 電子發燒友App
電子發燒友App


混合學習
這種學習范式試圖去跨越監督學習與無監督學習邊界。由于標簽數據的匱乏和收集有標注數據集的高昂成本,它經常被用于商業環境中。從本質上講,混合學習是這個問題的答案。
我們如何才能使用監督學習方法來解決或者鏈接無監督學習問題?
例如這樣一個例子,半監督學習在機器學習領域正日益流行,因為它能夠在很少標注數據的情況下對有監督的問題表現得異常出色。例如,一個設計良好的半監督生成對抗網絡(Generative antimarial Network)在MNIST數據集上僅使用25個訓練樣本,就達到了90%以上的準確率。
半監督學習學習專門為了那些有打大量無標注樣本和少量有標注樣本的數據集。傳統來說, 監督學習是使用有標注的那一部分數據集,而無監督學習則采用另外無標注的一部分數據集, 半監督學習模型可以將有標注數據和從無標注數據集中提取的信息結合起來。
半監督生成對抗網絡(簡稱SGAN), 是標準的生成對抗網絡的一種改進。判別器不僅輸出0和1去判別是否為生成的圖像,而且輸出樣本的類別(多輸出學習)。
這是基于這樣的一個想法,通過判別器學習區分真實和生成的圖像, 能夠在沒有標簽的情況下學得具體的結構。通過從少量的標記數據中進行額外的增強,半監督模型可以在最少的監督數據量下獲得最佳性能。
你可以在這兒閱讀更多關于SGAN和半監督學習的信息。
GAN也涉及了其他的混合學習的領域——自監督學習, 在自監督學習中無監督問題被明確地定義為有監督的問題。GANs通過引入生成器來人工創建監督數據;創建的標簽被用來來識別真實/生成的圖像。在無監督的前提下,創建了一個有監督的任務。
另外,考慮使用進行壓縮的編碼器-解碼器模型。在它們最簡單的形式中,它們是中間有少量節點的神經網絡,用來表示某種bottleneck與壓縮形式,兩邊的兩個部分是編碼器和解碼器。
訓練這個網絡生成與輸入向量相同的輸入(一個無監督數據手工設計的有監督任務)。由于中間有一個故意設計的bottleneck,因此網絡不能被動地傳輸信息。相反, 為了解碼器能夠更好的解碼, 它一定要找到最好的方式將輸入的信息保留至一個非常小的單元中。
訓練之后, 編碼器與解碼器分離, 編碼器用在壓縮數據的接收端或編碼數據用來傳輸, 利用極少的數據格式來傳輸信息同時保證丟失最少的數據信息。 也可以用來降低數據的維度。
另一個例子是,考慮大量的文本集合(也許是來自數字平臺的評論)。通過某種聚類或流形學習方法,我們可以為文本集合生成聚類標簽,然后將其作為標簽處理(前提是聚類工作做得很好)。
在對每個聚類簇進行解釋后(例如,聚類A代表抱怨產品的評論,聚類B代表積極反饋等),然后可以使用BERT這樣的深層NLP架構將新文本分類到這些聚類簇中,所有這些都是完全未標記的數據和最少的人工參與。
這又是一個將無監督任務轉換為有監督任務的有趣應用程序。在一個絕大多數數據都是無監督數據的時代,通過混合學習建立創造性的橋梁,跨越有監督和無監督學習之間的界限,具有巨大的價值和潛力。
成分學習
成分學習不僅使用一個模型的知識,而且使用多個模型的知識。人們相信,通過獨特的信息組合或投入(包括靜態和動態的),深度學習可以比單一的模型在理解和性能上不斷深入。
遷移學習是一個非常明顯的成分學習的例子, 基于這樣的一個想法, 在相似問題上預訓練的模型權重可以用來在一個特定的問題上進行微調。構建像Inception或者VGG-16這樣的預訓練模型來區分不同類別的圖像。
如果我打算訓練一個識別動物(例如貓和狗)的模型, 我不會從頭訓練一個卷積神經網絡,因為這樣會消耗太多的時間才能夠達到很好的結果。相反,我會采用一個像Inception的預訓練模型,這個模型已經存儲了圖像識別的基本信息, 然后在這個數據集(貓狗數據集)上訓練額外的迭代次數即可。
類似地,在NLP神經網絡中的詞嵌入模型,它根據單詞之間的關系將單詞映射到嵌入空間中更接近其他單詞的位置(例如,蘋果和句子的距離比蘋果和卡車的距離要小)。像GloVe這樣的預訓練embedding可以被放入神經網絡中,從已經有效地將單詞映射到數值的, 有意義的實體開始。
不那么明顯的是,競爭也能刺激知識增長。其一,生成性對抗性網絡借用了復合學習范式從根本上使兩個神經網絡相互對立。生成器的目標是欺騙鑒別器,而鑒別器的目標是不被欺騙。
模型之間的競爭將被稱為“對抗性學習”,不要與另一種類型的對抗性學習相混淆,那是設計惡意輸入并發現模型中的弱決策邊界。
對抗性學習可以刺激模型,通常是不同類型的模型,其中模型的性能可以表示為與其他模型的性能相關。在對抗性學習領域還有很多研究要做,生成性對抗性網絡是對抗性學習的唯一突出創舉。
另一方面,競爭學習類似于對抗性學習,但是在逐節點規模上進行的:節點競爭對輸入數據子集的響應權。競爭學習是在一個“競爭層”中實現的,在競爭層中,除了一些隨機分布的權值外,一組神經元都是相同的。
將每個神經元的權重向量與輸入向量進行比較,并激活相似度最高的神經元也就是“贏家通吃”神經元(輸出=1)。其他的被“停用”(輸出=0)。這種無監督技術是自組織映射和特征發現的核心部分。
另一個成分學習的又去例子時神經架構搜索。簡單來說, 在強化學習環境中, 一個神經網絡(通常時遞歸神經網絡)學習生成對于這個數據集來說最好的網絡架構——算法為你找到最好的架構,你可以在這兒讀到更多的關于這個理論的知識,并且在這兒應用python代碼實現。
集成的方法在成分學習中也時主要的, 深度集成的方法已經展示出了其高效性。并且模型端到端的堆疊, 例如編碼器與解碼器已經變得非常受歡迎。
許多成分學習都在尋找在不同模型之間建立聯系的獨特方法。它們都基于這個想法:
單一的模型甚至一個非常大的模型,通常也比幾個小模型/組件表現的差,這些小模型每一個都被分配專門處理任務中的一部分
例如, 考慮構建餐廳聊天機器人的任務。
我們可以將這個機器人分割為三個分離的部分:寒暄/閑聊,信息檢索和行動機器人,并為每一部分專門設計一個模型。或者,我們可以委托一個單一的模型來執行這三個任務。
組合模型可以在占用較少空間的同時表現更好,這一點也不奇怪。此外,這些類型的非線性拓撲可以用Keras functional API等工具輕松構建。
為了處理像視頻和三維數據等形式日益多樣化的數據類型,研究人員必須構建創造性的組合模型。
在這里閱讀更多關于成分學習和未來的信息。
簡化學習
在深度學習領域, 特別是在NLP(深度學習領域研究最熱潮激動人心的領域)中,模型的規模正在不斷增長。最新的GPT-3模型有1750億個參數。把它和BERT比較就像把木星比作蚊子一樣(好吧,不是字面意思)。深度學習的未來會更大嗎?
按理來說,不會,GPT-3是非常有說服力的,但它在過去反復表明,“成功的科學”是對人類影響最大的科學。學術界總是離現實太遠,太過模糊。在19世紀末,由于可用數據太少,神經網絡被遺忘了很短一段時間,所以這個想法,無論多么巧妙,都毫無用處。
GPT-3是另一種語言模型,它可以編寫令人信服的文本。它的應用在哪里?是的,例如,它可以生成查詢的答案。然而,有更有效的方法來做到這一點(例如,遍歷一個知識圖譜并使用一個更小的模型,如BERT來輸出答案)。
在計算能力枯竭的情況下,GPT-3的巨大尺寸(更不用說更大的模型)是不可行的或不必要的。
“摩爾定律有點沒用了。” Satya Nadella,微軟首席執行官
取而代之的是,我們正在走向一個人工智能嵌入式世界,智能冰箱可以自動訂購食品,而無人機可以自動導航整個城市。強大的機器學習方法應該能夠下載到個人電腦、手機和小芯片上。
這就需要輕量級人工智能:在保持性能的同時使神經網絡更小。
這直接或間接地表明,在深度學習研究中,幾乎所有的事情都與減少必要的參數量有關,這與提高泛化能力和性能密切相關。例如,卷積層的引入大大減少了神經網絡處理圖像所需的參數數量。遞歸層融合了時間的思想,同時使用相同的權值,使得神經網絡能夠更好地處理序列,并且參數更少。
嵌入層顯式地將實體映射到具有物理意義的數值,這樣就不會給附加參數增加負擔。在一種解釋中,Dropout層顯式地阻止參數對輸入的某些部分進行操作。L1/L2正則化通過確保所有參數都不會增長過大來確保網絡利用了所有參數,并且每個參數都能使其信息價值最大化。
隨著這種特殊專用層的創建,網絡對更復雜和更大的數據所需的參數越來越少。其他較新的方法顯式地尋求壓縮網絡。
神經網絡修剪試圖去除那些對網絡輸出沒有價值的突觸和神經元。通過修剪,網絡可以保持其性能,同時刪除幾乎所有的自身。
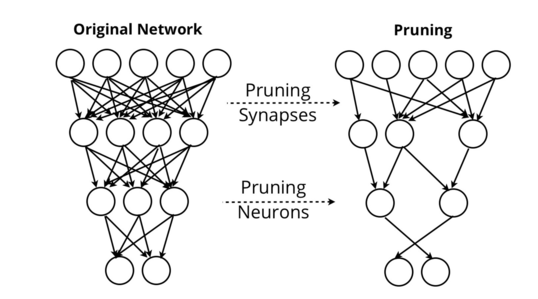
其他的方法像Patient Knowledge Distillation找到一些壓縮語言模型的方法, 使其可以下載到例如用戶的手機的格式。 對于谷歌神經機器翻譯系統來說這是必要的考慮, 這個系統支持谷歌翻譯, 谷歌翻譯公司需要創建一個可以離線訪問的高性能翻譯服務。
本質上,簡化學習集中在以部署為中心的設計上。這就是為什么大多數簡化學習的研究來自公司的研究部門。以部署為中心的設計的一個方面不是盲目地遵循數據集的性能指標,而是在部署模型時關注潛在的問題。
例如,前面提到的對抗輸入是設計用來欺騙網絡的惡意輸入。在標牌上噴漆或貼上標簽,會誘使自動駕駛汽車加速超過限速。負責任的簡化學習的不僅使模型足夠輕量級以供使用,而且確保它能夠適應數據集中沒有出現過的角落情況。
在深度學習的研究中,簡化學習可能是最不受關注的,因為“我們通過一個可行的架構尺寸實現了良好的性能” 并不像 “我們通過由數千千萬萬個參數組成的體系結構實現了最先進的性能”一樣吸引人。
不可避免地,當追求更高得分表現的宣傳消失時,正如創新的歷史所示,簡化學習—實際上是真正的實踐性學習—將得到更多應有的關注。
?責任編輯人:CC

























 工商網監
工商網監
評論