正是一種復雜的映射關系,因此,本研究將全波段與特征波段降維后的數據分別導入DPS中,采用BP算法建立不同稻米的鑒別模型。
2 結果與討論
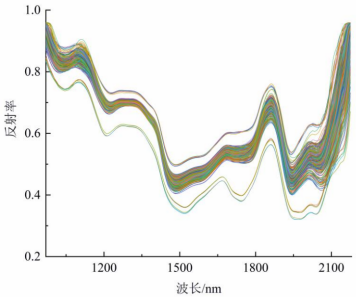
2.1 稻米樣本的可見/近紅外漫反射光譜
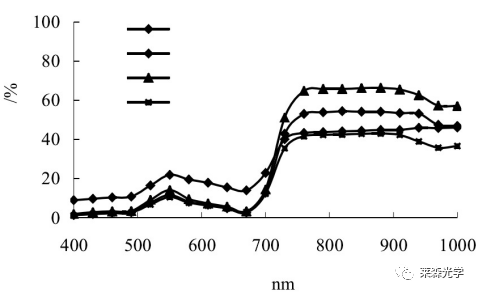
圖1為5種稻米部分可見/近紅外漫反射光譜曲線。從圖中可看出,不同品種稻米的反射光譜的波形有稍許差異,而同種稻米樣本的光譜則有一定的聚集趨勢,但憑肉眼難以準確區分。分析時,先將光譜數據轉化為ASCII碼,在Unscramble 9.7中完成預處理后進行PCA分析。
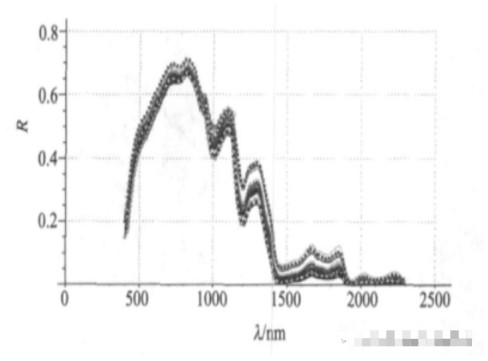
圖1 5種稻米樣本的可見/近紅外反射光譜
2.2 PCA分析與特征波段提取
訓練集樣本經PCA降維分析后,分別以前3個主成分PC 1、PC 2、PC 3作為x、y、z坐標,建立各樣本的三維得分圖(圖2),以表征樣本在該三維空間中的分布。由于前3個主成分對光譜矩陣的累積方差貢獻達91.82%,因此,樣本在三維空間的分布可大體反映其在超維空間的分布特征,表征出不同稻米的聚類結果。從圖2中可看出,各種稻米有良好的聚類趨勢,可進行定性分析,但要取得精確的定量分析結果,還需要建立鑒別能力更強的模型。
由于PCA分析的前3個主成分已包含了絕大部分的分類信息,因此,可根據不同波段的光譜對前3個主成分的貢獻值分析出稻米分類的特征波段。在Unscramble 9.7中,得出前3個主成分的X-加載圖,以表征各波段對模型前3個主成分的貢獻大小(圖3).以波譜區域對PC 1的貢獻值為主要參考指標,并綜合考慮對PC 2與PC 3的貢獻值,得出400~500nm、910~1300nm與1940~2300nm三個波段為稻米鑒別的特征波段。根據水、淀粉、蛋白質的吸收特征,可分析出910~1400nm、1940~2300nm兩段特征波段主要反映了不同稻米營養成分的差異,而400~500nm這一位于可見光部分的特征波段則主要反映了形狀與顏色的差異。
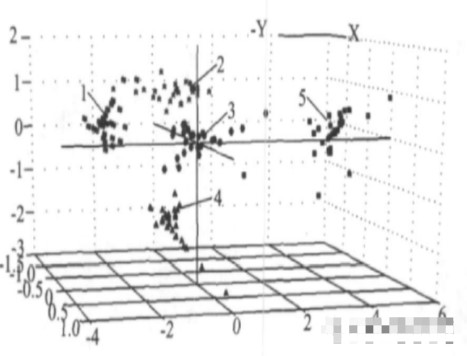
圖2 5種稻米前3個主成分的得分聚類
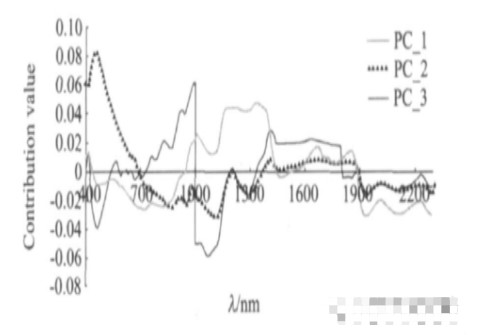
圖3 不同譜區對PCA分析前3個主成分的貢獻值
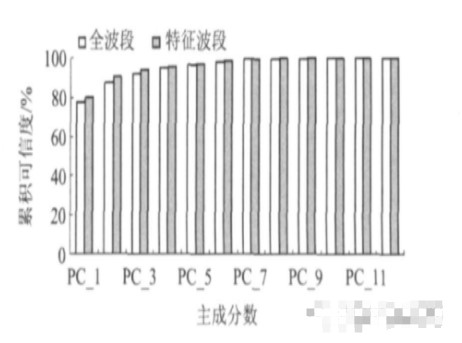
圖4 兩種模型訓練集前12個主成分的累積可信度
在建立模型過程中,如果所選取的主成分過少,將會因不充分擬合而導致模型預測準確度降低;而若選用的主成分過多,則會產生過擬合現象而導致模型預測的準確率下降。因此,本研究通過交互驗證確定最佳主成分數,即在累積可信度(累積方差貢獻)變化不大的情況下選取較少的主成分數.將全光譜與特征光譜分別進行PCA分析后,所得前12個主成分的累積可信度如圖4所示。由圖可知,兩種方法前9個主成分的累積可信度在99.5%以上,包含了光譜數據絕大部分的特征信息。
2.3 BP神經網絡模型預測結果與比較分析
表1 兩種模型對25個未知樣本的預測結果
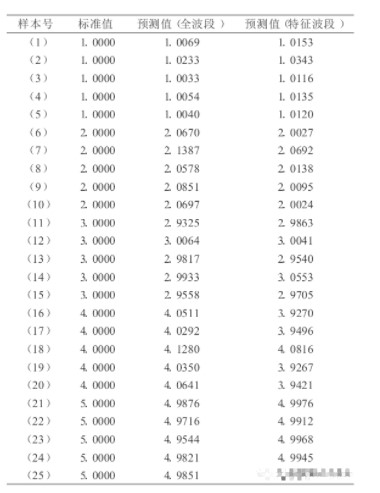
注:(1)~(5),泰國香米;(6)~(10),夜郎貢米;(11)~(15),珍珠米;(16)~(20),泰國糯米;(21)~(25),珍珠米偽品
利用訓練集中的150個樣本,以PCA降維得到的前9個主成分作為BP神經網絡的輸入變量,在DPS中建立PCA-BP神經網絡預測模型。建模分析時,泰國香米、夜郎貢米、珍珠米、泰國糯米、劣質米分別賦值為1.0000、2.0000、3.0000、4.0000、5.0000;BP網絡各層間采用Sigmoid激勵函數,其中Sigmoid參數取0.9,動態參數取0.6,最小訓練速度設為0.1,允許誤差設為0.0001,最大迭代次數設為3000次.通過調節隱含層的節點數反復地驗證以優化網絡結構,得到最佳的BP網絡結構為9-6-5三層BP神經網絡模型。用模型對預測集的25個未知樣進行預測,結果表明兩類模型對所有樣本預測的正確率均達100%(表1)。為獲得最佳建模方法,分析了兩種方法對25個未知樣的預測結果。兩類模型對預測集的擬合結果與標準值之間的回歸關系見圖5。由圖可知,兩回歸方程的斜率都接近于1,但特征波段模型預測集決定系數(R 2= 0.9994)比全波段模型(R 2= 0.9988)稍高,而預測標準誤差(SEP= 0.0390)與預測誤差均方根(RMSEP= 0.0383)則比全波段模型(SEP=0.0519;RMSEP= 0.0550)稍低,說明特征波段模型具有更好的預測效果,是一種優選方法。
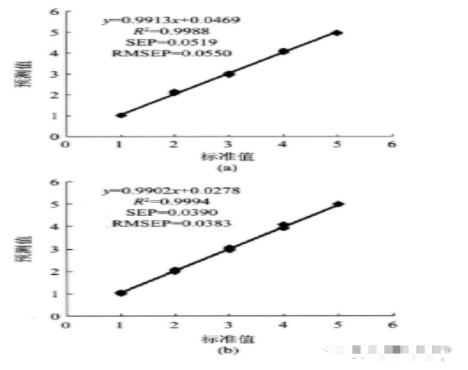
圖5 全波段模型(a)與特征波段模型(b)對未知樣本預測值與標準值之間的關系
3 結 論
對5種稻米的分析結果表明,采用可見/近紅外光譜技術進行稻米品種與真偽的鑒別是可行的,從而為稻米品種與真偽的快速、無損鑒別提供了一種新方法。比較分析結果表明,利用特征波段所建立的模型比全波段模型具有更高的預測精度,說明特征波段提取是進行模型優化的有效手段。
審核編輯:湯梓紅












































 工商網監
工商網監
評論