 TensorRT支持使用8位整數表示量化的浮點值
TensorRT支持使用8位整數表示量化的浮點值

7.1. Introduction to Quantization
TensorRT 支持使用 8 位整數來表示量化的浮點值。量化方案是對稱均勻量化 – 量化值以有符號 INT8 表示,從量化到非量化值的轉換只是一個乘法。在相反的方向上,量化使用倒數尺度,然后是舍入和鉗位。
要啟用任何量化操作,必須在構建器配置中設置 INT8 標志。
7.1.1. Quantization Workflows
創建量化網絡有兩種工作流程:
訓練后量化(PTQ: Post-training quantization) 在網絡經過訓練后得出比例因子。 TensorRT 為 PTQ 提供了一個工作流程,稱為校準(calibration),當網絡在代表性輸入數據上執行時,它測量每個激活張量內的激活分布,然后使用該分布來估計張量的尺度值。
量化感知訓練(QAT: Quantization-aware training) 在訓練期間計算比例因子。這允許訓練過程補償量化和去量化操作的影響。
TensorRT 的量化工具包是一個 PyTorch 庫,可幫助生成可由 TensorRT 優化的 QAT 模型。您還可以利用工具包的 PTQ 方式在 PyTorch 中執行 PTQ 并導出到 ONNX。
7.1.2. Explicit vs Implicit Quantization
量化網絡可以用兩種方式表示:
在隱式量化網絡中,每個量化張量都有一個相關的尺度。在讀寫張量時,尺度用于隱式量化和反量化值。
在處理隱式量化網絡時,TensorRT 在應用圖形優化時將模型視為浮點模型,并適時的使用 INT8 來優化層執行時間。如果一個層在 INT8 中運行得更快,那么它在 INT8 中執行。否則,使用 FP32 或 FP16。在這種模式下,TensorRT 僅針對性能進行優化,您幾乎無法控制 INT8 的使用位置——即使您在 API 級別明確設置層的精度,TensorRT 也可能在圖優化期間將該層與另一個層融合,并丟失它必須在 INT8 中執行的信息。 TensorRT 的 PTQ 功能可生成隱式量化網絡。
在顯式量化的網絡中,在量化和未量化值之間轉換的縮放操作由圖中的IQuantizeLayer ( C++ , Python)和IDequantizeLayer ( C++ , Python ) 節點顯式表示 – 這些節點此后將被稱為 Q/DQ 節點。與隱式量化相比,顯式形式精確地指定了與 INT8 之間的轉換在何處執行,并且優化器將僅執行由模型語義規定的精度轉換,即使:
- 添加額外的轉換可以提高層精度(例如,選擇 FP16 內核實現而不是 INT8 實現)
- 添加額外的轉換會導致引擎執行得更快(例如,選擇 INT8 內核實現來執行指定為具有浮點精度的層,反之亦然)
ONNX 使用顯式量化表示 – 當 PyTorch 或 TensorFlow 中的模型導出到 ONNX 時,框架圖中的每個偽量化操作都導出為 Q,然后是 DQ。由于 TensorRT 保留了這些層的語義,因此您可以期望任務準確度非常接近框架中看到的準確度。雖然優化保留了量化和去量化的位置,但它們可能會改變模型中浮點運算的順序,因此結果不會按位相同。 請注意,與 TensorRT 的 PTQ 相比,在框架中執行 QAT 或 PTQ 然后導出到 ONNX 將產生一個明確量化的模型。Table 2. Implicit vs Explicit Quantization
有關量化的更多背景信息,請參閱深度學習推理的整數量化:原理和實證評估論文。
7.1.3. Per-Tensor and Per-Channel Quantization
有兩種常見的量化尺度粒度:
每張量量化:其中使用單個比例值(標量)來縮放整個張量。
每通道量化:沿給定軸廣播尺度張量 – 對于卷積神經網絡,這通常是通道軸。
通過顯式量化,權重可以使用每張量量化進行量化,也可以使用每通道量化進行量化。在任何一種情況下,比例精度都是 FP32。激活只能使用每張量量化來量化。
當使用每通道量化時,量化軸必須是輸出通道軸。例如,當使用KCRS表示法描述 2D 卷積的權重時, K是輸出通道軸,權重量化可以描述為:
For each k in K: For each c in C: For each r in R: For each s in S: output[k,c,r,s] := clamp(round(input[k,c,r,s] / scale[k]))
比例尺是一個系數向量,必須與量化軸具有相同的大小。量化尺度必須由所有正浮點系數組成。四舍五入方法是四舍五入到最近的關系到偶數,并且鉗位在[-128, 127]范圍內。
除了定義為的逐點操作外,反量化的執行方式類似:
output[k,c,r,s] := input[k,c,r,s] * scale[k]
TensorRT 僅支持激活張量的每張量量化,但支持卷積、反卷積、全連接層和 MatMul 的每通道權重量化,其中第二個輸入是常數且兩個輸入矩陣都是二維的。7.2. Setting Dynamic Range
TensorRT 提供 API 來直接設置動態范圍(必須由量化張量表示的范圍),以支持在 TensorRT 之外計算這些值的隱式量化。 API 允許使用最小值和最大值設置張量的動態范圍。由于 TensorRT 目前僅支持對稱范圍,因此使用max(abs(min_float), abs(max_float))計算比例。請注意,當abs(min_float) != abs(max_float)時,TensorRT 使用比配置更大的動態范圍,這可能會增加舍入誤差。
將在 INT8 中執行的操作的所有浮點輸入和輸出都需要動態范圍。
您可以按如下方式設置張量的動態范圍: C++
tensor-》setDynamicRange(min_float, max_float);
Python
tensor.dynamic_range = (min_float, max_float)
sampleINT8API說明了這些 API 在 C++ 中的使用。
7.3. Post-Training Quantization using Calibration
在訓練后量化中,TensorRT 計算網絡中每個張量的比例值。這個過程稱為校準,需要您提供有代表性的輸入數據,TensorRT 在其上運行網絡以收集每個激活張量的統計信息。
所需的輸入數據量取決于應用程序,但實驗表明大約 500 張圖像足以校準 ImageNet 分類網絡。
給定激活張量的統計數據,決定最佳尺度值并不是一門精確的科學——它需要平衡量化表示中的兩個誤差源:離散化誤差(隨著每個量化值表示的范圍變大而增加)和截斷誤差(其中值被限制在可表示范圍的極限)。因此,TensorRT 提供了多個不同的校準器,它們以不同的方式計算比例。較舊的校準器還為 GPU 執行層融合,以在執行校準之前優化掉不需要的張量。這在使用 DLA 時可能會出現問題,其中融合模式可能不同,并且可以使用kCALIBRATE_BEFORE_FUSION量化標志覆蓋。
IInt8EntropyCalibrator2
熵校準選擇張量的比例因子來優化量化張量的信息論內容,通常會抑制分布中的異常值。這是當前推薦的熵校準器,是 DLA 所必需的。默認情況下,校準發生在圖層融合之前。推薦用于基于 CNN 的網絡。
IInt8MinMaxCalibrator
該校準器使用激活分布的整個范圍來確定比例因子。它似乎更適合 NLP 任務。默認情況下,校準發生在圖層融合之前。推薦用于 NVIDIA BERT(谷歌官方實現的優化版本)等網絡。
IInt8EntropyCalibrator
這是原始的熵校準器。它的使用沒有 LegacyCalibrator 復雜,通常會產生更好的結果。默認情況下,校準發生在圖層融合之后。
IInt8LegacyCalibrator
該校準器與 TensorRT 2.0 EA 兼容。此校準器需要用戶參數化,并且在其他校準器產生不良結果時作為備用選項提供。默認情況下,校準發生在圖層融合之后。您可以自定義此校準器以實現最大百分比,例如,觀察到 99.99% 的最大百分比對于 NVIDIA BERT 具有最佳精度。
構建 INT8 引擎時,構建器執行以下步驟:
構建一個 32 位引擎,在校準集上運行它,并為激活值分布的每個張量記錄一個直方圖。
從直方圖構建一個校準表,為每個張量提供一個比例值。
根據校準表和網絡定義構建 INT8 引擎。
校準可能很慢;因此步驟 2 的輸出(校準表)可以被緩存和重用。這在多次構建相同的網絡時非常有用,例如,在多個平臺上 – 特別是,它可以簡化工作流程,在具有離散 GPU 的機器上構建校準表,然后在嵌入式平臺上重用它。可在此處找到樣本校準表。 在運行校準之前,TensorRT 會查詢校準器實現以查看它是否有權訪問緩存表。如果是這樣,它直接進行到上面的步驟 3。緩存數據作為指針和長度傳遞。
只要校準發生在層融合之前,校準緩存數據就可以在平臺之間以及為不同設備構建引擎時移植。這意味著在默認情況下使用IInt8EntropyCalibrator2或IInt8MinMaxCalibrator校準器或設置QuantizationFlag::kCALIBRATE_BEFORE_FUSION時,校準緩存是可移植的。不能保證跨平臺或設備的融合是相同的,因此在層融合之后進行校準可能不會產生便攜式校準緩存。 除了量化激活,TensorRT 還必須量化權重。它使用對稱量化和使用權重張量中找到的最大絕對值計算的量化比例。對于卷積、反卷積和全連接權重,尺度是每個通道的。
注意:當構建器配置為使用 INT8 I/O 時,TensorRT 仍希望校準數據位于 FP32 中。您可以通過將 INT8 I/O 校準數據轉換為 FP32 精度來創建 FP32 校準數據。您還必須確保 FP32 投射校準數據在[-128.0F, 127.0F]范圍內,因此可以轉換為 INT8 數據而不會造成任何精度損失。
INT8 校準可與動態范圍 API 一起使用。手動設置動態范圍會覆蓋 INT8 校準生成的動態范圍。
注意:校準是確定性的——也就是說,如果您在同一設備上以相同的順序為 TensorRT 提供相同的校準輸入,則生成的比例在不同的運行中將是相同的。當提供相同的校準輸入時,當使用具有相同批量大小的相同設備生成時,校準緩存中的數據將按位相同。當使用不同的設備、不同的批量大小或使用不同的校準輸入生成校準緩存時,不能保證校準緩存中的確切數據按位相同。
7.3.1. INT8 Calibration Using C++
要向 TensorRT 提供校準數據,請實現IInt8Calibrator接口。
關于這個任務
構建器調用校準器如下:
首先,它查詢接口的批次大小并調用getBatchSize()來確定預期的輸入批次的大小。
然后,它反復調用getBatch()來獲取批量輸入。批次必須與getBatchSize()的批次大小完全相同。當沒有更多批次時, getBatch()必須返回false 。
實現校準器后,您可以配置構建器以使用它:
config->setInt8Calibrator(calibrator.get());
要緩存校準表,請實現writeCalibrationCache()和readCalibrationCache()方法。
有關配置 INT8 校準器對象的更多信息,請參閱sampleINT8
7.3.2. Calibration Using Python
以下步驟說明了如何使用 Python API 創建 INT8 校準器對象。 程序
導入 TensorRT:
import tensorrt as trt
NUM_IMAGES_PER_BATCH = 5 batchstream = ImageBatchStream(NUM_IMAGES_PER_BATCH, calibration_files)
Int8_calibrator = EntropyCalibrator(["input_node_name"], batchstream)
config.set_flag(trt.BuilderFlag.INT8) config.int8_calibrator = Int8_calibrator
7.4. Explicit Quantization
當 TensorRT 檢測到網絡中存在 Q/DQ 層時,它會使用顯式精度處理邏輯構建一個引擎。
AQ/DQ 網絡必須在啟用 INT8 精度構建器標志的情況下構建:
config->setFlag(BuilderFlag::kINT8);
在顯式量化中,表示與 INT8 之間的網絡變化是顯式的,因此,INT8 不能用作類型約束。7.4.1. Quantized Weights
Q/DQ 模型的權重必須使用 FP32 數據類型指定。 TensorRT 使用對權重進行操作的IQuantizeLayer的比例對權重進行量化。量化的權重存儲在引擎文件中。也可以使用預量化權重,但必須使用 FP32 數據類型指定。 Q 節點的 scale 必須設置為1.0F ,但 DQ 節點必須是真實的 scale 值。
7.4.2. ONNX Support
當使用 Quantization Aware Training (QAT) 在 PyTorch 或 TensorFlow 中訓練的模型導出到 ONNX 時,框架圖中的每個偽量化操作都會導出為一對QuantizeLinear和DequantizeLinear ONNX 運算符。
當 TensorRT 導入 ONNX 模型時,ONNX QuantizeLinear算子作為IQuantizeLayer實例導入,ONNX DequantizeLinear算子作為IDequantizeLayer實例導入。
使用 opset 10 的 ONNX 引入了對 QuantizeLinear/DequantizeLinear 的支持,并且在 opset 13 中添加了量化軸屬性(每通道量化所必需的)。 PyTorch 1.8 引入了對使用 opset 13 將 PyTorch 模型導出到 ONNX 的支持。
警告: ONNX GEMM 算子是一個可以按通道量化的示例。 PyTorch torch.nn.Linear層導出為 ONNX GEMM 算子,具有(K, C)權重布局并啟用了transB GEMM 屬性(這會在執行 GEMM 操作之前轉置權重)。另一方面,TensorFlow在 ONNX 導出之前預轉置權重(C, K) :
PyTorch: $y = xW^T$
TensorFlow: $y = xW$
因此,PyTorch 權重由 TensorRT 轉置。權重在轉置之前由 TensorRT 進行量化,因此源自從 PyTorch 導出的 ONNX QAT 模型的 GEMM 層使用維度0進行每通道量化(軸K = 0 );而源自 TensorFlow 的模型使用維度1 (軸K = 1 )。
TensorRT 不支持使用 INT8 張量或量化運算符的預量化 ONNX 模型。具體來說,以下 ONNX 量化運算符不受支持,如果在 TensorRT 導入 ONNX 模型時遇到它們,則會生成導入錯誤:
QLinearConv/QLinearMatmul
ConvInteger/MatmulInteger
7.4.3. TensorRT Processing Of Q/DQ Networks
當 TensorRT 在 Q/DQ 模式下優化網絡時,優化過程僅限于不改變網絡算術正確性的優化。由于浮點運算的順序會產生不同的結果(例如,重寫 $a * s + b * s$ 為 $(a + b) * s$是一個有效的優化)。允許這些差異通常是后端優化的基礎,這也適用于將具有 Q/DQ 層的圖轉換為使用 INT8 計算。
Q/DQ 層控制網絡的計算和數據精度。 IQuantizeLayer實例通過量化將 FP32 張量轉換為 INT8 張量, IDequantizeLayer實例通過反量化將INT8張量轉換為 FP32 張量。 TensorRT 期望量化層的每個輸入上都有一個 Q/DQ 層對。量化層是深度學習層,可以通過與IQuantizeLayer和IDequantizeLayer實例融合來轉換為量化層。當 TensorRT 執行這些融合時,它會將可量化層替換為實際使用 INT8 計算操作對 INT8 數據進行操作的量化層。
對于本章中使用的圖表,綠色表示 INT8 精度,藍色表示浮點精度。箭頭代表網絡激活張量,正方形代表網絡層。
下圖。 可量化的AveragePool層(藍色)與 DQ 層和 Q 層融合。所有三層都被量化的AveragePool層(綠色)替換。
在網絡優化期間,TensorRT 在稱為 Q/DQ 傳播的過程中移動 Q/DQ 層。傳播的目標是最大化以低精度處理的圖的比例。因此,TensorRT 向后傳播 Q 節點(以便盡可能早地進行量化)和向前傳播 DQ 節點(以便盡可能晚地進行去量化)。 Q-layers 可以與 commute-with-Quantization 層交換位置,DQ-layers 可以與 commute-with-Dequantization 層交換位置。
A layer Op commutes with quantization if $Q (Op (x) ) ==Op (Q (x) )$
Similarly, a layer Op commutes with dequantization if $Op (DQ (x) ) ==DQ (Op (x) )$
下圖說明了 DQ 前向傳播和 Q 后向傳播。這些是對模型的合法重寫,因為 Max Pooling 具有 INT8 實現,并且因為 Max Pooling 與 DQ 和 Q 通訊。
下圖描述 DQ 前向傳播和 Q 后向傳播的插圖。
注意:
為了理解最大池化交換,讓我們看一下應用于某個任意輸入的最大池化操作的輸出。 Max Pooling應用于輸入系數組并輸出具有最大值的系數。對于由系數組成的組i : ${x_0 。 . x_m}$
$utput_i := max({x_0, x_1, … x_m}) = max({max({max({x_0, x_1}), x_2)}, … x_m})$
因此,在不失一般性(WLOG)的情況下查看兩個任意系數就足夠了:
$x_j = max({x_j, x_k})\ \ \ for\ \ \ x_j 》= x_k$
對于量化函數$Q(a, scale, x_max, x_min) := truncate(round(a/scale), x_max,x_min)$ 來說$scale》0$, 注意(不提供證明,并使用簡化符號):
$Q(x_j, scale) 》= Q(x_k, scale)\ \ \ for\ \ \ x_j 》= x_k$
因此:
$max({Q(x_j, scale), Q(x_k, scale)}) = Q(x_j, scale)\ \ \ for\ \ \ x_j 》= x_k$
然而,根據定義:
$Q(max({x_j, x_k}), scale) = Q(x_j, scale)\ \ \ for\ \ \ x_j 》= x_k$
函數 $max$ commutes-with-quantization 和 Max Pooling 也是如此。
類似地,對于去量化,函數$DQ (a, scale) :=a * scale with scale》0$ 我們可以證明:
$max({DQ(x_j, scale), DQ(x_k, scale)}) = DQ(x_j, scale) = DQ(max({x_j, x_k}), scale)\ \ \ for\ \ \ x_j 》= x_k$
量化層和交換層的處理方式是有區別的。兩種類型的層都可以在 INT8 中計算,但可量化層也與 DQ 輸入層和 Q 輸出層融合。例如, AveragePooling層(可量化)不與 Q 或 DQ 交換,因此使用 Q/DQ 融合對其進行量化,如第一張圖所示。這與如何量化 Max Pooling(交換)形成對比。
7.4.4. Q/DQ Layer-Placement Recommendations
Q/DQ 層在網絡中的放置會影響性能和準確性。由于量化引入的誤差,激進量化會導致模型精度下降。但量化也可以減少延遲。此處列出了在網絡中放置 Q/DQ 層的一些建議。
量化加權運算(卷積、轉置卷積和 GEMM)的所有輸入。權重和激活的量化降低了帶寬需求,還使 INT8 計算能夠加速帶寬受限和計算受限的層。
下圖 TensorRT 如何融合卷積層的兩個示例。在左邊,只有輸入被量化。在右邊,輸入和輸出都被量化了。
默認情況下,不量化加權運算的輸出。保留更高精度的去量化輸出有時很有用。例如,如果線性運算后面跟著一個激活函數(SiLU,下圖中),它需要更高的精度輸入才能產生可接受的精度。
不要在訓練框架中模擬批量歸一化和 ReLU 融合,因為 TensorRT 優化保證保留這些操作的算術語義。
TensorRT 可以在加權層之后融合element-wise addition,這對于像 ResNet 和 EfficientNet 這樣具有跳躍連接的模型很有用。element-wise addition層的第一個輸入的精度決定了融合輸出的精度。
比如下圖中,$x_f^1$的精度是浮點數,所以融合卷積的輸出僅限于浮點數,后面的Q層不能和卷積融合。
相比之下,當$x_f^1$量化為 INT8 時,如下圖所示,融合卷積的輸出也是 INT8,尾部的 Q 層與卷積融合。
為了獲得額外的性能,請嘗試使用 Q/DQ 量化不交換的層。目前,具有 INT8 輸入的非加權層也需要 INT8 輸出,因此對輸入和輸出都進行量化。
如果 TensorRT 無法將操作與周圍的 Q/DQ 層融合,則性能可能會降低,因此在添加 Q/DQ 節點時要保守,并牢記準確性和 TensorRT 性能進行試驗。
下圖是額外 Q/DQ 操作可能導致的次優融合示例(突出顯示的淺綠色背景矩形)。
對激活使用逐張量量化;和每個通道的權重量化。這種配置已經被經驗證明可以帶來最佳的量化精度。
您可以通過啟用 FP16 進一步優化引擎延遲。 TensorRT 盡可能嘗試使用 FP16 而不是 FP32(目前并非所有層類型都支持)
7.4.5. Q/DQ Limitations
TensorRT 執行的一些 Q/DQ 圖重寫優化比較兩個或多個 Q/DQ 層之間的量化尺度值,并且僅在比較的量化尺度相等時才執行圖重寫。改裝可改裝的 TensorRT 引擎時,可以為 Q/DQ 節點的尺度分配新值。在 Q/DQ 引擎的改裝操作期間,TensorRT 檢查是否為參與尺度相關優化的 Q/DQ 層分配了破壞重寫優化的新值,如果為真則拋出異常。
下比較 Q1 和 Q2 的尺度是否相等的示例,如果相等,則允許它們向后傳播。如果使用 Q1 和 Q2 的新值對引擎進行改裝,使得Q1 != Q2 ,則異常中止改裝過程。
7.4.6. QAT Networks Using TensorFlow
目前,沒有用于 TensorRT 的 TensorFlow 量化工具包,但是,有幾種推薦的方法:
TensorFlow 2 引入了一個新的 API 來在 QAT(量化感知訓練)中執行偽量化: tf.quantization.quantize_and_dequantize_v2 該算子使用與 TensorRT 的量化方案一致的對稱量化。我們推薦這個 API 而不是 TensorFlow 1 tf.quantization.quantize_and_dequantize API。 導出到 ONNX 時,可以使用tf2onnx轉換器將quantize_and_dequantize_v2算子轉換為一對 QuantizeLinear 和 DequantizeLinear 算子(Q/DQ 算子) 。請參閱quantization_ops_rewriter以了解如何執行此轉換。
默認情況下,TensorFlow 將tf.quantization.quantize_and_dequantize_v2算子(導出到 ONNX 后的 Q/DQ 節點)放在算子輸出上,而 TensorRT 建議將 Q/DQ 放在層輸入上。有關詳細信息,請參閱QDQ 位置。
TensorFlow 1 不支持每通道量化 (PCQ)。建議將 PCQ 用于權重,以保持模型的準確性。
7.4.7. QAT Networks Using PyTorch
PyTorch 1.8.0 和前版支持 ONNX QuantizeLinear / DequantizeLinear ,支持每通道縮放。您可以使用pytorch-quantization進行 INT8 校準,運行量化感知微調,生成 ONNX,最后使用 TensorRT 在此 ONNX 模型上運行推理。更多詳細信息可以在PyTorch-Quantization Toolkit 用戶指南中找到。
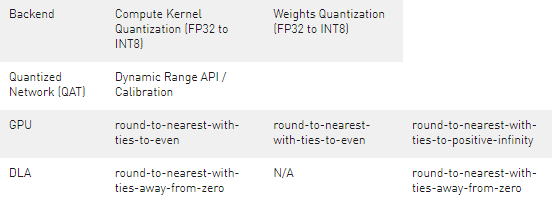
7.5. INT8 Rounding Modes
關于作者
Ken He 是 NVIDIA 企業級開發者社區經理 & 高級講師,擁有多年的 GPU 和人工智能開發經驗。自 2017 年加入 NVIDIA 開發者社區以來,完成過上百場培訓,幫助上萬個開發者了解人工智能和 GPU 編程開發。在計算機視覺,高性能計算領域完成過多個獨立項目。并且,在機器人和無人機領域,有過豐富的研發經驗。對于圖像識別,目標的檢測與跟蹤完成過多種解決方案。曾經參與 GPU 版氣象模式GRAPES,是其主要研發者。
審核編輯:郭婷
-
API
+關注
關注
2文章
1590瀏覽量
63927 -
引擎
+關注
關注
1文章
366瀏覽量
22978
發布評論請先 登錄
基于雙向塊浮點量化的大語言模型高效加速器設計
解鎖NVIDIA TensorRT-LLM的卓越性能
NVIDIA TensorRT-LLM Roadmap現已在GitHub上公開發布

TensorRT-LLM低精度推理優化

電容容值如何表示?換算單位方法是什么?

基于FPGA的數字信號處理——浮點數

西門子博途新數據類型之:SINT(8位整數)






 工商網監
工商網監
評論