首先,Karpathy 認為,Tokenization 引入了復雜性:通過使用 tokenizati....
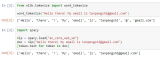
援引自 mPLUG-Owl,這三個工作的主要區別如圖 1 所示,總體而言,模型結構和訓練策略方面大同....
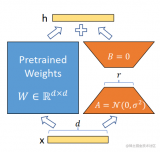
在推理時,將左右兩部分的結果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要將訓練完成的矩....
通過我們的VPGTrans框架可以根據需求為各種新的大語言模型靈活添加視覺模塊。比如我們在LLaMA....

以ChatGPT為代表的大語言模型(Large Language Models, LLM)在機器翻譯....

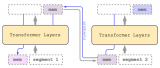
CoLT5達到64K,GPT-4達到32K長度,而RMT在實驗結果中長度加到4096個分段20480....
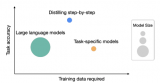
為優化LLM為“小模型/少數據/好效果”,提供了一種新思路:”一步步蒸餾”(Distilling s....
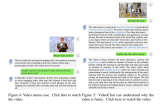
區別于現有多模態大模型針對視頻輸入的處理方法,即首先文本化視頻內容再接入大模型利用大模型自然語言理解....
縮放定律的一個重要作用就是預測模型的性能,但是隨著規模的擴大,模型的能力在不同的任務上并不總表現出相....

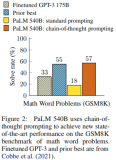
結果表明,GP-T-4+PHP 在多個數據集上取得了 SOTA 結果,包括 SVAMP (91.9%....

如果經過多任務微調,編碼器-解碼器掩碼模型最好【這參數量都翻倍了,很難說不是參數量加倍導致的】。換個....
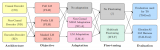
這項工作是對齊研究方法的第三個支柱的一部分:希望使對齊研究工作本身自動化。這種方法的一個有前途的方面....

添加關鍵字過濾器是增強檢索結果的一種方法。但這也帶來了一系列挑戰。我們需要手動或通過 NLP 關鍵字....
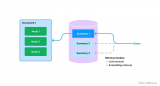
基于開源多模態模型 OpenFlamingo,作者使用公開數據集創建了各種視覺指令數據,包括視覺問答....

大型語言模型LLM(Large Language Model)具有很強的通用知識理解以及較強的邏輯推....
因此,對于ChatGPT的評測方面,不止需要關注給定下游任務的性能評測,同時還需要考慮到使用大模型過....

近來NLP領域由于語言模型的發展取得了顛覆性的進展,擴大語言模型的規模帶來了一系列的性能提升,然而單....
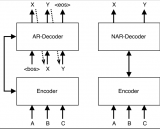
雖然GPT模型在自然語言處理領域中表現出色,但是它們仍然存在一些問題。例如,GPT模型的自回歸設計導....
從信息論的角度來看,具有保持信息多樣性能力的隨機dropping方法比沒有這種能力的能保存更多的信息....
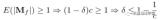
神經網絡在訓練的時候,采用的隨機梯度下降算法,一定程度上等效于物種的基因突變,本質是有一定方向的隨機....
通用計算機的誕生對社會生產力的提升意義重大。學習寫代碼比學習開發邏輯電路要簡單太多了。普通人經過一段....

復旦大學自然語言處理實驗室,自2019年起,自研了PDF處理工具DocAI,針對非掃描件PDF,具有....
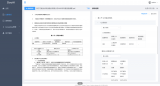
Instruct-UIE 統一了信息抽取任務訓練方法,可以融合不同類型任務以及不同的標注規范,統一進....

另一方面,根據Moors等人[8],人類的感覺和行動傾向是情緒的兩個重要組成部分,并在很大程度上為目....
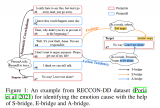
隨著大規模預訓練語言模型(LLM)能力的不斷提升,in-context learning(ICL)逐....
基礎 LLM 基本信息表,GPT-style 表示 decoder-only 的自回歸語言模型,T5....
同樣的,使用這些低資源語言的研究人員在ML和NLP社區中的代表性同樣不足。例如,雖然我們可以觀察到隸....
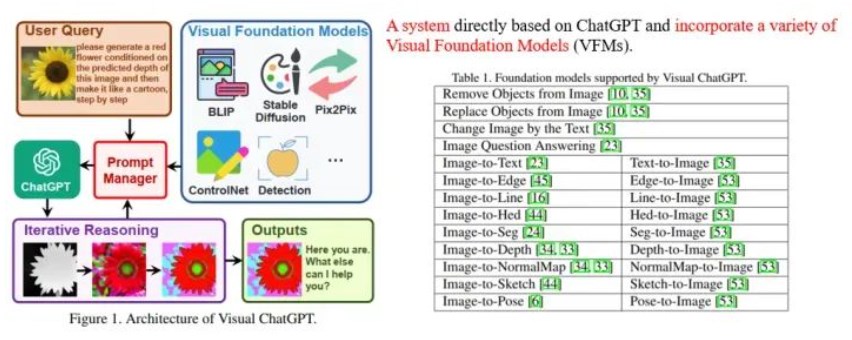
Visual ChatGPT 是一種智能交互系統,它將不同的視覺基礎模型與 ChatGPT 相結合,....
在本文中,我們將展示如何使用 大語言模型低秩適配 (Low-Rank Adaptation of L....
提出了一個簡單有效的視覺語言模型架構,BridgeTower,通過在頂層單模態層和每個跨模態層之間建....





 工商網監
工商網監