電子發燒友網報道(文/周凱揚)人工智能在進化的過程中,最不可或缺的便是模型和算力。訓練出來的通用大模型省去了重復的開發工作,目前不少大模型都為學術研究和AI開發提供了方便,比如華為的盤古、搜狗
2021-12-18 06:51:00 2840
2840 電子發燒友網報道(文/李彎彎)在深度學習中,經常聽到一個詞“模型訓練”,但是模型是什么?又是怎么訓練的?在人工智能中,面對大量的數據,要在雜亂無章的內容中,準確、容易地識別,輸出需要的圖像/語音
2022-10-23 00:19:0024539 訓練和微調大型語言模型對于硬件資源的要求非常高。目前,主流的大模型訓練硬件通常采用英特爾的CPU和英偉達的GPU。然而,最近蘋果的M2 Ultra芯片和AMD的顯卡進展給我們帶來了一些新的希望。
2023-07-28 16:11:012174 
為克服智能化設計難題、搶占智能醫療市場先機,ADI公司亞太區醫療行業市場經理王勝為大家分享了ADI的應對之策?ADI公司從技術層面而言,憑借其傳感器技術,模擬及混合信號處理技術,無線傳輸以及數據處理技術一直致力于提供具有差異化及競爭優勢的產品以應對智能化設計難題。
2013-05-23 10:11:321233 隨著預訓練語言模型(PLMs)的不斷發展,各種NLP任務設置上都取得了不俗的性能。盡管PLMs可以從大量語料庫中學習一定的知識,但仍舊存在很多問題,如知識量有限、受訓練數據長尾分布影響魯棒性不好
2022-04-02 17:21:438837 NLP領域的研究目前由像RoBERTa等經過數十億個字符的語料經過預訓練的模型匯主導。那么對于一個預訓練模型,對于不同量級下的預訓練數據能夠提取到的知識和能力有何不同?
2023-03-03 11:21:511354 為什么?一般有 tensor parallelism、pipeline parallelism、data parallelism 幾種并行方式,分別在模型的層內、模型的層間、訓練數據三個維度上對 GPU 進行劃分。三個并行度乘起來,就是這個訓練任務總的 GPU 數量。
2023-09-15 11:16:2113132 
,近些年國內也有不少GPU企業在逐步成長,雖然在大模型的訓練和推理方面,與英偉達GPU差距極大,但是不可忽視的是,不少國產GPU企業也在AI的訓練和推理應用上找到位置。 ? ? 景嘉微 ? 景嘉微是國產GPU市場的主要參與者,目前已經完成JM5、JM7和J
2024-03-29 00:27:002677 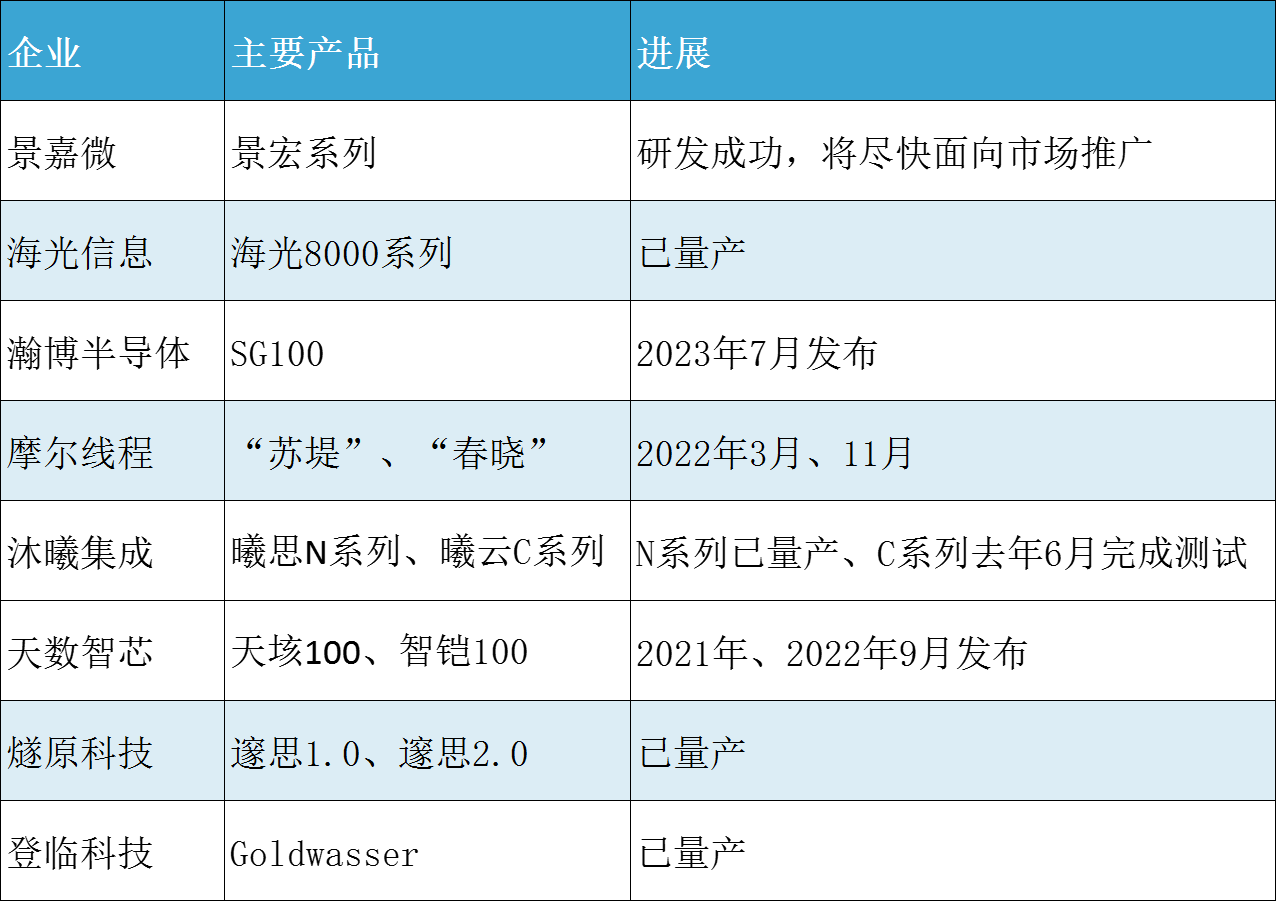
不斷推出新品,產品也逐漸在各個領域取得應用,而且在大模型的訓練和推理方面,也有所建樹。 ? 國產GPU在大模型上的應用進展 ? 電子發燒友此前就統計過目前國內主要的GPU廠商,也介紹了這些廠商主要的產品及產品發布、量產進展情況。可以看到
2024-04-01 09:28:261902 
,國產GPU在不斷成長的過程中也存在諸多挑戰。 ? 在大模型訓練上存在差距 ? 大語言模型是基于深度學習的技術。這些模型通過在海量文本數據上的訓練,學習語言的語法、語境和語義等多層次的信息,用于理解和生成自然語言文本。大語言模型是
2024-04-03 01:08:001550
在 CPU 和 GPU 上推斷出具有 OpenVINO? 基準的相同模型:
benchmark_app.exe -m model.xml -d CPU
benchmark_app.exe -m
2023-08-15 06:43:46
GPU編程--OpenCL四大模型
2019-04-29 07:40:44
GPU虛擬化在哪里發生?它是否出現在GRID卡中,然后將vGPU呈現給管理程序然后呈現給客戶?或者,GPU的虛擬化和調度是否真的發生在管理程序上安裝的GRID管理器軟件?是否使用了SR-IOV?我
2018-09-28 16:45:15
萬物互聯時代,智慧農業發展難題如何解決?農業是人類的生存之本,是經濟穩定快速發展的重要基礎。一直以來人類在農業上的探索就沒有停止過,農業也從過去的人力為主,變成了現在的機械為主,人類賦予了農業智慧
2018-01-31 11:09:11
訓練好的ai模型導入cubemx不成功咋辦,試了好幾個模型壓縮了也不行,ram占用過大,有無解決方案?
2023-08-04 09:16:28
上漲,因為事實表明,它們的 GPU 在訓練和運行 深度學習模型 方面效果明顯。實際上,英偉達也已經對自己的業務進行了轉型,之前它是一家純粹做 GPU 和游戲的公司,現在除了作為一家云 GPU 服務
2024-03-21 15:19:45
),其中y取值1或-1(代表二分類的類別標簽),這也是GBDT可以用來解決分類問題的原因。模型訓練代碼地址 https://github.com/qianshuang/ml-expdef train
2019-01-23 14:38:58
Mali GPU 支持tensorflow或者caffe等深度學習模型嗎? 好像caffe2go和tensorflow lit可以部署到ARM,但不知道是否支持在GPU運行?我希望把訓練
2022-09-16 14:13:01
問題最近在Ubuntu上使用Nvidia GPU訓練模型的時候,如果機器鎖屏一段時間再打開的時候鼠標非常卡頓,或者說顯示界面非常卡頓,使用nvidia-smi查看發現,訓練模型的GPU沒有問題,但是
2021-12-30 06:44:30
本教程以實際應用、工程開發為目的,著重介紹模型訓練過程中遇到的實際問題和方法。在機器學習模型開發中,主要涉及三大部分,分別是數據、模型和損失函數及優化器。本文也按順序的依次介紹數據、模型和損失函數
2018-12-21 09:18:02
能否直接調用訓練好的模型文件?
2021-06-22 14:51:03
本帖最后由 wcl86 于 2021-9-9 10:39 編輯
`labview調用深度學習tensorflow模型非常簡單,效果如下,附上源碼和訓練過的模型:[hide][/hide
2021-06-03 16:38:25
模型收斂的情況下,最大集群規模只支持10塊GPU。這意味著在進行數據運算時,即時使用更多的GPU,計算效果也只相當于10塊GPU的能力,這樣訓練的時間將更加的漫長。 而華為云的深度學習
2018-08-02 20:44:09
準備開始為家貓做模型訓練檢測,要去官網https://maix.sipeed.com/home 注冊帳號,文章尾部的視頻是官方的,與目前網站略有出路,說明訓練網站的功能更新得很快。其實整個的過程
2022-06-26 21:19:40
` EasyDL網站可以免費生成針對EdgeBoard板卡FZ5的離線訓練模型SDK,該SDK可以完美與FZ5硬件契合,最重要的是——free(免費)。下面就是針對FZ5生成模型SDK的實例——圖片
2021-03-23 14:32:35
一定的了解,在這篇文章中我們無法一一介紹。盡管transformer模型可以產生非常好的結果,被用于越來越多的長序列,例如11k大小的文本,許多這樣的大型模型只能在大型工業計算平臺上訓練,在單個GPU
2022-11-02 15:19:41
醫療模型人訓練系統是為滿足廣大醫學生的需要而設計的。我國現代醫療模擬技術的發展處于剛剛起步階段,大部分仿真系統產品都源于國外,雖然對于模擬人仿真已經出現一些產品,但那些產品只是就模擬人的某一部分,某一個功能實現的仿真,沒有一個完整的系統綜合其所有功能。
2019-08-19 08:32:45
問題最近在Ubuntu上使用Nvidia GPU訓練模型的時候,沒有問題,過一會再訓練出現非常卡頓,使用nvidia-smi查看發現,顯示GPU的風扇和電源報錯:解決方案自動風扇控制在nvidia
2022-01-03 08:24:09
CV:基于Keras利用訓練好的hdf5模型進行目標檢測實現輸出模型中的臉部表情或性別的gradcam(可視化)
2018-12-27 16:48:28
/16bit 運算,運算性能高達 3.0TOPS。相較于 GPU 作為 AI 運算單元的大型芯片方案,功耗不到 GPU 所需要的 1%。可直接加載 Caffe / Mxnet / TensorFlow 模型
2022-05-31 11:10:20
大數據與萬物互聯重新定義未來
2021-02-23 06:20:34
我正在嘗試使用 eIQ 門戶訓練人臉檢測模型。我正在嘗試從 tensorflow 數據集 (tfds) 導入數據集,特別是 coco/2017 數據集。但是,我只想導入 wider_face。但是,當我嘗試這樣做時,會出現導入程序錯誤,如下圖所示。任何幫助都可以。
2023-04-06 08:45:14
現有的圖數據規模極大,導致時序圖神經網絡的訓練需要格外長的時間,因此使用多GPU進行訓練變得成為尤為重要,如何有效地將多GPU用于時序圖神經網絡訓練成為一個非常重要的研究議題。本文提供了兩種方式來
2022-09-28 10:37:20
導出格式進行推理,包括自定義訓練模型。有關導出模型的詳細信息,請參閱TFLite、ONNX、CoreML、TensorRT 導出教程。專業提示:在GPU 基準測試中, TensorRT可能比
2022-07-22 16:02:42
如何使用寬頻率范圍矢量網絡分析儀去應對高速互聯測試的挑戰?
2021-04-30 07:25:40
(1 GPU)和時間(24小時)資源下從頭開始訓練ViT模型。首先,提出了一種向ViT架構添加局部性的有效方法。其次,開發了一種新的圖像大小課程學習策略,該策略允許在訓練開始時減少從每個圖像中提
2022-11-24 14:56:31
智能家居解決各平臺互聯互通仍是一個難題
2021-05-21 07:09:14
深度融合模型的特點,背景深度學習模型在訓練完成之后,部署并應用在生產環境的這一步至關重要,畢竟訓練出來的模型不能只接受一些公開數據集和榜單的檢驗,還需要在真正的業務場景下創造價值,不能只是為了PR而
2021-07-16 06:08:20
嵌入式設備自帶專用屬性,不適合作為隨機性很強的人工智能深度學習訓練平臺。想象用S3C2440訓練神經網絡算法都會頭皮發麻,PC上的I7、GPU上都很吃力,大部分都要依靠服務器來訓練。但是一旦算法訓練
2021-08-17 08:51:57
),其中y取值1或-1(代表二分類的類別標簽),這也是GBDT可以用來解決分類問題的原因。模型訓練代碼地址 https://github.com/qianshuang/ml-expdef train
2019-01-25 15:02:15
英偉達不斷推出GPU卡,并且實現多卡互聯NVLink,實際整個系統會累積到一個較大的公差,而目前市面上已有的連接器只能吸收較少的公差,這個是怎么做到匹配的呢?
2022-03-05 16:17:06
目前官方的線上模型訓練只支持K210,請問K510什么時候可以支持
2023-09-13 06:12:13
Mali T604 GPU的結構是由哪些部分組成的?Mali T604 GPU的編程特性有哪些?Mali GPU的并行化計算模型是怎樣構建的?基于Mali-T604 GPU的快速浮點矩陣乘法并行化該如何去實現?
2021-04-19 08:06:26
:【tensorflow篇】訓練:intelcpu或gpu:N卡1060,20系列可用,30系列顯卡不可用調用:intelcpu【yolov4篇】訓練:gpu:N卡1060,20系列可用,30系列顯卡不可用(后續課程
2021-09-03 09:39:28
在為這樣的大規模應用部署GPU加速時,出現了一個主要的技術挑戰:訓練數據太大而無法存儲在GPU上可用的存儲器中。因此,在訓練期間,需要有選擇地處理數據并反復移入和移出GPU內存。為了解釋應用程序的運行時間,研究人員分析了在GPU內核中花費的時間與在GPU上復制數據所花費的時間。
2018-03-26 10:29:154301 針對深度神經網絡在分布式多機多GPU上的加速訓練問題,提出一種基于虛擬化的遠程多GPU調用的實現方法。利用遠程GPU調用部署的分布式GPU集群改進傳統一對一的虛擬化技術,同時改變深度神經網絡在分布式
2018-03-29 16:45:25 0
0 帶寬模型最大的限制就是這些計算是針對特定矩陣大小的,計算的難度在各種尺寸之間都不同。例如,如果你的batch size是128,那么GPU的速度會比TPU稍快一點。如果batch size小于128
2018-10-21 09:20:344007 云TPU包含8個TPU核,每個核都作為獨立的處理單元運作。如果沒有用上全部8個核心,那就沒有充分利用TPU。為了充分加速訓練,相比在單GPU上訓練的同樣的模型,我們可以選擇較大的batch尺寸。總batch尺寸定為1024(每個核心128)一般是一個不錯的起點。
2018-11-16 09:10:0310102 深度學習模型和數據集的規模增長速度已經讓 GPU 算力也開始捉襟見肘,如果你的 GPU 連一個樣本都容不下,你要如何訓練大批量模型?通過本文介紹的方法,我們可以在訓練批量甚至單個訓練樣本大于 GPU
2018-12-03 17:24:01677 幾乎任何類型的密集并行計算難題都可以用GPU去解決。從這個層面來看,GPU是這類應用的最佳選擇。
2019-03-04 15:01:242115 正如我們在本文中所述,ULMFiT使用新穎的NLP技術取得了令人矚目的成果。該方法對預訓練語言模型進行微調,將其在WikiText-103數據集(維基百科的長期依賴語言建模數據集Wikitext之一)上訓練,從而得到新數據集,通過這種方式使其不會忘記之前學過的內容。
2019-04-04 11:26:2623213 
YOLACT——Real-time Instance Segmentation提出了一種簡潔的實時實例分割全卷積模型,速度明顯優于以往已有的算法,而且就是在一個 GPU 上訓練取得的!
2019-06-11 10:34:576981 本文把對抗訓練用到了預訓練和微調兩個階段,對抗訓練的方法是針對embedding space,通過最大化對抗損失、最小化模型損失的方式進行對抗,在下游任務上取得了一致的效果提升。 有趣的是,這種對抗
2020-11-02 15:26:491821 
讓我們面對現實吧,你的模型可能還停留在石器時代。我敢打賭你仍然使用32位精度或GASP甚至只在一個GPU上訓練。 我明白,網上都是各種神經網絡加速指南,但是一個checklist都沒有(現在
2020-11-27 10:43:521509 導讀:預訓練模型在NLP大放異彩,并開啟了預訓練-微調的NLP范式時代。由于工業領域相關業務的復雜性,以及工業應用對推理性能的要求,大規模預訓練模型往往不能簡單直接地被應用于NLP業務中。本文將為
2020-12-31 10:17:112229 
。這些大模型的出現讓普通研究者越發絕望:沒有「鈔能力」、沒有一大堆 GPU 就做不了 AI 研究了嗎? 在此背景下,部分研究者開始思考:如何讓這些大模型的訓練變得更加接地氣?也就是說,怎么用更少的卡訓練更大的模型? 為了解決這個問題,來自微軟、加州大學默塞德分校的研究
2021-02-11 09:04:002187 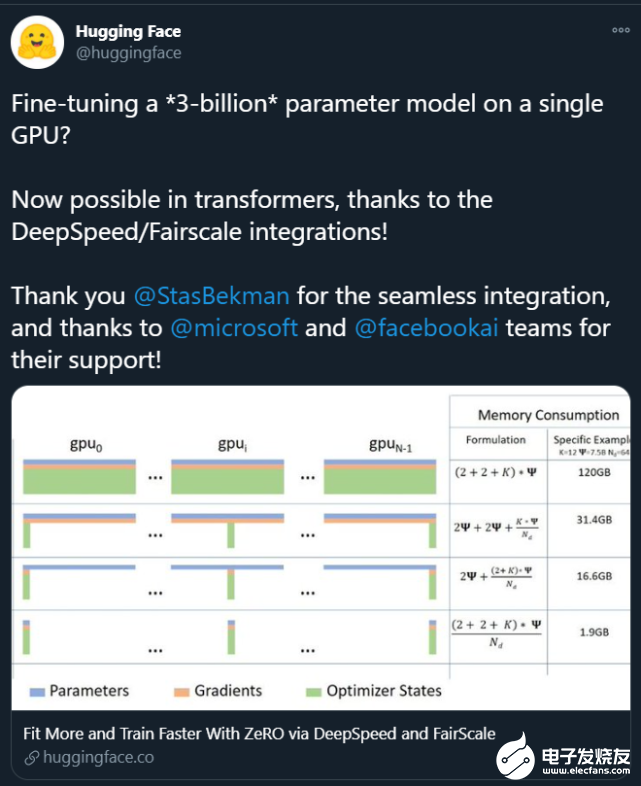
作為模型的初始化詞向量。但是,隨機詞向量存在不具備語乂和語法信息的缺點;預訓練詞向量存在¨一詞-乂”的缺點,無法為模型提供具備上下文依賴的詞向量。針對該問題,提岀了一種基于預訓練模型BERT和長短期記憶網絡的深度學習
2021-04-20 14:29:0619 本文關注于向大規模預訓練語言模型(如RoBERTa、BERT等)中融入知識。
2021-06-23 15:07:313539 
,其中的模型數量達數千個,日均調用服務達到千億級別。無量推薦系統,在模型訓練和推理都能夠進行海量Embedding和DNN模型的GPU計算,是目前業界領先的體系結構設計。 傳統推薦系統面臨挑戰 傳統推薦系統具有以下特點: 訓練是基于參數
2021-08-23 17:09:034514 在某一方面的智能程度。具體來說是,領域專家人工構造標準數據集,然后在其上訓練及評價相關模型及方法。但由于相關技術的限制,要想獲得效果更好、能力更強的模型,往往需要在大量的有標注的數據上進行訓練。 近期預訓練模型的
2021-09-06 10:06:533383 
深度學習是推動當前人工智能大趨勢的關鍵技術。在 MATLAB 中可以實現深度學習的數據準備、網絡設計、訓練和部署全流程開發和應用。聯合高性能 NVIDIA GPU 加快深度神經網絡訓練和推斷。
2022-02-18 13:31:441732 NLP中,預訓練大模型Finetune是一種非常常見的解決問題的范式。利用在海量文本上預訓練得到的Bert、GPT等模型,在下游不同任務上分別進行finetune,得到下游任務的模型。然而,這種方式
2022-03-21 15:33:301870 訓練引擎 Modulus 接受所有輸入,并利用 PyTorch 和 TensorFlow 來訓練生成的模型 cuDNN 進行 GPU 加速,利用 Magnum IO 進行多 GPU /多節點縮放。
2022-04-14 14:58:461026 由于亂序語言模型不使用[MASK]標記,減輕了預訓練任務與微調任務之間的gap,并由于預測空間大小為輸入序列長度,使得計算效率高于掩碼語言模型。PERT模型結構與BERT模型一致,因此在下游預訓練時,不需要修改原始BERT模型的任何代碼與腳本。
2022-05-10 15:01:271196 本文對任務低維本征子空間的探索是基于 prompt tuning, 而不是fine-tuning。原因是預訓練模型的參數實在是太多了,很難找到這么多參數的低維本征子空間。作者基于之前的工作提出
2022-07-08 11:28:24958 自BERT出現以來,nlp領域已經進入了大模型的時代,大模型雖然效果好,但是畢竟不是人人都有著豐富的GPU資源,在訓練時往往就捉襟見肘,出現顯存out of memory的問題,或者訓練時間非常非常的久
2022-08-31 18:16:051971 通過 NVIDIA GPU 加速平臺,Colossal-AI 實現了通過高效多維并行、異構內存管理、大規模優化庫、自適應任務調度等方式,更高效快速部署 AI 大模型訓練與推理。
2022-10-19 09:39:391164 電子發燒友網報道(文/李彎彎)在深度學習中,經常聽到一個詞“模型訓練”,但是模型是什么?又是怎么訓練的?在人工智能中,面對大量的數據,要在雜亂無章的內容中,準確、容易地識別,輸出需要的圖像/語音
2022-10-23 00:20:037403 預訓練 AI 模型是為了完成特定任務而在大型數據集上訓練的深度學習模型。這些模型既可以直接使用,也可以根據不同行業的應用需求進行自定義。 如果要教一個剛學會走路的孩子什么是獨角獸,那么我們首先應
2023-04-04 01:45:021057 。 另外,還有一個特別有意思的是,馬斯克才呼吁暫停?ChatGPT 的訓練,馬上就轉身就下場買了10000個GPU要訓練大模型。根據最新的數據統計顯示,馬斯克的身價為1876億美元,是全球第二大富豪,也是美國首富。美國首富買一些GPU不算什么。毛毛雨啦。 據
2023-04-12 14:19:28702 作為深度學習領域的 “github”,HuggingFace 已經共享了超過 100,000 個預訓練模型
2023-05-19 15:57:43514 
預訓練 AI 模型是為了完成特定任務而在大型數據集上訓練的深度學習模型。這些模型既可以直接使用,也可以根據不同行業的應用需求進行自定義。
2023-05-25 17:10:09618 電子發燒友網站提供《PyTorch教程13.5之在多個GPU上進行訓練.pdf》資料免費下載
2023-06-05 14:18:520 當chatgpt掀起一股新的ai大規模模型熱潮時,提供基本計算能力的nvidia是最大的受惠者之一,而nvidia的gpu產品幾乎沒有能夠替代大規模模型訓練的東西。
2023-06-05 10:58:421118 實驗室在 SageMaker Studio Lab 中打開筆記本
到目前為止,我們討論了如何在 CPU 和 GPU 上高效地訓練模型。在13.3 節中,我們甚至展示了深度學習框架如何允許人們在它們
2023-06-05 15:44:33733 
,全面介紹了天數智芯基于自研通用GPU的全棧式集群解決方案及其在支持大模型上的具體實踐。 天數智芯產品線總裁鄒翾 鄒翾指出,順應大模型的發展潮流,天數智芯依托通用GPU架構,從訓練和推理兩個角度為客戶提供支撐,全力打造高性
2023-06-08 22:55:021000 
的Aquila語言基礎模型,使用代碼數據進行繼續訓練,穩定運行19天,模型收斂效果符合預期,證明天數智芯有支持百億級參數大模型訓練的能力。 在北京市海淀區的大力支持下,智源研究院、天數智芯與愛特云翔共同合作,聯手開展基于自主通用GPU的
2023-06-12 15:23:17588 
在一些非自然圖像中要比傳統模型表現更好 CoOp 增加一些 prompt 會讓模型能力進一步提升 怎么讓能力更好?可以引入其他知識,即其他的預訓練模型,包括大語言模型、多模態模型 也包括
2023-06-15 16:36:11299 
首臺GPU千億參數大模型訓推一體機由數字寧夏倡議發起技術攻關,基于沐曦最新發布的曦云C500旗艦GPU芯片提供的算力支持、智譜華章的AI大模型以及優刻得靈活的算力部署方案,共同打造國內模型能力、算力支持及解決方案領先的國有自主知識產權的AI大模型訓練推理一體機
2023-08-21 14:41:202660 卷積神經網絡模型訓練步驟? 卷積神經網絡(Convolutional Neural Network, CNN)是一種常用的深度學習算法,廣泛應用于圖像識別、語音識別、自然語言處理等諸多領域。CNN
2023-08-21 16:42:00966 生成式AI和大語言模型(LLM)正在以難以置信的方式吸引全世界的目光,本文簡要介紹了大語言模型,訓練這些模型帶來的硬件挑戰,以及GPU和網絡行業如何針對訓練的工作負載不斷優化硬件。
2023-09-01 17:14:561072 
針對 GPU 計算特點,在顯存允許的情況下,XTuner 支持將多條短數據拼接至模型最大輸入長度,以此最大化 GPU 計算核心的利用率,可以顯著提升訓練速度。例如,在使用 oasst1 數據集微調 Llama2-7B 時,數據拼接后的訓練時長僅為普通訓練的 50% 。
2023-09-04 16:12:261349 
從 GPT-3,Gopher 到 LLaMA,大模型有更好的性能已成為業界的共識。但相比之下,單個 GPU 的顯存大小卻增長緩慢,這讓顯存成為了大模型訓練的主要瓶頸,如何在有限的 GPU 內存下訓練大模型成為了一個重要的難題。
2023-09-11 16:08:49250 
的博文,對 Pytorch的AMP ( autocast與Gradscaler 進行對比) 自動混合精度對模型訓練加速 。 注意Pytorch1.6+,已經內置torch.cuda.amp,因此便不需要加載
2023-11-03 10:00:191082 
。為了解決這個問題,英偉達將針對中國市場推出新的AI芯片,以應對美國出口限制。本文將探討如何在多個GPU上訓練大型模型,并分析英偉達禁令對中國AI計算行業的影響。
2023-11-16 11:39:31966 
本文將介紹亞馬遜如何使用 NVIDIA NeMo 框架、GPU 以及亞馬遜云科技的 EFA 來訓練其 最大的新一代大語言模型(LLM)。 大語言模型的一切都很龐大——巨型模型是在數千顆 NVIDIA
2023-11-29 21:15:02308 
基于英偉達混合資源及天數智芯混合資源完成訓練的大模型, 也是智源研究院與天數智芯合作取得的最新成果,再次證明了天數智芯通用 GPU 產品支持大模型訓練的能力,以及與主流產品的兼容能力。 據林詠華副院長介紹,為了解決異構算力混合訓練難題,智源研究院開發了高效并行訓練框
2023-11-30 13:10:02880 
谷歌模型訓練軟件主要是指ELECTRA,這是一種新的預訓練方法,源自谷歌AI。ELECTRA不僅擁有BERT的優勢,而且在效率上更勝一籌。
2024-02-29 17:37:39364 谷歌在模型訓練方面提供了一些強大的軟件工具和平臺。以下是幾個常用的谷歌模型訓練軟件及其特點。
2024-03-01 16:24:01222
 電子發燒友App
電子發燒友App









 工商網監
工商網監
評論