 基于ICL范式的LLM的最高置信度預測方案
基于ICL范式的LLM的最高置信度預測方案

作者:cola
雖然大多數現有的LLM提示工程只專注于如何在單個提示輸入中選擇一組更好的數據樣本(In-Context Learning或ICL),但為什么我們不能設計和利用多個提示輸入來進一步提高LLM性能?本文提出上下文采樣(ICS),一種低資源LLM提示工程技術,通過優化多個ICL提示輸入的結構來產生最有置信度的預測結果。
介紹
指令微調的LLMs,如Flan-T5、LLaMA和Mistral展示了通用的自然語言理解(NLI)和生成(NLG)能力。然而,解決實際任務需要廣泛的領域專業知識,這對LLM來說仍然具有挑戰性。研究人員提出了各種激勵策略來探索LLM的能力。一個突出的方法是少樣本上下文學習(ICL),通過向提示輸入插入一些數據示例,特別是對未見任務的能力提高了LLM的任務解釋和解決能力。最近的幾項工作研究了不同ICL設置的影響,包括數量、順序和組合。然而,最好的ICL策略還沒有共識。
本文假設不同的ICL為LLM提供了關于任務的不同知識,導致對相同數據的不同理解和預測。因此,一個直接的研究問題出現了:llm能否用多個ICL提示輸入來增強,以提供最可信的預測?為解決這個問題,本文提出上下文采樣(ICS)。ICS遵循三步流程:采樣、增強和驗證,如圖1所示。
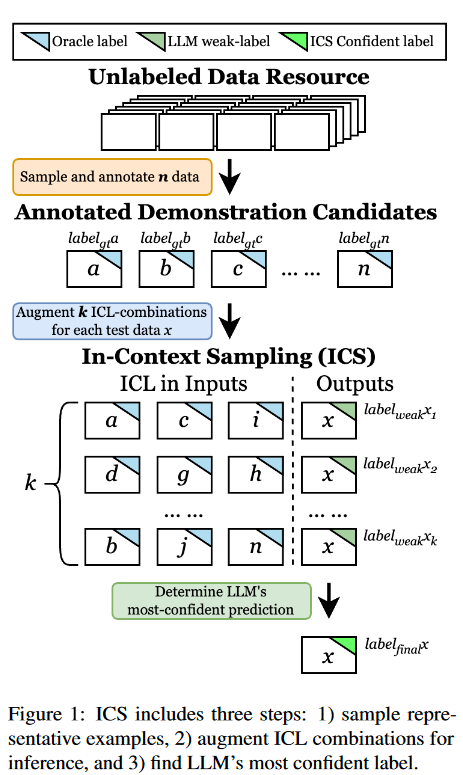
ICS策略
給定一個自然語言任務指令和一個數據,指令微調的SOTA可以接受輸入,生成一個輸出,其中表示上下文中的注釋示例,是預測結果。
示例可以為LLM提供:
直接理解任務指令(I)和預期輸出
間接指導如何解決任務。
本文假設不同的ICL示例集為LLM提供了關于該任務的不同知識。因此,LLM可以根據不同的ICL提示輸入改變對相同數據的預測,但預測的變化最終將收斂到一個最可信的預測。
ICS的框架如圖1所示。
從未標記的數據池中采樣示例候選集并獲取注釋,
用不同的ICL組合增加標簽,
驗證置信度最高的標簽作為增強標簽的最終預測。
ICS方法是模型無關的且“即插即用”,可以以最小的工作量切換到不同的采樣、增強和驗證算法。
示例候選集采樣
從許多未標記的數據中采樣少量數據作為ICL示例,通常分為兩種類型:基于數據多樣性和基于模型概率。我們的策略堅持基于集群的策略(即核心集),旨在識別代表所有未標記數據的示例,同時最大化這些選定實例的多樣性。該策略用句子轉換器編碼計算每個數據的余弦相似度,其中embed表示句Transformer Embedding。然后,根據相似度得分對候選樣本進行排序,并檢索個相同間隔的樣本集,以保證樣本集的多樣性。本文試圖確定樣本量和增強的ICL組合數量,在下面三個角度上取得平衡:
包含足夠的多樣性充分表示基礎數據,
置信預測具有魯棒性,
最小化注釋成本。
ICL組合增強
如圖1所示,ICS通過為要預測的相同數據構建不同的ICL組合來增強標簽,然后獲得所有標簽中置信度最高的標簽。然而,如果要求LLM預測候選的每個組合,計算量可能會很大。我們認為,ICS不需要每個ICL組合來找到模型的最可信的標簽。類似于人類投票,少數代表代表更多的人口投票,我們計劃調查合理數量的“代表”,即及時的輸入。用一個隨機和基于數據多樣性的算法作為基準,用于示例增強,并研究了策略差異的影響。兩種方法都是從候選列表中迭代采樣次,其中基于多樣性的增強策略使用上述策略。然后對相同的測試數據查詢LLM次,得到個弱標簽,記為。
置信標簽驗證
既然我們從上述ICS步驟中獲得了一組標簽,就可以應用一些驗證算法來找到置信度最高的標簽,獲得了最可信的預測。可以想象ICL有潛力提供模型可信的無監督標簽,以在資源匱乏的場景中迭代地微調LLM,這些場景中專家注釋難以訪問且昂貴。
實驗
實驗設置
采用了兩個SOTA LLMs FLAN-T5-XL和Mistral,并在三個難度越來越大的NLI任務上進行實驗:eSNLI、Multi-NLI和ANLI。排除了LLaMA-2的原因是初步實驗顯示了LLaMA-2在“中性”類別上有過擬合問題。我們使用vanilla ICL作為基線。利用隨機抽樣來構建基礎ICS策略的ICS提示輸入,并使用多數代表方法來找到最可信的標簽。對每個提示輸入使用3個示例。操作ICS的兩個控制變量:采樣的代表性數據的大小,其中,以及每個待預測數據的增強示例組合的數量,其中,其中是ICL基線。對于真實場景,500個注釋是一個合理的預算。在10次試驗中取平均值。
對LLaMA-2進行分析
利用三種不同的自然語言指令,在ANLI上對LLaMA-2進行初始推理實驗:
確定一個假設是否是蘊涵的,中性的,矛盾的前提。
將一對前提和假設句分為三類:蘊涵句、中性句、矛盾句。
通過蘊涵、中性、矛盾來預測前提和假設之間的關系。
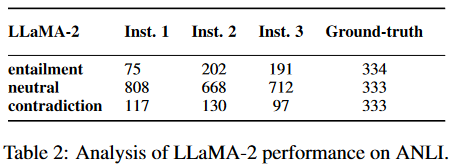
結果如表2所示,我們可以很容易地觀察到,盡管改變了指令,LLaMA-2傾向于過度預測其他兩個類別的"中性",而真實分布是跨類別的。因此,我們在工作中省略了LLaMA-2。可能有不同的原因導致了這個問題;例如,LLaMA-2對NLI任務或共享同一組目標類別("蘊含"、"中性"和"矛盾")的類似任務進行了過擬合。
實驗結果
在圖2中,我們展示了時,基線ICL和我們的ICS策略對每個模型和數據集的預測精度。基線和我們的策略之間的標準差變化也用右縱軸的虛線表示。以隨機采樣策略為基準的ICS策略,可以不斷提高LLM在每個組合中的預測性能,證明了所提出的ICS管道的有效性。
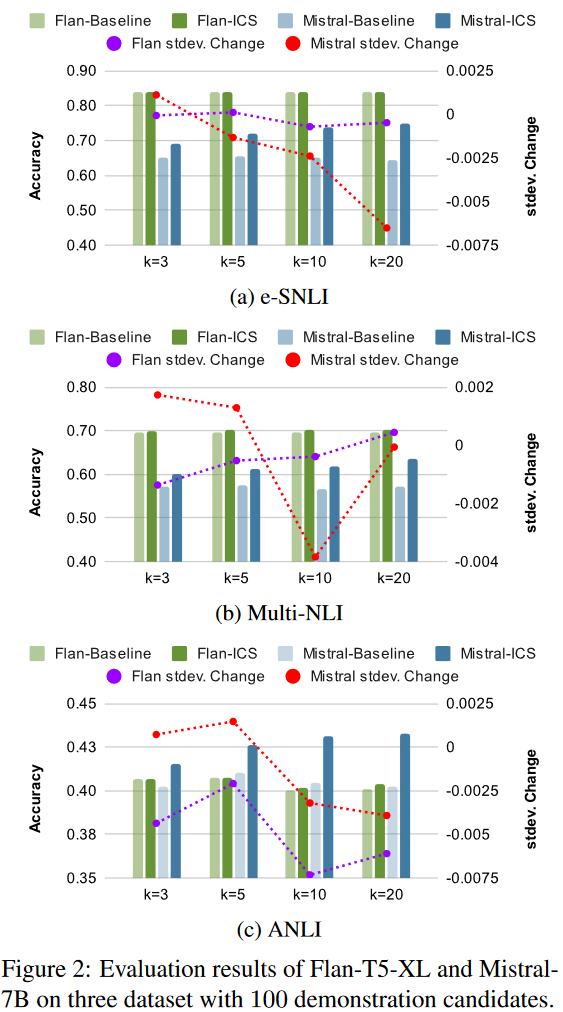
此外,我們觀察到LLM對ICS有明顯的敏感性。具體來說,對于Flan-T5來說,ICS策略提供的精度提升遠小于Mistral,這可以歸因于Flan-T5可能會過擬合我們實驗的三個數據集或NLI任務。另一方面,Mistral證明了ICS策略對準確性的顯著提升,在所有數據集上的平均提升超過5%。當時,兩個模型的標準偏差減少得最多,當超過10時,增加的提供的性能改善開始逐漸減少。對于示例候選采樣,一旦超過100,精度的提高就不顯著。樣本量超過100可以被認為具有足夠的多樣性和代表性。
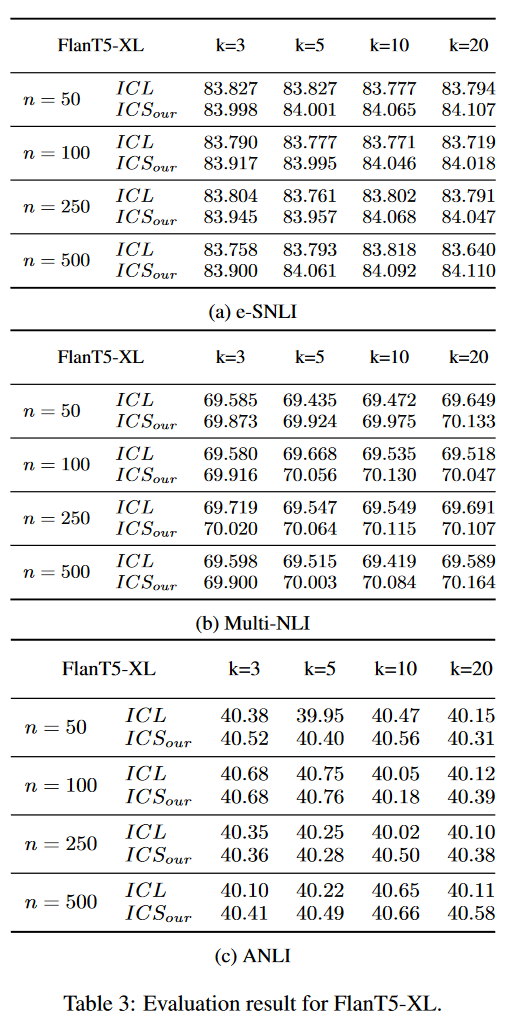
表3和表4報告了對FlanT5XL和Mistral-7b的完整評估結果。
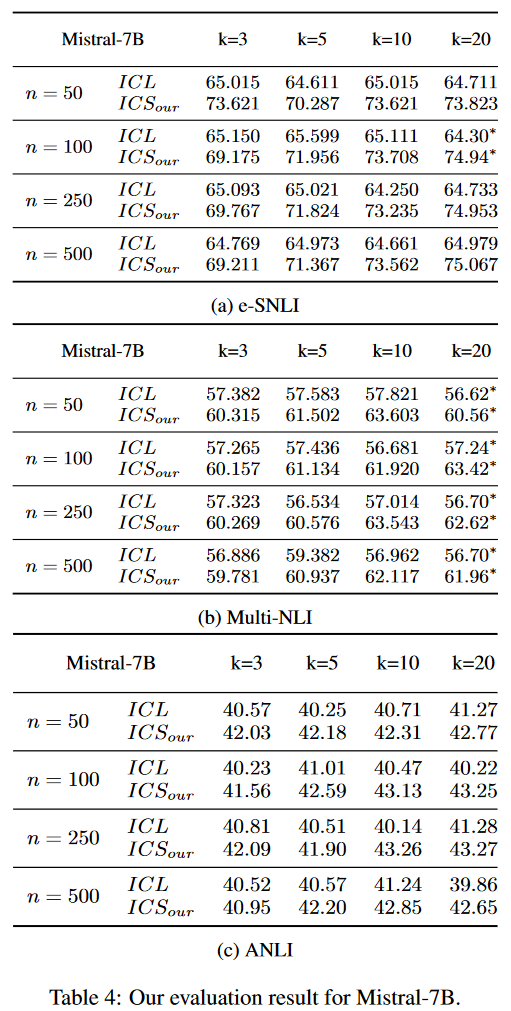
消融實驗
使用Mistral-7B和性能最佳的設置:和。從3個NLI數據集中隨機采樣3000和1000數據作為訓練集和測試集。我們共進行了4種情況下的10次試驗,記為組合策略,其中RD為隨機策略,DS為基于數據相似性的策略。實驗結果如表1所示:
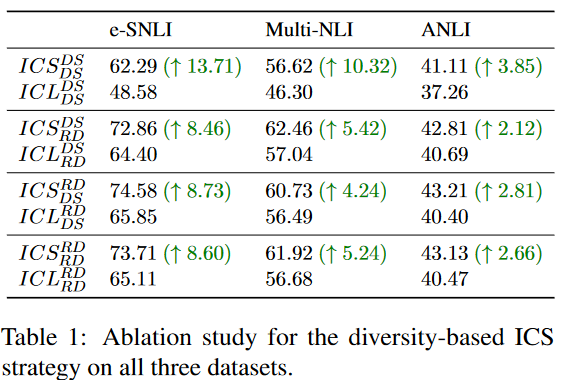
基于多樣性的示例候選采樣和組合增強策略可以有效提高ICL的性能。
總結
本文提出上下文采樣(ICS),一種新的基于ICL的范式,用于探測LLM的最高置信度預測。實驗結果表明,與傳統的ICL方法相比,ICS方法提高了ICL的準確性,降低了標準偏差。還研究了不同樣本數量和ICL組合量的影響,然后進一步進行消融實驗,以說明基于ICS簡單但有效的數據多樣性采樣策略的有用性。
限制
本文的主要重點是提出并證明ICS的有效性。然而,盡管對不同的和組合進行了廣泛的實驗,但仍有幾個潛在變量需要進一步分析。例如,盡管我們考慮了3個不同難度的數據集,并且每個ICL組合是任意的,但3個數據集都是NLI任務。此外,只進行了一項基于數據多樣性的候選采樣和組合增強策略的小規模消融研究。并且我們的實驗原本打算由三個SOTA LLM組成,但由于LLaMA-2傾向于預測“中性”類別,因此不包括它。我們仍有各種其他的指令微調LLM沒有包括在這項工作中,如InstructGPT。
審核編輯:黃飛
-
轉換器
+關注
關注
27文章
9015瀏覽量
151412 -
Sample
+關注
關注
0文章
11瀏覽量
8923 -
自然語言
+關注
關注
1文章
291瀏覽量
13633 -
prompt
+關注
關注
0文章
15瀏覽量
2764 -
LLM
+關注
關注
1文章
324瀏覽量
793
原文標題:ICL的時候,更多sample好還是更多prompt好呢?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用NVIDIA Triton和TensorRT-LLM部署TTS應用的最佳實踐

詳解 LLM 推理模型的現狀

無法在OVMS上運行來自Meta的大型語言模型 (LLM),為什么?
傳感器仿真模型的可信度評估方案
小白學大模型:構建LLM的關鍵步驟
什么是LLM?LLM在自然語言處理中的應用
如何訓練自己的LLM模型
LLM技術對人工智能發展的影響
LLM和傳統機器學習的區別
端到端InfiniBand網絡解決LLM訓練瓶頸






 工商網監
工商網監
評論