") 如何使用triton的language api來實現(xiàn)gemm的算子
如何使用triton的language api來實現(xiàn)gemm的算子

前言
通過前兩章對于triton的簡單介紹,相信大家已經(jīng)能夠通過從源碼來安裝triton,同時通過triton提供的language前端寫出自己想要的一些計算密集型算子。這章開始,我們通過構建一套比較標準的batch gemm的benchmark,來看看目前這些主流的代碼生成工具,高性能模板庫,與廠商提供的vendor library的差距。因為只有明確了目前的差距,后期關于針對性的優(yōu)化才能做到點上。這一章,我將使用一個batch的gemm作為例子,來看看triton目前對其的優(yōu)化能力。選batch gemm的原因是因為目前的LLM中不可避免會有對應的attention操作,而attention操作中,核心的計算密集型算子就是batch的gemm,如果你能夠?qū)atch的gemm有一個很好的優(yōu)化思路,那么在MLSys中大部分的算子優(yōu)化類的工作對你來說將不會顯得那么無從下手。
通過Triton實現(xiàn)一個batch GEMM算子
在triton的官方tutorial中給出了如何使用triton的language api來實現(xiàn)gemm的算子,在上一章的最后,我也給出了對應的例子以及他通過和調(diào)用torch.matmul實現(xiàn)的gemm在3090上的性能比較。最終可以發(fā)現(xiàn),針對某些size的gemm,triton在TFLOPS這個指標層面是能夠超過cublas的實現(xiàn),但是后面我通過nsight system對每個kernel的具體執(zhí)行時間進行了profiling,發(fā)現(xiàn)在torch.matmul或者torch.bmm底層所調(diào)用的cuBLAS的kernel并不是對應輸入輸出datatype以及computetype中最快的那個。所以,這樣的比較就顯得有些沒有意義。不過,沒事,這對我們建立起如何優(yōu)化一個計算密集型算子來說是一個不錯的入門。
其實想要通過triton實現(xiàn)一個batch的gemm非常簡單,我們只需要將triton中原先例子里的tl.program_id(axis=0),在這個program_id上再添加一個axis來表示batch維度的并行就可以了,然后針對每個數(shù)組的變化由單batch到多batch,只用增加一個大小為矩陣size的stride偏置即可,這種實現(xiàn)方式其實也是cuBLAS中cublasGemmStridedBatched命名的得來。具體的代碼如下所示:
@triton.jit defmatmul_kernel( #Pointerstomatrices A_ptr,B_ptr,C_ptr, #Matrixdimensions B,M,N,K, #Thestridevariablesrepresenthowmuchtoincreasetheptrbywhenmovingby1 #elementinaparticulardimension.E.g.stride_amishowmuchtoincreasea_ptr #bytogettheelementonerowdown(AhasMrows) stride_ab,stride_am,stride_ak, stride_bb,stride_bk,stride_bn, stride_cb,stride_cm,stride_cn, #Meta-parameters BLOCK_SIZE_M:tl.constexpr,BLOCK_SIZE_N:tl.constexpr,BLOCK_SIZE_K:tl.constexpr, GROUP_SIZE_M:tl.constexpr, ACTIVATION:tl.constexpr, ): pid=tl.program_id(axis=0) offs_b=tl.program_id(axis=1) num_pid_m=tl.cdiv(M,BLOCK_SIZE_M) num_pid_n=tl.cdiv(N,BLOCK_SIZE_N) num_pid_k=tl.cdiv(K,BLOCK_SIZE_K) num_pid_in_group=GROUP_SIZE_M*num_pid_n group_id=pid//num_pid_in_group first_pid_m=group_id*GROUP_SIZE_M group_size_m=min(num_pid_m-first_pid_m,GROUP_SIZE_M) pid_m=first_pid_m+(pid%group_size_m) pid_n=(pid%num_pid_in_group)//group_size_m offs_m=pid_m*BLOCK_SIZE_M+tl.arange(0,BLOCK_SIZE_M) offs_n=pid_n*BLOCK_SIZE_N+tl.arange(0,BLOCK_SIZE_N) offs_k=tl.arange(0,BLOCK_SIZE_K) A_ptr=A_ptr+(offs_b*stride_ab+offs_m[:,None]*stride_am+offs_k[None,:]*stride_ak) B_ptr=B_ptr+(offs_b*stride_bb+offs_k[:,None]*stride_bk+offs_n[None,:]*stride_bn) #initializeanditerativelyupdateaccumulator acc=tl.zeros((BLOCK_SIZE_M,BLOCK_SIZE_N),dtype=tl.float32) forkinrange(0,K,BLOCK_SIZE_K): a=tl.load(A_ptr) b=tl.load(B_ptr) acc+=tl.dot(a,b) A_ptr+=BLOCK_SIZE_K*stride_ak B_ptr+=BLOCK_SIZE_K*stride_bk c=acc.to(tl.float16) C_ptr=C_ptr+(offs_b*stride_cb+offs_m[:,None]*stride_cm+offs_n[None,:]*stride_cn) c_mask=(offs_b
然后寫一個簡單的單元測試,確保通過triton寫出來的kernel能夠和torch.matmul/torch.bmm對上即可。
torch.manual_seed(0) a=torch.randn((4,512,512),device='cuda',dtype=torch.float16) b=torch.randn((4,512,512),device='cuda',dtype=torch.float16) torch_output=torch.bmm(a,b) triton_output=matmul(a,b,activation=None) print(f"triton_output={triton_output}") print(f"torch_output={torch_output}") iftorch.allclose(triton_output,torch_output,atol=1e-2,rtol=0): print("TritonandTorchmatch") else: print("TritonandTorchdiffer")
其實triton的language語法確實很簡單,相比較cuda來說,它能夠幫我們快速驗證一些idea,同時給出比cublas性能相當?shù)乃阕印H绻阆胍肅UDA從0開始實現(xiàn)一個batch GEMM并且調(diào)用tensor core,借助shared memory,register files去幫你加速運算或者優(yōu)化data movement,那么這個過程是非常需要一定的高性能計算和架構的經(jīng)驗,你才可能拿到和cuBLAS的kernel接近的性能。OK,有了triton的具體kernel實現(xiàn),接下來其實就是要去寫一個triton需要被調(diào)優(yōu)的模版,需要triton從你定義的這個比較小的搜索空間中,去得到對應的最優(yōu)解,從而作為本次batch gemm的最優(yōu)實現(xiàn),我在autotuner這塊并沒有花太大的精力去改進,依舊GEMM例子中的模版拿來作為一個參考,具體代碼如下:
@triton.autotune( configs=[ triton.Config({'BLOCK_SIZE_M':128,'BLOCK_SIZE_N':256,'BLOCK_SIZE_K':64,'GROUP_SIZE_M':8},num_stages=3,num_warps=8), triton.Config({'BLOCK_SIZE_M':64,'BLOCK_SIZE_N':256,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4), triton.Config({'BLOCK_SIZE_M':128,'BLOCK_SIZE_N':128,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4), triton.Config({'BLOCK_SIZE_M':128,'BLOCK_SIZE_N':64,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4), triton.Config({'BLOCK_SIZE_M':64,'BLOCK_SIZE_N':128,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4), triton.Config({'BLOCK_SIZE_M':128,'BLOCK_SIZE_N':32,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4), triton.Config({'BLOCK_SIZE_M':64,'BLOCK_SIZE_N':32,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=5,num_warps=2), triton.Config({'BLOCK_SIZE_M':32,'BLOCK_SIZE_N':64,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=5,num_warps=2), ], key=['M','N','K'], )
然后通過調(diào)用Triton的do_bench就可以將你寫的算子跑起來了,do_bench處在python/triton/testing.py下,其中會對每個kernel進行25次的warm_up和100次iteration,最后會根據(jù)你設置的分位數(shù)得到一個相對穩(wěn)定的性能。切記,在測試每個kernel的運行情況的時候,需要將GPU的頻率鎖在最高頻,通過下面的代碼就可以做到,由于我用到的A10,A10最大頻率在1695 MHz
sudonvidia-smi--lock-gpu-clocks=1695,1695
這是通過對fp16的輸入,acc_type = fp32,最終輸出為fp16的batch gemm (16x4096x4096, 16x4096x4096)
通過nsight system + nvtx就可以看到每個kernel的具體實現(xiàn)情況:
img
添加圖片注釋,不超過 140 字(可選)
使用torch.bmm/torch.matmul來實現(xiàn)batch-gemm,其中調(diào)用的kernel名字為ampere_fp16_s1688gemm_fp16_256x64_Idg8_f2f_stages_32x1_nn,該kernel運行的時間是46.059ms
那么,當我們運行triton的時候,通過同樣的方式來得到同樣迭代次序的kernel,nsight分析如下
img
該kernel的名字為matmul_kernel_0d1d2d3d4d5d6d7d8d9c10d11d12c13d14d15c,運行時間為35.067ms
當然通過torch.matmul調(diào)用的cuBLAS這個算子,顯然不是我們想要的那個,我們就需要去深入到cuBLAS的具體文檔,翻一翻,找出其最快的API。在后面的benchmark中,我選用了cublasHgemmStridedBatched和cublasGemmStrideBatchedEx這兩個API來分別實現(xiàn)batch GEMM。通過cublasHgemmStridedBatched啟動kernel名字為ampere_h16816gemm_256x128_Idg8_stages_32x3_nn,其運行時間為30.330ms
img
通過cuBLAS的cublasGemmStridedBatchedEx API構建算子性能標準
在cuBLAS中,針對batch gemm的實現(xiàn)有很多種方式,我也踩了不少坑。第一次調(diào)用成了cublasHgemmStridedBatched,該kernel的性能其實是不如cublasGemmStridedBatchedEx,因為cublasGemmStridedBatchedEx給了一個cublasGemmAlgo_t algo的參數(shù),該參數(shù)可以幫我們選擇對應batch gemm的不同實現(xiàn),關于algo又具有如下這么多種:
CUBLAS_GEMM_DEFAULT, CUBLAS_GEMM_ALGO0, CUBLAS_GEMM_ALGO1, CUBLAS_GEMM_ALGO2, CUBLAS_GEMM_ALGO3, CUBLAS_GEMM_ALGO4, CUBLAS_GEMM_ALGO5, CUBLAS_GEMM_ALGO6, CUBLAS_GEMM_ALGO7, CUBLAS_GEMM_ALGO8, CUBLAS_GEMM_ALGO9, CUBLAS_GEMM_ALGO10, CUBLAS_GEMM_ALGO11, CUBLAS_GEMM_ALGO12, CUBLAS_GEMM_ALGO13, CUBLAS_GEMM_ALGO14, CUBLAS_GEMM_ALGO15, CUBLAS_GEMM_ALGO16, CUBLAS_GEMM_ALGO17, CUBLAS_GEMM_DFALT_TENSOR_OP, CUBLAS_GEMM_ALGO0_TENSOR_OP, CUBLAS_GEMM_ALGO1_TENSOR_OP, CUBLAS_GEMM_ALGO2_TENSOR_OP, CUBLAS_GEMM_ALGO3_TENSOR_OP, CUBLAS_GEMM_ALGO4_TENSOR_OP, CUBLAS_GEMM_ALGO18, CUBLAS_GEMM_ALGO19, CUBLAS_GEMM_ALGO20, CUBLAS_GEMM_ALGO21, CUBLAS_GEMM_ALGO22, CUBLAS_GEMM_ALGO23, CUBLAS_GEMM_ALGO5_TENSOR_OP, CUBLAS_GEMM_ALGO6_TENSOR_OP, CUBLAS_GEMM_ALGO7_TENSOR_OP, CUBLAS_GEMM_ALGO8_TENSOR_OP, CUBLAS_GEMM_ALGO9_TENSOR_OP, CUBLAS_GEMM_ALGO10_TENSOR_OP, CUBLAS_GEMM_ALGO11_TENSOR_OP, CUBLAS_GEMM_ALGO12_TENSOR_OP, CUBLAS_GEMM_ALGO13_TENSOR_OP, CUBLAS_GEMM_ALGO14_TENSOR_OP, CUBLAS_GEMM_ALGO15_TENSOR_OP,
其中,帶有_TENSOR_OP后綴的則為調(diào)用tensor core來加速運算的。看到這么多種實現(xiàn),不要慌,通過一個for-loop的遍歷,就可以方便的找到速度最快的那一個,然后對應就可以得到TFLOPS,對應實現(xiàn)如下:
floatmin_time=0xffff; cublasGemmAlgo_talgo_index; for(constauto&algo:algoList){ floattotal_time=0.0; for(inti=0;i(algo)); cudaEventRecord(end,0); cudaEventSynchronize(end); floatelapsed_time; cudaEventElapsedTime(&elapsed_time,start,end); total_time+=elapsed_time; } floatcurrent_time=total_time/iteration; std::cout<
通過CUTLASS實現(xiàn)batch GEMM算子
CUTLASS這里就不花過多的篇幅進行介紹了,知乎上有很多比較詳細的文章,建議做GPU性能優(yōu)化的同學都能夠好好研究下CUTLASS,不得不說,CUTLASS的抽象層級做的確實很好,通過暴露出對應的C++模版,就可以通過這些模版組合成很多工程開發(fā)實際中可以跑的很快的算子,而且相比于直接寫CUDA嵌入PTX的匯編來說,開發(fā)的難易程度也被很大程度的降低,同時能帶來和cuBLAS肩比肩的效果。在本次benchmark的構建中,我使用的是2.9.1版本的CUTLASS,在編譯的時候一定要打開所有的kernel,然后通過下面的命令進行配置:
1.gitclonehttps://github.com/NVIDIA/cutlass.git 2.gitcheckoutv2.9.1 3.exportCUDACXX=/usr/local/cuda/bin/nvcc 4.mkdirbuild&&cdbuild 5.cmake..-DCUTLASS_NVCC_ARCHS=80-DCUTLASS_LIBRARY_KERNELS=all 6.makecutlass_profiler-j16
然后我們可以通過使用cutlass_profiler來找到目前CUTLASS中針對應尺寸算子的TFLOPS最優(yōu)的那個實現(xiàn)。這里直接使用如下代碼就可以得到CUTLASS對應的實現(xiàn),同時只要在對應的workload添加不同尺寸的GEMM。
Triton, CUTLASS, cuBLAS性能對比
通過上述的講解,我們將所有的輸入和計算過程與cublasGemmStridedBatchedEx中的參數(shù)對齊,輸入為fp16,輸出為fp16,Accumulator_type也改為fp16。在triton中需要將如下代碼進行替換:
#acc=tl.zeros((BLOCK_SIZE_M,BLOCK_SIZE_N),dtype=tl.float32) acc=tl.zeros((BLOCK_SIZE_M,BLOCK_SIZE_N),dtype=tl.float16) #acc+=tl.dot(a,b) acc+=tl.dot(a,b,out_dtype=tl.float16)
然后把他們?nèi)慨嫵鰜恚v坐標表示的TFLOPS,橫坐標對應矩陣的shape,batch=16。我們可以看出來,目前我這個版本的tirton代碼其實性能并不是很好,原因有很多,這個后面我給大家慢慢分析,最重要的其實就是triton.autotune中那些參數(shù)的選取和設定,以及后端的一些優(yōu)化。cublasGemmStridedBatchedEx中最快的那個algo可以看出來目前基本上占據(jù)了領先位置,也就是為什么會被稱為目前GPU上去做計算密集型算子優(yōu)化的上屆,CUTLASS在某些尺寸上的batch gemm還是表現(xiàn)的很優(yōu)秀的,但是距離最快的cublasGemmStridedBatchedEx仍然有一些差距,不過只能說CUTLASS的優(yōu)化真的牛逼,至少我知道目前國內(nèi)很多HPC的組在開發(fā)對應的kernel的時候,都是選擇直接魔改拼接CUTLASS的組件來加快整個開發(fā)流程。
img
總結
通過上述對batch gemm性能的分析,我們可以看出來triton距離cuBLAS的性能還有一定的距離要走,在后續(xù)的教程中,我們將結合Triton Dialect, TritonGPU Dialect, 以及Triton中autotuner作為核心組件來對Triton的所有優(yōu)化過程中有一個清晰的認識。以及通過編譯手段,一步一步來逼近cuBLAS的性能,甚至超越他。
審核編輯:彭靜
-
gpu
+關注
關注
28文章
4937瀏覽量
131115 -
源碼
+關注
關注
8文章
671瀏覽量
30290 -
Triton
+關注
關注
0文章
28瀏覽量
7160 -
算子
+關注
關注
0文章
16瀏覽量
7345
原文標題:【連載】OpenAITriton MLIR 第二章 Batch GEMM benchmark
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
請問一下拉普拉斯算子的FPGA實現(xiàn)方法是什么?
LOG算子在FPGA中的實現(xiàn)
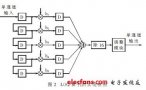
Laplacian算子的FPGA實現(xiàn)方法
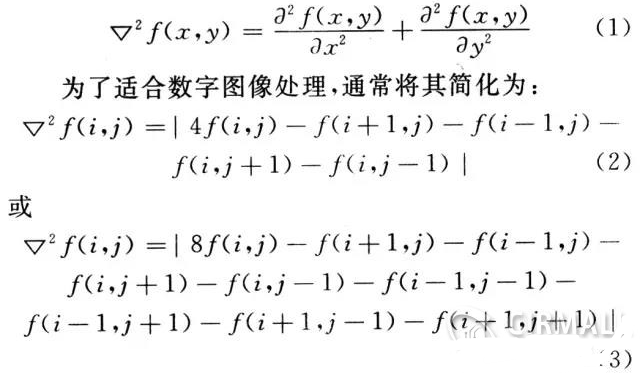
使用CUTLASS實現(xiàn)高性能矩陣乘法
Laplacian算子的硬件實現(xiàn)及結果
Sobel算子原理介紹與實現(xiàn)方法
如何通過ApiFox來構建API場景測試
NVIDIA Triton系列文章:開發(fā)資源說明
解析OneFlow Element-Wise算子實現(xiàn)方法
如何對GPU中的矩陣乘法(GEMM)進行優(yōu)化

什么是Triton-shared?Triton-shared的安裝和使用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論