 電子發燒友App
電子發燒友App


作者 |?FelixCoder
前言
由于 ChatGPT 和 GPT4 興起,如何讓人人都用上這種大模型,是目前 AI 領域最活躍的事情。當下開源的??LLM(Large language model)非常多,可謂是百模大戰。面對諸多開源本地模型,根據自己的需求,選擇適合自己的基座模型和參數量很重要。選擇完后需要對訓練數據進行預處理,往往這一步就難住很多同學,無從下手,更別說 training。
然后再對模型進行 finetuning 來更好滿足自己的下游任務。那么對于如果要訓練一個專家模型。預訓練也是必不可缺的工作。不管是預訓練還是??finetuning(微調),無論選用何種方案,都避免不了訓練中產生的災難性遺忘問題,那么怎么減少和避免這種情況的發生,也是本文想講的一個重點。對于推理,在 GPU 資源不富裕的情況,如何最小化的利用內存,提升推理效率,也是可以討論的內容。
模型選擇
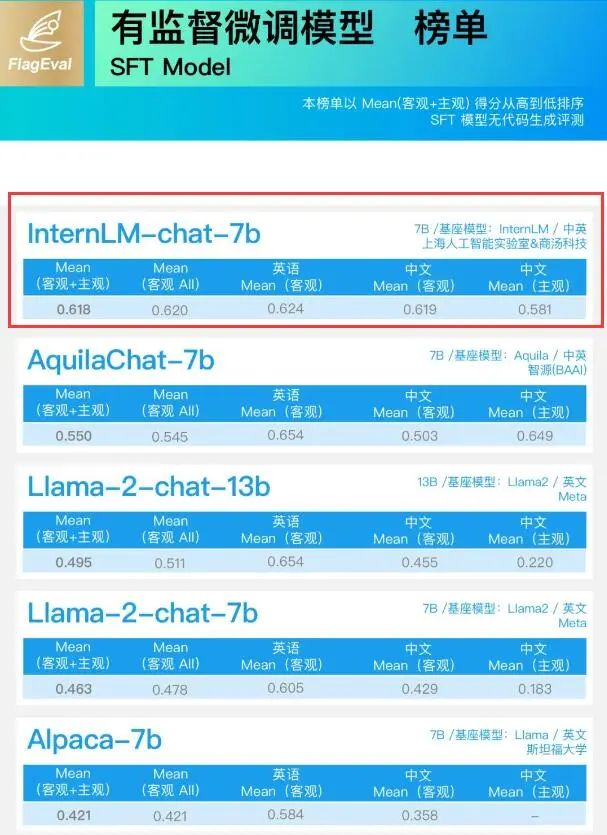
先看一下最好的模型有哪些,以下數據是最新 LLM 排行,來自?UC 伯克利?[1]
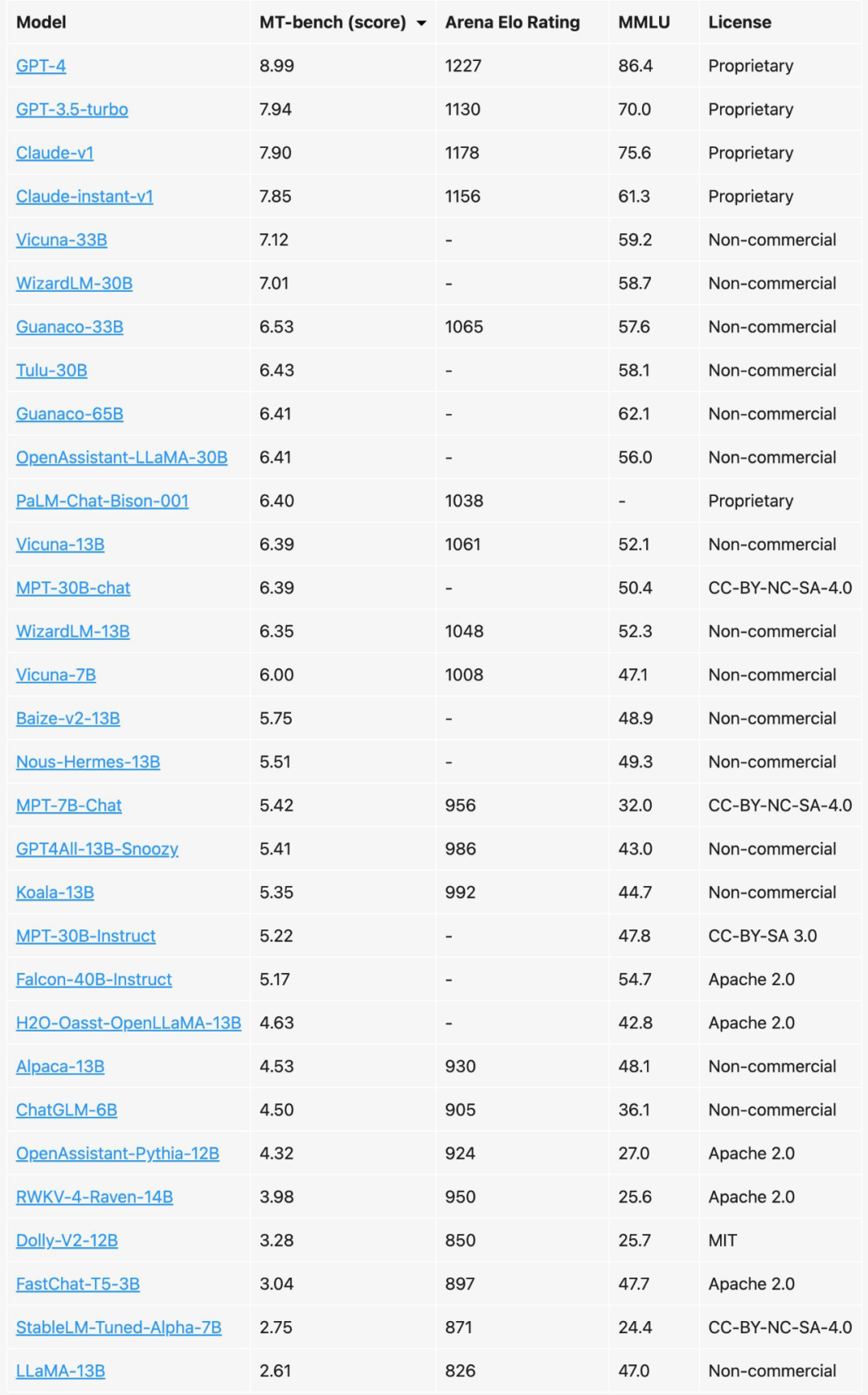
▲ FireShot Capture 015 - Chatbot Arena Leaderboard Week 8_ Introducing MT-Bench and Vicuna-33B_ - lmsys.org.png
當然這里前 3 名都閉源模型,后面開源模型,大多數也都是英文的模型。如果 GPU 資源充足(至少 A100*8),這里也可以基于開源模型做中文的預訓練,最后再 finetuning 。但我們沒有 GPU 資源, 我們可以選擇開源的中文模型直接做微調。?
具體有哪些中文模型可以選擇,可以參考這兩個地址?中文語言理解測評基準(CLUE)[2] 和?SuperCLUE 瑯琊榜?[3]。開源領域 ChatGLM,LLAMA,RWKV 主要就是這 3 種模型, 中文好一點就是 ChatGLM,潛力最好的就是 LLAMA,RNN 架構決定 RWKV 有很好的推理效率(隨輸入長度內存占比線性自增,而 LLAMA 則是指數增加) 和? Length Extrapolation?(關于長度外推性,可以參考蘇神的文章?[4])。
當然?MPT-7B-StoryWriter-65k+?[5] 模型也有較長的外推能力,主要在于,注意力這塊使用了?ALIBI?[6]。要擁有什么樣的長度,取決你的需求。對于對話模型,往往不需要那么長的外推能力。但對于想做知識庫領域相關的應用, 需要模型能夠看更多的內容,是有這個需求的。
這里不做推薦,一切來自你的具體需求和 GPU 資源,不知道怎么樣選擇,可以將您的需求和資源情況留言,我給你做一個選擇。
模型大小選擇
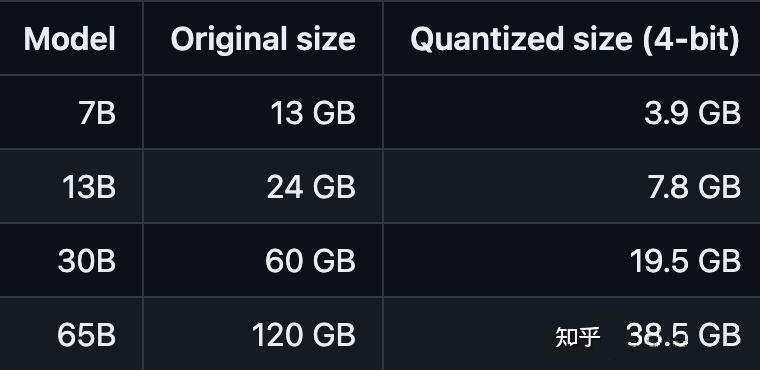
當然對于模型參數的選擇,往往是參數越大效果越好。如果資源充足,當然是推薦 30B 以上的模型。不管是 6B, 7B 和 13B 同樣的訓練數據,同樣訓練參數,模型參數量大效果則優于低參數的模型。那么根據模型參數,如何預估我們的訓練所需的內存開銷,這里有一個簡單的方法 比如 6B 模型,60 億規模參數,根據以下公式計算:?
模型參數 + 梯度參數 + 優化器參數 = 6B * 1bytes + 6GB + 2*6GB = 24GB?
以上是全量預訓練,當然如果采用 lora 這種方法,則會有更低內存占用。當然我們還可以對模型進行量化,來提高內存效率。?
注意:參數多量化低的模型要優于參數低量化高的模型,舉例 :33B-fb4 模型要優于 13b-fb16 模型.
數據處理
對于 LLM 訓練,數據質量很重要。預訓練時,我們可以將數據先進行預處理,比如對數據進行一定規則的篩選,數據去重,去除一些低質量的數據。同時,我們可能面臨各種類型的數據,PDF,Word,HTML,代碼文件等等,對于這種不同類型的數據我們需要都處理成文本,同時還過濾掉一些干擾項或亂碼的數據。
當然,我們也可以利用一些工具去處理,比如 justext?[7],trafilatura?[8],來提取文檔主要內容,減少數據的噪音。對于空的文檔或文檔長度低于 100 進行過濾,進一步減少噪音。
對于一些機器生成的文本或 OCR?識別錯誤的文本,質量不高,由沒有什么邏輯性,雖然比較難以檢測,但是還是會有一些工具能做這樣的事情,比如?ctrl-detector?[9]。當然對于一些有毒的或帶有偏見的數據,可以采用?PerspectiveAPI?[10] 或垃圾郵件檢測的辦法來過濾。
我們還不得不考慮數據的一些隱私風險,也需要考慮,比如身份證號,銀行卡等信息,比如 presidio 和 pii-codex 等工具提供了檢測、分析和處理文本數據中的個人身份信息的能力。
指令微調數據,我們可以使用?PromptSource?[11] 來創建微調數據。當然我們還可以讓 GPT4 給我們標注一些數據,這樣蒸餾知識,可以讓數據質量進一步提升。這里我分享一個我使用的 Prompt 工程:
first_prompt?=?""" 作為一位專業的xxxx,您的任務是從給定的上下文回答問題。 給定的上下文: """ last_prompt?=?""" 請綜合上述信息,你給出的回復需要包含以下三個字段: 1.questions:?基于上下文內容,提出與這個內容相關的問題,至少兩個以上。 2.answers:?然后根據問題,分別給出每個問題的答案,請用 markdown 格式。 3.instruction:?給出上下文內容的總結,盡量精簡,用 markdown 格式。 請按照以下JSON格式來回答: 前括號 ??????"questions":?[ ??????????"<內容相關問題1>", ??????????"<內容相關問題2>" ??????], ??????"answers":?[ ???????????"<內容相關問題1的答案>", ???????????"<內容相關問題2的答案>" ??????], ??????instruction:?"<總結性的內容>" 后括號 注意:如果碰到上下文內容信息不夠,無法回答問題的情況,answers和questions可以返回空。 最后強調一下:你的回復將直接用于javascript的JSON.parse解析,所以注意一定要以標準的JSON格式做回答,不要包含任何其他非JSON內容,否則你將被扣分!!! """
微調方案
目前對于 LLM 微調方案有很多,我將常用的一些方案和相關資料做一個列舉。?
Prefix-Tuning(P-Tuning v2)[12]
Prompt Tuning?[13]
Lora?/?QLora [14]
根據實際經驗,這里推薦采用 Lora 或 QLora。簡單介紹一下 QLoRA,重點改進是將模型采用 4bit 量化后加載,訓練時把數值反量化到 bf16 后進行訓練,利用 LoRA 可以鎖定原模型參數不參與訓練,只訓練少量 LoRA 參數的特性使得訓練所需的顯存大大減少。例如 33B 的 LLaMA 模型經過這種方式可以在 24GB 的顯卡上訓練,也就是說消費級單卡都可以實現,大大降低了微調的門檻。
英文模型需要做詞表擴充嗎?
對于像 LLaMA 模型的詞表大小是 32K,其主要針對英語進行訓練(具體詳見?LLaMA 論文 [15]),對多語種支持不是特別理想(可以對比一下多語言經典模型 XLM-R 的詞表大小為 250K)。
通過初步統計發現,LLaMA 詞表中僅包含很少的中文字符,所以在切詞時會把中文切地更碎,需要多個 byte token 才能拼成一個完整的漢字,進而導致信息密度降低。比如,在擴展詞表后的模型中,單個漢字傾向于被切成 1 個 token,而在 LLaMA 中可能就需要 2-3 個才能組合成一個漢字,顯著降低模型的推理效率。
如何避免災難遺忘
通常我們有以下方式,可以減少或避免災難性遺忘問題
將重要的權重凍結 - 像 Lora 就是采用的這種方案,只學習部分網絡權重。但這里 Lora 的配置其實是要注意一下,如果你是用 Lora 做預訓練,lora 訓練模塊可以配上 q_proj,v_proj,k_proj,o_proj??如果是微調則只需要訓練? q_proj,v_proj? lora_rank 的設置也有講究,初始設 lora_ran 為 8,訓練存在遺忘時,可以將 lora_rank 改為 64(原因是與原模型數據領域相差較大的話,需要更大的秩,原論文有說明)。
復習 - 跟人一樣,在預訓練或微調時,回看之前訓練的數據。還可以專門把特征圖存起來,量化以后放在一個類似于記憶庫的地方,之后在新任務上訓練的時候從這個記憶庫里重構出記憶和新數據一起訓練。感興趣可以看這篇論文?[16]。?
MoE - 稀疏門控制的專家混合層,最近爆出 GPT4 是由 8 個 220B 的模型組合。關于?Moe 相關資料?[17]?大家自行了解。?
推理加速
對于推理,一般我們采用量化方案,這里有兩個辦法。第一個則是采用 ggml 工具,比如?llama.cpp?[18] 針對 llama 模型,將模型量化運行在 cpu 或 gpu 上,也可以 cpu 和 gpu 一起跑,內存則大大減少,推理速度有極大的提高。?
▲ image.png
這里如果將 llama.cpp 運行在 gpu 上, 編譯時一定要加?LLAMA_CUBLAS=1,同時推理的時候,指定? --gpu-layers|-ngl? 來分配運行在 gpu 上的層數,當然越大,占用 gpu 的內存會越多。
如果是 RWKV 模型,則考慮采用?rwkv.cpp?[19],此方法與?llama.cpp?類似,使用方式也是類似的。
還有 Llama 模型還可以考慮使用?exllama?[20] 純 GPU 的加速,雖然還不夠完善,但也可以值得一試。
另一個,采用?LLM Accelerator?[21],LLM 存在大量的相似性推理,基于此,可以做一些優化加速推理,具體請看論文。最后采用架構上的調整,faster transformer?[22] 要優于傳統的 transformer 架構。
總結
最后總結幾條原則:?
參數多量化低的模型要優于參數低量化高的模型?
模型質量與訓練數據質量是存在相關性的?
擴充中文詞表有助于提高推理效率?
微調推薦采用 Lora QLora 方案?
模型加速必然需要對模型進行量化
編輯:黃飛
?















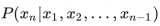








 工商網監
工商網監
評論