 電子發(fā)燒友App
電子發(fā)燒友App


1 摘要
自 OpenAI 發(fā)布 ChatGPT 以來,基于 Transformer 架構(gòu)的大語言模型 (LLM) 在全球范圍內(nèi)引發(fā)了深度的技術(shù)關(guān)注,并取得了令人矚目的成就。其強大的理解和生成能力,正在深刻改變我們對人工智能的認(rèn)知和應(yīng)用。然而大語言模型的推理應(yīng)用成本過高,高昂的成本大大阻礙了技術(shù)落地。因此,大語言模型的推理性能優(yōu)化成為業(yè)界研究的熱點。
大語言模型推理面臨計算資源的巨大需求和計算效率的挑戰(zhàn)。優(yōu)化推理性能不僅可以減少硬件成本,還可以提高模型的實時響應(yīng)速度。它使模型能夠更快速地執(zhí)行自然語言理解、翻譯、文本生成等任務(wù),從而改善用戶體驗,加速科學(xué)研究,推動各行業(yè)應(yīng)用的發(fā)展。
本文從推理服務(wù)系統(tǒng)全局視角介紹典型性能優(yōu)化技術(shù)和各自特點,最后分析未來大語言模型推理優(yōu)化技術(shù)的發(fā)展趨勢和演進方向,最終為未來的人工智能應(yīng)用打開更廣闊的可能性。
2 優(yōu)化技術(shù)
LLM 推理服務(wù)重點關(guān)注兩個指標(biāo):吞吐量和時延:
吞吐量:主要從系統(tǒng)的角度來看,即系統(tǒng)在單位時間內(nèi)能處理的 tokens 數(shù)量。計算方法為系統(tǒng)處理完成的 tokens 個數(shù)除以對應(yīng)耗時,其中 tokens 個數(shù)一般指輸入序列和輸出序列長度之和。吞吐量越高,代表 LLM 服務(wù)系統(tǒng)的資源利用率越高,對應(yīng)的系統(tǒng)成本越低。
時延:主要從用戶的視角來看,即用戶平均收到每個 token 所需位時間。計算方法為用戶從發(fā)出請求到收到完整響應(yīng)所需的時間除以生成序列長度。一般來講,當(dāng)時延不大于 50 ms/token 時,用戶使用體驗會比較流暢。
吞吐量關(guān)注系統(tǒng)成本,高吞吐量代表系統(tǒng)單位時間處理的請求大,系統(tǒng)利用率高。時延關(guān)注用戶使用體驗,即返回結(jié)果要快。這兩個指標(biāo)一般情況下需要會相互影響,因此需要權(quán)衡。例如,提高吞吐量的方法一般是提升 batchsize,即將用戶的請求由串行改為并行。但 batchsize 的增大會在一定程度上損害每個用戶的時延,因為以前只計算一個請求,現(xiàn)在合并計算多個請求,每個用戶等待的時間變長。
LLM 推理性能優(yōu)化主要以提高吞吐量和降低時延為目的,具體可以劃分為如下六部分,下面詳細(xì)展開描述。
2.1 顯存相關(guān)優(yōu)化
2.1.1 KV Cache
大模型推理性能優(yōu)化的一個最常用技術(shù)就是 KV Cache,該技術(shù)可以在不影響任何計算精度的前提下,通過空間換時間思想,提高推理性能。目前業(yè)界主流 LLM 推理框架均默認(rèn)支持并開啟了該功能。
Transformer 模型具有自回歸推理的特點,即每次推理只會預(yù)測輸出一個 token,當(dāng)前輪輸出token 與歷史輸入 tokens 拼接,作為下一輪的輸入 tokens,反復(fù)執(zhí)行多次。該過程中,前后兩輪的輸入只相差一個 token,存在重復(fù)計算。KV Cache 技術(shù)實現(xiàn)了將可復(fù)用的鍵值向量結(jié)果保存下來,從而避免了重復(fù)計算。
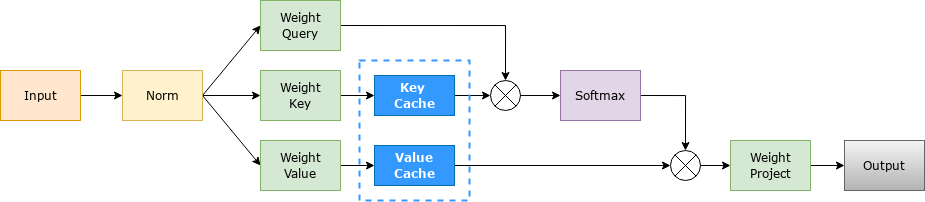
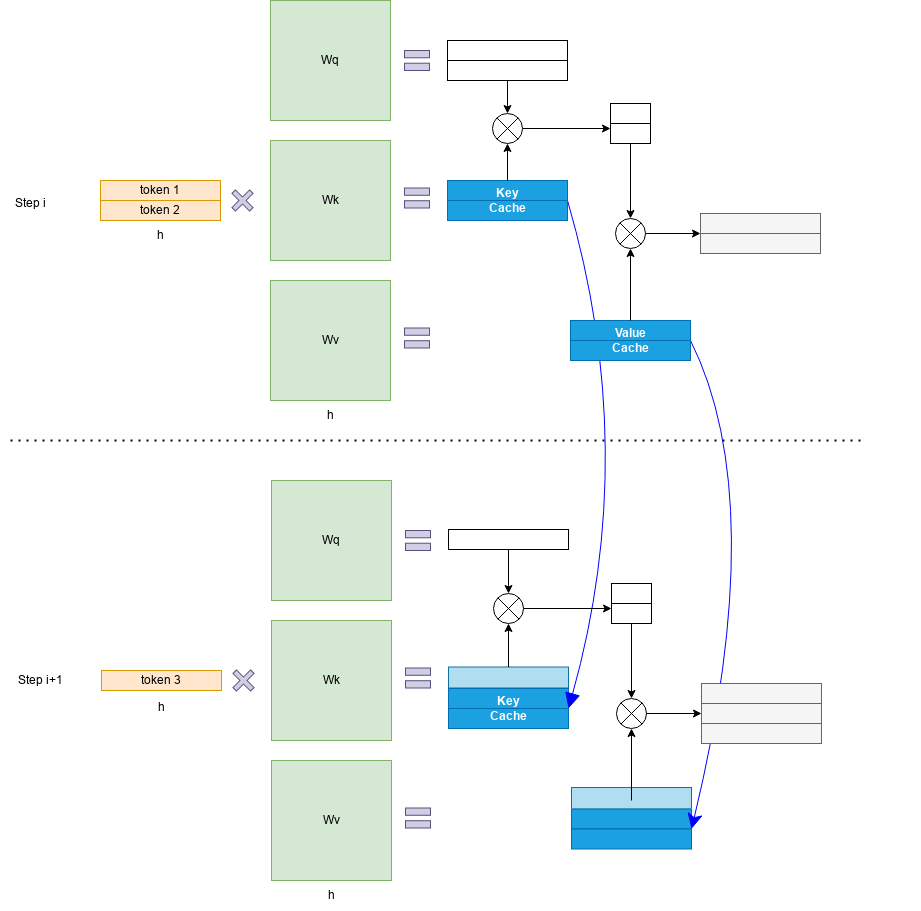
具體來講,KV Cache 技術(shù)是指每次自回歸推理過程中,將 Transformer 每層的 Attention 模塊中的 和 結(jié)果保存保存在一個數(shù)據(jù)結(jié)構(gòu)(稱為 KV Cache)中,當(dāng)執(zhí)行下一次自回歸推理時,直接將 和 與 KV Cache 拼接在一起,供后續(xù)計算使用。其中, 代表第 步推理的輸入, 和 分別代表鍵值權(quán)重矩陣。
KV Cache 緩存每一輪已計算完畢的鍵值向量,因此會額外增加顯存開銷。以 LLaMA-7B 模型為例,每個 token 對應(yīng)的 KV Cache 空間 可通過如下公式計算:

公式中第一個因子 2 代表 Key/Value 兩個向量,每層都需存儲這兩個向量, 為 Transformer layer 個數(shù), 代表 KV head 個數(shù)(模型為多頭注意力時,該值即注意力頭數(shù),模型為多查詢注意力時,該值為 1), 為每個 KV head 的維度, 為每存放一個數(shù)據(jù)所需的字節(jié)數(shù)。模型推理所需的 KV Cache 總量為公式 如下,其中 為輸入和輸出序列長度之和。因此,KV Cache 與 batchsize 和序列長度呈線性關(guān)系。
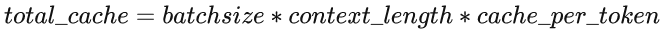
KV Cache 的引入也使得推理過程分為如下兩個不同階段,進而影響到后續(xù)的其他優(yōu)化方法。
預(yù)填充階段:發(fā)生在計算第一個輸出 token 過程中,計算時需要為每個 Transformer layer 計算并保存 key cache 和 value cache;FLOPs 同 KV Cache 關(guān)閉一致,存在大量 GEMM (GEneral Matrix-Matrix multiply) 操作,屬于 Compute-bound 類型計算。
解碼階段:發(fā)生在計算第二個輸出 token 至最后一個 token 過程中,這時 KV Cache 已存有歷史鍵值結(jié)果,每輪推理只需讀取 Cache,同時將當(dāng)前輪計算出的新的 Key、Value 追加寫入至 Cache;GEMM 變?yōu)?GEMV (GEneral Matrix-Vector multiply) 操作,F(xiàn)LOPs 降低,推理速度相對預(yù)填充階段變快,這時屬于 Memory-bound 類型計算。
2.1.2 Paged Attention
LLM 推理服務(wù)的吞吐量指標(biāo)主要受制于顯存限制。研究團隊發(fā)現(xiàn)現(xiàn)有系統(tǒng)由于缺乏精細(xì)的顯存管理方法而浪費了 60% 至 80% 的顯存,浪費的顯存主要來自 KV Cache。因此,有效管理 KV Cache 是一個重大挑戰(zhàn)。
在 Paged Attention 之前,業(yè)界主流 LLM 推理框架在 KV Cache 管理方面均存在一定的低效。HuggingFace Transformers 庫中,KV Cache 是隨著執(zhí)行動態(tài)申請顯存空間,由于 GPU顯存分配耗時一般都高于 CUDA kernel 執(zhí)行耗時,因此動態(tài)申請顯存空間會造成極大的時延開銷,且會引入顯存碎片化。FasterTransformer 中,預(yù)先為 KV Cache 分配了一個充分長的顯存空間,用于存儲用戶的上下文數(shù)據(jù)。例如 LLaMA-7B 的上下文長度為 2048,則需要為每個用戶預(yù)先分配一個可支持 2048 個 tokens 緩存的顯存空間。如果用戶實際使用的上下文長度低于2048,則會存在顯存浪費。Paged Attention 將傳統(tǒng)操作系統(tǒng)中對內(nèi)存管理的思想引入 LLM,實現(xiàn)了一個高效的顯存管理器,通過精細(xì)化管理顯存,實現(xiàn)了在物理非連續(xù)的顯存空間中以極低的成本存儲、讀取、新增和刪除鍵值向量。
具體來講,Paged Attention 將每個序列的 KV Cache 分成若干塊,每個塊包含固定數(shù)量token 的鍵和值。
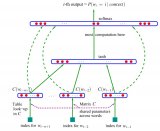
首先在推理實際任務(wù)前,會根據(jù)用戶設(shè)置的和 預(yù)跑一次推理計算,記錄峰值顯存占用量 ,然后根據(jù)上面公式獲得當(dāng)前軟硬件環(huán)境下 KV Cache 可用的最大空間,并預(yù)先申請緩存空間。其中,為部署環(huán)境的硬件顯存一次最多能容納的 token 總量, 為模型推理的最大顯存占用比例, 為物理顯存量, 為塊大小(默認(rèn)設(shè)為 16)。
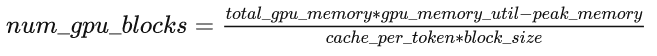
在實際推理過程中,維護一個邏輯塊到物理塊的映射表,多個邏輯塊可以對應(yīng)一個物理塊,通過引用計數(shù)來表示物理塊被引用的次數(shù)。當(dāng)引用計數(shù)大于一時,代表該物理塊被使用,當(dāng)引用計數(shù)等于零時,代表該物理塊被釋放。通過該方式即可實現(xiàn)將地址不連續(xù)的物理塊串聯(lián)在一起統(tǒng)一管理。
Paged Attention 技術(shù)開創(chuàng)性地將操作系統(tǒng)中的分頁內(nèi)存管理應(yīng)用到 KV Cache 的管理中,提高了顯存利用效率。另外,通過 token 塊粒度的顯存管理,系統(tǒng)可以精確計算出剩余顯存可容納的 token 塊的個數(shù),配合后文 Dynamic Batching 技術(shù),即可避免系統(tǒng)發(fā)生顯存溢出的問題。
2.2 計算相關(guān)優(yōu)化
2.2.1 算子融合
算子融合是深度學(xué)習(xí)模型推理的一種典型優(yōu)化技術(shù),旨在通過減少計算過程中的訪存次數(shù)和 Kernel 啟動耗時達到提升模型推理性能的目的,該方法同樣適用于 LLM 推理。
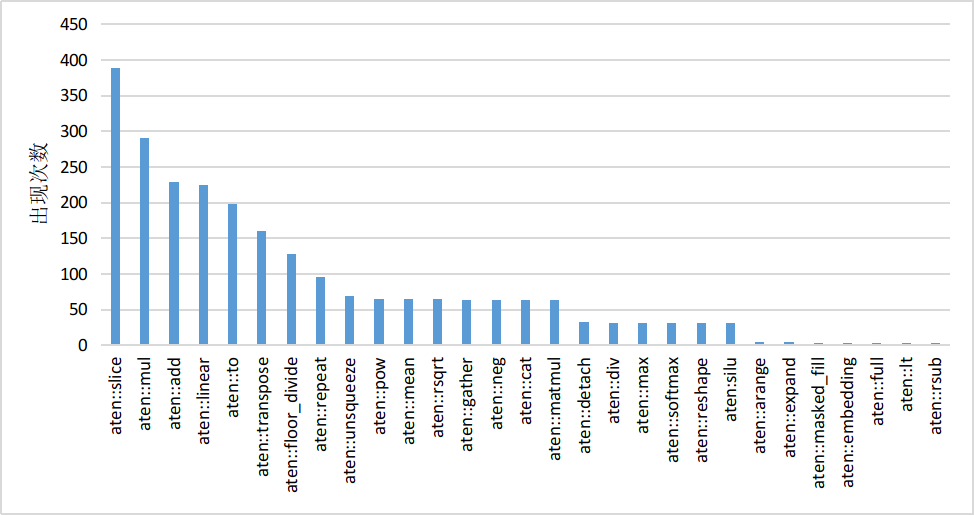
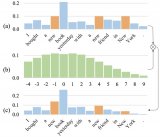
以 HuggingFace Transformers 庫推理 LLaMA-7B 模型為例,經(jīng)分析模型推理時的算子執(zhí)行分布如下圖所示,該模型有 30 個類型共計 2436 個算子,其中 aten::slice 算子出現(xiàn)頻率為 388 次。大量小算子的執(zhí)行會降低 GPU 利用率,最終影響推理速度。
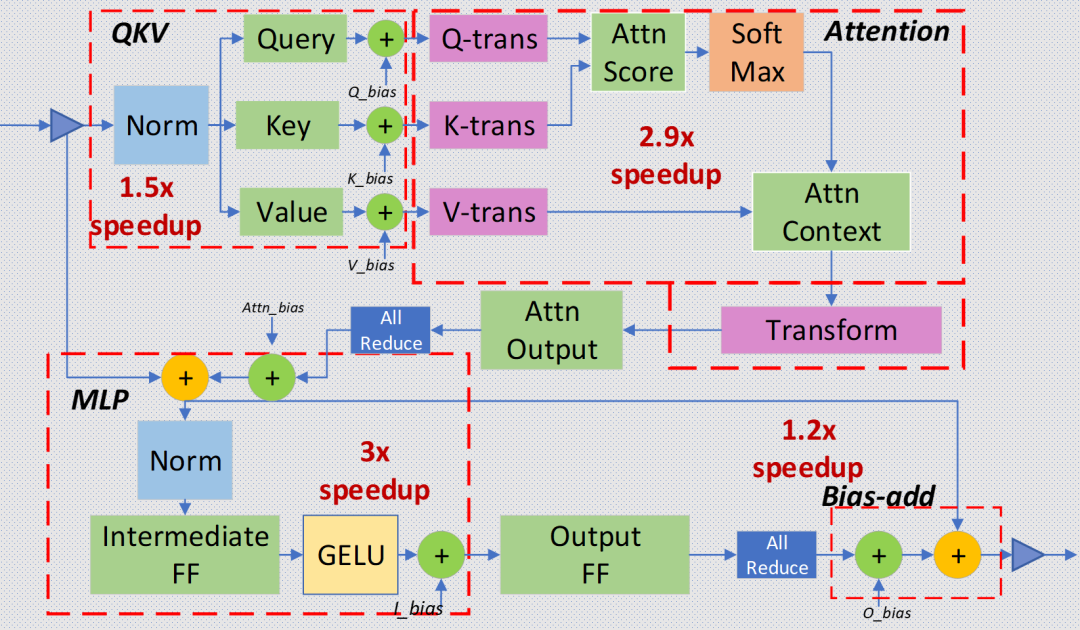
目前業(yè)界基本都針對 Transformer layer 結(jié)構(gòu)特點,手工實現(xiàn)了算子融合。以 DeepSpeed Inference 為例,算子融合主要分為如下四類:
歸一化層和 QKV 橫向融合:將三次計算 Query/Key/Value 的操作合并為一個算子,并與前面的歸一化算子融合。
自注意力計算融合:將自注意力計算涉及到的多個算子融合為一個,業(yè)界熟知的 FlashAttention 即是一個成熟的自注意力融合方案。
殘差連接、歸一化層、全連接層和激活層融合:將 MLP 中第一個全連接層上下相關(guān)的算子合并為一個。
偏置加法和殘差連接融合。
由于算子融合一般需要定制化實現(xiàn)算子 CUDA kernel,因此對 GPU 編程能力要求較高。隨著編譯器技術(shù)的引入,涌現(xiàn)出 OpenAI Triton 、TVM 等優(yōu)秀的框架來實現(xiàn)算子融合的自動化或半自動化,并取得了一定的效果。
2.2.2 高性能算子
針對 LLM 推理運行熱點函數(shù)編寫高性能算子,也可以降低推理時延。
GEMM 操作相關(guān)優(yōu)化:在 LLM 推理的預(yù)填充階段,Self-Attention 和 MLP 層均存在多個 GEMM 操作,耗時占據(jù)了推理時延的 80% 以上。GEMM 的 GPU 優(yōu)化是一個相對古老的問題,在此不詳細(xì)展開描述算法細(xì)節(jié)。英偉達就該問題已推出 cuBLAS、CUDA、CUTLASS 等不同層級的優(yōu)化方案。例如,F(xiàn)asterTransformer 框架中存在大量基于 CUTLASS 編寫的 GEMM 內(nèi)核函數(shù)。另外,Self-Attention 中存在 GEMM+Softmax+GEMM 結(jié)構(gòu),因此會結(jié)合算子融合聯(lián)合優(yōu)化。
GEMV 操作相關(guān)優(yōu)化:在 LLM 推理的解碼階段,運行熱點函數(shù)由 GEMM 變?yōu)?GEMV。相比 GEMM,GEMV 的計算強度更低,因此優(yōu)化點主要圍繞降低訪存開銷開展。
高性能算子的實現(xiàn)同樣對 GPU 編程能力有較高要求,且算法實現(xiàn)中的若干超參數(shù)與特定問題規(guī)模相關(guān)。因此,編譯器相關(guān)的技術(shù)如自動調(diào)優(yōu)也是業(yè)界研究的重點。
2.3 服務(wù)相關(guān)優(yōu)化
服務(wù)相關(guān)優(yōu)化主要包括 Continuous Batching、Dynamic Batching 和 異步 Tokenize / Detokenize。其中 Continuous Batching 和 Dynamic Batching 主要圍繞提高可并發(fā)的 batchsize 來提高吞吐量,異步 Tokenize / Detokenize 則通過多線程方式將 Tokenize / Detokenize 執(zhí)行與模型推理過程時間交疊,實現(xiàn)降低時延目的。
?
| 問題分類 | 現(xiàn)象 | 解決方法 | 實現(xiàn)原理 | 特點 |
|---|---|---|---|---|
| 問題一 | 同批次序列推理時,存在“氣泡”,導(dǎo)致 GPU 資源利用率低 | Continuous Batching | 由 batch 粒度的調(diào)度細(xì)化為 step 級別的調(diào)度 | 在時間軸方向動態(tài)插入新序列 |
| 問題二 | 批次大小固定不變,無法隨計算資源負(fù)載動態(tài)變化,導(dǎo)致 GPU 資源利用率低 | Dynamic Batching | 通過維護一個作業(yè)隊列實現(xiàn) | 在 batch 維度動態(tài)插入新序列 |
| 問題三 | Tokenize / Detokenize 過程在 CPU 上執(zhí)行,期間 GPU 處于空閑狀態(tài) | 異步 Tokenize / Detokenize | 多線程異步 | 流水線 overlap 實現(xiàn)降低時延 |
?
大語言模型的輸入和輸出均是可變長度的。對于給定問題,模型在運行前無法預(yù)測其輸出長度。在實際服務(wù)場景下,每個用戶的問題長度各不相同,問題對應(yīng)的答案長度也不相同。傳統(tǒng)方法在同批次序列推理過程中,存在“氣泡”現(xiàn)象,即必須等同批次內(nèi)的所有序列完成推理之后,才會執(zhí)行下一批次序列,這就會引起 GPU 資源的浪費,導(dǎo)致 GPU 利用率偏低。
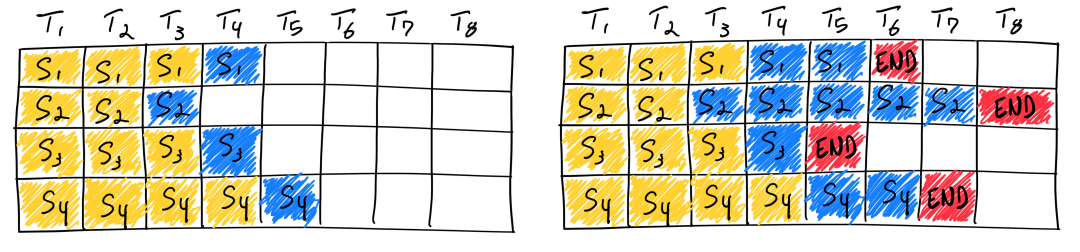
圖中序列 3 率先結(jié)束,但由于其他序列尚未結(jié)束,因此需要等待直至所有序列計算完畢。理想情況下,同批次的所有序列的輸入加輸出的長度均相同,這時不存在“氣泡”現(xiàn)象;極端情況下則會出現(xiàn)超過 50% 以上的資源浪費。
另一方面,傳統(tǒng)方法推理時 batchsize 是固定不變的,無法隨計算資源負(fù)載動態(tài)變化。比如某一段時間內(nèi),同批次下的序列長度都偏短,原則上可以增加 batchsize 以充分利用 GPU 計算資源。然而由于固定 batchsize,無法動態(tài)調(diào)整批次大小。
Continuous Batching 和 Dynamic Batching 思想最早來自論文 Orca: A Distributed Serving System for Transformer-Based Generative Models。針對問題一,提出 Continuous Batching,原理為將傳統(tǒng) batch 粒度的任務(wù)調(diào)度細(xì)化為 step 級別的調(diào)度。首先,調(diào)度器會維護兩個隊列,分別為 Running 隊列和 Waiting 隊列,隊列中的序列狀態(tài)可以在 Running 和 Waiting 之間轉(zhuǎn)換。在自回歸迭代生成每個 token 后,調(diào)度器均會檢查所有序列的狀態(tài)。一旦序列結(jié)束,調(diào)度器就將該序列由 Running 隊列移除并標(biāo)記為已完成,同時從 Waiting 隊列中按 FCFS (First Come First Service) 策略取出一個序列添加至 Running 隊列。
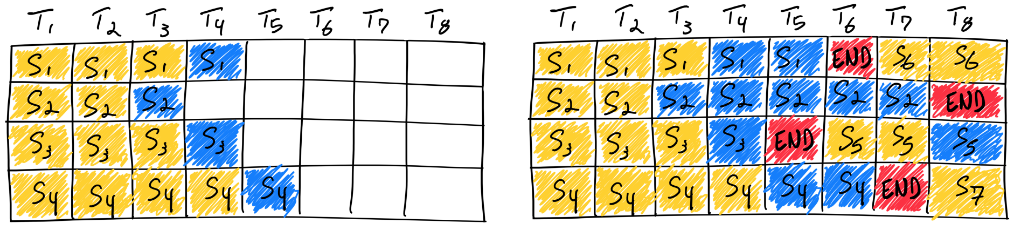
圖中,序列 3 率先在 T5 時刻結(jié)束,這時調(diào)度器會檢測到序列 3 已結(jié)束,將序列 3 從 Running 隊列中移除,并從 Waiting 隊列中按 FCFS 策略取出序列 5 添加至 Running 隊列并啟動該序列的推理。通過該方法,即可最大限度地消除“氣泡”現(xiàn)象。
問題一可以理解為在時間軸方向動態(tài)插入新序列,問題二則是在 batch 維度動態(tài)插入新序列,以盡可能地充分利用顯存空間。具體來講,在自回歸迭代生成每個 token 后,調(diào)度器通過當(dāng)前剩余顯存量,動態(tài)調(diào)整 Running 隊列的長度,從而實現(xiàn) Dynamic Batching。例如,當(dāng)剩余顯存量較多時,會盡可能增加 Running 隊列長度;當(dāng)待分配的 KV Cache 超過剩余顯存時,調(diào)度器會將 Running 隊列中低優(yōu)先級的序列換出至 Waiting 隊列,并將換出序列占用的顯存釋放。
如上兩個 batching 相關(guān)的優(yōu)化技術(shù)可有效提升推理吞吐量,目前已在 HuggingFace Text-Generation-Interface (TGI)、vLLM、OpenPPL-LLM 等多個框架中實現(xiàn)。
2.4 分布式相關(guān)優(yōu)化
由于大語言模型參數(shù)量較大,可能無法存放到單一計算設(shè)備中,分布式并行可以有效解決該問題。分布式并行中的模型并行和流水線并行已在 LLM 推理中得到應(yīng)用。由于篇幅有限,本文聚焦模型并行。模型并行通過將權(quán)重參數(shù)拆分到多個計算設(shè)備中,實現(xiàn)分布式計算。
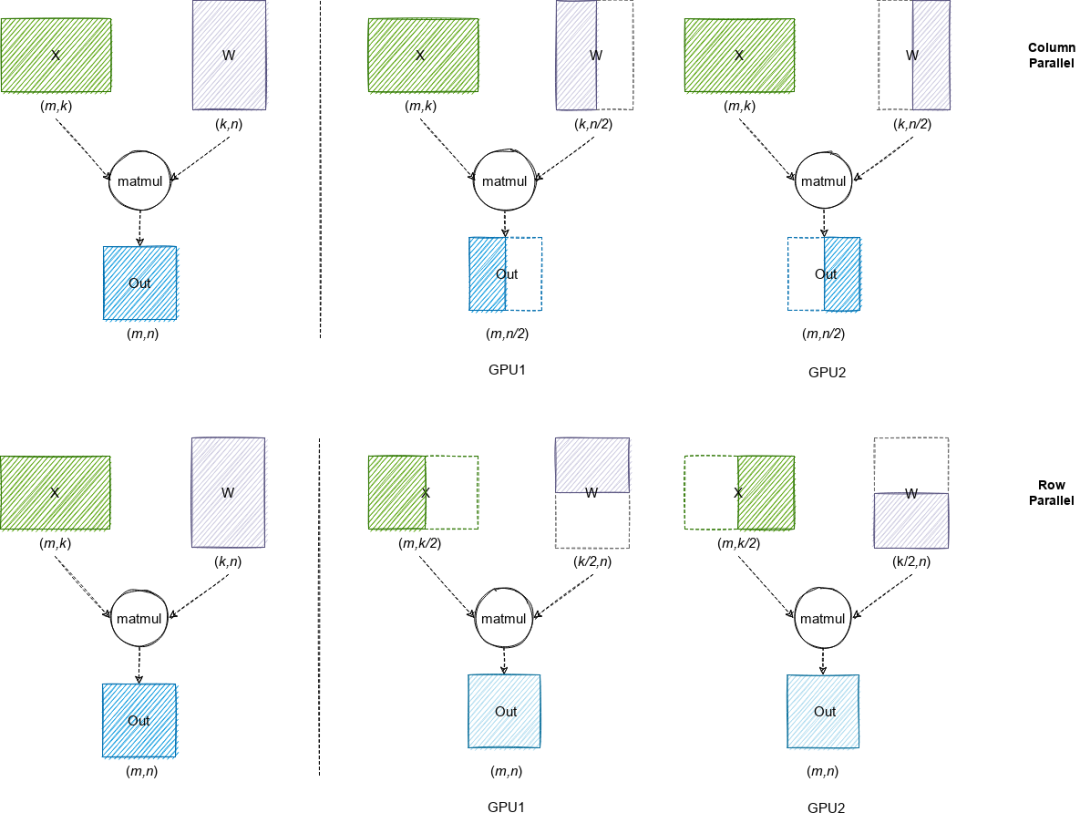
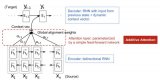
圖中,第一行代表 Column Parallel,即將權(quán)重數(shù)據(jù)按列拆分到多個 GPU 中,每個 GPU 上的本地計算結(jié)果需要在列方向拼接為最終結(jié)果;第二行代表 Row Parallel,即將權(quán)重數(shù)據(jù)按行拆分到多個 GPU 中,每個 GPU 上的本地計算結(jié)果需要 AllReduce 規(guī)約為最終結(jié)果。
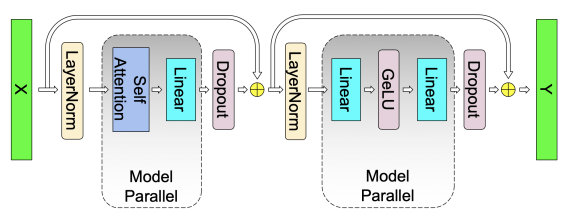
業(yè)界最流行的模型并行方案來自 Megatron-LM,其針對 Self-Attention 和 MLP 分別設(shè)計了簡潔高效的模型并行方案。
MLP: 第一個全連接層為 Column Parallel,第二個全連接層為 Row Parallel,整個 MLP 只需在 Row Parallel 后執(zhí)行一次 AllReduce 規(guī)約操作即可。
Self-Attention:在計算 Query、Key 和 Value 向量時執(zhí)行 Column Parallel(按注意力頭個數(shù)均分到每個 GPU),在將注意力得分做空間映射時執(zhí)行 Row Parallel,整個 Self-Attention 只需在 Row Parallel 后執(zhí)行一次 AllReduce 規(guī)約操作即可。
上面分析了 Transformer layer 的模型并行方式。除此之外,LLM 模型中的 Input Embedding 采用 Row Parallel,Output Embedding 采用 Column Parallel;Dropout / Layer Norm / Residual Connections 等操作都沒有做并行拆分。例如 Layer Norm 的權(quán)重參數(shù)和計算,在每個 GPU 上都是完整的。
?
| Layers | Model Parallel Method |
|---|---|
| Input Embedding | Row Parallel |
| Self-Attention | Column Parallel + Row Parallel |
| MLP | Column Parallel + Row Parallel |
| Output Embedding | Column Parallel |
?
基于以上基礎(chǔ),以 LLaMA-34B 模型為例進行通信量分析。該模型包含 48 個 Transformer layers,隱藏層大小 8192,每次單 batch 推理共 2 * 48 次 Broadcast 和 248 次 AllReduce 操作,每次通信傳輸?shù)臄?shù)據(jù)量均為 16 KB(此處假設(shè)數(shù)據(jù)類型為半精度浮點,81922/1024=16 KB)。考慮到推理服務(wù)一般都是按多 batch 推理執(zhí)行,假設(shè) batchsize 為 64,每次通信傳輸?shù)臄?shù)據(jù)量也僅為 1 MB。下圖在 A100-PCIE-40GB 機器上測試 NCCL AllReduce 帶寬數(shù)據(jù),PCIE 理論帶寬為 32-64 GB/s 左右,實際推理場景下的通信數(shù)據(jù)量主要集中在 1 MB 以下,對應(yīng)的實際帶寬約為 1-10 GB/s。NVLink 理論帶寬為 400-600 GB/s,但由于每次的通信量很小,實際帶寬也遠遠小于理論帶寬。因此模型參數(shù)量越大、batchsize 越大,通信效率越高,使用模型并行獲得的收益約明顯。
2.5 低比特量化
回歸到 LLM 模型推理吞吐量和時延這兩個重要的性能指標(biāo)上:吞吐量的提升主要受制于顯存容量,如果降低推理時顯存占用量,就可以運行更大的 batchsize,即可提升吞吐量;LLM 推理具有 Memory-bound 特點,如果降低訪存量,將在吞吐量和時延兩個性能指標(biāo)上都有收益。低比特量化技術(shù)可以降低顯存占用量和訪存量,其能取得加速的關(guān)鍵在于顯存量和訪存量的節(jié)省以及量化計算的加速遠大于反量化帶來的額外開銷。
?
| 被量化的對象 | 量化方法 | 特點 |
|---|---|---|
| 權(quán)重量化 | LLM.int8(), GPTQ | 顯存占用減半,但由于計算結(jié)果需反量化,時延基本無收益 |
| 權(quán)重和激活同時量化 | SmoothQuant | 顯存占用減半,時延有收益,精度幾乎匹配 FP16 |
| KV Cache量化 | INT8 或 FP8 量化 | 方法簡單,吞吐量收益明顯 |
| 基于硬件特點的量化:英偉達 Hopper 架構(gòu)下的 FP8 | 直接利用 TensorCore FP8 計算指令 | 不需要額外的量化/反量化操作,時延收益明顯 |
?
表中的四類量化方法各有特點,業(yè)界在低比特量化方向的研究進展也層出不窮,希望探索出一個適用于大語言模型的、能夠以較高壓縮率壓縮模型、加速端到端推理同時保證精度的量化方法。
2.6 其他新技術(shù)
當(dāng)前,業(yè)界在將傳統(tǒng)優(yōu)化技術(shù)引入 LLM 推理的同時,同時也在探索從大模型自回歸解碼特點出發(fā),通過調(diào)整推理過程和引入新的模型結(jié)構(gòu)來進一步提升推理性能。
例如,投機采樣(Speculative decoding)針對 LLM 推理串行解碼特點,通過引入一個近似模型來執(zhí)行串行解碼,原始模型執(zhí)行并行評估采樣,通過近似模型和原始模型的互相配合,在保證精度一致性的同時降低了大模型串行解碼的次數(shù),進而降低了推理時延。美杜莎頭(Medusa head)則是對投機采樣的進一步改進,其摒棄了近似模型,在原始模型結(jié)構(gòu)上新增了若干解碼頭,每個解碼頭可并行預(yù)測多個后續(xù) tokens,然后使用基于樹狀注意力機制并行處理,最后使用典型接收方案篩選出合理的后續(xù) tokens。該方法同樣降低了大模型串行解碼的次數(shù),最終實現(xiàn)約兩倍的時延加速。
3 總結(jié)
大語言模型推理性能優(yōu)化技術(shù)正迅速演進,不僅涉及計算機科學(xué)和人工智能領(lǐng)域,還融合了多個學(xué)科的知識,實現(xiàn)了前所未有的跨學(xué)科交叉滲透。演進的動力源自對大規(guī)模模型應(yīng)用的需求,為了充分發(fā)揮這些模型的潛力,研究人員正在不斷改進推理性能,包括算法優(yōu)化、硬件加速、分布式計算等方面的創(chuàng)新。這一快速演進和跨學(xué)科滲透的趨勢不僅將提高大語言模型的實用性,還為未來的自然語言處理應(yīng)用和人工智能技術(shù)帶來更大的創(chuàng)新和應(yīng)用潛力。
參考
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu,J. E. Gonzalez, H. Zhang and I. Stoica, Efficient MemoryManagement for Large Language Model Serving with Page-dAttention, Proceedings of the ACM SIGOPS 29th Sympo-sium on Operating Systems Principles, 2023.
S. Z. Y. S. L. Z. C. Y. J. G. H. Z. Woosuk Kwon, Zhuohan Liand I. Stoica, vLLM: Easy, Fast, and Cheap LLM Servingwith PagedAttention,https://vllm.ai/, 2022.
HuggingFace, ?Transformers: ? State-of-the-art ?MachineLearning for Pytorch, TensorFlow, and JAX.,https://github.com/huggingface/transformers.
NVIDIA, ? ?FasterTransformer,https://github.com/NVIDIA/FasterTransformer, 2021.
R. Y. Aminabadi, S. Rajbhandari, A. A. Awan, C. Li, D. Li,E. Zheng, O. Ruwase, S. Smith, M. Zhang, J. Rasley et al.,DeepSpeed-inference: enabling efficient inference of trans-former models at unprecedented scale, SC22: InternationalConference for High Performance Computing, Networking,Storage and Analysis, 2022, 1–15.
P. Tillet, H.-T. Kung and D. Cox, Triton: an intermedi-ate language and compiler for tiled neural network com-putations, Proceedings of the 3rd ACM SIGPLAN Inter-national Workshop on Machine Learning and ProgrammingLanguages, 2019, 10–19.
T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, H. Shen,M. Cowan, L. Wang, Y. Hu, L. Ceze et al., TVM: An au-tomated End-to-End optimizing compiler for deep learning,13th USENIX Symposium on Operating Systems Design andImplementation (OSDI 18), 2018, 578–594.
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casperand B. Catanzaro, Megatron-lm: Training multi-billion pa-rameter language models using model parallelism, arXivpreprint arXiv:1909.08053, 2019.
T. Dettmers, M. Lewis, Y. Belkada and L. Zettlemoyer, Llm.int8 (): 8-bit matrix multiplication for transformers at scale,arXiv preprint arXiv:2208.07339, 2022.
E. Frantar, ?S. Ashkboos, ?T. Hoefler and D. Alistarh,Gptq: ?Accurate post-training quantization for generativepre-trained transformers, arXiv preprint arXiv:2210.17323,2022.
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth and S. Han,Smoothquant: Accurate and efficient post-training quanti-zation for large language models, International Conferenceon Machine Learning, 2023, 38087–38099.
A. C. Elster and T. A. Haugdahl, Nvidia hopper gpu andgrace cpu highlights, Computing in Science & & Engineering, 2022, 24, 95–100.
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifreand J. Jumper, Accelerating large language model decodingwith speculative sampling, arXiv preprint arXiv:2302.01318,2023.
Y. Leviathan, M. Kalman and Y. Matias, Fast inference fromtransformers via speculative decoding, International Confer-ence on Machine Learning, 2023, 19274–19286.
T. Cai, Y. Li, Z. Geng, H. Peng and T. Dao, Medusa: SimpleFramework for Accelerating LLM Generation with MultipleDecoding ?Heads,https://github.com/FasterDecoding/Medusa, 2023.
審核編輯:黃飛
?




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論