 電子發燒友App
電子發燒友App


摘要:
摘要: 在工業系統中普遍存在樣本數據不平衡現象,正常樣本數量遠遠大于異常樣本數量。而傳統的機器學習算法和深度學習方法,例如樸素貝葉斯和支持向量機,在處理類不平衡問題時,很難獲得較高的識別分類準確率,因為它們往往會偏向保證多數類的準確率。為此,本文提出了一種基于生成對抗網絡(GAN)的異常檢測方法。這個方法中的生成器結構是“編碼器–解碼器–編碼器”的三子網,并且訓練該生成器只需要從正常樣本中提取特征,所以訓練數據集中就不需要異常樣本。此系統的異常檢測結果由樣本的最終得分來判別,其中異常分數由表觀損失和潛在損失組成。本文方法的亮點在于可以實現在無異常樣本訓練的情況下對異常數據樣本做檢測,通過系統生成更高的異常分數來診斷故障。本項目在凱斯西儲大學(CWRU)獲得的基準滾動軸承數據集上驗證了該方法的可行性和有效性。本文提出的方法在數據集中區分異常樣本與正常樣本的準確率達到了100%。
1. 項目介紹
異常檢測對于現代工業系統的可靠性和安全性至關重要。及時準確的異常檢測有助于預防重大事故的發生,提高生產效率。然而,工業生產中數據類不平衡的情況比較嚴重,在正常條件下的樣本比在異常條件下的樣本普遍得多,為準確診斷工業設備故障造成了巨大的障礙。此外,工業系統總是具有非線性和不確定性,這對模型訓練提出了很大的挑戰 [1]。
工業異常檢測的數據一般是不同傳感器在一定時間內記錄的電流、溫度等物理信號,也稱為時間序列。對于工業異常檢測領域,時間序列通常作為訓練模型的輸入數據 [2]。一般以時間序列為輸入,異常檢測框架通常分為特征提取和故障識別兩個階段。通過特征提取算法,將時間序列預處理為低維特征向量,送入故障檢測器進行故障檢測 [3]。機器學習算法作為一種強大的異常檢測模式識別工具,已經成為關注的焦點,包括貝葉斯分類器、支持向量機方法等 [4]。上述方法都是假設基于類平衡的情況,然而當數據分類不平衡時這些方法難以獲得較高的精度 [5]。除了數據集的類均衡假設外,標記數據也是訓練階段機器學習算法的關鍵。然而,在許多實際的工業系統中,來自異常情況下的樣本數量往往很少。另外,當系統在正常狀態下運行了很長一段時間后,突然出現異常,要準確定位異常的發生時間是極其困難的 [6]。因此,不準確的異常標簽也會對異常檢測的準確性產生不利的影響。
當正常和異常的標簽不平衡時,機器學習方法的分類器會犧牲少數類來保證多數類的準確性,這意味著分類結果會偏向于測試樣本整體的正態性 [5]。但是,對于工業系統中的異常檢測,我們應該特別關注那些處于少數情況的類,如何能夠準確捕捉和判別異常數據是當前工業系統中異常檢測的重點。在2014年,由Goodfellow等人提出的生成對抗網絡(GAN)為解決工業中類不平衡問題提供了一個新的思路。這個網絡模型最先出現在“Generative Adversarial Networks”一文中,起初它被用于圖像識別領域,并取得了卓越的成績 [7]。GAN的基本思想是通過一個具有隨機數據點的生成器生成原型樣本,這些隨機數據點滿足一定的分布(如高斯分布)。在圖像的異常診斷領域,已經有一些基于GAN的具有競爭力的網絡架構被提出,如AnoGAN [8] 、BiGAN [9] 和GANomaly [10]。這些基于GAN的方法只訓練正常圖像的模型,根據正常圖像和異常圖像的特征分布差異來區分異常圖像。從這一點出發,基于GAN的模型對于學習和識別不平衡數據集是有效的,可以防止診斷結果偏向于多數類。然而,在工業應用中,基于GAN的異常檢測方法非常少見。經過類似項目的調查研究,發現依次有基于GAN網絡的機械故障檢測方法 [11] 和基于GAN的不平衡數據故障診斷方法 [12] 被提出。這些研究啟發可以進一步研究GAN在工業故障檢測方面的有效性,特別是在沒有異常數據的情況下。因此針對工業時間序列的特性,本文基于GANomaly,改善了生成器整體的損失函數,以實現類不平衡場景的檢測高精度。
在這項工作中,針對工業系統中異常數據的匱乏,本文提出了一種基于GAN的方法來解決智能異常檢測問題。這個方法的系統由一個生成器和一個判別器組成,將生成器和判別器進行對抗訓練得到訓練后的模型來用于診斷。該系統的生成器基于卷積生成對抗網絡,采用“Encoder-Decoder-Encoder”為結構的三子網絡。為了提高診斷性能,在原始數據和GAN之間插入數據轉換器對原始數據集進行預處理。通過在CWRU滾動軸承數據集的實驗,驗證了該方法的可行性和有效性。
本文的主要貢獻如下:
a) 針對工業領域的不平衡時間序列問題,提出了一種新的基于GAN的異常檢測方法。
b) 所提出的網絡訓練中只需要正常樣本。這是一個比其他現有算法網絡更貼合現實場景的網絡。因為在真實的工業場景中,異常樣本的數量往往非常少。實驗基于CWRU的滾動軸承基準數據集進行了訓練和調整,通過測試確保了該系統模型具有良好的診斷性能,并進一步驗證了本文方法的有效性,使其可以作為解決工業數據類不平衡問題的新思路。
2. 項目背景
關注微信公眾號:人工智能技術與咨詢。了解更多咨詢!
2.1. 深度學習用于智能故障診斷
隨著各種工業系統中產生的時間序列數據流越來越動態、復雜和龐大,許多用于深度學習的異常檢測技術得到了很好的發展。在調用這些深度學習模型的過程中,它們被賦予學習目的,但這并不意味它們清楚最終的輸出特性是什么。這些黑箱旨在為特定的數據集提取特定的模式,如長短時記憶網絡(LSTM),遞歸神經網絡(RNN),卷積神經網絡(CNN)。雖然上述的這些深度學習模型在異常檢測方面顯現出了許多卓越的性能,但在面對不平衡的數據集時,其準確率仍然不能令人滿意 [13]。此外,由于數據表示的差異(如圖像和時間序列),許多深度學習模型適用于圖像領域,但在工業領域往往難以實施和應用。
2.2. 類不平衡問題
在基于不平衡時間序列的異常檢測中,通常會考慮兩種主要方法:數據級方法和算法級方法 [14]。數據級方法通常利用采樣策略改變不平衡的數據分布,其中廣泛使用過采樣和欠采樣兩種策略 [15]。算法級的方法一般采用調整分類器以適應不平衡的數據,其中通常使用bagging和boost ensemble-based方法 [16]。具體的有Easy Ensemble [17] 和Balance Cascade [18] 算法被提出用于處理類不平衡問題。Easy Ensemble [17] 是通過多次從多數類樣本有放回的隨機抽取一部分樣本生成多個子數據集,將每個子集與少數類數據聯合起來進行訓練生成多個模型,然后集合多個模型的結果進行判斷。這種方法看起來和隨機森林的原理很相似 [14]。Balance Cascade [17] 是通過一次隨機欠采樣產生訓練集,訓練一個分類器,對于那些分類正確的多數類樣本不放回,然后對這個剩下的多數類樣本再次進行欠采樣產生第二個訓練集,訓練第二個分類器,同樣把分類正確的樣本不放回,以此類推,直到滿足某個停止條件,最終的模型也是多個分類器的組合 [17]。
2.3. GAN和GANOMALY
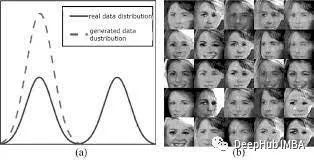
近年來,在類不平衡圖像的異常檢測中,對抗訓練尤其是GAN占據了越來越重要的地位。GAN最早由Goodfellow等人提出,被認為是一種無監督機器學習算法,在圖像識別領域取得了突出的應用效果。GAN的網絡結構如圖1,使用原始數據對生成器進行訓練,生成器(Generator)產生新的樣本。生成器數據和真實訓練數據輸入到判別器(Discriminator)中,訓練得到能正確區分數據類型的判別器。判別器和生成器相互對抗,生成器通過學習來產生更逼近真實數據的新樣本,用于欺騙判別器,反之判別器也需要更好地區分生成數據與真實數據。自2014年以來,基于GAN的對抗性算法層出不窮,很多新的方法和框架被提出并取得了優秀的表現。
Figure 1. Structure of generate adversarial network
圖1. 生成對抗網絡結構
在圖像分類領域中,Akcay等人提出了一種通用的異常檢測體系結構GANomaly。與以往的先進方法相比,該結構在多個基準圖像數據集上具有顯著的優越性和有效性 [10],給予我們在工業領域的異常檢測一些啟發。下面是對GANomaly的簡要介紹。該模型中,其生成器由“編碼器–解碼器–編碼器”三子網構成訓練半監督網絡,該結構使用深度卷積生成對抗網絡(DCGAN) [18],并在生成器中使用三個損失函數來捕獲輸入圖像和潛在空間中的特征。該算法的特點之一是不考慮異常樣本,并在圖像數據集中實現了優異的異常檢測性能。
論文的其余結構如下。第三部分提出了基于GAN的異常檢測框架。第四節和第五節分別介紹了實驗裝置和實驗結果。第六部分為結論和未來工作。
3. 項目方法
圖2是本文提出的方法概述。圖中可以看出在訓練階段,這個系統模型只考慮正常樣本。本文使用數據轉換器來對樣本進行處理并提取有用的特征,這些特征經過轉換可以更好的被模型學習。系統中生成器采用編碼器–解碼器–編碼器三子網,判別器則是基于DCGAN網絡結構。在檢測階段,異常樣本可以通過比正常樣本更高的異常分數來識別。
3.1. 方法介紹
Figure 2. The proposed method framework
圖2. 本文方法框架
在訓練的步驟中,用 DtrainDtrain 訓練一個GAN-Based模型M。訓練過程的目標是最小化 DtrainDtrain 中每個子數據集的輸出。在訓練過后,用于測試的數據集 DtestDtest 將會放入模型M。訓練后的生成器將對故障樣本和正常樣本進行相應的編碼和解碼。由于訓練后的網絡只學習了正常數據的可能表示模式,如果用異常數據樣本 DutestDtestu 作為輸入,那么模型M的輸出與正常輸入 DvtestDtestv 的輸出相比,會有很大的偏差。這個偏差值最終幫助確定異常樣本的存在。
3.2. 訓練的過程
本文提出的方法中其訓練階段的主要目的是正常條件下生成盡可能小的樣本分數的模型。本文方法的網絡結構由數據轉換器、生成器和判別器三部分組成。基本網絡架構用DCGAN表示。在生成器的設計中,開發了一種由“Encoder-Decoder-Encoder”組成的三子網。在將數據輸入生成器之前,需要設計一個數據轉換器將一維的時間序列數據轉為二維的圖像數據,可以幫助DCGAN更好的提取和學習樣本特征。基于普適性原則,不對原始數據進行其他處理,因此任何時間序列都可以封裝到這些特征中。在訓練過程中,首先在正常條件下提取時間序列的特征,然后利用本文設計的異常檢測器獲得這些特征的數據分布和可能的代表模式。在測試階段,將異常樣本輸入訓練好的異常檢測器,異常數據的特征分布會得到比正常樣本更高的分數,以此為差異來識別和診斷。
3.2.1. 生成器和判別器
在生成器中,第一個編碼器用于學習樣本原始特征F的表征,第二個編碼器用于生成再生特征F^。同時,解碼器 GdGd 用于試圖重建F^。整個過程如下:
該生成器保證了原始特征集F的特征不變的同時可以得到潛在向量Z的模式。判別器(Discriminator)采用DCGAN中引入的標準判別器網絡,用于判斷輸入數據是真實的還是生成的。根據判別器的反饋再對生成器進行調整和訓練。在定義了整個網絡架構之后,本文將稱述如何定義訓練的損失函數。
3.2.2. 目標函數
在訓練階段,因為只訓練正常數據集 DtrainDtrain,所以模型M只會獲得正常數據集下的模式。但是在測試階段,M需要通過輸出更高的異常分數來確定異常樣本。那就意味著 GdGd 和 GeGe 將會解碼潛在表示Z和重新編碼F^,這與在訓練階段獲得的模式類似。之后F^和Z^將不可避免地與原來的F和Z產生差異,這樣有助于我們識別異常故障。
由于生成器的結構是采用“Encoder-Decoder-Encoder”組成的三個子網絡,因此生成器的最終損失函數將由欺騙損失(Fraud Loss)、表面損失(Apparent Loss)和潛在損失(Latent Loss)三部分組成,接下來將會分別對三個損失函數進行說明。
欺騙損失:在這里引入fraud loss的目的是為了誘導判別器將生成器生成的樣本誤判為真實的工業樣本。將生成的樣本輸入判別器,通過判別器輸出計算的fraud loss,公式如下:
3.3. 測試步驟
在測試階段,我們的模型使用潛在損失和表面損失對檢測到的測試數據樣本進行評分。判定樣本分數的公式可以定義為:
在這一部分中,我們使用 ωaωa, ωlωl 的比率作為合適的加權值超參數 λλ,意思是此處使用最好的訓練結果,即最小的生成器損失和判別器損失。因為本文提出的方法只在正常數據樣本上訓練異常檢測器,所以實驗中的異常檢測器將只學習和識別正常樣本的潛在模式和數據分布。在這個判定公式中,正常樣本得到的T(F)將接近于0,而對于異常樣本,公式得到的值將相對大很多。在測試中,通過公式T(F)的值的波動可以很容易地找到異常。
4. 實驗設置
為了評估本文方法的可行性和有效性,實驗和測試將在凱斯西儲大學(CWRU)獲得的滾動軸承數據上進行,實驗臺如圖3所示。
Figure 3. Testing bed in CWRU
圖3. CWRU實驗臺
4.1. 數據集描述
這是一個基準軸承異常檢測數據集,通過在電機上使用加速度計測量軸承的振動信號得到。采用電火花加工方法對電機軸承進行了故障樣本創建。分別在內滾道(IR),滾動部件(i.e. Ball)和外滾道(OR)創建了直徑范圍在0.007英寸到0.028英寸的故障點。故障軸承被重新安裝到測試電機中,并記錄電機負載從0到3馬力(電機速度從1720到1797 rpm)。數據集的采樣頻率為48 kHz,每個數據集文件由三種類型的信號組成,即驅動端加速度計信號、風扇端加速度計信號和基礎加速度計信號。表1總結了實驗中數據集的詳細信息。
| ? | CWRU數據 |
| 信號類型 | 振動信號 |
| 信噪比 | 高 |
| 采樣頻率(kHz) | 48 |
| 運轉速度(rmp) | 1730,1750,1772,1797 |
| 故障直徑 | 0.007,0.014,0.021,0.028 |
| 故障類型 | IR,OR,B |
Table 1. Data parameters collected by CWRU
表1. CWRU數據集的參數
4.1. 數據集處理
我們將正常數據樣本分為訓練集和測試集兩個部分。對于來源于CWRU的滾動軸承數據集,得到的初始訓練數據集 DtrainDtrain 都是傳感器在一段時間t內記錄的樣本。這些數據可以寫成矩陣型式,
在項目的實際訓練中發現樣本的數量以及樣本的多樣性需要得到進一步擴充,因此采用了對初始數據進行分割的方法來處理數據集。將時間t內記錄的樣本進行分割,依次取連續不間斷的3136個數據點作為新樣本。這個新數據樣本是一個1 × 3136的矩陣 Dti=[Xi1,Xi2,Xi3,?,Xi3136]Dti=[Xi1,Xi2,Xi3,?,Xi3136]。然后將數據轉換成4 × 28 × 28的矩陣,此處可以理解為將一維的原始數據轉變成了4張尺寸為1 × 28 × 28的圖像數據作為輸入模型的訓練數據,經過處理得到訓練集 Dtrain∈Rt×bDtrain∈Rt×b (b是訓練樣本的數量)。眾所周知GAN這一網絡模型最初就是在圖像識別領域展現了優異的性能,因此對數據進行該項處理可以優化模型對樣本特征的學習和提取。
對應的測試樣本是 Dtest=[Dvtest,Dutest]∈Rt×(v+u)Dtest=[Dtestv,Dtestu]∈Rt×(v+u),v和u分別是正常樣本和異常樣本的數量。所以這個項目的樣本總數n可以表示為 n=b+v+un=b+v+u。在CWRU的數據集中,實驗使用正常狀態條件下b = 400的樣本來訓練異常檢測器,同時設置了v = 541和u = 383的沒有標簽的樣本用于測試集。
4.3. 實施細節
實驗的具體實施放在PyTorch中,并使用了Adam優化網絡來實現本文提出的方法。首先設定訓練模型的參數,初始化學習率設為 lr=0.0001lr=0.0001,動量 β1,β2β1,β2 的值分別設為0.5和0.999。對于兩個數據集,每個模型在訓練時epochs都設為50,batch-size即一次訓練樣本的數量設為32。本文提出的方法的具體網絡結構在表2中進行了詳細的說明。
Table 2. Model network structure
表2. 模型網絡結構
Ks/S?1 = Kernel Size/Stride.
5. 實驗結果
在實驗時,將凱斯西儲大學(CWRU)收集的滾動軸承數據輸入本文方法構建的系統中,生成器經過訓練集數據的訓練生成初始的網絡模型,接著將生成器生成的樣本輸入判別器,根據判別器反饋的結果,對生成器進行新的訓練,直到判別器能成功被生成器生成的樣本所欺騙,此時生成器的訓練收斂。接著調用生成器訓練后的網絡模型對測試樣本進行測試,得到并輸出該樣本數據的得分情況。所提出方法的CWRU數據集得分如圖4所示。
Figure 4. CWRU data experimental results
圖4. CWRU數據實驗結果
從這張輸出結果圖中可以看出因為滾動軸承的故障情況不同,所以每種情況所得分值也明顯不同。同時表示閾值的藍色虛線清晰的分隔了正常和異常樣本。紅色的數值點是正常樣本在生成器中的得分情況,可以清楚的看出正常樣本的Scores值區間小于0.02并總體呈均勻分布,此處可以進一步驗證該生成器的訓練收斂了。圖中紫色的點代表內滾道故障樣本的得分情況,該類型樣本的整體分布較為混亂,得分區間在[0.04, 0.06]之間。圖中黃色的點代表外滾道故障樣本的得分情況,該類型的整體得分情況最為分散。此外圖中綠色的點代表滾動部件故障樣本的得分情況,此故障的得分情況相較其余兩種較為穩定,得分區間在[0.08, 0.10]之間。該得分結果還表明,滾動故障(圖中的Ball fault)數據的模式與正常樣本數據的模式最接近,而外滾道故障(圖中的OR fault)與正常數據模式的差異最大。
6. 項目結論
本文提出了一種基于生成對抗網絡(GAN)的針對工業時間序列不平衡的異常檢測體系結構。與當前大多數的深度學習方法相比,這種體系結構的特點是只需要使用正常的數據樣本進行訓練,不用考慮工業系統中樣本分類不均衡的問題。在異常檢測之前,我們根據本項目工業數據的特征和網絡模型的特點設計了一個數據轉換器。然后利用“Encoder-Decoder-Encoder”構建的生成器輸出較大的異常分數來檢測異常樣本的存在。該網絡結構在CWRU滾動軸承數據集上實現了100%的測試精度。
隨著工業領域技術的進步,以及設備的計算能力和存儲能力的提高,工業中的傳感器現在可以收集比以往更多更復雜的多元時間序列數據。在未來的工作中,針對多元的時間序列數據,如何將不同維度的信息進行融合或者如何對這些工業數據進行多進程的學習和識別,會有更多的想法和嘗試。
審核編輯:湯梓紅


































 工商網監
工商網監
評論