 電子發(fā)燒友App
電子發(fā)燒友App


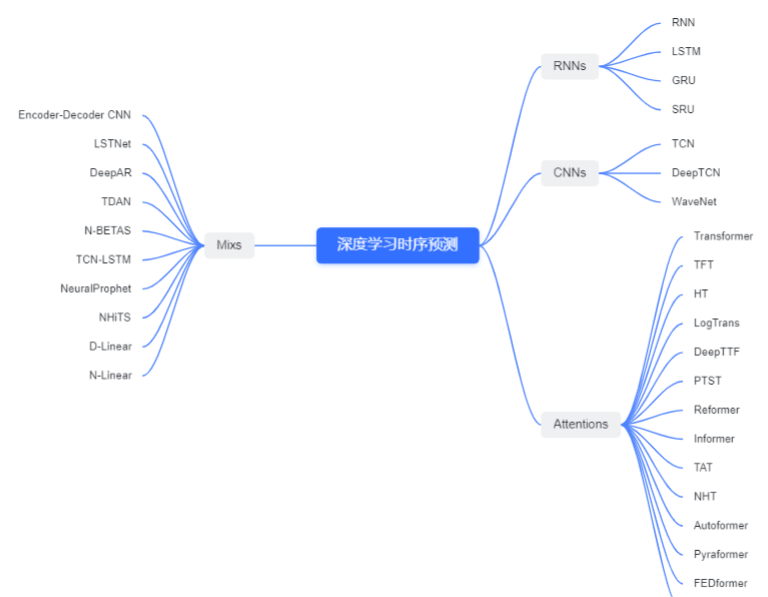
1、概述
深度學(xué)習(xí)方法是一種利用神經(jīng)網(wǎng)絡(luò)模型進(jìn)行高級(jí)模式識(shí)別和自動(dòng)特征提取的機(jī)器學(xué)習(xí)方法,近年來(lái)在時(shí)序預(yù)測(cè)領(lǐng)域取得了很好的成果。常用的深度學(xué)習(xí)模型包括循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)、長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)、門(mén)控循環(huán)單元(GRU)、卷積神經(jīng)網(wǎng)絡(luò)(CNN)、注意力機(jī)制(Attention)和混合模型(Mix )等,與機(jī)器學(xué)習(xí)需要經(jīng)過(guò)復(fù)雜的特征工程相比,這些模型通常只需要經(jīng)數(shù)據(jù)預(yù)處理、網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)和超參數(shù)調(diào)整等,即可端到端輸出時(shí)序預(yù)測(cè)結(jié)果。深度學(xué)習(xí)算法能夠自動(dòng)學(xué)習(xí)時(shí)間序列數(shù)據(jù)中的模式和趨勢(shì),神經(jīng)網(wǎng)絡(luò)涉及隱藏層數(shù)、神經(jīng)元數(shù)、學(xué)習(xí)率和激活函數(shù)等重要參數(shù),對(duì)于復(fù)雜的非線性模式,深度學(xué)習(xí)模型有很好的表達(dá)能力。在應(yīng)用深度學(xué)習(xí)方法進(jìn)行時(shí)序預(yù)測(cè)時(shí),需要考慮數(shù)據(jù)的平穩(wěn)性和周期性,選擇合適的模型和參數(shù),進(jìn)行訓(xùn)練和測(cè)試,并進(jìn)行模型的調(diào)優(yōu)和驗(yàn)證。
2、算法展示
2.1 RNN類
在RNN中,每個(gè)時(shí)刻的輸入和之前時(shí)刻的狀態(tài)被映射到隱藏狀態(tài)中,同時(shí)根據(jù)當(dāng)前的輸入和之前的狀態(tài),預(yù)測(cè)下一個(gè)時(shí)刻的輸出。RNN的一個(gè)重要特性是可以處理變長(zhǎng)的序列數(shù)據(jù),因此非常適用于時(shí)序預(yù)測(cè)中的時(shí)間序列數(shù)據(jù)。另外,RNN還可以通過(guò)增加LSTM、GRU、SRU等門(mén)控機(jī)制來(lái)提高模型的表達(dá)能力和記憶能力。
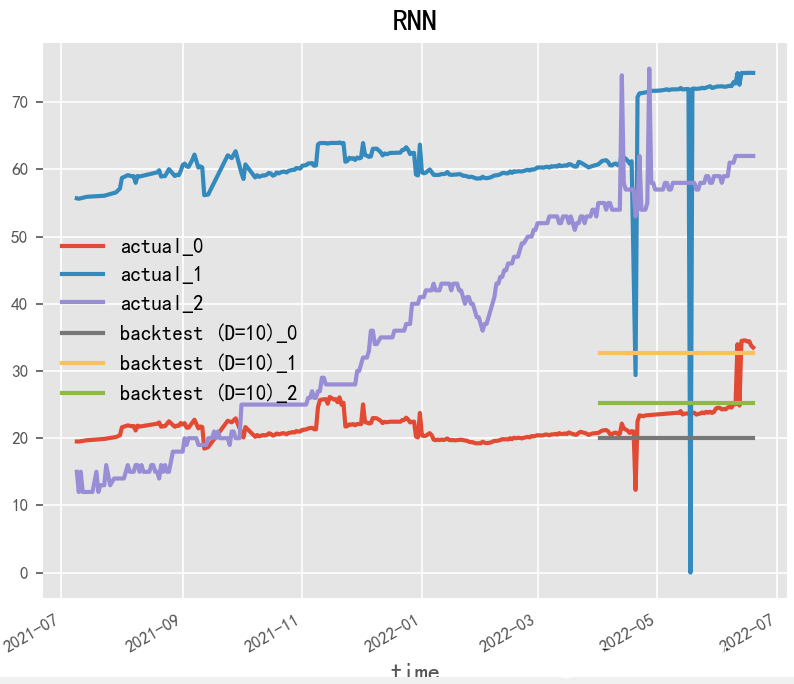
2.1.1 RNN(1990)
Paper:Finding Structure in Time
RNN(循環(huán)神經(jīng)網(wǎng)絡(luò))是一種強(qiáng)大的深度學(xué)習(xí)模型,經(jīng)常被用于時(shí)間序列預(yù)測(cè)。RNN通過(guò)在時(shí)間上展開(kāi)神經(jīng)網(wǎng)絡(luò),將歷史信息傳遞到未來(lái),從而能夠處理時(shí)間序列數(shù)據(jù)中的時(shí)序依賴性和動(dòng)態(tài)變化。在RNN模型的構(gòu)建中,LSTM和GRU模型常被使用,因?yàn)樗鼈兛梢蕴幚黹L(zhǎng)序列,并具有記憶單元和門(mén)控機(jī)制,能夠有效地捕捉時(shí)間序列中的時(shí)序依賴性。

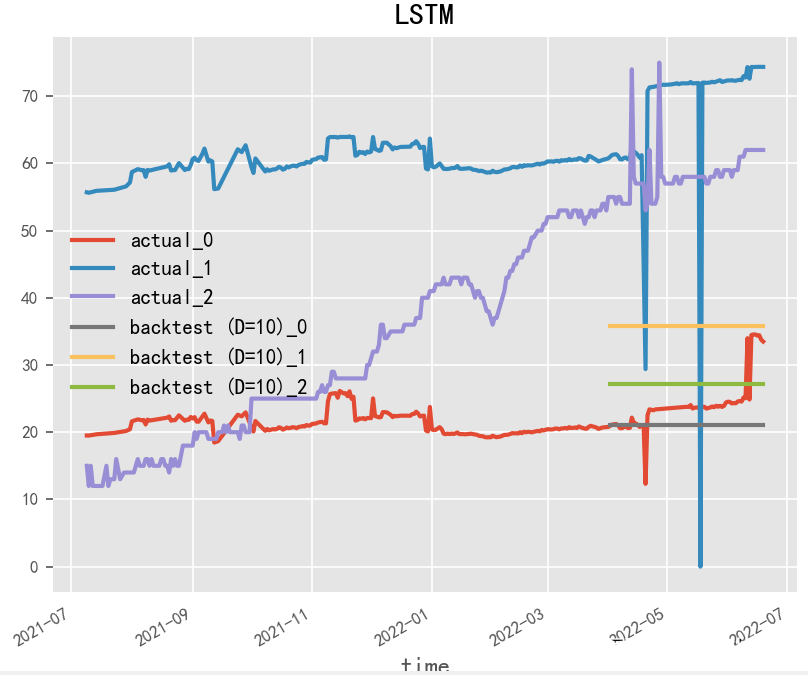
2.1.2 LSTM(1997)
Paper:Long Short-Term Memory
LSTM(長(zhǎng)短期記憶)是一種常用的循環(huán)神經(jīng)網(wǎng)絡(luò)模型,經(jīng)常被用于時(shí)間序列預(yù)測(cè)。相對(duì)于基本的RNN模型,LSTM具有更強(qiáng)的記憶和長(zhǎng)期依賴能力,可以更好地處理時(shí)間序列數(shù)據(jù)中的時(shí)序依賴性和動(dòng)態(tài)變化。在LSTM模型的構(gòu)建中,關(guān)鍵的是對(duì)LSTM單元的設(shè)計(jì)和參數(shù)調(diào)整。LSTM單元的設(shè)計(jì)可以影響模型的記憶能力和長(zhǎng)期依賴能力,參數(shù)的調(diào)整可以影響模型的預(yù)測(cè)準(zhǔn)確性和魯棒性。

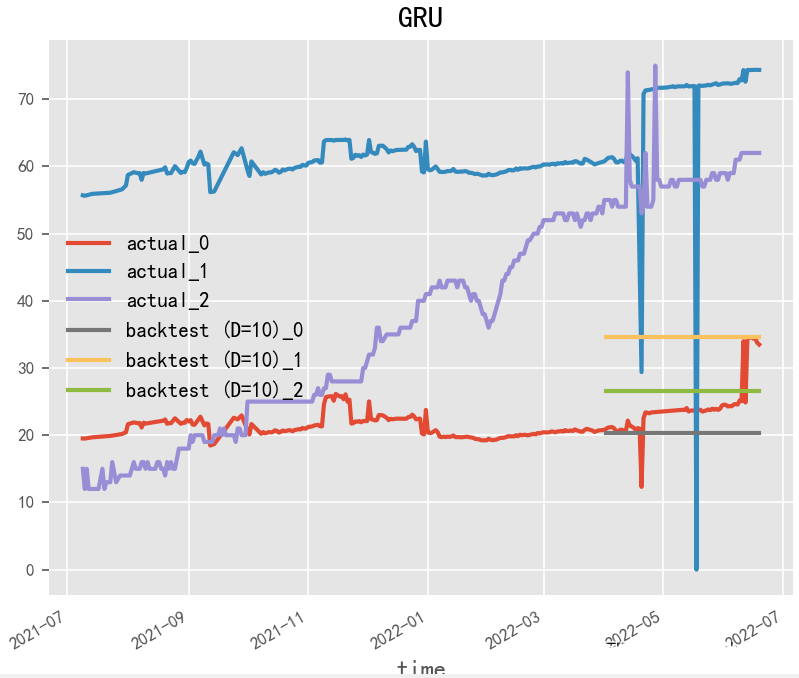
2.1.3 GRU(2014)
Paper:Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
GRU(門(mén)控循環(huán)單元)是一種常用的循環(huán)神經(jīng)網(wǎng)絡(luò)模型,與LSTM模型類似,也是專門(mén)用于處理時(shí)間序列數(shù)據(jù)的模型。GRU模型相對(duì)于LSTM模型來(lái)說(shuō),參數(shù)更少,運(yùn)算速度也更快,但是仍然能夠處理時(shí)間序列數(shù)據(jù)中的時(shí)序依賴性和動(dòng)態(tài)變化。在GRU模型的構(gòu)建中,關(guān)鍵的是對(duì)GRU單元的設(shè)計(jì)和參數(shù)調(diào)整。GRU單元的設(shè)計(jì)可以影響模型的記憶能力和長(zhǎng)期依賴能力,參數(shù)的調(diào)整可以影響模型的預(yù)測(cè)準(zhǔn)確性和魯棒性。

2.1.4 SRU(2018)
Paper:Simple Recurrent Units for Highly Parallelizable Recurrence
SRU(隨機(jī)矩陣單元)是一種基于矩陣計(jì)算的循環(huán)神經(jīng)網(wǎng)絡(luò)模型,也是專門(mén)用于處理時(shí)間序列數(shù)據(jù)的模型。SRU模型相對(duì)于傳統(tǒng)的LSTM和GRU模型來(lái)說(shuō),具有更少的參數(shù)和更快的運(yùn)算速度,同時(shí)能夠處理時(shí)間序列數(shù)據(jù)中的時(shí)序依賴性和動(dòng)態(tài)變化。在SRU模型的構(gòu)建中,關(guān)鍵的是對(duì)SRU單元的設(shè)計(jì)和參數(shù)調(diào)整。SRU單元的設(shè)計(jì)可以影響模型的記憶能力和長(zhǎng)期依賴能力,參數(shù)的調(diào)整可以影響模型的預(yù)測(cè)準(zhǔn)確性和魯棒性。
2.2 CNN類
CNN通過(guò)卷積層和池化層等操作可以自動(dòng)提取時(shí)間序列數(shù)據(jù)的特征,從而實(shí)現(xiàn)時(shí)序預(yù)測(cè)。在應(yīng)用CNN進(jìn)行時(shí)序預(yù)測(cè)時(shí),需要將時(shí)間序列數(shù)據(jù)轉(zhuǎn)化為二維矩陣形式,然后利用卷積和池化等操作進(jìn)行特征提取和壓縮,最后使用全連接層進(jìn)行預(yù)測(cè)。相較于傳統(tǒng)的時(shí)序預(yù)測(cè)方法,CNN能夠自動(dòng)學(xué)習(xí)時(shí)間序列數(shù)據(jù)中的復(fù)雜模式和規(guī)律,同時(shí)具有更好的計(jì)算效率和預(yù)測(cè)精度。
2.2.1 WaveNet(2016)
Paper:WAVENET: A GENERATIVE MODEL FOR RAW AUDIO
WaveNet是由DeepMind團(tuán)隊(duì)在2016年提出的一種用于生成語(yǔ)音的神經(jīng)網(wǎng)絡(luò)模型,它的核心思想是利用卷積神經(jīng)網(wǎng)絡(luò)來(lái)模擬語(yǔ)音信號(hào)的波形,并使用殘差連接和門(mén)控卷積操作來(lái)提高模型的表示能力。除了用于語(yǔ)音生成,WaveNet還可以應(yīng)用于時(shí)序預(yù)測(cè)任務(wù)。在時(shí)序預(yù)測(cè)任務(wù)中,我們需要預(yù)測(cè)給定時(shí)間序列的下一個(gè)時(shí)間步的取值。通常情況下,我們可以將時(shí)間序列看作是一個(gè)一維向量,并將其輸入到WaveNet模型中,得到下一個(gè)時(shí)間步的預(yù)測(cè)值。
在WaveNet模型的構(gòu)建中,關(guān)鍵的是對(duì)卷積層的設(shè)計(jì)和參數(shù)調(diào)整。卷積層的設(shè)計(jì)可以影響模型的表達(dá)能力和泛化能力,參數(shù)的調(diào)整可以影響模型的預(yù)測(cè)準(zhǔn)確性和魯棒性。
2.2.2 TCN(2018)
Paper:An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
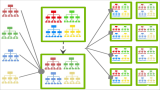
TCN(Temporal Convolutional Network)是一種基于卷積神經(jīng)網(wǎng)絡(luò)的時(shí)序預(yù)測(cè)算法,其設(shè)計(jì)初衷是為了解決傳統(tǒng)RNN(循環(huán)神經(jīng)網(wǎng)絡(luò))在處理長(zhǎng)序列時(shí)存在的梯度消失和計(jì)算復(fù)雜度高的問(wèn)題。。相比于傳統(tǒng)的RNN等序列模型,TCN利用卷積神經(jīng)網(wǎng)絡(luò)的特點(diǎn),能夠在更短的時(shí)間內(nèi)對(duì)長(zhǎng)期依賴進(jìn)行建模,并且具有更好的并行計(jì)算能力。TCN模型由多個(gè)卷積層和殘差連接組成,其中每個(gè)卷積層的輸出會(huì)被輸入到后續(xù)的卷積層中,從而實(shí)現(xiàn)對(duì)序列數(shù)據(jù)的逐層抽象和特征提取。TCN還采用了類似于ResNet的殘差連接技術(shù),可以有效地減少梯度消失和模型退化等問(wèn)題,而空洞卷積可以擴(kuò)大卷積核的感受野,從而提高模型的魯棒性和準(zhǔn)確性。
TCN模型的結(jié)構(gòu)如下圖所示:
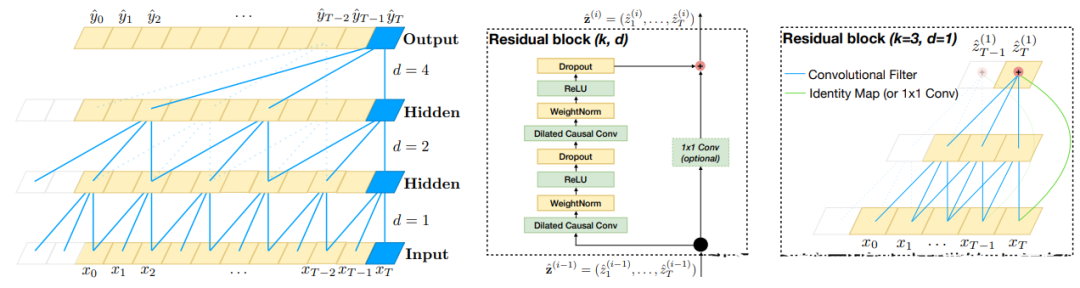
TCN模型的預(yù)測(cè)過(guò)程包括以下幾個(gè)步驟:
輸入層:接收時(shí)間序列數(shù)據(jù)的輸入。
卷積層:采用一維卷積對(duì)輸入數(shù)據(jù)進(jìn)行特征提取和抽象,每個(gè)卷積層包含多個(gè)卷積核,可以捕獲不同尺度的時(shí)間序列模式。
殘差連接:類似于ResNet,通過(guò)將卷積層的輸出與輸入進(jìn)行殘差連接,可以有效地減少梯度消失和模型退化等問(wèn)題,提高模型的魯棒性。
重復(fù)堆疊:重復(fù)堆疊多個(gè)卷積層和殘差連接,逐層提取時(shí)間序列數(shù)據(jù)的抽象特征。
池化層:在最后一個(gè)卷積層之后添加一個(gè)全局平均池化層,將所有特征向量進(jìn)行平均,得到一個(gè)固定長(zhǎng)度的特征向量。
輸出層:將池化層的輸出通過(guò)一個(gè)全連接層進(jìn)行輸出,得到時(shí)間序列的預(yù)測(cè)值。
TCN模型的優(yōu)點(diǎn)包括:
能夠處理長(zhǎng)序列數(shù)據(jù),并且具有良好的并行性。
通過(guò)引入殘差連接和空洞卷積等技術(shù),避免了梯度消失和過(guò)擬合的問(wèn)題。
相對(duì)于傳統(tǒng)RNN模型,TCN模型具有更高的計(jì)算效率和預(yù)測(cè)準(zhǔn)確率。
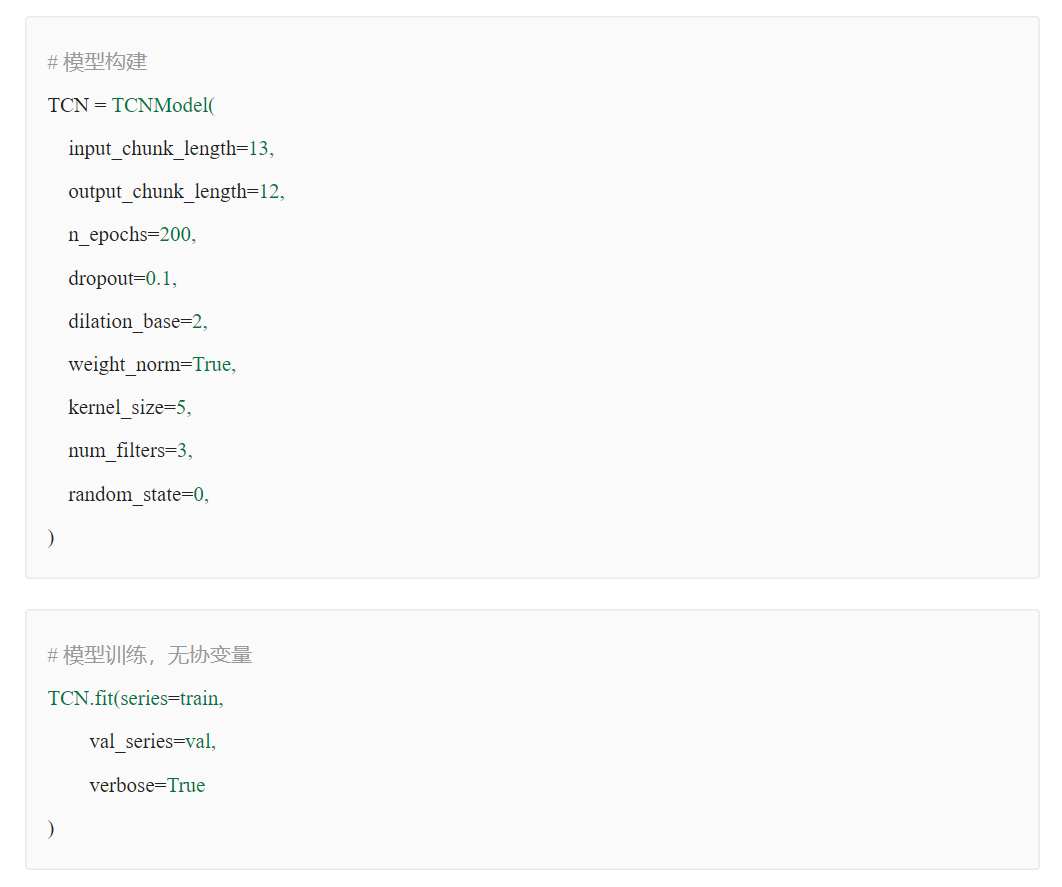
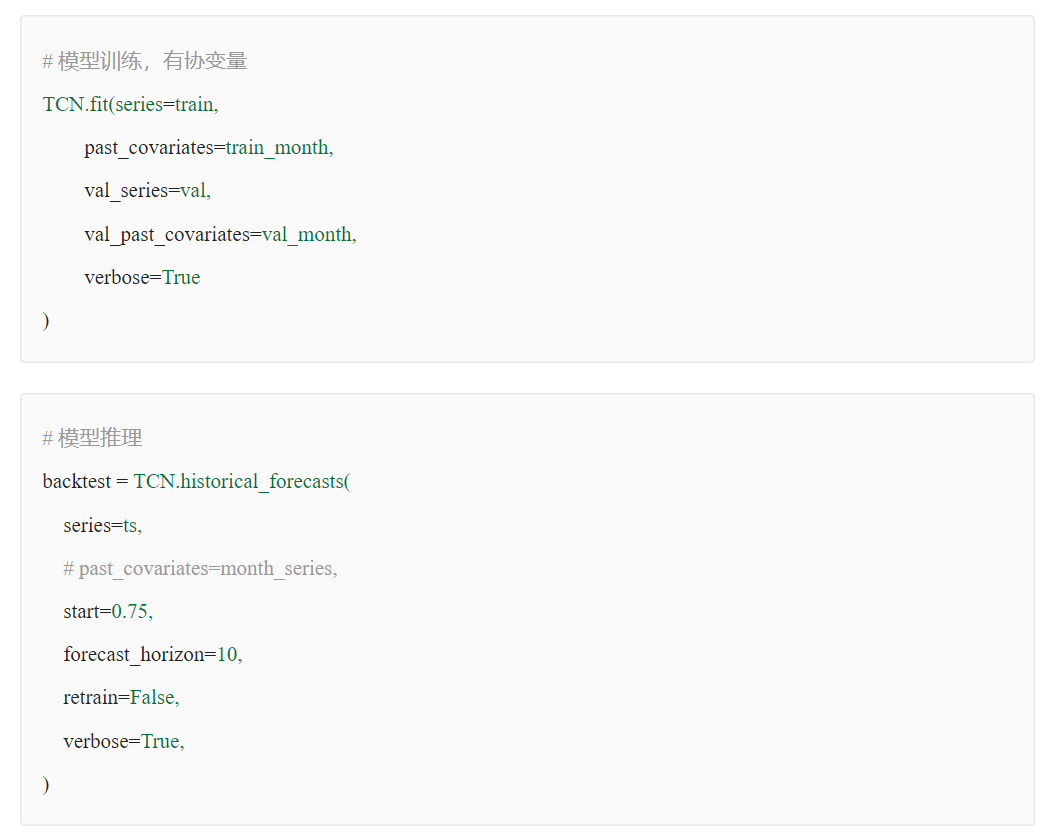
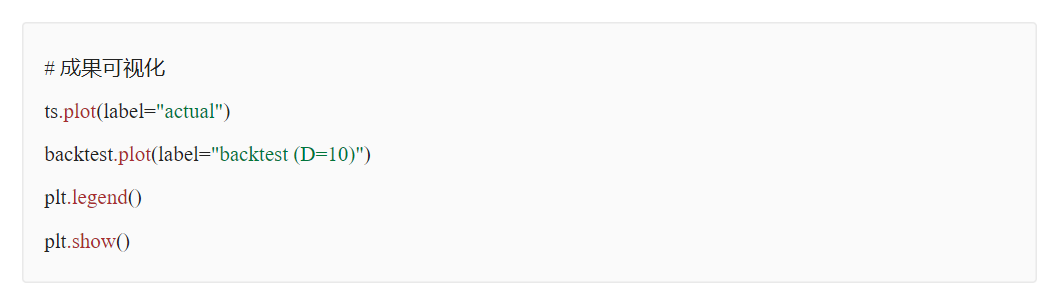
數(shù)據(jù)歸一化對(duì)時(shí)序預(yù)測(cè)影響探究?
原始數(shù)據(jù)是否按月份生成協(xié)變量,是否歸一化,對(duì)最終時(shí)序預(yù)測(cè)效果影響重大,就本實(shí)驗(yàn)場(chǎng)景而言,原始數(shù)據(jù)為百分制更適用于無(wú)歸一化&有協(xié)變量方式,協(xié)變量需根據(jù)實(shí)際業(yè)務(wù)表現(xiàn)進(jìn)行選擇
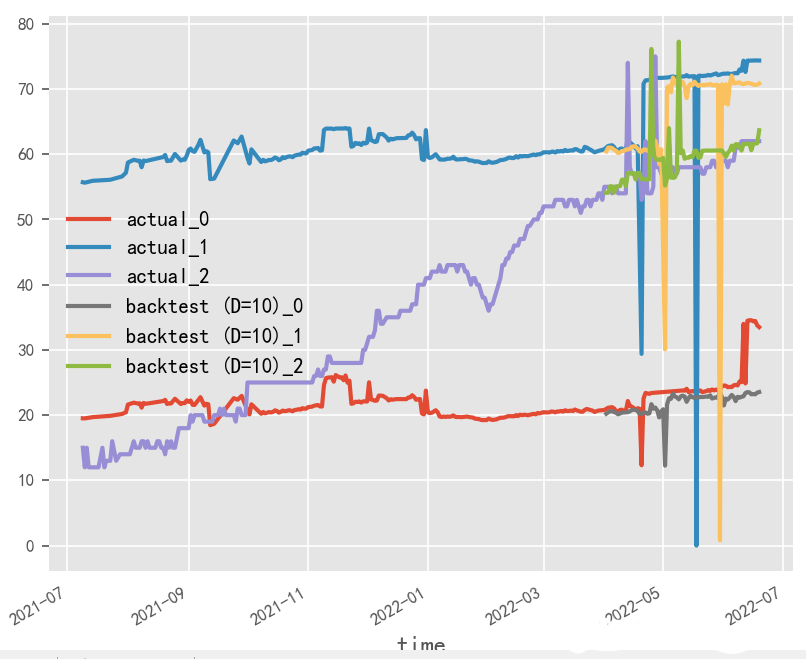
歸一化&無(wú)協(xié)變量
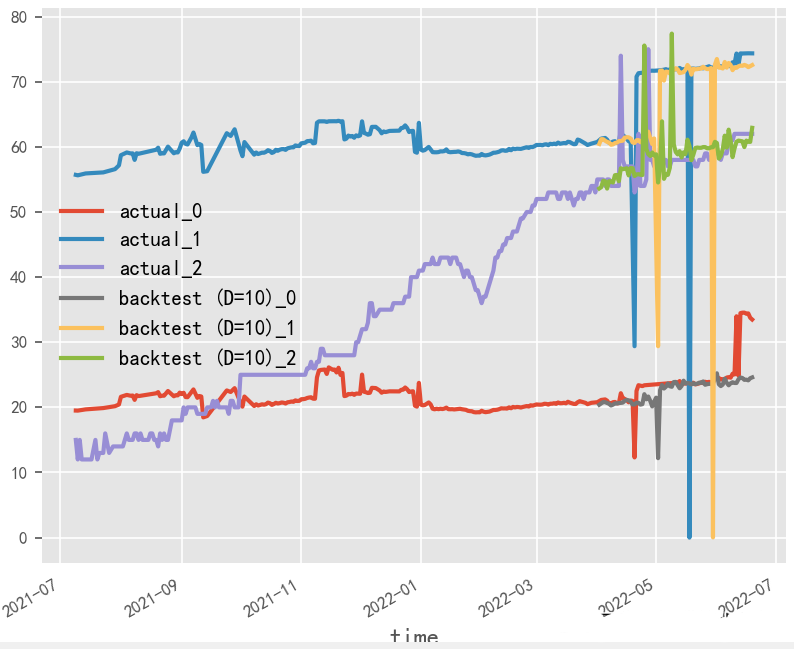
歸一化&有協(xié)變量
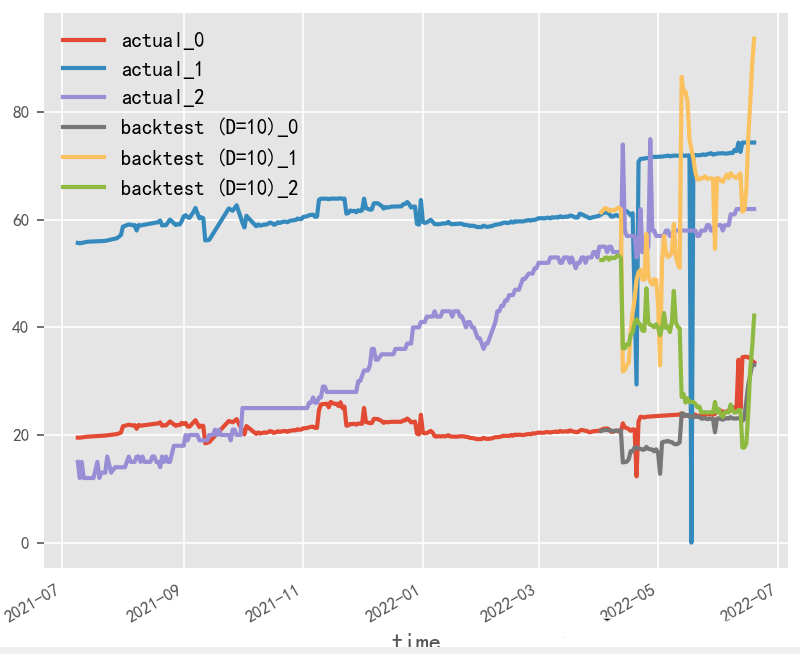
無(wú)歸一化&無(wú)協(xié)變量
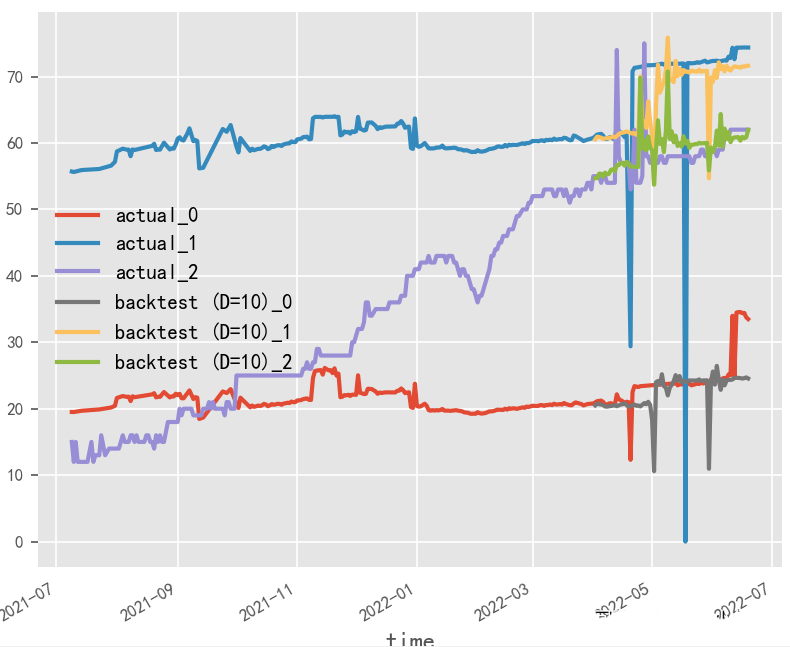
無(wú)歸一化&有協(xié)變量
2.2.3 DeepTCN(2019)
Paper:Probabilistic Forecasting with Temporal Convolutional Neural Network
Code:deepTCN
DeepTCN(Deep Temporal Convolutional Networks)是一種基于深度學(xué)習(xí)的時(shí)序預(yù)測(cè)模型,它是對(duì)傳統(tǒng)TCN模型的改進(jìn)和擴(kuò)展。DeepTCN模型使用了一組1D卷積層和最大池化層來(lái)處理時(shí)序數(shù)據(jù),并通過(guò)堆疊多個(gè)這樣的卷積-池化層來(lái)提取時(shí)序數(shù)據(jù)的不同特征。在DeepTCN模型中,每個(gè)卷積層都包含多個(gè)1D卷積核和激活函數(shù),并且使用殘差連接和批量歸一化技術(shù)來(lái)加速模型的訓(xùn)練。
DeepTCN模型的訓(xùn)練過(guò)程通常涉及以下幾個(gè)步驟:
數(shù)據(jù)預(yù)處理:將原始的時(shí)序數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化和歸一化處理,以減小不同特征的尺度不一致對(duì)模型訓(xùn)練的影響。
模型構(gòu)建:使用多個(gè)1D卷積層和最大池化層構(gòu)建DeepTCN模型,可以使用深度學(xué)習(xí)框架,如TensorFlow、PyTorch等來(lái)構(gòu)建模型。
模型訓(xùn)練:使用訓(xùn)練數(shù)據(jù)集對(duì)DeepTCN模型進(jìn)行訓(xùn)練,并通過(guò)損失函數(shù)(如MSE、RMSE等)來(lái)度量模型的預(yù)測(cè)性能。在訓(xùn)練過(guò)程中,可以使用優(yōu)化算法(如SGD、Adam等)來(lái)更新模型參數(shù),并使用批量歸一化和DeepTCN等技術(shù)來(lái)提高模型的泛化能力。
模型評(píng)估:使用測(cè)試數(shù)據(jù)集對(duì)訓(xùn)練好的DEEPTCN模型進(jìn)行評(píng)估,并計(jì)算模型的性能指標(biāo),如平均絕對(duì)誤差(MAE)、平均絕對(duì)百分比誤差(MAPE)等。
模型訓(xùn)練輸入輸出長(zhǎng)度對(duì)時(shí)序預(yù)測(cè)影響探究?
就本實(shí)驗(yàn)場(chǎng)景而言,受原始數(shù)據(jù)樣本限制,輸入輸出長(zhǎng)度和batch_size無(wú)法過(guò)大調(diào)整,從性能角度建議選用大batch_size&短輸入輸出方式
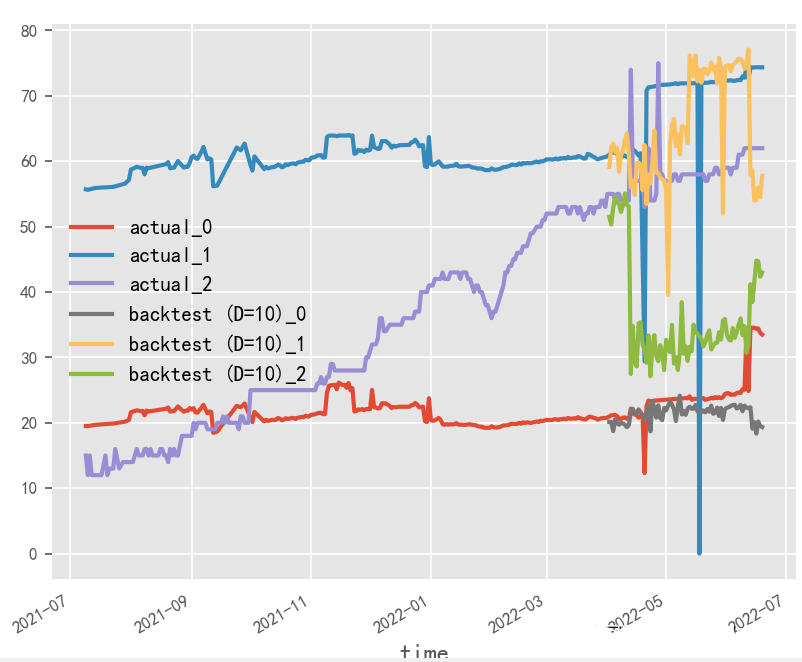
短輸入輸出
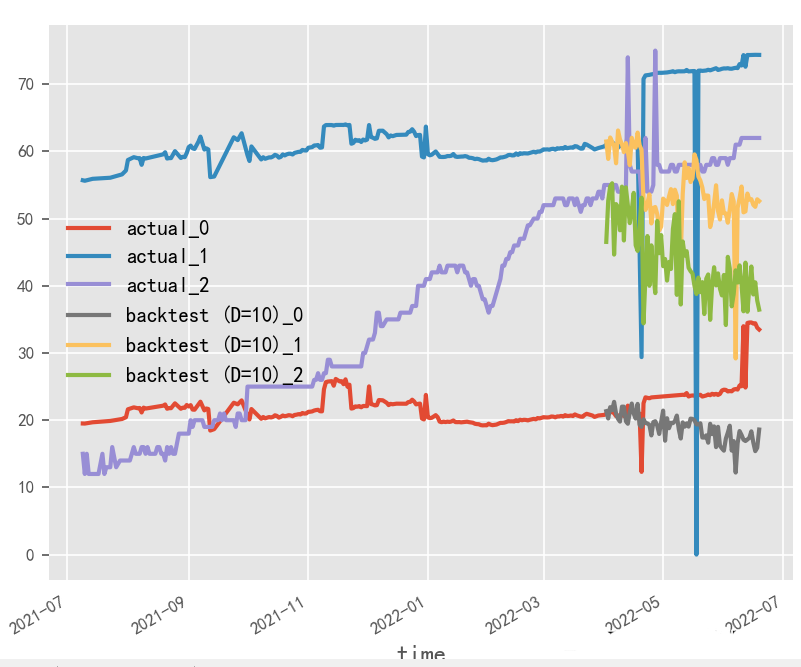
長(zhǎng)輸入輸出
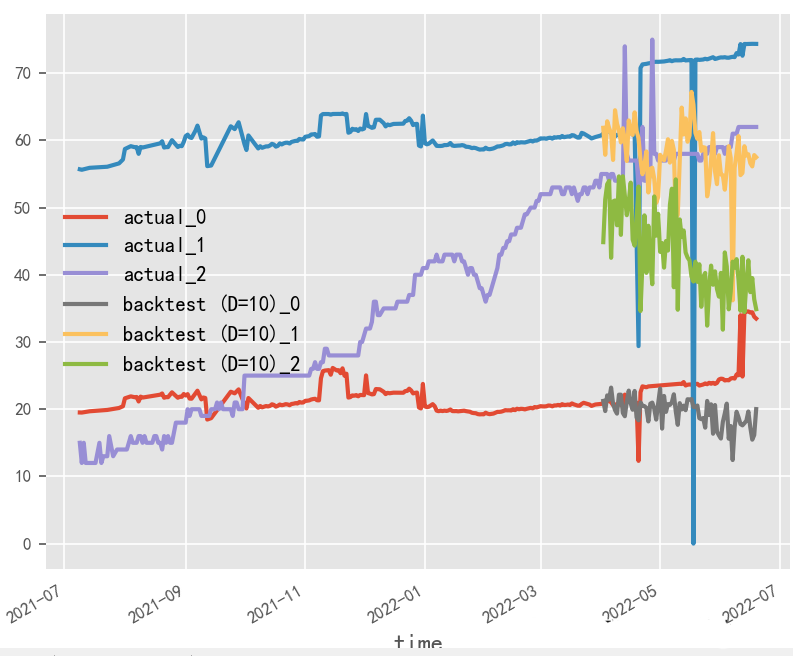
長(zhǎng)輸入輸出,大batch_size
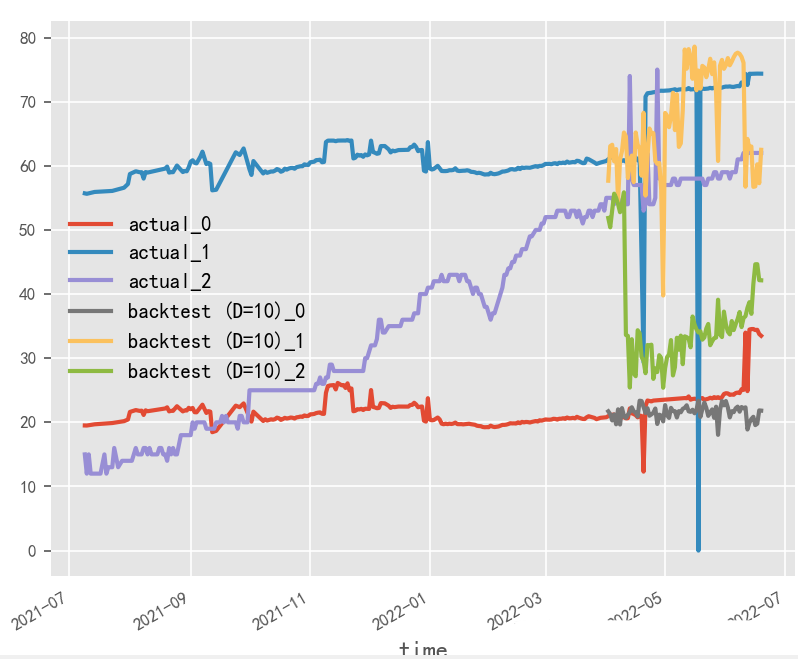
短輸入輸出,大batch_size
2.3 Attention類
注意力機(jī)制(Attention)是一種用于解決序列輸入數(shù)據(jù)中重要特征提取的機(jī)制,也被應(yīng)用于時(shí)序預(yù)測(cè)領(lǐng)域。Attention機(jī)制可以自動(dòng)關(guān)注時(shí)間序列數(shù)據(jù)中的重要部分,為模型提供更有用的信息,從而提高預(yù)測(cè)精度。在應(yīng)用Attention進(jìn)行時(shí)序預(yù)測(cè)時(shí),需要利用Attention機(jī)制自適應(yīng)地加權(quán)輸入數(shù)據(jù)的各個(gè)部分,從而使得模型更加關(guān)注關(guān)鍵信息,同時(shí)減少無(wú)關(guān)信息的影響。Attention機(jī)制不僅可以應(yīng)用于RNN等序列模型,也可以應(yīng)用于CNN等非序列模型,是目前時(shí)序預(yù)測(cè)領(lǐng)域研究的熱點(diǎn)之一。
2.3.1 Transformer(2017)
Paper:Attention Is All You Need
Transformer是一種廣泛應(yīng)用于自然語(yǔ)言處理(NLP)領(lǐng)域的神經(jīng)網(wǎng)絡(luò)模型,其本質(zhì)是一種序列到序列(seq2seq)的模型。Transformer將序列中的每個(gè)位置視為一個(gè)向量,并使用多頭自注意力機(jī)制和前饋神經(jīng)網(wǎng)絡(luò)來(lái)捕捉序列中的長(zhǎng)程依賴性,從而使得模型能夠處理變長(zhǎng)序列和不定長(zhǎng)序列。
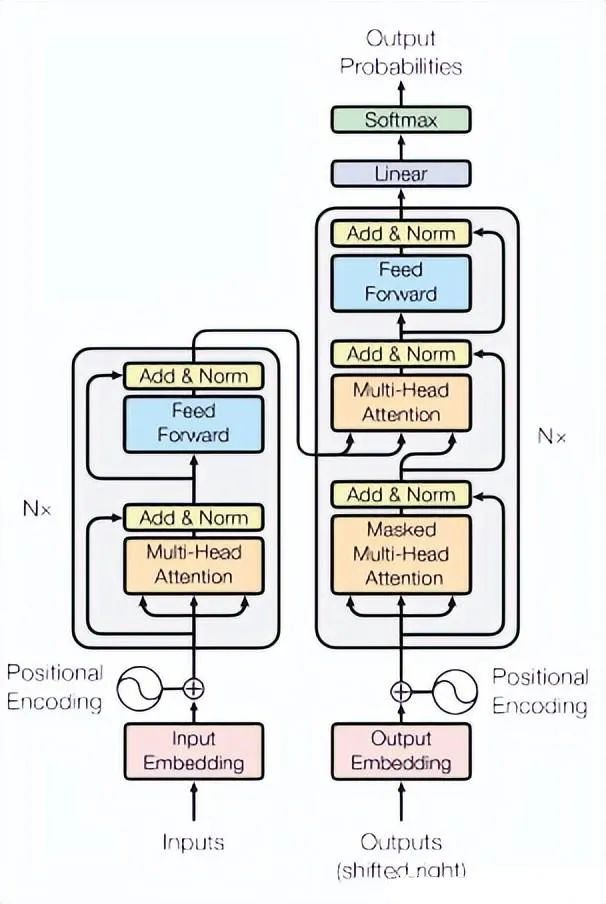
在時(shí)序預(yù)測(cè)任務(wù)中,Transformer模型可以將輸入序列的時(shí)間步作為位置信息,將每個(gè)時(shí)間步的特征表示為一個(gè)向量,并使用編碼器-解碼器框架進(jìn)行預(yù)測(cè)。具體來(lái)說(shuō),可以將預(yù)測(cè)目標(biāo)的前N個(gè)時(shí)間步作為編碼器的輸入,將預(yù)測(cè)目標(biāo)的后M個(gè)時(shí)間步作為解碼器的輸入,并使用編碼器-解碼器框架進(jìn)行預(yù)測(cè)。編碼器和解碼器都是由多個(gè)Transformer模塊堆疊而成,每個(gè)模塊由多頭自注意力層和前饋神經(jīng)網(wǎng)絡(luò)層組成。
在訓(xùn)練過(guò)程中,可以使用均方誤差(MSE)或平均絕對(duì)誤差(MAE)等常見(jiàn)的損失函數(shù)來(lái)度量模型的預(yù)測(cè)性能,使用隨機(jī)梯度下降(SGD)或Adam等優(yōu)化算法來(lái)更新模型參數(shù)。在模型訓(xùn)練過(guò)程中,還可以使用學(xué)習(xí)率調(diào)整、梯度裁剪等技術(shù)來(lái)加速模型的訓(xùn)練和提高模型的性能。
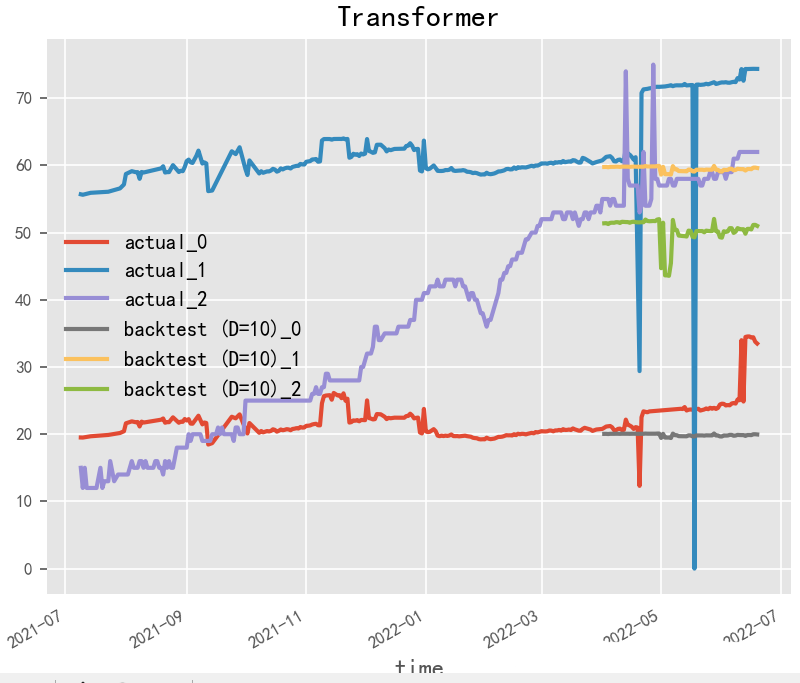
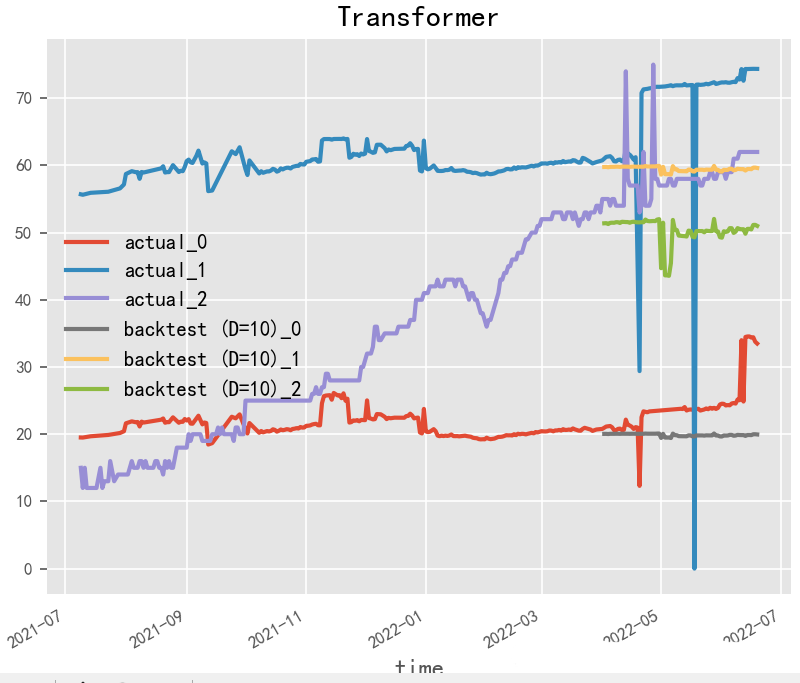
2.3.2 TFT(2019)
Paper:Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting
TFT(Transformer-based Time Series Forecasting)是一種基于Transformer模型的時(shí)序預(yù)測(cè)方法,它是由谷歌DeepMind團(tuán)隊(duì)于2019年提出的。TFT方法的核心思想是在Transformer模型中引入時(shí)間特征嵌入(Temporal Feature Embedding)和模態(tài)嵌入(Modality Embedding)。時(shí)間特征嵌入可以幫助模型更好地學(xué)習(xí)時(shí)序數(shù)據(jù)中的周期性和趨勢(shì)性等特征,而模態(tài)嵌入可以將外部的影響因素(如氣溫、節(jié)假日等)與時(shí)序數(shù)據(jù)一起進(jìn)行預(yù)測(cè)。
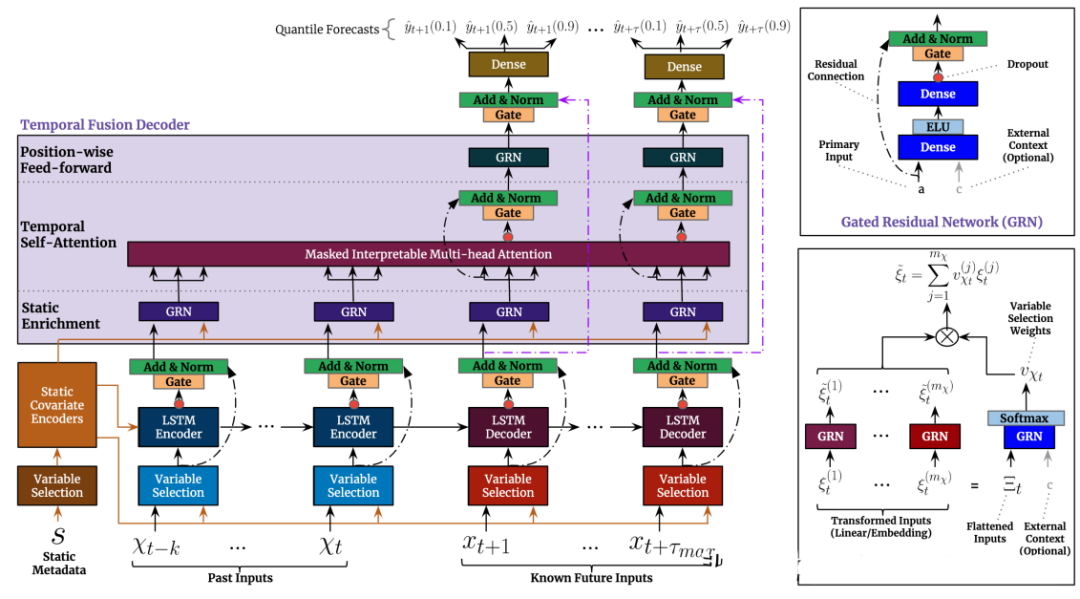
TFT方法可以分為兩個(gè)階段:訓(xùn)練階段和預(yù)測(cè)階段。在訓(xùn)練階段,TFT方法使用訓(xùn)練數(shù)據(jù)來(lái)訓(xùn)練Transformer模型,并使用一些技巧(如隨機(jī)掩碼、自適應(yīng)學(xué)習(xí)率調(diào)整等)來(lái)提高模型的魯棒性和訓(xùn)練效率。在預(yù)測(cè)階段,TFT方法使用已訓(xùn)練好的模型來(lái)對(duì)未來(lái)時(shí)序數(shù)據(jù)進(jìn)行預(yù)測(cè)。
與傳統(tǒng)的時(shí)序預(yù)測(cè)方法相比,TFT方法具有以下優(yōu)點(diǎn):
可以更好地處理不同尺度的時(shí)間序列數(shù)據(jù),因?yàn)門(mén)ransformer模型可以對(duì)時(shí)間序列的全局和局部特征進(jìn)行學(xué)習(xí)。
可以同時(shí)考慮時(shí)間序列數(shù)據(jù)和外部影響因素,從而提高預(yù)測(cè)精度。
可以通過(guò)端到端的訓(xùn)練方式直接學(xué)習(xí)預(yù)測(cè)模型,不需要手動(dòng)提取特征。
2.3.3 HT(2019)
HT(Hierarchical Transformer)是一種基于Transformer模型的時(shí)序預(yù)測(cè)算法,由中國(guó)香港中文大學(xué)的研究人員提出。HT模型采用分層結(jié)構(gòu)來(lái)處理具有多個(gè)時(shí)間尺度的時(shí)序數(shù)據(jù),并通過(guò)自適應(yīng)注意力機(jī)制來(lái)捕捉不同時(shí)間尺度的特征,以提高模型的預(yù)測(cè)性能和泛化能力。
HT模型由兩個(gè)主要組件組成:多尺度注意力模塊和預(yù)測(cè)模塊。在多尺度注意力模塊中,HT模型通過(guò)自適應(yīng)多頭注意力機(jī)制來(lái)捕捉不同時(shí)間尺度的特征,并將不同時(shí)間尺度的特征融合到一個(gè)共同的特征表示中。在預(yù)測(cè)模塊中,HT模型使用全連接層對(duì)特征表示進(jìn)行預(yù)測(cè),并輸出最終的預(yù)測(cè)結(jié)果。
HT模型的優(yōu)點(diǎn)在于,它能夠自適應(yīng)地處理具有多個(gè)時(shí)間尺度的時(shí)序數(shù)據(jù),并通過(guò)自適應(yīng)多頭注意力機(jī)制來(lái)捕捉不同時(shí)間尺度的特征,以提高模型的預(yù)測(cè)性能和泛化能力。此外,HT模型還具有較好的可解釋性和泛化能力,可以適用于多種時(shí)序預(yù)測(cè)任務(wù)。
2.3.4 LogTrans(2019)
Paper:Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
Code:Autoformer
LogTrans提出了一種 Transformer 時(shí)間序列預(yù)測(cè)改進(jìn)方法,包括卷積自注意力(生成具有因果卷積的查詢和密鑰,將局部環(huán)境納入注意力機(jī)制)和LogSparse Transformer(Transformer 的內(nèi)存效率較高的變體,用于降低長(zhǎng)時(shí)間序列建模的內(nèi)存成本),主要用于解決Transformer時(shí)間序列預(yù)測(cè)與位置無(wú)關(guān)的注意力和記憶瓶頸兩個(gè)主要弱點(diǎn)。
2.3.5 DeepTTF(2020)
DeepTTF(Deep Temporal Transformational Factorization)是一種基于深度學(xué)習(xí)和矩陣分解的時(shí)序預(yù)測(cè)算法,由美國(guó)加州大學(xué)洛杉磯分校的研究人員提出。DeepTTF模型將時(shí)間序列分解為多個(gè)時(shí)間段,并使用矩陣分解技術(shù)對(duì)每個(gè)時(shí)間段進(jìn)行建模,以提高模型的預(yù)測(cè)性能和可解釋性。
DeepTTF模型由三個(gè)主要組件組成:時(shí)間分段、矩陣分解和預(yù)測(cè)器。在時(shí)間分段階段,DeepTTF模型將時(shí)間序列分為多個(gè)時(shí)間段,每個(gè)時(shí)間段包含連續(xù)的一段時(shí)間。在矩陣分解階段,DeepTTF模型將每個(gè)時(shí)間段分解為兩個(gè)低維矩陣,分別表示時(shí)間和特征之間的關(guān)系。在預(yù)測(cè)器階段,DeepTTF模型使用多層感知機(jī)對(duì)每個(gè)時(shí)間段進(jìn)行預(yù)測(cè),并將預(yù)測(cè)結(jié)果組合成最終的預(yù)測(cè)序列。
DeepTTF模型的優(yōu)點(diǎn)在于,它能夠有效地捕捉時(shí)間序列中的局部模式和全局趨勢(shì),同時(shí)保持較高的預(yù)測(cè)精度和可解釋性。此外,DeepTTF模型還支持基于時(shí)間分段的交叉驗(yàn)證,以提高模型的魯棒性和泛化能力。
2.3.6 PTST(2020)
Probabilistic Time Series Transformer (PTST)是一種基于Transformer模型的時(shí)序預(yù)測(cè)算法,由Google Brain于2020年提出。該算法采用了概率圖模型來(lái)提高時(shí)序預(yù)測(cè)的準(zhǔn)確性和可靠性,能夠在不確定性較大的時(shí)序數(shù)據(jù)中取得更好的表現(xiàn)。
PTST模型主要由兩個(gè)部分組成:序列模型和概率模型。序列模型采用Transformer結(jié)構(gòu),能夠?qū)r(shí)間序列數(shù)據(jù)進(jìn)行編碼和解碼,并利用自注意力機(jī)制對(duì)序列中的重要信息進(jìn)行關(guān)注和提取。概率模型則引入了變分自編碼器(VAE)和卡爾曼濾波器(KF)來(lái)捕捉時(shí)序數(shù)據(jù)中的不確定性和噪聲。
具體地,PTST模型的序列模型使用Transformer Encoder-Decoder結(jié)構(gòu)來(lái)進(jìn)行時(shí)序預(yù)測(cè)。Encoder部分采用多層自注意力機(jī)制來(lái)提取輸入序列的特征,Decoder部分則通過(guò)自回歸方式逐步生成輸出序列。在此基礎(chǔ)上,概率模型引入了一個(gè)隨機(jī)變量,即時(shí)序數(shù)據(jù)的噪聲項(xiàng),它被建模為一個(gè)正態(tài)分布。同時(shí),為了減少潛在的誤差,概率模型還使用KF對(duì)序列進(jìn)行平滑處理。
在訓(xùn)練過(guò)程中,PTST采用了最大后驗(yàn)概率(MAP)估計(jì)方法,以最大化預(yù)測(cè)的概率。在預(yù)測(cè)階段,PTST利用蒙特卡洛采樣方法來(lái)從后驗(yàn)分布中抽樣,以生成一組概率分布。同時(shí),為了衡量預(yù)測(cè)的準(zhǔn)確性,PTST還引入了均方誤差和負(fù)對(duì)數(shù)似然(NLL)等損失函數(shù)。
2.3.7 Reformer(2020)
Paper:Reformer: The Efficient Transformer
Reformer是一種基于Transformer模型的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),它在時(shí)序預(yù)測(cè)任務(wù)中具有一定的應(yīng)用前景。可以使用Reformer模型進(jìn)行采樣、自回歸、多步預(yù)測(cè)和結(jié)合強(qiáng)化學(xué)習(xí)等方法來(lái)進(jìn)行時(shí)序預(yù)測(cè)。在這些方法中,通過(guò)將已知的歷史時(shí)間步送入模型,然后生成未來(lái)時(shí)間步的值。Reformer模型通過(guò)引入可分離的卷積和可逆層等技術(shù),使得模型更加高效、準(zhǔn)確和可擴(kuò)展。總之,Reformer模型為時(shí)序預(yù)測(cè)任務(wù)提供了一種全新的思路和方法。
2.3.8 Informer(2020)
Paper:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Code: https://github.com/zhouhaoyi/Informer2020
Informer是一種基于Transformer模型的時(shí)序預(yù)測(cè)方法,由北京大學(xué)深度學(xué)習(xí)與計(jì)算智能實(shí)驗(yàn)室于2020年提出。與傳統(tǒng)的Transformer模型不同,Informer在Transformer模型的基礎(chǔ)上引入了全新的結(jié)構(gòu)和機(jī)制,以更好地適應(yīng)時(shí)序預(yù)測(cè)任務(wù)。Informer方法的核心思想包括:
長(zhǎng)短時(shí)記憶(LSTM)編碼器-解碼器結(jié)構(gòu):Informer引入了LSTM編碼器-解碼器結(jié)構(gòu),可以在一定程度上緩解時(shí)間序列中的長(zhǎng)期依賴問(wèn)題。
自適應(yīng)長(zhǎng)度注意力(AL)機(jī)制:Informer提出了自適應(yīng)長(zhǎng)度注意力機(jī)制,可以在不同時(shí)間尺度上自適應(yīng)地捕捉序列中的重要信息。
多尺度卷積核(MSCK)機(jī)制:Informer使用多尺度卷積核機(jī)制,可以同時(shí)考慮不同時(shí)間尺度上的特征。
生成式對(duì)抗網(wǎng)絡(luò)(GAN)框架:Informer使用GAN框架,可以通過(guò)對(duì)抗學(xué)習(xí)的方式進(jìn)一步提高模型的預(yù)測(cè)精度。
在訓(xùn)練階段,Informer方法可以使用多種損失函數(shù)(如平均絕對(duì)誤差、平均平方誤差、L1-Loss等)來(lái)訓(xùn)練模型,并使用Adam優(yōu)化算法來(lái)更新模型參數(shù)。在預(yù)測(cè)階段,Informer方法可以使用滑動(dòng)窗口技術(shù)來(lái)預(yù)測(cè)未來(lái)時(shí)間點(diǎn)的值。
Informer方法在多個(gè)時(shí)序預(yù)測(cè)數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),并與其他流行的時(shí)序預(yù)測(cè)方法進(jìn)行了比較。實(shí)驗(yàn)結(jié)果表明,Informer方法在預(yù)測(cè)精度、訓(xùn)練速度和計(jì)算效率等方面都表現(xiàn)出了很好的性能。
2.3.9 TAT(2021)
TAT(Temporal Attention Transformer)是一種基于Transformer模型的時(shí)序預(yù)測(cè)算法,由北京大學(xué)智能科學(xué)實(shí)驗(yàn)室提出。TAT模型在傳統(tǒng)的Transformer模型基礎(chǔ)上增加了時(shí)間注意力機(jī)制,能夠更好地捕捉時(shí)間序列中的動(dòng)態(tài)變化。
TAT模型的基本結(jié)構(gòu)與Transformer類似,包括多個(gè)Encoder和Decoder層。每個(gè)Encoder層包括多頭自注意力機(jī)制和前饋網(wǎng)絡(luò),用于從輸入序列中提取特征。每個(gè)Decoder層則包括多頭自注意力機(jī)制、多頭注意力機(jī)制和前饋網(wǎng)絡(luò),用于逐步生成輸出序列。與傳統(tǒng)的Transformer模型不同的是,TAT模型在多頭注意力機(jī)制中引入了時(shí)間注意力機(jī)制,以捕捉時(shí)間序列中的動(dòng)態(tài)變化。具體地,TAT模型將時(shí)間步信息作為額外的特征輸入,然后利用多頭注意力機(jī)制對(duì)時(shí)間步進(jìn)行關(guān)注和提取,以輔助模型對(duì)序列中動(dòng)態(tài)變化的建模。此外,TAT模型還使用了增量式訓(xùn)練技術(shù),以提高模型的訓(xùn)練效率和預(yù)測(cè)性能。
2.3.10 NHT(2021)
Paper:Nested Hierarchical Transformer: Towards Accurate, Data-Efficient and Interpretable Visual Understanding
NHT(Nested Hierarchical Transformer)是一種用于時(shí)間序列預(yù)測(cè)的深度學(xué)習(xí)算法。它采用了一種嵌套的層次變換器結(jié)構(gòu),通過(guò)多層次嵌套的自注意力機(jī)制和時(shí)間重要性評(píng)估機(jī)制來(lái)實(shí)現(xiàn)對(duì)時(shí)間序列數(shù)據(jù)的精確預(yù)測(cè)。NHT模型通過(guò)引入更多的層次結(jié)構(gòu)來(lái)改進(jìn)傳統(tǒng)的自注意力機(jī)制,同時(shí)使用時(shí)間重要性評(píng)估機(jī)制來(lái)動(dòng)態(tài)地控制不同層次的重要性,以獲得更好的預(yù)測(cè)性能。該算法在多個(gè)時(shí)間序列預(yù)測(cè)任務(wù)中表現(xiàn)出了優(yōu)異的性能,證明了其在時(shí)序預(yù)測(cè)領(lǐng)域的潛力。
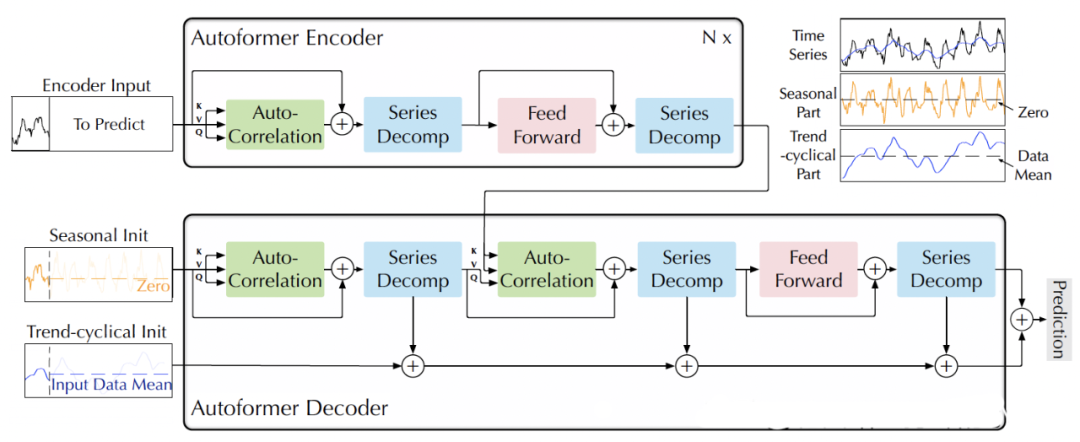
2.3.11 Autoformer(2021)
Paper:Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
Code:https://github.com/thuml/Autoformer
AutoFormer是一種基于Transformer結(jié)構(gòu)的時(shí)序預(yù)測(cè)模型。相比于傳統(tǒng)的RNN、LSTM等模型,AutoFormer具有以下特點(diǎn):
自注意力機(jī)制:AutoFormer采用自注意力機(jī)制,可以同時(shí)捕捉時(shí)間序列的全局和局部關(guān)系,避免了長(zhǎng)序列訓(xùn)練時(shí)的梯度消失問(wèn)題。
Transformer結(jié)構(gòu):AutoFormer使用了Transformer結(jié)構(gòu),可以實(shí)現(xiàn)并行計(jì)算,提高了訓(xùn)練效率。
多任務(wù)學(xué)習(xí):AutoFormer還支持多任務(wù)學(xué)習(xí),可以同時(shí)預(yù)測(cè)多個(gè)時(shí)間序列,提高了模型的效率和準(zhǔn)確性。
AutoFormer模型的具體結(jié)構(gòu)類似于Transformer,包括編碼器和解碼器兩部分。編碼器由多個(gè)自注意力層和前饋神經(jīng)網(wǎng)絡(luò)層組成,用于從輸入序列中提取特征。解碼器同樣由多個(gè)自注意力層和前饋神經(jīng)網(wǎng)絡(luò)層組成,用于將編碼器的輸出轉(zhuǎn)化為預(yù)測(cè)序列。此外,AutoFormer還引入了跨時(shí)間步的注意力機(jī)制,可以在編碼器和解碼器中自適應(yīng)地選擇時(shí)間步長(zhǎng)。總體而言,AutoFormer是一種高效、準(zhǔn)確的時(shí)序預(yù)測(cè)模型,適用于多種類型的時(shí)間序列預(yù)測(cè)任務(wù)。
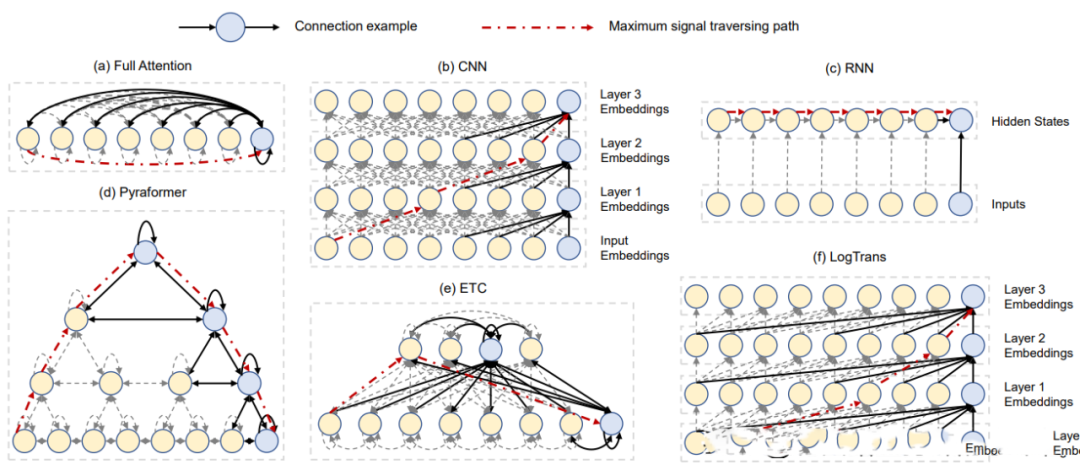
2.3.12 Pyraformer(2022)
Paper:Pyraformer: Low-complexity Pyramidal Attention for Long-range Time Series Modeling and Forecasting
Code: https://github.com/ant-research/Pyraformer
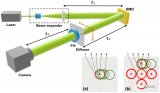
螞蟻研究院提出一種新的基于金字塔注意力的Transformer(Pyraformer),以彌補(bǔ)捕獲長(zhǎng)距離依賴和實(shí)現(xiàn)低時(shí)間和空間復(fù)雜性之間的差距。具體來(lái)說(shuō),通過(guò)在金字塔圖中傳遞基于注意力的信息來(lái)開(kāi)發(fā)金字塔注意力機(jī)制,如圖(d)所示。該圖中的邊可以分為兩組:尺度間連接和尺度內(nèi)連接。尺度間的連接構(gòu)建了原始序列的多分辨率表示:最細(xì)尺度上的節(jié)點(diǎn)對(duì)應(yīng)于原始時(shí)間序列中的時(shí)間點(diǎn)(例如,每小時(shí)觀測(cè)值),而較粗尺度下的節(jié)點(diǎn)代表分辨率較低的特征(例如,每日、每周和每月模式)。這種潛在的粗尺度節(jié)點(diǎn)最初是通過(guò)粗尺度構(gòu)造模塊引入的。另一方面,尺度內(nèi)邊緣通過(guò)將相鄰節(jié)點(diǎn)連接在一起來(lái)捕獲每個(gè)分辨率下的時(shí)間相關(guān)性。因此,該模型通過(guò)以較粗的分辨率捕獲此類行為,從而使信號(hào)穿越路徑的長(zhǎng)度更短,從而為遠(yuǎn)距離位置之間的長(zhǎng)期時(shí)間依賴性提供了一種簡(jiǎn)潔的表示。此外,通過(guò)稀疏的相鄰尺度內(nèi)連接,在不同尺度上對(duì)不同范圍的時(shí)間依賴性進(jìn)行建模,可以顯著降低計(jì)算成本。
?
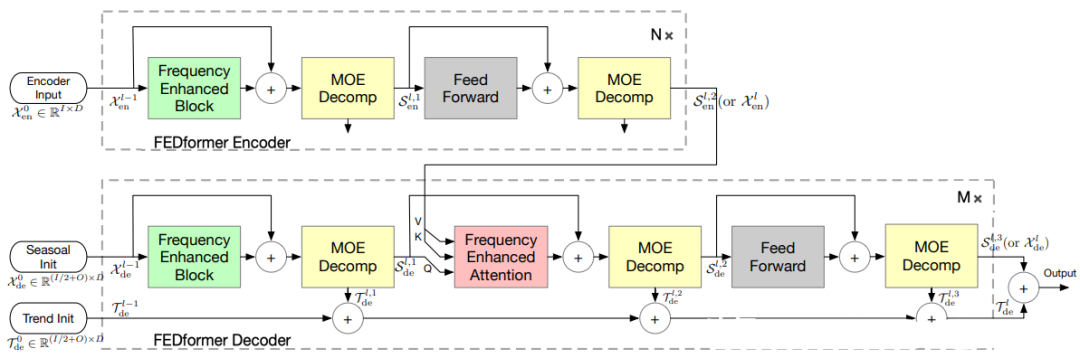
2.3.13 FEDformer(2022)
Paper:FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting
Code: https://github.com/MAZiqing/FEDformer
FEDformer是一種基于Transformer模型的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),專門(mén)用于分布式時(shí)序預(yù)測(cè)任務(wù)。該模型將時(shí)間序列數(shù)據(jù)分成多個(gè)小的分塊,并通過(guò)分布式計(jì)算來(lái)加速訓(xùn)練過(guò)程。FEDformer引入了局部注意力機(jī)制和可逆注意力機(jī)制,使得模型能夠更好地捕捉時(shí)序數(shù)據(jù)中的局部特征,并且具有更高的計(jì)算效率。此外,F(xiàn)EDformer還支持動(dòng)態(tài)分區(qū)、異步訓(xùn)練和自適應(yīng)分塊等功能,使得模型具有更好的靈活性和可擴(kuò)展性。
2.3.14 Crossformer(2023)
Paper:Crossformer: Transformer Utilizing Cross-Dimension Dependency for Multivariate Time Series Forecasting
Code: https://github.com/Thinklab-SJTU/Crossformer
Crossformer提出一個(gè)新的層次Encoder-Decoder的架構(gòu),如下所示,由左邊Encoder(灰色)和右邊Decoder(淺橘色)組成,包含Dimension-Segment-Wise (DSW) embedding,Two-Stage Attention (TSA)層和Linear Projection三部分。
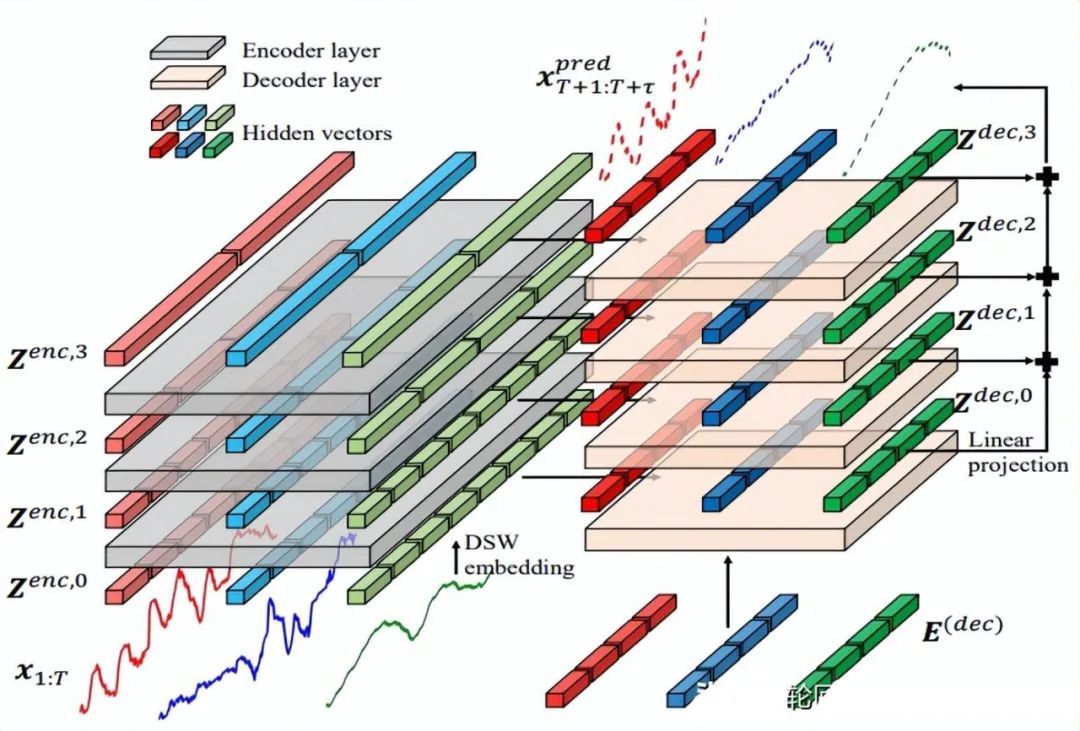
2.4 Mix類
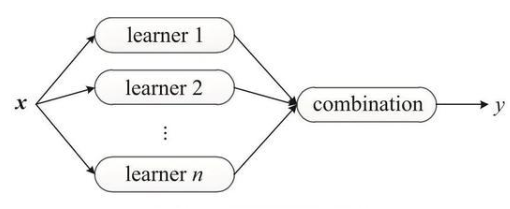
將ETS、自回歸、RNN、CNN和Attention等算法進(jìn)行融合,可以利用它們各自的優(yōu)點(diǎn),提高時(shí)序預(yù)測(cè)的準(zhǔn)確性和穩(wěn)定性。這種融合的方法通常被稱為“混合模型”。其中,RNN能夠自動(dòng)學(xué)習(xí)時(shí)間序列數(shù)據(jù)中的長(zhǎng)期依賴關(guān)系;CNN能夠自動(dòng)提取時(shí)間序列數(shù)據(jù)中的局部特征和空間特征;Attention機(jī)制能夠自適應(yīng)地關(guān)注時(shí)間序列數(shù)據(jù)中的重要部分。通過(guò)將這些算法進(jìn)行融合,可以使得時(shí)序預(yù)測(cè)模型更加魯棒和準(zhǔn)確。在實(shí)際應(yīng)用中,可以根據(jù)不同的時(shí)序預(yù)測(cè)場(chǎng)景,選擇合適的算法融合方式,并進(jìn)行模型的調(diào)試和優(yōu)化。
2.4.1 Encoder-Decoder CNN(2017)
Paper:Deep Learning for Precipitation Nowcasting: A Benchmark and A New Model
Encoder-Decoder CNN也是一種可以用于時(shí)序預(yù)測(cè)任務(wù)的模型,它是一種融合了編碼器和解碼器的卷積神經(jīng)網(wǎng)絡(luò)。在這個(gè)模型中,編碼器用于提取時(shí)間序列的特征,而解碼器則用于生成未來(lái)的時(shí)間序列。
具體而言,Encoder-Decoder CNN模型可以按照以下步驟進(jìn)行時(shí)序預(yù)測(cè):
輸入歷史時(shí)間序列數(shù)據(jù),通過(guò)卷積層提取時(shí)間序列的特征。
將卷積層輸出的特征序列送入編碼器,通過(guò)池化操作逐步降低特征維度,并保存編碼器的狀態(tài)向量。
將編碼器的狀態(tài)向量送入解碼器,通過(guò)反卷積和上采樣操作逐步生成未來(lái)的時(shí)間序列數(shù)據(jù)。
對(duì)解碼器的輸出進(jìn)行后處理,如去均值或標(biāo)準(zhǔn)化,以得到最終的預(yù)測(cè)結(jié)果。
需要注意的是,Encoder-Decoder CNN模型在訓(xùn)練過(guò)程中需要使用適當(dāng)?shù)膿p失函數(shù)(如均方誤差或交叉熵),并根據(jù)需要進(jìn)行超參數(shù)調(diào)整。此外,為了提高模型的泛化能力,還需要使用交叉驗(yàn)證等技術(shù)進(jìn)行模型評(píng)估和選擇。
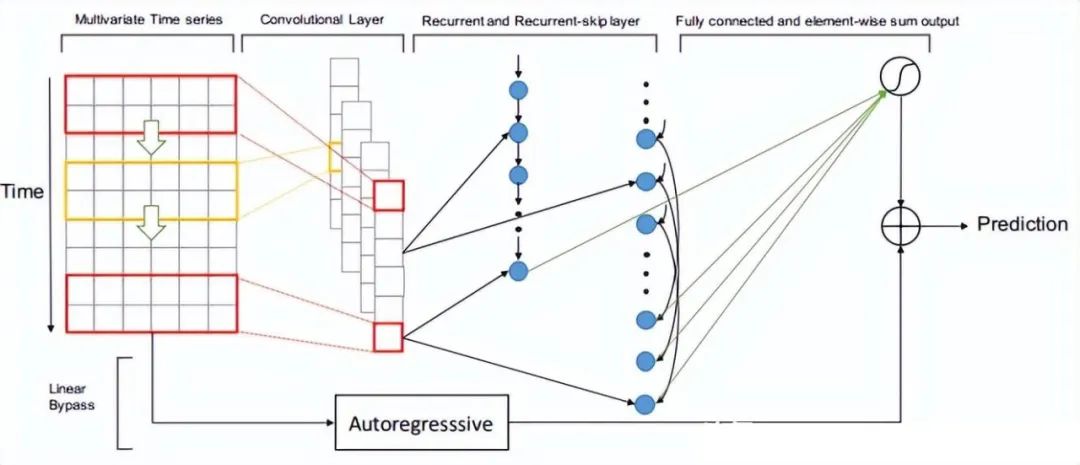
2.4.2 LSTNet(2018)
Paper:Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks
LSTNet是一種用于時(shí)間序列預(yù)測(cè)的深度學(xué)習(xí)模型,其全稱為L(zhǎng)ong- and Short-term Time-series Networks。LSTNet結(jié)合了長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)和一維卷積神經(jīng)網(wǎng)絡(luò)(1D-CNN),能夠有效地處理長(zhǎng)期和短期時(shí)間序列信息,同時(shí)還能夠捕捉序列中的季節(jié)性和周期性變化。LSTNet最初是由中國(guó)科學(xué)院計(jì)算技術(shù)研究所的Guokun Lai等人于2018年提出的。
LSTNet模型的核心思想是利用CNN對(duì)時(shí)間序列數(shù)據(jù)進(jìn)行特征提取,然后將提取的特征輸入到LSTM中進(jìn)行序列建模。LSTNet還包括一個(gè)自適應(yīng)權(quán)重學(xué)習(xí)機(jī)制,可以有效地平衡長(zhǎng)期和短期時(shí)間序列信息的重要性。LSTNet模型的輸入是一個(gè)形狀為(T, d)的時(shí)間序列矩陣,其中T表示時(shí)間步數(shù),d表示每個(gè)時(shí)間步的特征維數(shù)。LSTNet的輸出是一個(gè)長(zhǎng)度為H的預(yù)測(cè)向量,其中H表示預(yù)測(cè)的時(shí)間步數(shù)。在訓(xùn)練過(guò)程中,LSTNet采用均方誤差(MSE)作為損失函數(shù),并使用反向傳播算法進(jìn)行優(yōu)化。
2.4.3 TDAN(2018)
Paper:TDAN: Temporal Difference Attention Network for Precipitation Nowcasting
TDAN(Time-aware Deep Attentive Network)是一種用于時(shí)序預(yù)測(cè)的深度學(xué)習(xí)算法,它通過(guò)融合卷積神經(jīng)網(wǎng)絡(luò)和注意力機(jī)制來(lái)捕捉時(shí)間序列的時(shí)序特征。相比于傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò),TDAN能夠更加有效地利用時(shí)間序列數(shù)據(jù)中的時(shí)間信息,從而提高時(shí)序預(yù)測(cè)的準(zhǔn)確性。
具體而言,TDAN算法可以按照以下步驟進(jìn)行時(shí)序預(yù)測(cè):
輸入歷史時(shí)間序列數(shù)據(jù),通過(guò)卷積層提取時(shí)間序列的特征。
將卷積層輸出的特征序列送入注意力機(jī)制中,根據(jù)歷史數(shù)據(jù)中與當(dāng)前預(yù)測(cè)相關(guān)的權(quán)重,計(jì)算加權(quán)特征向量。
將加權(quán)特征向量送入全連接層,進(jìn)行最終的預(yù)測(cè)。
需要注意的是,TDAN算法在訓(xùn)練過(guò)程中需要使用適當(dāng)?shù)膿p失函數(shù)(如均方誤差),并根據(jù)需要進(jìn)行超參數(shù)調(diào)整。此外,為了提高模型的泛化能力,還需要使用交叉驗(yàn)證等技術(shù)進(jìn)行模型評(píng)估和選擇。
TDAN算法的優(yōu)點(diǎn)在于可以自適應(yīng)地關(guān)注歷史數(shù)據(jù)中與當(dāng)前預(yù)測(cè)相關(guān)的部分,從而提高時(shí)序預(yù)測(cè)的準(zhǔn)確性。同時(shí),它也可以有效地處理時(shí)間序列數(shù)據(jù)中的缺失值和異常值等問(wèn)題,具有一定的魯棒性。
2.4.4 DeepAR(2019)
Paper:DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
DeepAR 是一個(gè)自回歸循環(huán)神經(jīng)網(wǎng)絡(luò),使用遞歸神經(jīng)網(wǎng)絡(luò) (RNN) 結(jié)合自回歸 AR 來(lái)預(yù)測(cè)標(biāo)量(一維)時(shí)間序列。在很多應(yīng)用中,會(huì)有跨一組具有代表性單元的多個(gè)相似時(shí)間序列。DeepAR 會(huì)結(jié)合多個(gè)相似的時(shí)間序列,例如是不同方便面口味的銷量數(shù)據(jù),通過(guò)深度遞歸神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)不同時(shí)間序列內(nèi)部的關(guān)聯(lián)特性,使用多元或多重的目標(biāo)個(gè)數(shù)來(lái)提升整體的預(yù)測(cè)準(zhǔn)確度。DeepAR 最后產(chǎn)生一個(gè)可選時(shí)間跨度的多步預(yù)測(cè)結(jié)果,單時(shí)間節(jié)點(diǎn)的預(yù)測(cè)為概率預(yù)測(cè),默認(rèn)輸出P10,P50和P90三個(gè)值。這里的P10指的是概率分布,即10%的可能性會(huì)小于P10這個(gè)值。通過(guò)給出概率預(yù)測(cè),我們既可以綜合三個(gè)值給出一個(gè)值預(yù)測(cè),也可以使用P10 – P90的區(qū)間做出相應(yīng)的決策。
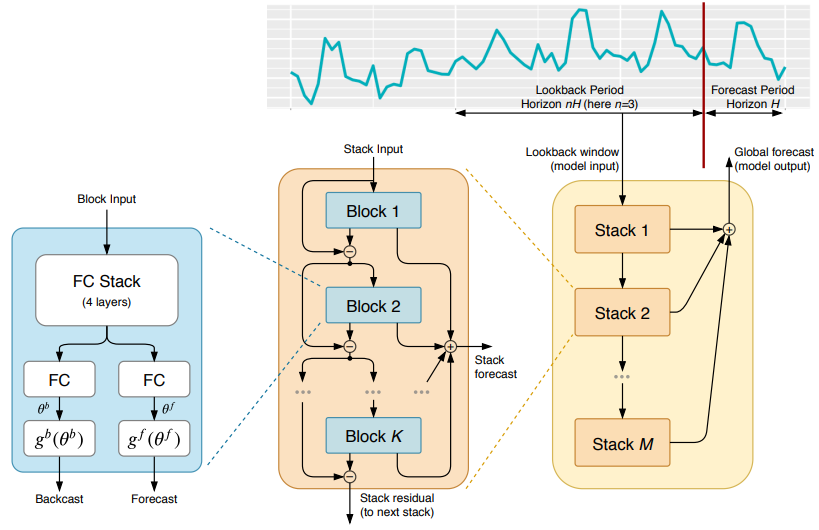
2.4.5 N-BEATS(2020)
Paper:N-BEATS: Neural basis expansion analysis for interpretable time series forecasting
Code: https://github.com/amitesh863/nbeats_forecast
N-BEATS(Neural basis expansion analysis for interpretable time series forecasting)是一種基于神經(jīng)網(wǎng)絡(luò)的時(shí)序預(yù)測(cè)模型,由Oriol Vinyals等人在Google Brain團(tuán)隊(duì)開(kāi)發(fā)。N-BEATS使用基于學(xué)習(xí)的基函數(shù)(learned basis function)對(duì)時(shí)間序列數(shù)據(jù)進(jìn)行表示,從而能夠在保持高精度的同時(shí)提高模型的可解釋性。N-BEATS模型還采用了堆疊的回歸模塊和逆卷積模塊,可以有效地處理多尺度時(shí)序數(shù)據(jù)和長(zhǎng)期依賴關(guān)系。
?
2.4.6 TCN-LSTM(2021)
Paper:A Comparative Study of Detecting Anomalies in Time Series Data Using LSTM and TCN Models
TCN-LSTM是一種融合了Temporal Convolutional Network(TCN)和Long Short-Term Memory(LSTM)的模型,可以用于時(shí)序預(yù)測(cè)任務(wù)。在這個(gè)模型中,TCN層和LSTM層相互協(xié)作,分別用于捕捉長(zhǎng)期和短期時(shí)間序列的特征。具體而言,TCN層可以通過(guò)堆疊多個(gè)卷積層來(lái)實(shí)現(xiàn),以擴(kuò)大感受野,同時(shí)通過(guò)殘差連接來(lái)防止梯度消失。而LSTM層則可以通過(guò)記憶單元和門(mén)控機(jī)制來(lái)捕捉時(shí)間序列的長(zhǎng)期依賴關(guān)系。
TCN-LSTM模型可以按照以下步驟進(jìn)行時(shí)序預(yù)測(cè):
輸入歷史時(shí)間序列數(shù)據(jù),通過(guò)TCN層提取時(shí)間序列的短期特征。
將TCN層輸出的特征序列送入LSTM層,捕捉時(shí)間序列的長(zhǎng)期依賴關(guān)系。
將LSTM層輸出的特征向量送入全連接層,進(jìn)行最終的預(yù)測(cè)。
需要注意的是,TCN-LSTM模型在訓(xùn)練過(guò)程中需要使用適當(dāng)?shù)膿p失函數(shù)(如均方誤差),并根據(jù)需要進(jìn)行超參數(shù)調(diào)整。此外,為了提高模型的泛化能力,還需要使用交叉驗(yàn)證等技術(shù)進(jìn)行模型評(píng)估和選擇。
2.4.7 NeuralProphet(2021)
Paper:Neural Forecasting at Scale
NeuralProphet是Facebook提供的基于神經(jīng)網(wǎng)絡(luò)的時(shí)間序列預(yù)測(cè)框架,它在Prophet框架的基礎(chǔ)上增加了一些神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),可以更準(zhǔn)確地預(yù)測(cè)具有復(fù)雜非線性趨勢(shì)和季節(jié)性的時(shí)間序列數(shù)據(jù)。
NeuralProphet的核心思想是利用深度神經(jīng)網(wǎng)絡(luò)來(lái)學(xué)習(xí)時(shí)間序列的非線性特征,并將Prophet的分解模型與神經(jīng)網(wǎng)絡(luò)結(jié)合起來(lái)。NeuralProphet提供了多種神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)和優(yōu)化算法,可以根據(jù)具體的應(yīng)用需求進(jìn)行選擇和調(diào)整。NeuralProphet的特點(diǎn)如下:
靈活性:NeuralProphet可以處理具有復(fù)雜趨勢(shì)和季節(jié)性的時(shí)間序列數(shù)據(jù),并且可以靈活地設(shè)置神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)和優(yōu)化算法。
準(zhǔn)確性:NeuralProphet可以利用神經(jīng)網(wǎng)絡(luò)的非線性建模能力,提高時(shí)間序列預(yù)測(cè)的準(zhǔn)確性。
可解釋性:NeuralProphet可以提供豐富的可視化工具,幫助用戶理解預(yù)測(cè)結(jié)果和影響因素。
易用性:NeuralProphet可以很容易地與Python等編程語(yǔ)言集成,并提供了豐富的API和示例,使用戶可以快速上手。
NeuralProphet在許多領(lǐng)域都有廣泛的應(yīng)用,例如金融、交通、電力等。它可以幫助用戶預(yù)測(cè)未來(lái)的趨勢(shì)和趨勢(shì)的變化,并提供有用的參考和決策支持。
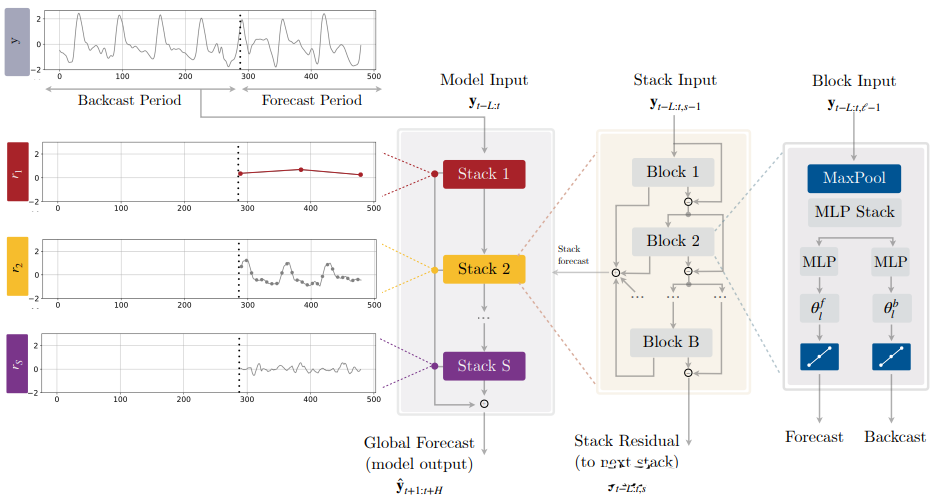
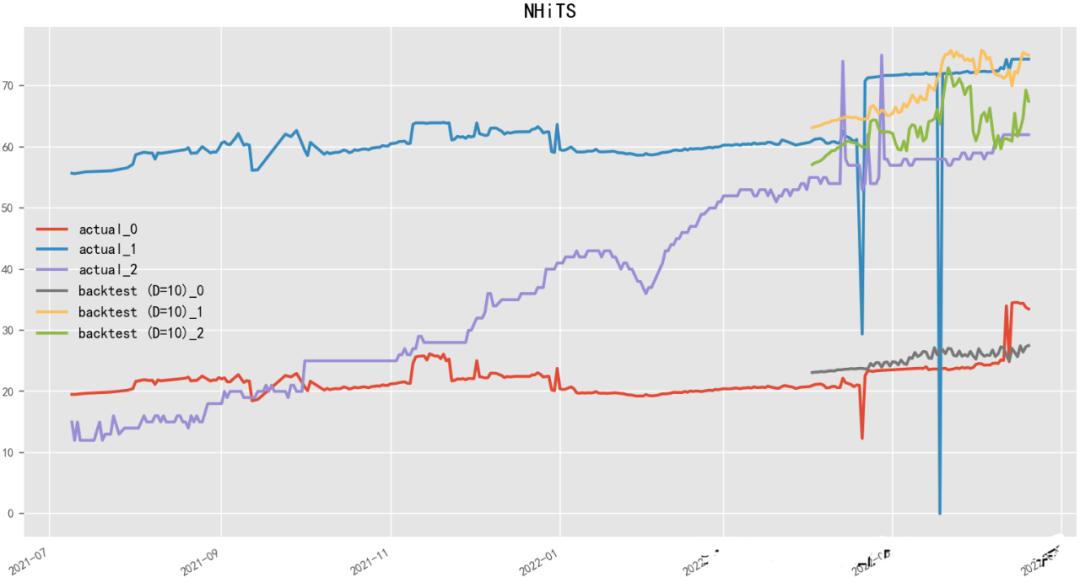
2.4.8 N-HiTS(2022)
Paper:N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting
N-HiTS(Neural network-based Hierarchical Time Series)是一種基于神經(jīng)網(wǎng)絡(luò)的層次時(shí)序預(yù)測(cè)模型,由Uber團(tuán)隊(duì)開(kāi)發(fā)。N-HiTS使用基于深度學(xué)習(xí)的方法來(lái)預(yù)測(cè)多層次時(shí)間序列數(shù)據(jù),如產(chǎn)品銷售、流量、股票價(jià)格等。該模型采用了分層結(jié)構(gòu),將整個(gè)時(shí)序數(shù)據(jù)分解為多個(gè)層次,每個(gè)層次包含不同的時(shí)間粒度和特征,然后使用神經(jīng)網(wǎng)絡(luò)模型進(jìn)行預(yù)測(cè)。N-HiTS還采用了一種自適應(yīng)的學(xué)習(xí)算法,可以動(dòng)態(tài)地調(diào)整預(yù)測(cè)模型的結(jié)構(gòu)和參數(shù),以最大程度地提高預(yù)測(cè)精度。
?
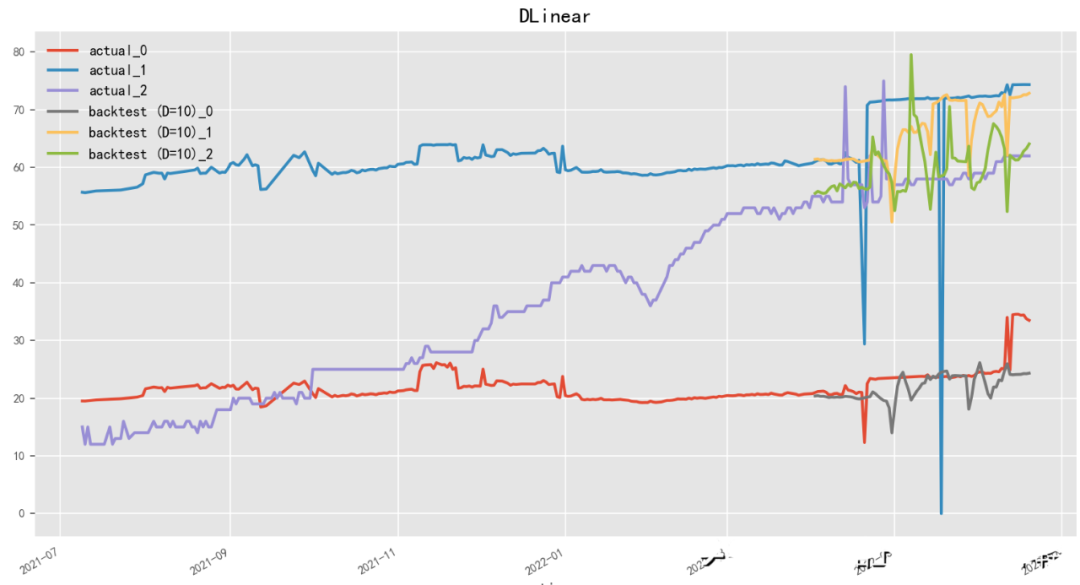
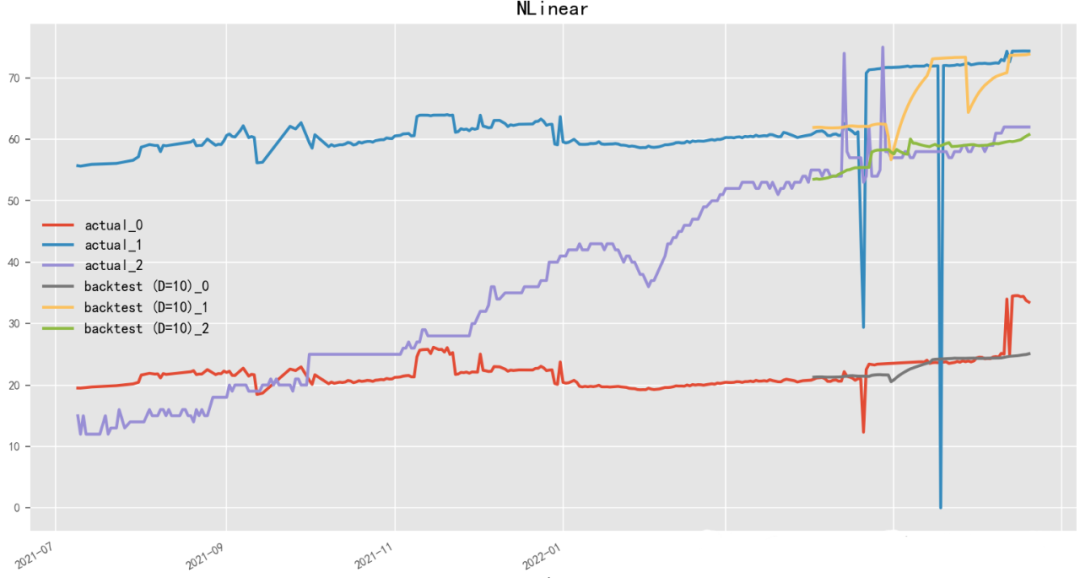
2.4.9 D-Linear(2022)
Paper:Are Transformers Effective for Time Series Forecasting?
Code: https://github.com/cure-lab/LTSF-Linear
D-Linear(Deep Linear Model)是一種基于神經(jīng)網(wǎng)絡(luò)的線性時(shí)序預(yù)測(cè)模型,由李宏毅團(tuán)隊(duì)開(kāi)發(fā)。D-Linear使用神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)來(lái)進(jìn)行時(shí)間序列數(shù)據(jù)的線性預(yù)測(cè),從而能夠在保持高預(yù)測(cè)精度的同時(shí)提高模型的可解釋性。該模型采用了多層感知器(Multilayer Perceptron)作為神經(jīng)網(wǎng)絡(luò)模型,并通過(guò)交替訓(xùn)練和微調(diào)來(lái)提高模型的性能。D-Linear還提供了一種基于稀疏編碼的特征選擇方法,能夠自動(dòng)選擇具有區(qū)分性和預(yù)測(cè)能力的特征。與之相近,N-Linear(Neural Linear Model)是一種基于神經(jīng)網(wǎng)絡(luò)的線性時(shí)序預(yù)測(cè)模型,由百度團(tuán)隊(duì)開(kāi)發(fā)。
?
編輯:黃飛
?

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論