完善資料讓更多小伙伴認識你,還能領(lǐng)取20積分哦,立即完善>
標簽 > 強化學習
文章:225個 瀏覽:11603次 帖子:1個
智能體的連接問題,如何創(chuàng)建能符合人類目標的智能體?
長期來看,我們會擴大獎勵建模的規(guī)模,將其應(yīng)用于人類難以評估的領(lǐng)域。為了做到這一點,我們需要增強用戶衡量輸出的能力。我們討論了如何循環(huán)應(yīng)用獎勵建模:我們可...
作者們提出的方法讓機器人有能力學習如何把不同的物體當作工具以完成用戶給定的任務(wù)(第一行圖中用黃色箭頭標出)。任務(wù)中并沒有指定機器人必須使用給定的工具,但...
有了OpenAI Five,它已經(jīng)可以在比賽中擊敗業(yè)余玩家
如果一個AI能在像星際、Dota這樣復雜的游戲里超越人類水平,那它就是一個里程碑。相較于AI之前在國際象棋和圍棋里取得的成就,游戲能更好地捕捉現(xiàn)實世界中...
2018-06-29 標簽:神經(jīng)網(wǎng)絡(luò)AI強化學習 3649 0

人工智能從神經(jīng)科學領(lǐng)域吸收了大量養(yǎng)分,并由此催生了深度學習和強化學習等智能處理方法。
OpenAI舉辦的首屆遷移學習競賽Retro Contest結(jié)束
Dharmaraja(法王)是一個6人組成的團隊:Qing Da、Jing-Cheng Shi、Anxiang Zeng、Guangda Huzhang...
在深度強化學習中,智能體是由神經(jīng)網(wǎng)絡(luò)表示的。神經(jīng)網(wǎng)絡(luò)直接與環(huán)境相互作用。它觀察環(huán)境的當前狀態(tài),并根據(jù)當前狀態(tài)和過去的經(jīng)驗決定采取何種行動(例如向左、向右...
在開發(fā)RND之前,OpenAI的研究人員和加州大學伯克利分校的學者進行了合作,他們測試了在沒有環(huán)境特定回報的情況下,智能體的學習情況。因為從理論上來說,...
強化學習(RL)能通過獎勵或懲罰使智能體實現(xiàn)目標,并將它們學習到的經(jīng)驗轉(zhuǎn)移到新環(huán)境中。

單v100 GPU,4小時搜索到一個魯棒的網(wǎng)絡(luò)結(jié)構(gòu)
這個采用了搜索robust neural cell來替代搜索整個網(wǎng)絡(luò)。如下圖,不同的操作(操作用箭頭表示)會計算出不同的中間結(jié)果(中間結(jié)果用cycle表...
2019-07-27 標簽:神經(jīng)網(wǎng)絡(luò)gpu強化學習 3357 0
首先, 什么是空間? 最早探討它的是物理學, 從亞里士多德到牛頓。 牛頓的物理學在絕對空間基礎(chǔ)上存在,所謂絕對空間, 可以簡化為一個歐式直角坐標系, ...
一年一度的國際機器學習會議( ICML ),于7月15日在瑞典斯德哥爾摩閉幕,ICML 的會議日程之緊湊,會議內(nèi)容之豐富,令人目不暇接。
2018-07-31 標簽:網(wǎng)絡(luò)架構(gòu)強化學習 3104 0
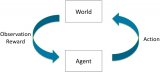
雖然很多基礎(chǔ)的RL理論是在表格案例中開發(fā)的,但現(xiàn)代RL幾乎完全是用函數(shù)逼近器完成的,例如人工神經(jīng)網(wǎng)絡(luò)。 具體來說,如果策略和值函數(shù)用深度神經(jīng)網(wǎng)絡(luò)近似,則...
2019-01-23 標簽:智能體強化學習tensorflow 3091 0

深度強化學習大神Pieter Abbeel發(fā)表深度強化學習的加速方法
首先將多個 CPU核心 與 單個GPU 相關(guān)聯(lián)。多個模擬器在CPU內(nèi)核上以并行進程運行,并且這些進程以同步方式執(zhí)行環(huán)境步驟。在每個步驟中,將所有單獨的觀...
使用新的機器學習技術(shù), 通過減少治療膠質(zhì)母細胞瘤過程中毒性化療和放療的劑量
然而,研究人員還必須確保該模型不僅僅為了最大療效而給出最大的劑量。任何時候模型選擇給予全部劑量時,它就會受到懲罰,因此它會選擇更少、更小的劑量。 “如果...
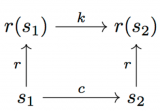
在涉及計算路徑的每一個步驟(不管是在r-空間還是在s-空間),我們都可以使用范圍廣泛的技術(shù),包括基于優(yōu)化的技術(shù)(TrajOpt),基于搜索的技術(shù)(RRT...
2018-09-06 標簽:神經(jīng)網(wǎng)絡(luò)機器翻譯強化學習 2798 0
奪旗原本是一項廣受歡迎的戶外運動,被廣泛的應(yīng)用于電子游戲中。在一張給定的地圖中,紅藍雙方保護自己的旗子并搶奪對方旗子,5分鐘時間內(nèi),奪旗次數(shù)最多的隊伍獲...
我們的設(shè)計使機器人明白如何使用不同的物體作為工具來實現(xiàn)指定的任務(wù)(根據(jù)黃色箭頭標記)。機器人在執(zhí)行任務(wù)期間自行決定是否使用已提供的工具。
2019-04-29 標簽:機器人數(shù)據(jù)集強化學習 2754 0
另外,策略網(wǎng)絡(luò)表示強化學習智能體使用的隨機策略,用πθ(s, a) = p(a|s;θ)表示,其中θ是神經(jīng)網(wǎng)絡(luò)的參數(shù)列表,會用Adam優(yōu)化器進行更新。系...
2018-11-24 標簽:神經(jīng)網(wǎng)絡(luò)智能體強化學習 2679 0
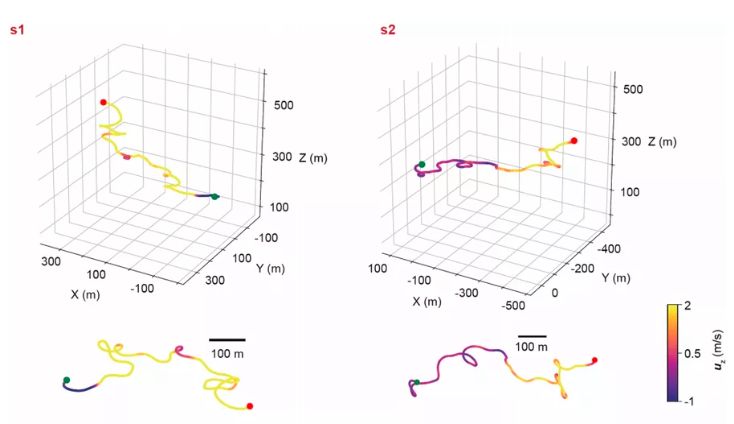
在我們可以真正使用AI控制的熱氣流滑翔機進行實際應(yīng)用之前,還有很多工作要做。這只是鳥類輔助自身飛行的氣流中的一種。換句話說:僅僅因為AI可以駕馭熱氣流,...

幫你們破除RL的神秘感,理清各算法發(fā)展的脈絡(luò)
因為篇幅所限,簡單介紹一下V(s)與Q(s,a)。它們是Value Function Approximation算法中兩個重要概念,著名的Deep Q-...
 換一批
換一批
編輯推薦廠商產(chǎn)品技術(shù)軟件/工具OS/語言教程專題
| 電機控制 | DSP | 氮化鎵 | 功率放大器 | ChatGPT | 自動駕駛 | TI | 瑞薩電子 |
| BLDC | PLC | 碳化硅 | 二極管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 無刷電機 | FOC | IGBT | 逆變器 | 文心一言 | 5G | 英飛凌 | 羅姆 |
| 直流電機 | PID | MOSFET | 傳感器 | 人工智能 | 物聯(lián)網(wǎng) | NXP | 賽靈思 |
| 步進電機 | SPWM | 充電樁 | IPM | 機器視覺 | 無人機 | 三菱電機 | ST |
| 伺服電機 | SVPWM | 光伏發(fā)電 | UPS | AR | 智能電網(wǎng) | 國民技術(shù) | Microchip |
| Arduino | BeagleBone | 樹莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 華秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS |
關(guān)注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1

