") 改進版BERT——SpanBERT,通過表示和預(yù)測分詞提升預(yù)訓(xùn)練效果!
改進版BERT——SpanBERT,通過表示和預(yù)測分詞提升預(yù)訓(xùn)練效果!

【導(dǎo)讀】本文提出了一個新的模型預(yù)訓(xùn)練方法 SpanBERT ,該方法能夠更好地表示和預(yù)測文本的分詞情況。新方法對 BERT 模型進行了改進,在實驗中, SpanBERT 的表現(xiàn)優(yōu)于 BERT 及其他基線,并在問答任務(wù)、指代消解等分詞選擇類任務(wù)中取得了重要進展。特別地,在使用和 BERT 相同的訓(xùn)練數(shù)據(jù)和模型大小時,SpanBERT 在 SQuAD 1.0 和 2.0 中的 F1 score 分別為 94.6% 和 88.7% 。在 OntoNotes 指代消解任務(wù)中,SpanBERT 獲得了 79.6% 的 F1 score,優(yōu)于現(xiàn)有模型。另外, SpanBERT 在 TACRED 關(guān)系抽取任務(wù)中的表現(xiàn)也超過了基線,獲得 70.8% 的 F1 score,在 GLUE 數(shù)據(jù)集上的表現(xiàn)也有所提升。

介紹
在現(xiàn)有研究中,包括 BERT 在內(nèi)的許多預(yù)訓(xùn)練模型都有很好的表現(xiàn),已有模型在單個單詞或更小的單元上增加掩膜,并使用自監(jiān)督方法進行模型訓(xùn)練。但是在許多 NLP 任務(wù)中都涉及對多個文本分詞間關(guān)系的推理。例如,在抽取式問答任務(wù)中,在回答問題“Which NFL team won Super Bown 50?”時,判斷“Denver Broncos” 是否屬于“NFL team”是非常重要的步驟。相比于在已知“Broncos”預(yù)測“Denver”的情況,直接預(yù)測“Denver Broncos”難度更大,這意味著這類分詞對自監(jiān)督任務(wù)提出了更多的挑戰(zhàn)。
在本文中,作者提出了一個新的分詞級別的預(yù)訓(xùn)練方法 SpanBERT ,其在現(xiàn)有任務(wù)中的表現(xiàn)優(yōu)于 BERT ,并在問答、指代消解等分詞選擇任務(wù)中取得了較大的進展。對 BERT 模型進行了如下改進:(1)對隨機的鄰接分詞(span)而非隨機的單個詞語(token)添加掩膜;(2)通過使用分詞邊界的表示來預(yù)測被添加掩膜的分詞的內(nèi)容,不再依賴分詞內(nèi)單個 token 的表示。
SpanBERT 能夠?qū)Ψ衷~進行更好地表示和預(yù)測。該模型和 BERT 在掩膜機制和訓(xùn)練目標上存在差別。首先,SpanBERT 不再對隨機的單個 token 添加掩膜,而是對隨機對鄰接分詞添加掩膜。其次,本文提出了一個新的訓(xùn)練目標 span-boundary objective (SBO) 進行模型訓(xùn)練。通過對分詞添加掩膜,作者能夠使模型依據(jù)其所在語境預(yù)測整個分詞。另外,SBO 能使模型在邊界詞中存儲其分詞級別的信息,使得模型的調(diào)優(yōu)更佳容易。圖1展示了模型的原理。
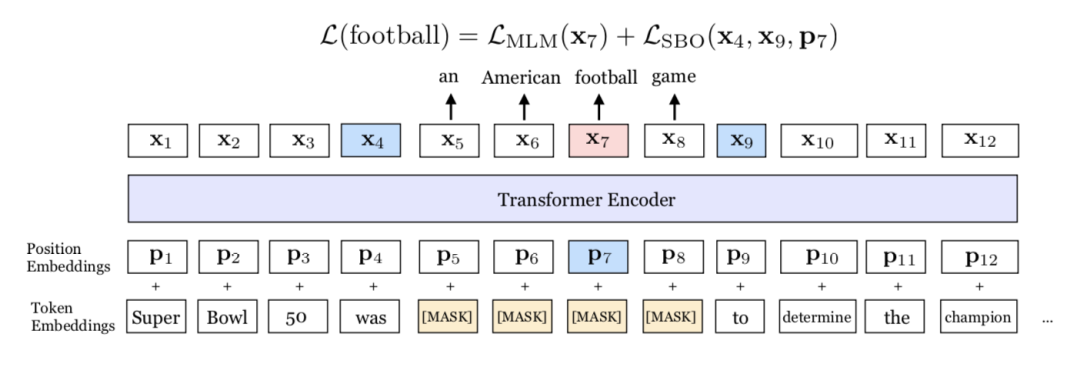
圖1 SpanBERT 圖示。在該示例中,分詞 an American football game上添加了掩膜。模型之后使用邊界詞 was和 to來預(yù)測分詞中的每個單詞。
為了搭建 SpanBERT ,作者首先構(gòu)建了一個 BERT 模型的并進行了微調(diào),該模型的表現(xiàn)優(yōu)于原始 BERT 模型。在搭建基線的時候,作者發(fā)現(xiàn)對單個部分進行預(yù)訓(xùn)練的效果,比使用 next sentence prediction (NSP) 目標對兩個長度為一半的部分進行訓(xùn)練的效果更優(yōu),在下游任務(wù)中表現(xiàn)尤其明顯。因此,作者在經(jīng)過調(diào)優(yōu)的 BERT 模型的頂端對模型進行了改進。
本文模型在多個任務(wù)中的表現(xiàn)都超越了所有的 BERT 基線模型,且在分詞選擇類任務(wù)中取得了重要提升。SpanBERT 在 SQuAD 1.0 和 2.0 中分別獲得 94.6% 和 88.7% 的 F1 score 。另外,模型在其他五個抽取式問答基線(NewsQA, TriviaQA, SearchQA, HotpotQA, Natural Questions)中的表現(xiàn)也有所提升。
SpanBERT 在另外兩個具有挑戰(zhàn)性的任務(wù)中也取得了新進展。在 CoNLL-2012 ("OnroNoets")的文本級別指代消解任務(wù)中,模型獲得了 79.6% 的 F1 socre ,超出現(xiàn)有最優(yōu)模型 6.6% 。在關(guān)系抽取任務(wù)中,SpanBERT 在 TACRED 中的 F1 score 為 70.8% ,超越現(xiàn)有最優(yōu)模型 2.8% 。另外,模型在一些不涉及分詞選擇的任務(wù)中也取得了進展,例如提升了 GLUE 上的表現(xiàn)。
在已有的一些研究中,學(xué)者提出了增加數(shù)據(jù)、擴大模型能夠帶來的優(yōu)勢。本文則探討了設(shè)計合理的預(yù)訓(xùn)練任務(wù)和目標的重要性。
研究背景:BERT
BERT 是一個用于預(yù)訓(xùn)練深度 transformer 編碼器的自監(jiān)督方法,在預(yù)訓(xùn)練后可以針對不同的下游任務(wù)進行微調(diào)。BERT 針對兩個訓(xùn)練目標進行最優(yōu)化—— 帶掩膜的語言模型(mask language modeling, MLM)和單句預(yù)測(next sentence prediction, NSP),其訓(xùn)練只需使用不帶標簽的大數(shù)據(jù)集。
符號
對于每一個單詞或子單元的序列 X = (x1, ..., xn) ,BERT 通過編碼器產(chǎn)生出其基于語境的向量表示: x1, ..., xn = enc(x1, ..., xn)。由于 BERT 是通過使用一個深度 transformor 結(jié)構(gòu)使用該編碼器,模型使用其位置嵌入 p1, ..., pn 來標識序列中每個單詞的絕對位置。
帶掩膜的語言模型(MLM)
MLM 又稱填空測驗,其內(nèi)容為預(yù)測一個序列中某一位置的缺失單詞。該步驟從單詞集合 X 中采樣一個子集合 Y ,并使用另一個單詞集合替換。在 BERT 中, Y 占 X 的 15% 。在 Y 中,80% 的詞被使用 [MASK] 替換,10% 的詞依據(jù) unigram 分布使用隨機的單詞替換,10% 保持不變。任務(wù)即使用這些被替換的單詞預(yù)測 Y 中的原始單詞。
在 BERT 中,模型通過隨機選擇一個子集來找出 Y ,每個單詞的選擇是相互獨立的。在 SpanBERT 中,Y 的選擇是通過隨機選擇鄰接分詞得到的(詳見3.1)。
單句預(yù)測(NSP)
NSP 任務(wù)中包含兩個輸入序列 XA, XB,并預(yù)測 XB 是否為 XA 的直接鄰接句。在 BERT 中,模型首先首先從詞匯表中讀取 XA ,之后有兩種操作的選擇:(1)從 XA 結(jié)束的地方繼續(xù)讀取 XB;(2)從詞匯表的另一個部分隨機采樣得到 XB 。兩句之間使用 [SEP] 符號隔開。另外,模型使用 [CLS] 符號表示 XB 是否是 XA 中的鄰接句,并加入到輸入之中。
在 SpanBERT 中,作者不再使用 NSP 目標,且只采樣一個全長度的序列(詳見3.3)。
模型
3.1 分詞掩膜
對于每一個單詞序列 X = (x1, ..., xn),作者通過迭代地采樣文本的分詞選擇單詞,直到達到掩膜要求的大小(例如 X 的 15%),并形成 X 的子集 Y。在每次迭代中,作者首先從幾何分布 l ~ Geo(p) 中采樣得到分詞的長度,該幾何分布是偏態(tài)分布,偏向于較短的分詞。之后,作者隨機(均勻地)選擇分詞的起點。
基于預(yù)進行的實驗,作者設(shè)定 p = 0.2,并將 l 裁剪為 lmax = 10 。因此分詞的平均長度為 3.8 。作者還測量了詞語(word)中的分詞程度,使得添加掩膜的分詞更長。圖2展示了分詞掩膜長度的分布情況。
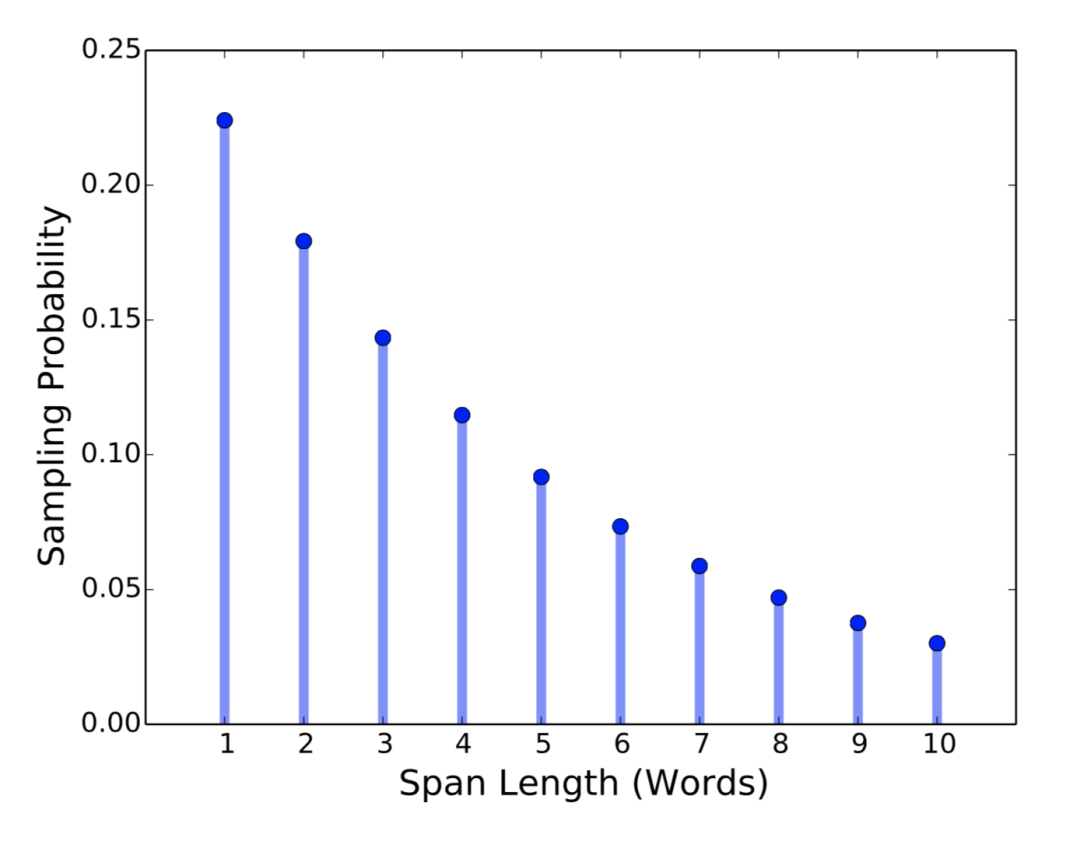
圖2 分詞長度(單詞)
和在 BERT 中一樣,作者將 Y 的規(guī)模設(shè)定為 X 的15%,其中 80% 使用 [MASK] 進行替換,10% 使用隨機單詞替換,10%保持不變。與之不同的是,作者是在分詞級別進行的這一替換,而非將每個單詞單獨替換。
3.2 分詞邊界目標(SBO)
分詞選擇模型一般使用其邊界詞創(chuàng)建一個固定長度的分詞表示。為了于該模型相適應(yīng),作者希望結(jié)尾分詞的表示的總和與中間分詞的內(nèi)容盡量相同。為此,作者引入了 SBO ,其僅使用觀測到的邊界詞來預(yù)測帶掩膜的分詞的內(nèi)容(如圖1)。
對于每一個帶掩膜的分詞 (xs, ..., xe) ,使用(s, e)表示其起點和終點。對于分詞中的每個單詞 xi ,使用外邊界單詞 xs-1 和 xe+1 的編碼進行表示,并添加其位置嵌入信息 pi ,如下:
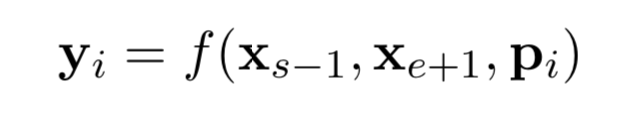
在本文中,作者使用一個兩層的前饋神經(jīng)網(wǎng)絡(luò)作為表示函數(shù),該網(wǎng)絡(luò)使用 GeLu 激活函數(shù),并使用層正則化:

作者使用向量表示 yi 來預(yù)測 xi ,并和 MLM 一樣使用交叉熵作為損失函數(shù)。
對于帶掩膜的分詞中的每一個單詞,SpanBERT 對分詞邊界和帶掩膜的語言模型的損失進行加和。
3.3 單序列訓(xùn)練
BERT 使用兩個序列 (XA, XB)進行訓(xùn)練,并預(yù)測兩個句子是否鄰接(NSP)。本文發(fā)現(xiàn)使用單個序列并移除 NSP 的效果比該方法更優(yōu)。作者推測其可能原因如下:(a)更長的語境對模型更有利;(b)加入另一個文本的語境信息會給帶掩膜的語言模型帶來噪音。
因此,本文僅采樣一個單獨的鄰接片段,該片段長度最多為512個單詞,其長度與 BERT 使用的兩片段的最大長度總和相同。
實驗設(shè)置
4.1 任務(wù)
本文在多個任務(wù)中對模型進行了評測,包括7個問答任務(wù),指代消解任務(wù),9個 BLUE 基線中對任務(wù),以及關(guān)系抽取任務(wù)。
抽取式問答
該任務(wù)的內(nèi)容為,給定一個短文本和一個問題作為輸入,模型從中抽取一個鄰接分詞作為答案。
本文首先在兩個主要的問答任務(wù)基線 SQuAD 1.1 和 2.0 上進行了評測,之后在 5 個 MRQA 的共享任務(wù)中進行了評測,包括 NewsQA, TirviaQA, HotpotQA, Natural Questions(Natural QA)。由于 MRQA 任務(wù)沒有一個公共的測試集,因此作者將開發(fā)集中的一半作為了測試集。由于這些數(shù)據(jù)集的領(lǐng)域和收集方式都不相同,這些任務(wù)能夠很好地測試 SpanBERT 的泛化性能。
作者對所有數(shù)據(jù)集都使用了與 BERT 相同的 QA 模型。作者首先將文段 P = (p1, ..., pn)和問題 Q = (q1, ..., ql') 轉(zhuǎn)化為一個序列 X = [CLS] p1 ... pl [SEP] q1 ... qL' [SEP] ,之后將其輸入到預(yù)訓(xùn)練的 transformer 編碼器中,并在其頂端獨立訓(xùn)練兩個線性分類器,用于預(yù)測回答分詞的邊界(起點和終點)。對于 SQuAD 2.0 中的不可回答問題,作者使用[CLS] 作為回答分詞。
指代消解
該任務(wù)的內(nèi)容為將文本中指向相同真實世界實體的內(nèi)容進行聚類。作者在 CoNLL-2012 共享任務(wù)中進行了評測,該評測為文檔級的指代消解。作者使用了高階指代模型(higher-order coreference model),并將其中的 LSTM 編碼器替換為了 BERT 的預(yù)訓(xùn)練 transformer 編碼器。
關(guān)系抽取
本任務(wù)內(nèi)容為,給定一個包含主語分詞和賓語分詞的句子,預(yù)測兩個分詞的關(guān)系,關(guān)系為給定的42種類型之一,包括 np_relation 。本文在 TACRED 數(shù)據(jù)集上進行了測試,并使用該文提出的實體掩膜機制進行了模型構(gòu)建。作者使用 NER 標簽對分詞進行了替換,形如“[CLS] [SUBG-PER] was born in [OBJ-LOC], Michigan, ...”,并在模型頂端加入了一個線性分類器用于預(yù)測關(guān)系類型。
GLUE
GLUE 包含9 個句子級的分類任務(wù),包括兩個單句任務(wù)(CoLA, SST-2),三個句子相似度任務(wù)( MRPC, STS-B, QQP),四個自然語言推理任務(wù)( MNLI, QNLI, Gi-, WNLI)。近期的模型主要針對單個任務(wù),但本文在所有任務(wù)上進行了評測。模型設(shè)置與 BERT 相同,并在頂端加入了一個線性分類器用于 [CLS] 單詞。
4.2 實驗步驟
作者在 fairseq 中對 BERT 模型和預(yù)訓(xùn)練方法重新進行了訓(xùn)練。本文與之前的最大不同在于,作者在每一個 epoch 使用了不同的掩膜,而 BERT 對每個序列采樣了是個不同的掩膜。另外,初始的 BERT 的采樣率較低,為 0.1, 本文則使用多達 512 個單詞作為采樣,直到到達文檔的邊界。
4.3 基線
本文與三個基線進行了比較,包括 Google BERT, 作者訓(xùn)練的 BERT ,以及作者訓(xùn)練的單序列 BERT。
結(jié)果
5.1 各任務(wù)結(jié)果
抽取式問答
表 1 展示了 SQuAD 1.1 和 2.0 上的結(jié)果,表 2 展示了其他數(shù)據(jù)集上的結(jié)果。可以發(fā)現(xiàn) SpanBERT 的效果由于基線模型。
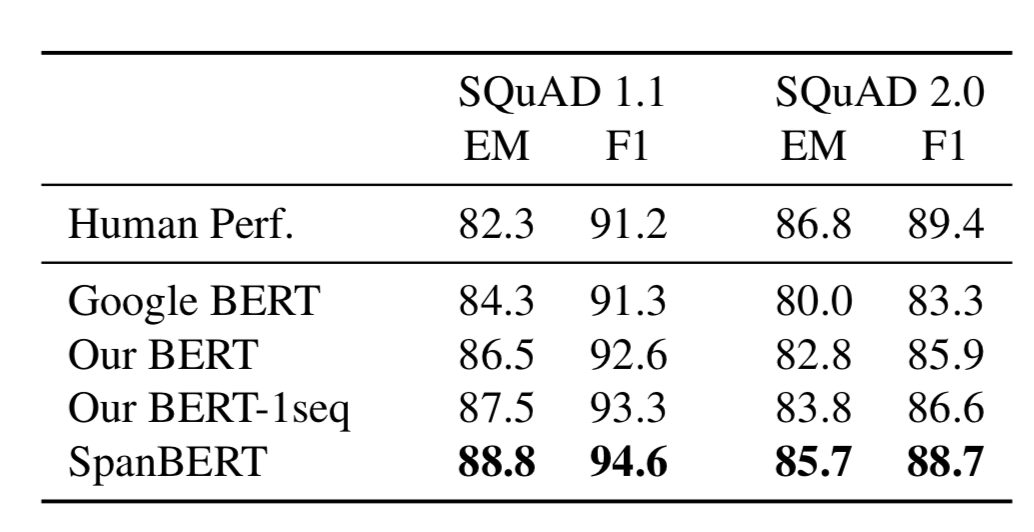
表1 SQuAD 1.1 和 2.0 數(shù)據(jù)集上的結(jié)果
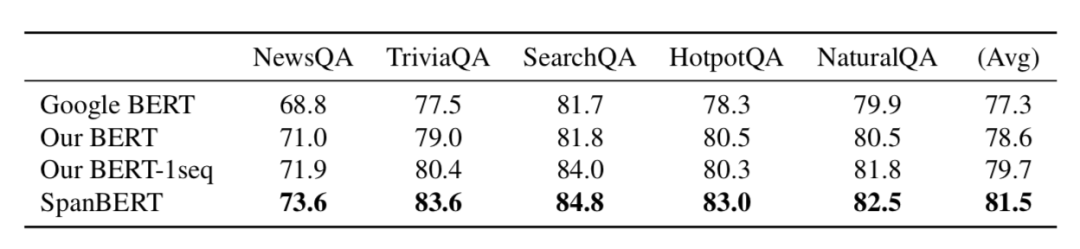
表2 其他五個數(shù)據(jù)集上的結(jié)果
指代消除
表3展示了 OntoNotes 上的模型表現(xiàn)。可以發(fā)現(xiàn),SpanBERT 的模型效果優(yōu)于基線。
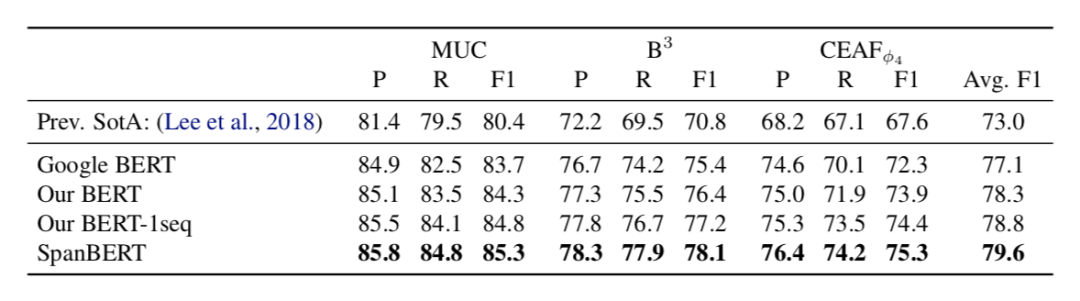
表3OntoNotes 數(shù)據(jù)集上的結(jié)果
關(guān)系抽取
表5展示了 TACRED 上的模型效果。SpanBERT 的表現(xiàn)超出了基線模型的評分。
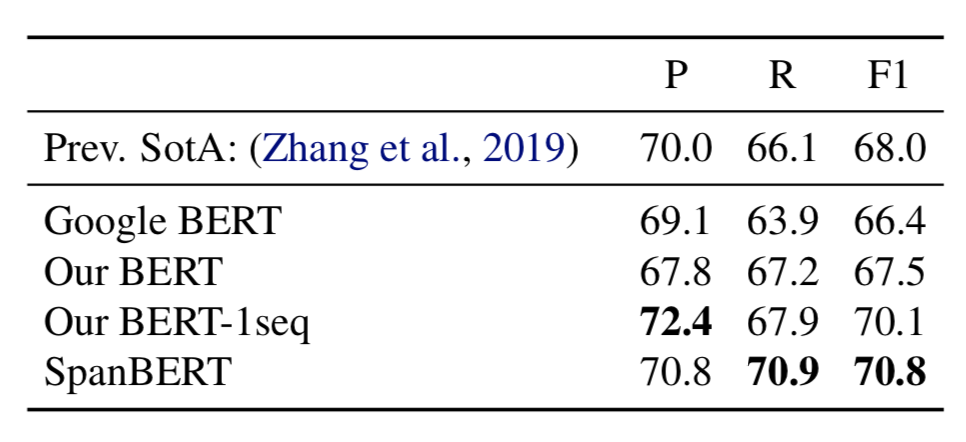
表5TACRED 數(shù)據(jù)集上的結(jié)果
GLUE
表4 展示了 GLUE 上的模型表現(xiàn), SpanBERT 同樣超越了已有評分。

表4 GLUE 上的結(jié)果
5.2 整體趨勢
通過實驗可以發(fā)現(xiàn), SpanBERT 在所有任務(wù)上的評分幾乎都優(yōu)于 BERT ,在抽取式問答任務(wù)中最為明顯。另外,作者發(fā)現(xiàn)單序列的訓(xùn)練優(yōu)于兩個序列的訓(xùn)練效果,且不再需要使用 NSP 。
消融實驗
本部分中,作者比較了隨機分詞掩膜機制和基于語言學(xué)信息的掩膜機制,發(fā)現(xiàn)本文使用的隨機分詞掩膜機制效果更優(yōu)。另外,作者研究了 SBO 的影響,并與 BERT 使用的 NSP 進行了比較。
6.1 掩膜機制
作者在子單詞、完整詞語、命名實體、名詞短語和隨機分詞方面進行了比較,表6展示了分析結(jié)果。
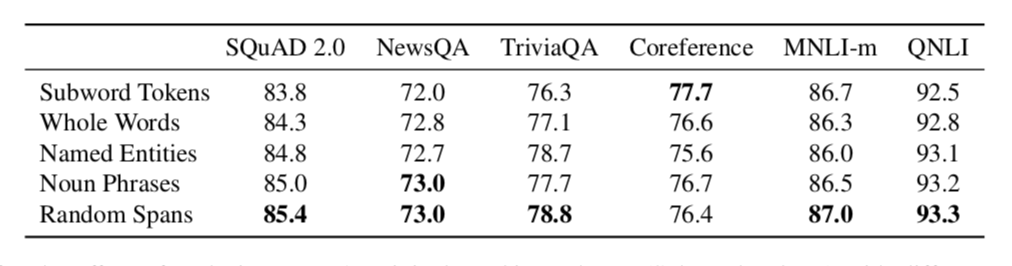
表6 使用不同掩膜機制替換 BERT 中掩膜機制的結(jié)果
6.2 輔助目標
表7展示了本實驗的結(jié)果,可以發(fā)現(xiàn),使用 SBO 替換 NSP 并使用單序列進行預(yù)測的效果更優(yōu)。

表7 使用不同的輔助目標帶來的影響
結(jié)論
本文提出了一個新的基于分詞的預(yù)訓(xùn)練模型,并對 BERT 進行了如下改進:(1)對鄰接隨機分詞而非隨機單詞添加掩膜;(2)使用分詞邊界的表示進行訓(xùn)練來預(yù)測添加掩膜的分詞的內(nèi)容,而不再使用單詞的表示進行訓(xùn)練。本文模型在多個評測任務(wù)中的得分都超越了 BERT 且在分詞選擇類任務(wù)中的提升尤其明顯。
-
編碼器
+關(guān)注
關(guān)注
45文章
3811瀏覽量
138136 -
模型
+關(guān)注
關(guān)注
1文章
3522瀏覽量
50452 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22631
原文標題:SpanBERT:提出基于分詞的預(yù)訓(xùn)練模型,多項任務(wù)性能超越現(xiàn)有模型!
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
介紹XLNet的原理及其與BERT的不同點
1024塊TPU在燃燒!將BERT預(yù)訓(xùn)練模型的訓(xùn)練時長從3天縮減到了76分鐘
新的預(yù)訓(xùn)練方法——MASS!MASS預(yù)訓(xùn)練幾大優(yōu)勢!

哈工大訊飛聯(lián)合實驗室發(fā)布基于全詞覆蓋的中文BERT預(yù)訓(xùn)練模型

圖解BERT預(yù)訓(xùn)練模型!
一種側(cè)重于學(xué)習情感特征的預(yù)訓(xùn)練方法

基于BERT的中文科技NLP預(yù)訓(xùn)練模型
文本分類任務(wù)的Bert微調(diào)trick大全
Multilingual多語言預(yù)訓(xùn)練語言模型的套路
一種基于亂序語言模型的預(yù)訓(xùn)練模型-PERT
預(yù)訓(xùn)練數(shù)據(jù)大小對于預(yù)訓(xùn)練模型的影響
PyTorch教程15.9之預(yù)訓(xùn)練BERT的數(shù)據(jù)集

PyTorch教程15.10之預(yù)訓(xùn)練BERT
PyTorch教程-15.9。預(yù)訓(xùn)練 BERT 的數(shù)據(jù)集
用PaddleNLP為GPT-2模型制作FineWeb二進制預(yù)訓(xùn)練數(shù)據(jù)集






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論