 ICCV 2023 | 超越SAM!EntitySeg:更少的數據,更高的分割質量
ICCV 2023 | 超越SAM!EntitySeg:更少的數據,更高的分割質量

稠密圖像分割問題一直在計算機視覺領域中備受關注。無論是在 Adobe 旗下的 Photoshop 等重要產品中,還是其他實際應用場景中,分割模型的泛化和精度都被賦予了極高的期望。對于這些分割模型來說,需要在不同的圖像領域、新的物體類別以及各種圖像分辨率和質量下都能夠保持魯棒性。為了解決這個問題,早在 SAM[6] 模型一年之前,一種不考慮類別的實體分割任務 [1] 被提出,作為評估模型泛化能力的一種統一標準。
在本文中,High-Quality Entity Segmentation 對分割問題進行了全新的探索,從以下三個方面取得了顯著的改進:
1. 更優的分割質量:正如上圖所示,EntitySeg 在數值指標和視覺表現方面都相對于 SAM 有更大的優勢。令人驚訝的是,這種優勢是基于僅占訓練數據量千分之一的數據訓練取得的。
2. 更少的高質量數據需求:相較于 SAM 使用的千萬級別的訓練數據集,EntitySeg 數據集僅含有 33,227 張圖像。盡管數據量相差千倍,但 EntitySeg 卻取得了可媲美的性能,這要歸功于其標注質量,為模型提供了更高質量的數據支持。
3. 更一致的輸出細粒度(基于實體標準):從輸出的分割圖中,我們可以清晰地看到 SAM 輸出了不同粒度的結果,包括細節、部分和整體(如瓶子的蓋子、商標、瓶身)。然而,由于 SAM 需要對不同部分的人工干預處理,這對于自動化輸出分割的應用而言并不理想。相比之下,EntitySeg 的輸出在粒度上更加一致,并且能夠輸出類別標簽,對于后續任務更加友好。
在闡述了這項工作對稠密分割技術的新突破后,接下來的內容中介紹 EntitySeg 數據集的特點以及提出的算法 CropFormer。

代碼鏈接:
https://github.com/qqlu/Entity/blob/main/Entityv2/README.md主頁鏈接:
http://luqi.info/entityv2.github.io/根據 Marr 計算機視覺教科書中的理論,人類的識別系統是無類別的。即使對于一些不熟悉的實體,我們也能夠根據相似性進行識別。因此,不考慮類別的實體分割更貼近人類識別系統,不僅可以作為一種更基礎的任務,還可以輔助于帶有類別分割任務 [2]、開放詞匯分割任務 [3] 甚至圖像編輯任務 [4]。與全景分割任務相比,實體分割將“thing”和“stuff”這兩個大類進行了統一,更加符合人類最基本的識別方式。
 ?
?EntitySeg數據集
由于缺乏現有的實體分割數據,作者在其工作 [1] 使用了現有的 COCO、ADE20K 以及 Cityscapes 全景分割數據集驗證了實體任務下模型的泛化能力。然而,這些數據本身是在有類別標簽的體系下標注的(先建立一個類別庫,在圖片中搜尋相關的類別進行定位標注),這種標注過程并不符合實體分割任務的初衷——圖像中每一個區域均是有效的,哪怕這些區域無法用言語來形容或者被 Blur 掉,都應該被定位標注。此外,受限于提出年代的設備,COCO 等數據集的圖片域以及圖片分辨率也相對單一。因此基于現有數據集下訓練出的實體分割模型也并不能很好地體現實體分割任務所帶來的泛化能力。最后,原作者團隊在提出實體分割任務的概念后進一步貢獻了高質量細粒度實體分割數據集 EntitySeg 及其對應方法。EntitySeg 數據集是由 Adobe 公司 19 萬美元贊助標注完成,已經開源貢獻給學術界使用。
項目主頁:
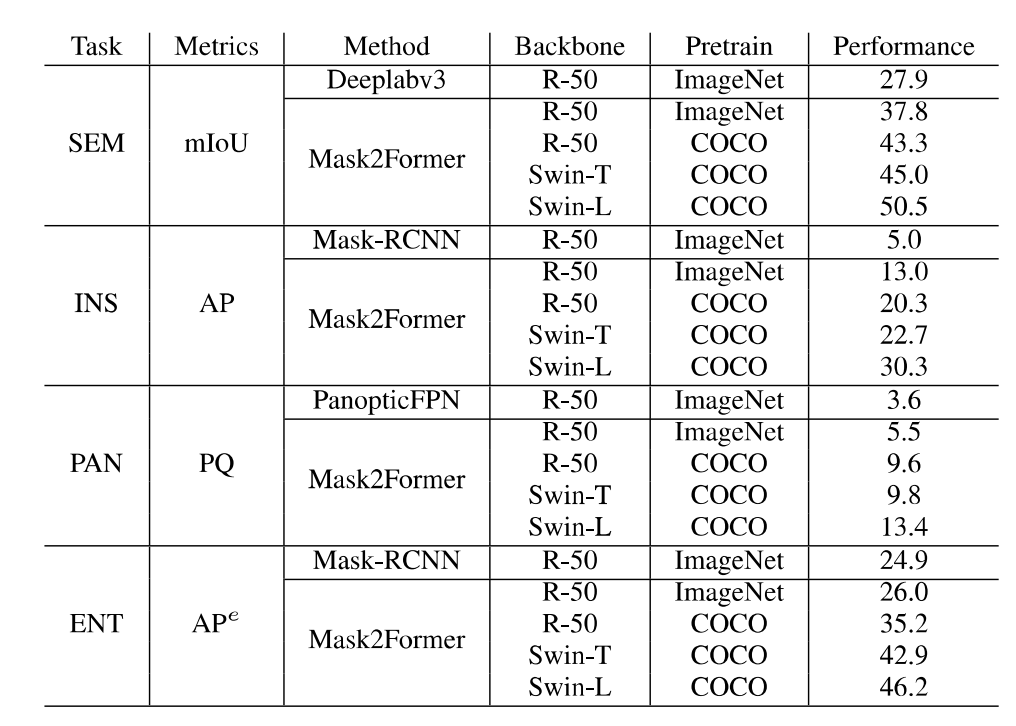
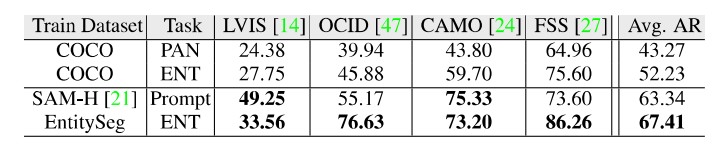
http://luqi.info/entityv2.github.io/數據集有三個重要特性:1. 數據集匯集了來自公開數據集和學術網絡的 33,227 張圖片。這些圖片涵蓋了不同的領域,包括風景、室內外場景、卡通畫、簡筆畫、電腦游戲和遙感場景等。2. 標注過程在無類別限制下進行的掩膜標注,并且可以覆蓋整幅圖像。3. 圖片分辨率更高,標注更精細。如上圖所示,即使相比 COCO 和 ADE20K 數據集的原始低分辨率圖片及其標注,EntitySeg 的實體標注更全且更精細。最后,為了讓 EntitySeg 數據集更好地服務于學術界,11580 張圖片在標注實體掩膜之后,以開放標簽的形式共標注了 643 個類別。EntitySeg、COCO 以及 ADE20K 數據集的統計特性對比如下: 通過和 COCO 以及 ADE20K 的數據對比,可以看出 EntitySeg 數據集圖片分辨率更高(平均圖片尺寸 2700)、實體數量更多(每張圖平均 18.1 個實體)、掩膜標注更為復雜(實體平均復雜度 0.719)。極限情況下,EntitySeg 的圖片尺寸可達到 10000 以上。與 SAM 數據集不同,EntitySeg 更加強調小而精,試圖做到對圖片中的每個實體得到最為精細的邊緣標注。此外,EntitySeg 保留了圖片和對應標注的原始尺寸,更有利于高分辨率分割模型的學術探索。基于 EntitySeg 數據集,作者衡量了現有分割模型在不同分割任務(無類別實體分割,語義分割,實例分割以及全景分割)的性能以及和 SAM 在 zero-shot 實體級別的分割能力。
通過和 COCO 以及 ADE20K 的數據對比,可以看出 EntitySeg 數據集圖片分辨率更高(平均圖片尺寸 2700)、實體數量更多(每張圖平均 18.1 個實體)、掩膜標注更為復雜(實體平均復雜度 0.719)。極限情況下,EntitySeg 的圖片尺寸可達到 10000 以上。與 SAM 數據集不同,EntitySeg 更加強調小而精,試圖做到對圖片中的每個實體得到最為精細的邊緣標注。此外,EntitySeg 保留了圖片和對應標注的原始尺寸,更有利于高分辨率分割模型的學術探索。基于 EntitySeg 數據集,作者衡量了現有分割模型在不同分割任務(無類別實體分割,語義分割,實例分割以及全景分割)的性能以及和 SAM 在 zero-shot 實體級別的分割能力。
 ?
?CropFormer算法框架
除此之外,高分辨率圖片和精細化掩膜給分割任務帶來了新的挑戰。為了節省硬件內存需求,分割模型需要壓縮高分辨率圖片及標注進行訓練和測試進而導致分割質量的降低。為了解決這一問題,作者提出了 CropFormer 框架來解決高分辨率圖片分割問題。CropFormer 受到 Video-Mask2Former [5] 的啟發, 利用一組 query 連結壓縮為低分辨率的全圖和保持高分辨率的裁剪圖的相同實體。因此,CropFormer 可以同時保證圖片全局和區域細節屬性。CropFormer 是根據 EntitySeg 高質量數據集的特點提出的針對高分辨率圖像的實例/實體分割任務的 baseline 方法,更加迎合當前時代圖片質量的需求。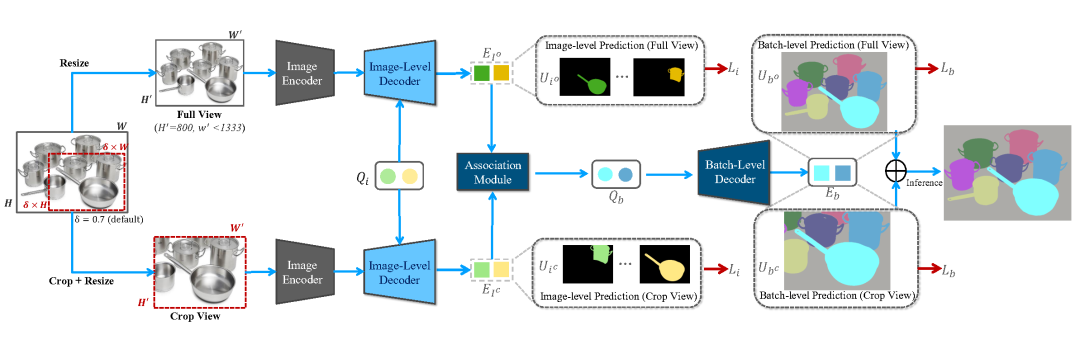
最后在補充材料中,作者展示了更多的 EntitySeg 數據集以及 CropFormer 的可視化結果。下圖為更多數據標注展示:
下圖為 CropFormer 模型測試結果:
參考文獻
[1] Open-World Entity Segmentation. TAPMI 2022.[2] CA-SSL: Class-agnostic Semi-Supervised Learning for Detection and Segmentation. ECCV 2022.[3] Open-Vocabulary Panoptic Segmentation with MaskCLIP. ICML 2023.[4] SceneComposer: Any-Level Semantic Image Synthesis. CVPR 2023.[5] Masked-attention Mask Transformer for Universal Image Segmentation. CVPR 2022.[6] Segment Anything. ICCV 2023.
-
物聯網
+關注
關注
2929文章
46052瀏覽量
389858
原文標題:ICCV 2023 | 超越SAM!EntitySeg:更少的數據,更高的分割質量
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄






 工商網監
工商網監
評論