 多模態機器學習的圖像語言轉換器
多模態機器學習的圖像語言轉換器
對于 AI 系統來說,將語言與視覺聯系起來是它需要面對并學會解決的基本問題,例如在進行圖像的檢索時,AI 系統需要既能識別圖像,也能識別語言,并將二者相關聯起來。
對于這類需要 AI 系統識別不同種類或形式的信息來源的任務中,就需要多模態機器學習(MML/Multimodal Machine Learning)來發揮作用。所謂模態,指的是一種信息的來源或形式,例如文字、圖像、視頻、音頻等都是模態。多模態機器學習是指利用機器學習來處理多種模態的信息。
近些年來,在多模態機器學習領域中,多模態圖像語言轉換器(Multimodal image–language transformers)已經取得了深刻進展,尤其在解決各種需要微調的任務,如視覺問答、圖像檢索中發揮了關鍵性作用。
但是,在既需要處理圖像又需要處理語言文本的多模態機器學習任務中,有一類問題對于多模態圖像語言轉換器來說尤其棘手,那就是對文本中的動詞的理解。例如要求 AI 系統來在圖像中區分識別找出“踢球”和“拋球”這兩種情景。在這一任務中,AI 系統不僅需要識別出圖像中的“球”這一對象,還需要識別圖像中不同對象之間的關系。
為了評估近年來多模態圖像語言轉換器的預訓練水平,尤其是在“看圖理解”中對于上文所說的動詞的識別能力。近日,DeepMind 開發出一套方法,并引入了名為 SVO-Probes 的“圖像-句子對” 數據集,來評估不同 AI 系統的多模態預訓練模型對于動詞的理解水平,尤其是了解這些 AI 系統多模態轉換器的預訓練模型在結合語言文本來識別圖像時,到底是既能夠識別中圖片中的物體、也能區分中圖像中的動作,還是只能夠識別出圖中的物體。
為了達到這一目的,DeepMind 建立的 SVO-Probes 數據集包含了 48000 個圖像-句子對,可以測試 AI 系統對 447 個動詞的理解,這些動詞要么是視覺可以區分的,要么是在預訓練數據中常見的,例如許多概念字幕數據集。這個數據集中的每個句子都可以分解成 一個 <主語、動詞、賓語> 三元組,也就是 SVO 三元組,并分別配對有與句子描述的內容相符和不符的圖像,它們在是實驗中分別被稱為“正實例圖像” 和 “負實例圖像”。

圖|評估多模態語言圖像轉換器對于動詞的識別能力的 SVO- Probes 數據集中的圖像-句子對(來源:DeepMind)
上圖顯示了圖像-句子對的幾個例子,以左上角的圖像-句子對為例,分別顯示了與句子“孩子、過、馬路”相符的正示例圖像,以及與“女士、過、馬路”不符的負示例圖像,通過這一對可以測試 AI 系統識別圖中的對象——也就是名詞的能力;而上方中間的圖像-句子對,則分別顯示了”人、唱歌、演唱會上“ 的正示例圖像和”“人、跳舞、演唱會上“ 的負示例圖像。通過這一對就可以既測試 AI 系統識別圖中的名詞的能力,也能測試 AI 識別動詞的能力。
在實驗中使用這一 SVO-Probes 數據集以零樣本的方式對 AI 預訓練模型進行評估之后,DeepMind 的工程師發現,相比名詞等其他詞性,預訓練模型在需要動詞理解的情況下錯誤率要高很多。
下面的條形圖詳細說明了測試的結果。標準多模態轉換器模型經過測試后總體準確率達到 64.3%,這也顯示了 SVO- Probes 數據集確實具有挑戰性。而這一 AI 模型在對于主語和賓語判斷的準確率分別為 67.0% 和 73.4%,但是對于動詞判斷的準確率卻下降到 60.8%。這一結果表明,動詞識別確實對 AI 系統模型具有挑戰性。
此外,該公司的工程師們還進一步總結調查了哪些類別的動詞對于這些 AI 預訓練模型尤其具有挑戰性。結果發現,像“抓”這樣的運動性動詞以及“帶領”這樣在不同類型的語境中經常出現的動詞對于 AI 來說更容易。而 AI 模型判斷的正確率最高的動詞有“打斗”“包圍”“滑雪”“參加”等;而錯誤率最高的幾個動詞有“切”“爭論”“斷”等。
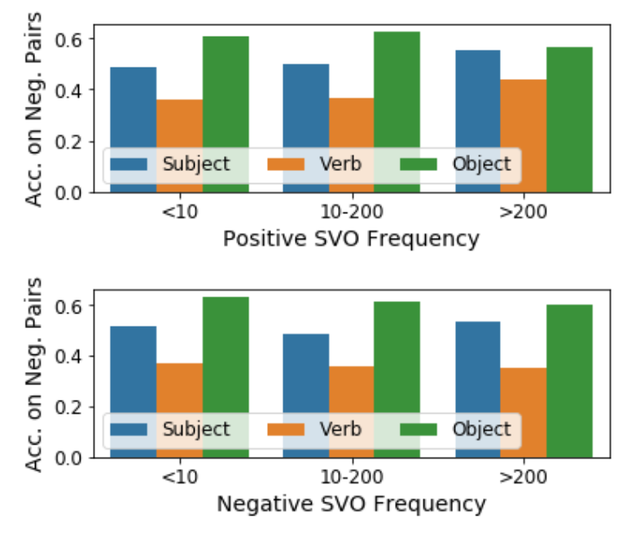
圖|多模態機器學習的圖像語言轉換器對于 SVO-Probes 數據集進行判斷測試之后的結果(來源:DeepMind)
值得一提的是,當工程師們對哪些模型架構在 SVO-Probes 數據集上的表現更好這一問題進行探索時,他們驚訝地發現,相比圖像建模能力更強的標準圖像語言轉換器模型,那些圖像建模較弱的模型反而表現更好。對這一與直覺相反的發現的解釋的一個假設是,標準轉換器模型在圖像識別方面可能有些“過度訓練”了。
審核編輯 :李倩
-
轉換器
+關注
關注
27文章
8762瀏覽量
148384 -
AI
+關注
關注
87文章
31982瀏覽量
270799 -
數據集
+關注
關注
4文章
1212瀏覽量
24895
原文標題:AI多模態圖像語言轉換器在看圖理解中對動詞的識別力
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

2025年Next Token Prediction范式會統一多模態嗎

【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
商湯日日新多模態大模型權威評測第一
自然語言處理與機器學習的關系 自然語言處理的基本概念及步驟
一文理解多模態大語言模型——下

一文理解多模態大語言模型——上

vga接口轉hdmi轉換器沒圖像沒反應怎么回事
利用OpenVINO部署Qwen2多模態模型
AMC7812具有多通道模數轉換器(ADC)數模轉換器(DAC)和溫度傳感器數據表

【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
李未可科技正式推出WAKE-AI多模態AI大模型

AI機器人迎來多模態模型
機器視覺圖像采集卡:關鍵的圖像處理設備






 工商網監
工商網監
評論