 摩爾定律、后摩爾時代以及Chiplet概念
摩爾定律、后摩爾時代以及Chiplet概念
Chiplet的概念一直都很火,國內外的各大公司各大專家,都發過各種各樣的視頻和長文。近段時間更是火熱,一級火,二級也火,而且因為Chiplet技術有著2個14nm堆疊出7nm這樣的說法,按照這個邏輯那4個14nm能不能堆疊5nm?
在普通人眼里,Chiplet像是國內彎道超車的技術和機會,一時間各種分析解讀,層出不窮,但是看完這些之后是不是有一種感覺,越看越糊涂?后摩爾時代為什么和先進封裝有關系?Chiplet到底是不是國內彎道超車的機會?
確實,太多專業概念需要科普,光靠自己去理解其中關系和概念其實挺困難的,簡直頭都大了。而且術業有專攻,不是專家自己擅長的領域不一定會覆蓋到,因此哪怕產業專家也有講的不夠全面地方。
有沒有一篇文章, 用最簡單通俗的話術,用普通人最容易理解的方式去解釋其中的前因后果以及各種概念?
經過走訪眾多大佬,刷過無數文章之后,筆者終于摸到一點門檻,今天就通過梳理發展歷史脈絡和概念,幫助大家更好的理解Chiplet和后摩爾時代半導體的發展方向。
01摩爾定律的歷史
這個摩爾定律大家都很熟悉,一句話來概括:每隔18個月,單位面積內晶體管數量翻倍且價格不變。
這條被奉為行業圭臬的定律是由英特爾創始戈登·摩爾在60多年前提出的。
如果把它拆解后可得到兩條衍生定律:1、成本減半定律,2、性能翻倍定律,且前置條件是更替節奏必須是每隔18個月。
成本減半很好理解,晶體管數量翻倍但是價格不變,等于每個晶體管的成本每個周期都在下降。
性能翻倍也很好理解,單位面積內晶體管數量翻倍,相當于每顆芯片的性能變得越來越強,畢竟晶體管數量的多少,很大程度上決定了這顆芯片的算力性能,越多基本等于越強。
當然這個是有前提的,僅適用于邏輯芯片領域,類似模擬,功率,傳感器,射頻之類不在這個討論范圍內,全世界最好的音頻芯片還是4-6英寸的工藝在做,都是30,40年前的工藝,摩爾定律不太適用,但是你能說它落后嗎?不,它已經是最好的了。
02摩爾定律的發展困境
假如,摩爾定律發展遇到困境了,那么從邏輯上來講,必然是成本減半和性能翻倍兩個結論,以及18個月這個周期,三者約定的條件中,有1-2個因素發展變化導致這個周期節奏被打破了,所以我們說摩爾定律發展遇到困境了。
換言之就是這個節奏玩不動了,或者不按這個節奏走了,所以結論就是摩爾定律被打破了,然后就開始提后摩爾時代這個概念了。這就是摩爾定律無法延續,我們要進入后摩爾時代的說法來源,確實先進工藝也確實快到極限了。
顯然成本減半和性能翻倍是一件非常矛盾的事,相當于又要馬兒少吃草,又要馬兒跑得快,而且更替節奏只有短短的18個月。
從現實發展而言,兩個定律都遇到兩個無法回避的現實問題。
1、晶體管數量翻倍導致性能翻倍背后,有個巨大的隱患,就是急劇攀升的功耗。
道理也很簡單,現在的集成電路技術,已經可以在指甲蓋大小的面積內塞下上百億個晶體管,如此狹小的面積內,任何電流經過都不可避免的帶來發熱,因此晶體管越多功耗越大,功耗越大意味著發熱量就大,內部堪比一個大火爐,發熱量一旦超過極限,芯片就直接燒穿了,那就是出大問題了。
可以說功耗和發熱問題一直制約著晶體管數量的翻倍,業界一直在尋找各種方案與功耗做斗爭。
2、成本減半,顯然也很痛苦,畢竟投入越來越大,還要維持18個月內減半, 其中蘊含著巨大的矛盾和商業風險。新技術從研發投入到最終產出,必須有看得見降本提效,否則就變成往無底洞扔錢,太難了。
03傳統思路是如何延續摩爾定律?
所以解決功耗和發熱,是集成電路工藝一直為之戰斗的目標,解決思路不外乎2個:1、改工藝;2、改基礎材料。
無論是改工藝,還是改基礎材料,目標都是繼續維持性能翻倍定律和成本減半定律,綜合下來就是怎么降本提效讓摩爾定律能繼續走下去。
先說改基礎材料的問題,這就是現在炒的火熱的概念,比如碳基芯片,硅光芯片/光電芯片,生物芯片等。
相當于把硅晶體管改成碳晶體管,或者硅光/光電子芯片,或者生物芯片。
分開聊聊這幾個方向的優缺點。
碳管就是石墨烯材料的一種具體應用。相比硅管,石墨烯碳管有更高的載流子遷移率和穩定性,有更薄的導電通道和完美的結構,確實是一種比硅更好的材料。當然現在碳基芯片還處于比較早期的研究階段,還有很多現實問題要解決,比如摻雜問題,晶體管制造的規模化等等,當然還有產業生態圈的問題,比如設計人員要如何設計電路才能完美發揮碳管的性能?晶圓工廠如何提供專業的工具包,標準晶體管單元庫,仿真平臺,以及制造工藝?
碳基芯片已經在實驗室被制造出來,但是大規模商業化還早,還要很多年反復論證之后產業才能成熟。
也許有朝一日碳管的時代會到來,中國在這方面有所布局,讓我們拭目以待。
硅光/光電子芯片,光電子芯片概念也很火,但是實際上也有兩層不同概念。
第一,比較簡單的方案是用光電互聯結構替代硅晶體管的金屬互聯結構,因為光子速度極快,且傳輸過程中沒有功耗,不會有額外的發熱,因此是非常理想取代金屬互聯層材料的方案。畢竟目前的芯片中,大約有一半的功耗是在金屬互聯層上,如果用光傳輸信號,確實能解決這個問題,能極大降低芯片功耗,包括英特爾,英偉達,臺積電等早就開始押注這個賽道了。
硅光芯片目前往這個方面在發展。

還有更高一層的夢想,就是用光子來替代硅晶體管進行0/1運算,這個有點類似量子計算,但是這個更早期,屬于最前沿的科研項目。
生物芯片同理,因為僅需一點點加入一些酶就能變化,優點是幾乎不需要什么能量,自然就不存在什么功耗和發熱的問題,缺點是計算結論比較難得到,目前業內認為用于存儲方面可能是一個比較可行的方案,當然現階段只是一個研究方向,是非常前沿的技術,離商業化應用還很遠。
改晶體管基礎材料說完了,再說說改工藝的方案。
改工藝,解決思路也就是從晶體管結構入手,從金屬互聯材料和結構入手,加入各種新材料輔以先進制造技術,繼續微縮晶體管尺寸,最終實現提高密度,降低功耗,提升性能這一目標。因此工藝進步依然是按著傳統的思路在前進,這屬于集成電路工程學的范疇。
以筆者在半導體工藝的知識儲備,改工藝方面大概能科普到以下內容,如果有誤望各位指正。
一、改進金屬互聯材料。
最早的集成電路工藝用的是鋁互聯工藝,這是英特爾另外一名創始人諾伊斯想出來的。
從6英寸工藝到8英寸再到12英寸工藝,看似是以硅片不同尺寸來命名的叫法,實際上每一代硅片變化的時候,工藝也在變化,不僅是改硅片尺寸,同時設備也做出更大改進,因此6英寸,8英寸,12英寸工藝設備,都有自己范圍內的工藝節點。
比如6英寸大多數是0.5um-0.25um的線寬,8英寸多數是0.35-0.13um的線寬,12英寸是從90nm-28nm算成熟12英寸制程,小于20nm的16/14nm,7nm,5nm,3nm屬于先進12英寸工藝范疇。
科普完了硅片和工藝節點的知識后,我們繼續。
不同的工藝節點上,金屬互聯材料以及接觸點材料就發生了巨大變化,6英寸用鋁,但是8英寸工藝上就加入了鎢塞工藝,鎢作為接觸點金屬材料被運用在接觸點上,而12英寸工藝上則加入了銅,用銅線替代了鋁線。
進入10nm工藝更先進的制程里,英特爾折騰出鈷互聯,鈷互聯用于局部替代銅鎢以及銅釕材料,用在襯底,導電,接觸點,以及中間層上,特別是在M0和M1層的連線基線上。

科普一下M0和M1層,是指和最底下晶體管那一兩層,直接和晶體管相連的,往上的M2到M十幾層,都屬于金屬互聯層。
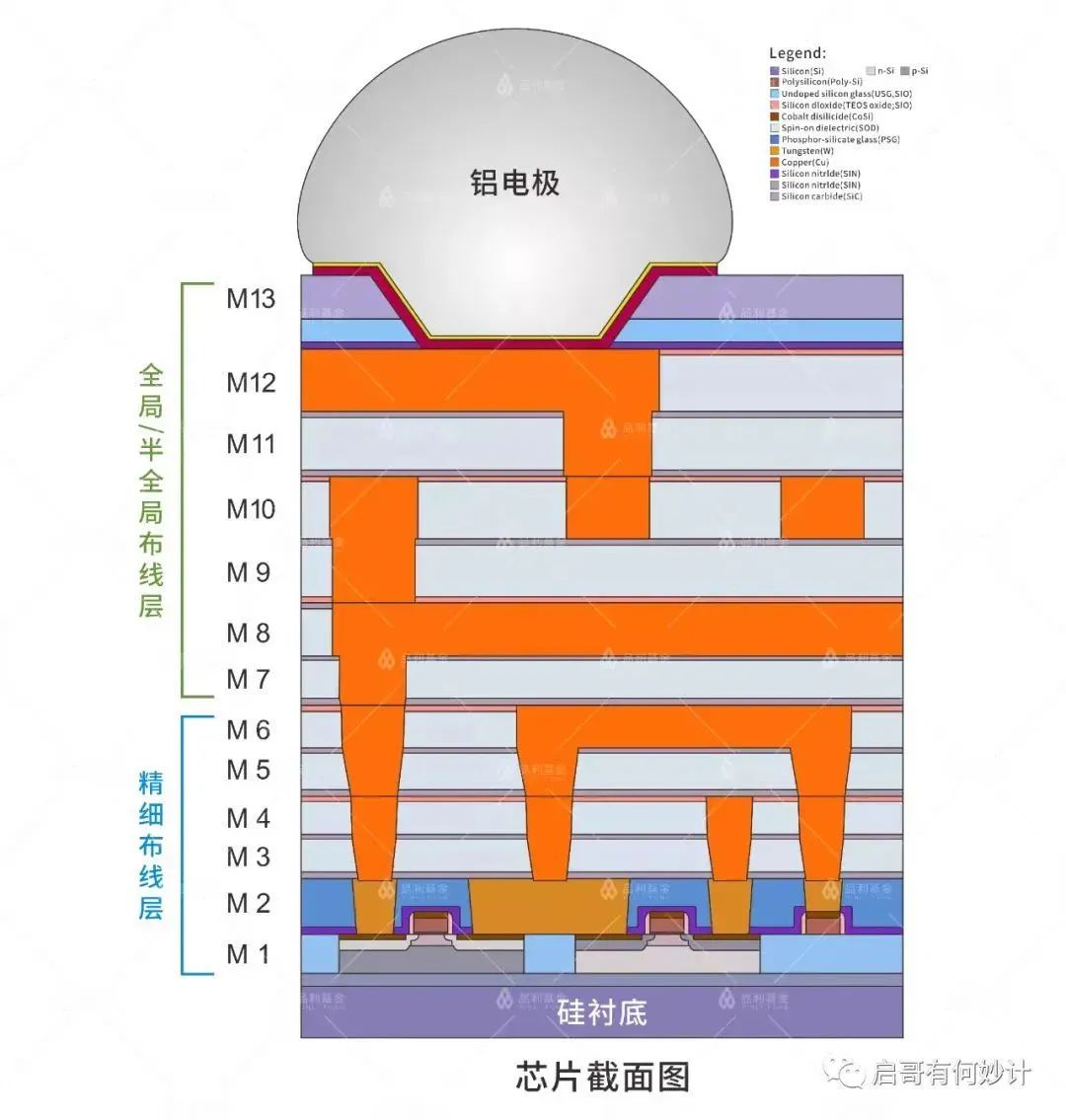
臺積電在3nm以下工藝又折騰出鉍互聯,也是同一個思路。
同時,由于不同金屬的導電率不同,隧穿率不同,我們需要在接觸點/互聯布線層外加入各種不同介電常數的材料作為阻擋層/緩沖層包裹起來,不讓電子隨便亂跑,不能漏出來,畢竟漏電了就代表有能量被帶走,然后帶來的就是大量發熱,這是需要努力克服的問題。
阻擋層/緩沖層還有一個作用,就是讓電子愉快的且不費力往前跑。
于是集成電路工藝大佬們在怎么弄阻擋層材料和沉積阻擋層工藝上也費了不少心血,目的就是為了就是讓電子更順暢通過,從而不漏電。
因此改金屬互聯工藝,就是改了接觸點和互聯層材料,以及包裹他們的阻擋層,緩沖層材料的一整套完整工藝。
這點上,應材去年推出了一款新設備叫 Endura Copper Barrier SeedIMSTM。
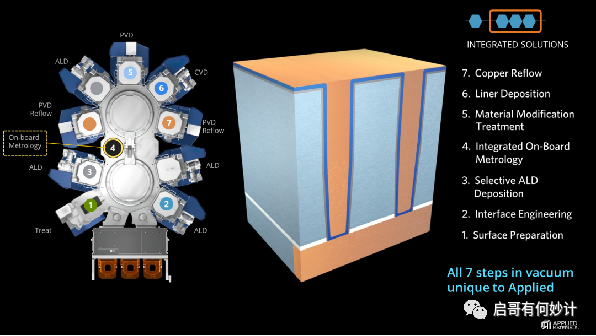
在這款新設備上,應材把ALD、PVD、CVD、銅回流、表面處理、界面工程和計量這七種不同的工藝技術集成到一個系統中,號稱通過這一解決方案,通孔接觸界面的電阻降低了50%,芯片性能和功率得以改善,邏輯微縮也得以繼續至3nm及以下節點,當然這設備實際能有多大效果我不知道,但是價格一定很大。
二、改變柵極厚度,大小,結構和材料
深入鉆研過集成電路工藝的小伙伴可能在28nm工藝上聽說過一種叫HKMG的工藝,HKMG叫做High-K Metal Gate,翻譯過來叫高介電常數金屬柵極。
這個K就是介電常數的意思。
實際上就是用高K材料HfO2(二氧化鉿)和HfSiON取代SiON(氮氧化硅)作為柵極氧化層。
到45nm工藝的時候,最先達到極限的就是這個柵極的介電質。
先來科普一下,柵極是啥。
MOSFET管,也就是金屬氧化物金屬場效應晶體管,簡單理解成這是芯片內部的基礎單位。比如一顆芯片集成了10億個晶體管,你可以理解成集成了10億個MOS管,但是實際上還有nMOS,pMOS,CMOS,Bicmos,電容之類的,比這個復雜多了,暫不做講解,今天只講科普原理。
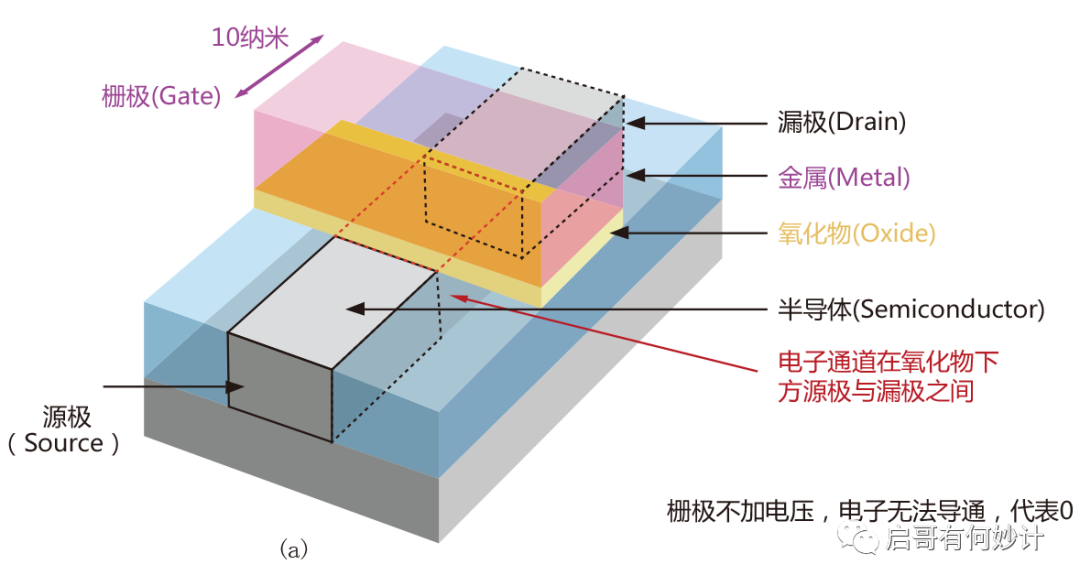
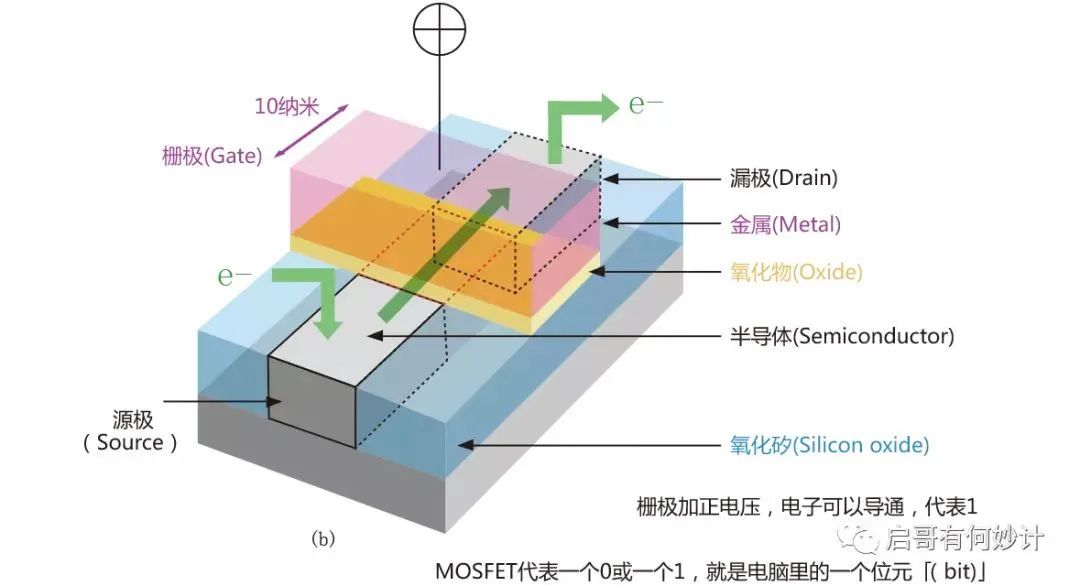
MOSFET結構有三個極,分別是源極(Source),漏極(Drain),柵極(Gate),可以理解成電流從源極進去,從漏極出來,而柵極相當于水龍頭的作用,加電壓就形成導通,沒有電壓就關斷(這是常關型MOS特性,如果是常通型MOS則是加負電壓關斷)。形成導通和關斷就能代表0和1,這就是計算機的基礎工作原理,對,0和1,二進制,德國數學家萊布尼茨發明的,其還發明了微積分。
顯然柵極的開關速度和開啟/關斷的閾值電壓,決定了晶體管工作的頻率,速度,柵極大小和功耗密切相關,柵極越小,溝道就越小,但是溝道越小就更容易漏電,因此得到更高頻率更好性能的芯片,帶來的副作用就是面臨更大損耗,同時發熱量也越大。
顯然柵極厚度,大小,結構和材料,很大程度上決定了晶體管的極限工作狀態下的開關速度,頻率以及功耗大小,換柵極材料就能繼續提高晶體管的性能和控制功耗。
因此45nm工藝最先遇到就是這個問題,傳統用二氧化硅材料做的柵極,已經沒辦法滿足晶體管性能提高,體積縮小的要求,容易產生漏電等問題,導致晶體管可靠性下降,因此提出了用高K金屬柵極材料替代傳統二氧化硅的工藝路線。
在28nm工藝上除了HKMG工藝,其他還有多達5-6個工藝版本,另外一個比較讓人熟知的是28nm PolySiON工藝,叫多晶硅工藝,顯然這是用多晶硅作為柵極的工藝。
PolySiON工藝水平接近40nm工藝性能,高性能HPC芯片用HKMG工藝的居多,到后面更是加入La2O3(氧化鑭)等高K材料。
結論是在傳統摩爾定律發展過程中,確實把克服柵極材料短板作為一項重要的工作內容,但是發展到后面,短板不在柵極上的時候,又一種解決摩爾定律的思路出現了。
三、改變晶體管結構
這里又要提一個耳熟能詳的大神——胡正明。
胡正明教授在1999年至2000年,分別提出了用于20nm以下的兩種新晶體管技術,FinFET和FD-SOI硅,并預言未來在20nm以下節點會用這兩種技術。
當時預測20nm是摩爾定律的盡頭,沒想到硬是靠胡正明的FinFET強行續了一命。
15年后,在2015-2016年,臺積電,三星,英特爾等前后研發出了基于FinFET晶體管技術的芯片,證明胡大神的設想是成立的。
FinFET的技術讓胡正明就此封神了,這項技術足以沖擊諾貝爾獎。
FinFET叫鰭式柵晶體管,顧名思義這東西像魚鰭一樣豎著的,和平面型的MOSFET不同,這是立體的晶體管結構。
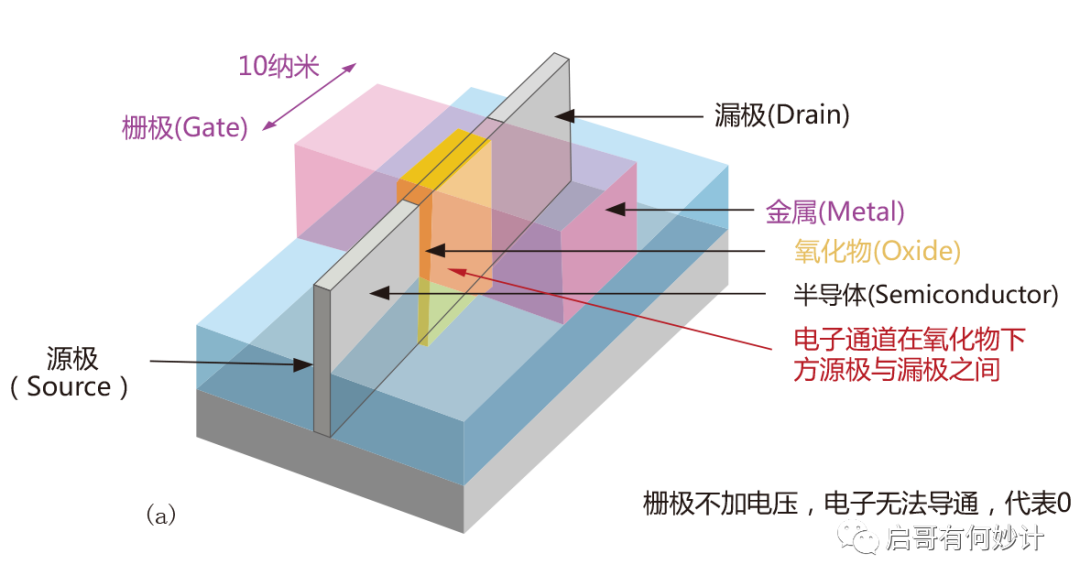
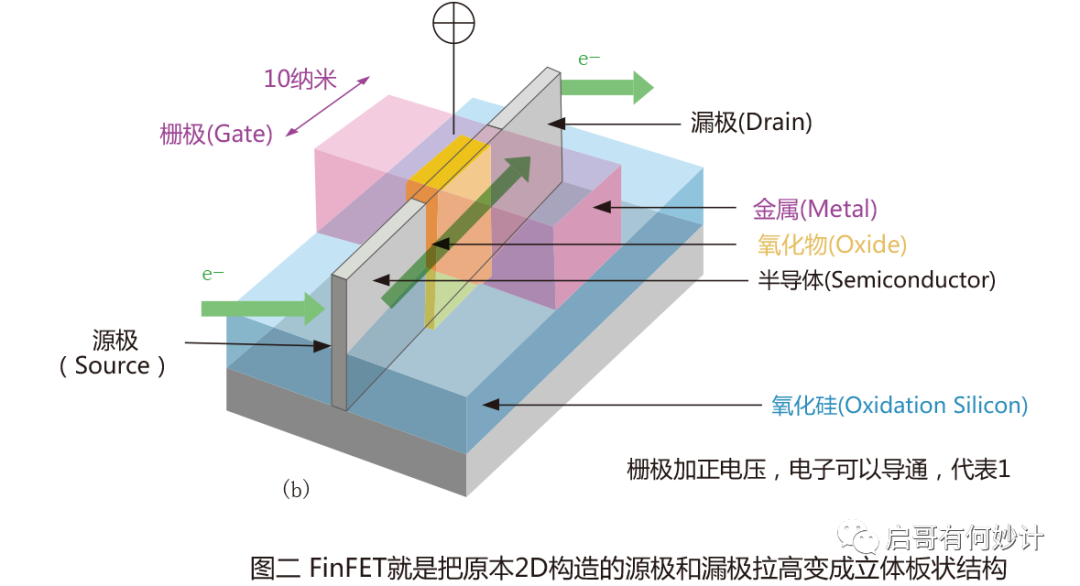
顯然豎起來之后,不僅晶體管密度大大增加,同時也克服了MOSFET致命的“短溝道效應”,FinFET的出現繼續給摩爾定律續命了。當然FinFET工藝也是配套一系列的工藝,為了解決FinFET特有比如電壓閾值難以控制,更高的寄生電容效應,特殊三維輪廓也是上了一大堆新技術例如SADP(多重曝光)。
當然到3nm節點,可能唱主角的變成GAA技術(Gate-all-around環繞式柵極晶體管)。現在三星和臺積電明爭暗斗,三星5nm無法超越臺積電,于是把資源都投在3nm節點上,相當于未來三星要和臺積電在3nm節點上決戰了。按照三星的說法,預計明年就能看到第一批使用GAA晶體管技術的芯片面世。
但是再往后呢?以人類無窮盡的智慧應該還有其他辦法,1nm以下可能會用更新的堆疊技術,也許會過渡到碳晶體管時代,讓我們拭目以待。
至于胡大神另外一個FD-SOI硅技術,也順帶科普下。
FD-SOI,叫全耗盡型絕緣硅,這種工藝需要使用一種特殊的硅片,一種類似三明治夾層結構的硅片,硅片中間有一層二氧化硅。

這種硅片中間有一層Oxide(氧化層),類似三明治夾層的結構
國內上海硅產業集團及法國子公司Soitec和沈陽硅基,都生產這種特殊的硅片。
這種特殊的硅片中間有一層二氧化硅,二氧化硅是非常良好的絕緣層,有絕緣層意味著不漏電,因此采用這種工藝制造的芯片有個絕對優點,就是功耗非常低。
而且不僅能實現低功耗,由于有二氧化硅夾層的存在,在制造過程中還能省光罩次數和層數,相當于降低了制造成本。
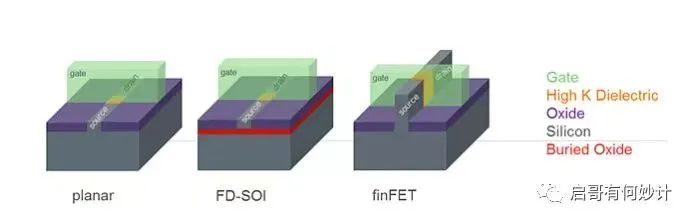
低功耗+省成本,是不是完美契合前文提到過的摩爾定律延伸出來的兩大定律,成本減半定律和性能翻倍定律?因此胡大神說它是20nm以下集成電路制造技術的另外一個路線。
以前IBM擅長此道,后面被格羅方德(改名為格芯)繼承,格羅方德還在桑杰·賈(Sanjay Jha)時代,2017年曾經宣布在成都要投資300億美金,蓋一個22nm FDX廠對標14nm FinFET,就是這個技術,22nm SOI技術竟然能對標14nm這個說法原因也在這里。
但是FD-SOI也有一大堆問題,首先是SOI硅片比較貴,是普通硅拋光片的8-10倍左右,然后最主要就是產業生態圈的問題,生態不成熟,沒有清晰的替代路徑,沒有考慮長遠的產品和技術迭代,仿真軟件和設計平臺也不成熟,目前國內除了在射頻和物聯網方面追求極致低功耗的領域有見過FD-SOI硅技術的身影之外,高性能計算領域幾乎是零,全是FinFET的天下。
FD-SOI硅技術,有很多優點,但是產業生態圈不成熟也是其最大的短板,國內芯原微電子比較力推這個路線,推出了各種IP,希望國內以后能利用自身市場優點和特點,在射頻和物聯網等低功耗領域把FD-SOI技術發揚光大。
改進工藝和改基礎材料,就科普到這里。
04如何延續后摩爾時代?
顯然改工藝和改基礎材料的各種方案都還是傳統的摩爾定律思路,用更小的晶體管技術制造更強大的芯片,但是萬事萬物都有盡頭,在當下各種成本高企的階段,確實力不從心了。
新工藝研發投入,新設備的研發投入,新廠的建設加一起堪稱天文數字,每年接近上千億美金的研發投入和新廠資本支出。
那么靈魂拷問來了,這些投入后的回報怎么算?
以老大哥英特爾為例,今年3月宣布在亞利桑那州投入200億美金的巨資,新建兩座工廠,相當于一座廠100億美金,你說這要賣多少顆CPU?一顆賣多少價格?一座工廠運營也需要天量資金,請問這些投入多少年才能回本???
當然英特爾蓋廠背后有美國政府的全力支持,芯片法案里有巨額補貼,實際上英特爾不需要從自己口袋里掏這么多錢,成本能降低不少。
但不可否認的是,新工藝,新設備,新建廠越來越高的成本也催生了巨大的商業風險,搞不好就是巨虧,擱誰都受不了。
所以這投入加一起已經堪比天文數字,如果平攤到每個晶體管上,會造成當期成品的單個晶體管成本不降反升!幾年以后會逐漸攤平研發投入,單個晶體管成本還是會下降,但是前幾年成本依然非常高。
有機構統計過,2015年前后剛出14nm的FinFET那會兒,當時每個晶體管的成本已經不降反升了,初期FinFET所涉及的技術太復雜,良率不高,導致成本居高不下。換句話說7年前,摩爾定律其中之一的晶體管成本減半定律已經被打破,那會兒摩爾定律已然失效,當然由于后續技術提升,提高良率后,整體成本還是下降的,摩爾定律得以繼續前進,但是以后呢?成本越來越高的問題已經沒辦法無視了,所以說業界到現在開始探討摩爾定律還能不能維持,怎么維持的問題。
延續后摩爾時代,已然要從根本問題入手,成本減半,性能翻倍,降本提效。于是后摩爾時代以及Chiplet概念來了。
05后摩爾時代與Chiplet
在商業環境下,拋開成本談性能是耍流氓,這是商業法則,因此必須兼顧性能和成本。
但是摩爾定律現在已經是百尺竿頭,逼近極限了,再進一步是難上加難。
但是性能的需求一直在增加?如何平衡這兩者關系?
因此后摩爾時代的概念被提出,后摩爾時代并不僅僅是提出新技術,新概念,延續摩爾定律, 而是從更高層面出發來定義新時代芯片如何設計,如何制造,如何平衡性能,功耗以及成本之間的關系。
在講Chiplet概念之前,還是有必要再講一段工藝制程的相關概念。
P.P.A,懂行的小伙伴都知道,它是衡量一道工藝,一顆芯片的關鍵指標,是性能(Performance),功耗(Power),以及面積尺寸(Area),是這三個英文字母的縮寫。
換言之,任何芯片都被希望有著更好的性能,更低的功耗,以及更小的面積尺寸,工程師們都希望在PPA之間尋找平衡點,兼顧性能和成本,這是為之努力的方向(工程師的真正KPI)。
當然這個目標極難實現,以至于這些工程師在還在努力過程中。
從集成電路的工藝角度而言,從45nm以下工藝開始,晶體管的真實柵極(Gate length)長度和節點工藝的命名規則,并不是一一對應關系,比如現在說14nm,7nm其實真實柵極長度并不是14nm,7nm。之所以這么叫14nm是根據上一代28nm工藝指標等效出來。
舉個例子,以上一代28nm工藝節點為標準,新一代工藝讓晶體管小了30%,功耗降低了25%,晶體管密度提高了50%,性能提升了40%,要不我們就叫他14nm工藝吧,于是14nm就這么來的。(真實數據筆者沒有認真考證,只是打個比方)
看起來似乎像文字游戲,這種等效叫法確實也造成一定的宣傳口徑不統一。例如臺積電的N7工藝和英特爾10nm工藝各方面都差不多,但是一個就是叫7nm,一個就是叫10nm,相比之下用臺積電N7工藝制造的AMD Zen系列CPU看起來就比英特爾10nm工藝制造的CPU更強些,英特爾在宣傳方面吃了個虧,10nm和7nm,明顯7nm在宣傳上更有優勢。
所以到現在這套工藝節點命名背后的邏輯,除了FAB廠里最資深的技術大佬會比較熟悉外,基本沒幾個人能說清。
不管如何,在后摩爾時代,對更高集成度,更強性能芯片追求并不會停下腳步,但是成本又非常高,如何解決問題?
繼續從高性能芯片入手,我們發現了一個問題。
以CPU為例,我們會發現,一顆CPU內部只有30%左右的面積是高性能計算單元,而70%則是SRAM(緩存單元)。
為什么會出現這樣的布局,CPU性能要強不應該是塞入更多的計算單元才變強的嗎?為什么一大半面積是SRAM?
深入研究后發現,因為瓶頸在數據存取上!
SRAM的作用是計算單元和外部內存單元之間的緩存,相當于一個臨時倉庫,它的容量比內存容量小很多,但是速度很快,主要用途是解決CPU運算速度和內存讀寫速率不匹配的矛盾。
所以算力瓶頸在運算核心和存儲器之間的矛盾,數據運算越快,就需要越大的存儲空間來放數據,而這個任務就是由CPU內部的SRAM和外部存儲來擔任,保證整體效率最高。
我們用一個比較形象的比喻就是,都是吃飯的家伙,顯然胃的容量要比口腔大很多,口腔作用就是處理數據(咀嚼食物),而胃則是存放處理過的數據(存儲食物),這么一看是不是就好理解了?
SRAM雖然速度快,但是由于占地面積大,在寸土寸金的CPU內部就顯得比較昂貴,而且SRAM的結構包括存儲單元整列(core cell array),行列地址編譯器(decode),靈敏放大器(sense amplifier),緩存驅動電路(FFIO),器件比較多,集成度對比運算單元也不高,功耗也大。
既然SRAM這么占地方,把大量寶貴的晶體管用來作為存儲數據的SRAM是不是有點虧?有沒有什么辦法來解決這個問題呢?
工程師想到的辦法是在CPU外面加上高性能的HBM高寬帶內存,來解決數據存儲和數據交互的問題。
所以大家看到現在的GPU,APU,以及AI芯片,各種xPU,各種高性能計算的芯片都是這個解決思路,在原來SoC核外面外掛一顆HBM高寬度內存,解決系統瓶頸問題。
如果這顆HBM內存顆粒放在PCB板上,顯然是無法發揮其最大性能,因為PCB布線的傳輸速度僅僅只有幾百M,顯然是不夠用的,那么只能盡可能在內部和SoC整合一起,并且用高速SerDes接口總線,把他們連起來,速度就能提升成百上千倍,系統瓶頸問題就解決一大半了!
這樣做不僅能減少SRAM的面積,把資源都堆在高性能計算單元上,最大程度提高整體性能,好鋼都用在刀刃上的思路!
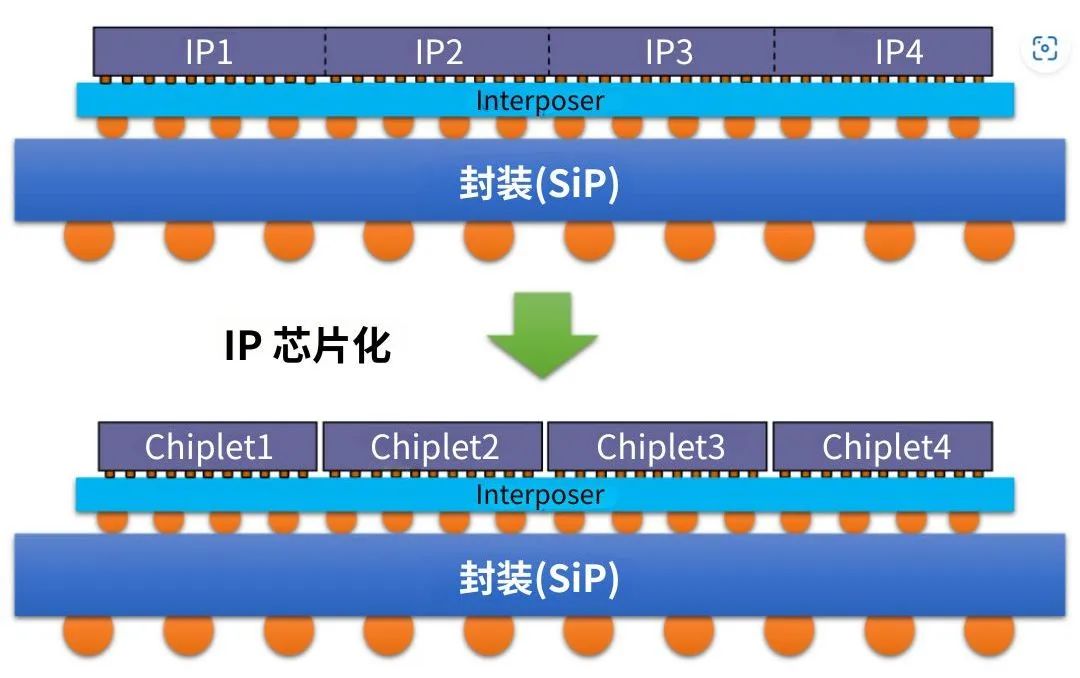
那么怎么整合到一起呢?PCB是肯定不行,SoC核內部已經定型了,也動不了,解決方案就是先進封裝,直接把兩顆裸芯粒(Die)集成到一起!
這種異構集成Chiplet的概念。
從字面上看Chiplet是小芯片的意思,但是我們從實際作用和思路可以拆解成三層概念,分別包含異構架,小芯粒和系統級集成。
1、異構架
異構架又包含兩層概念,第一是把不同類型的芯片整合到一起,比如上文提到的GPU+HBM,顯然GPU和HBEM是不同的芯片,一個是圖形計算核心單元,一個是高寬帶內存顆粒,它們設計不同,結構不同,類型不同,工藝也不同,是無法把他們在同一塊chip上制造出來的,因此它們是分開制造,再用先進封裝整合到一起。
在未來更廣闊的范圍里,我們還要整合不同材料的芯片,比如氮化鎵光電芯片+硅的驅動芯片+數模混合芯片,氮化鎵和硅屬于不同材料,更加不可能直接制造,只能是分開制造再整合到一起。
2、小芯粒
小芯粒是相對SoC大核而言,它把大核SoC各個功能區IP拆分重排,拆分成一個個小芯粒重新組合,從面不同市場出發,不同客戶的訴求出發,在成本,性能和特定功能之間找設計和制造的平衡點。
比較典型的案例如AMD的Zen 2,當時AMD就是把核心計算單元和I/O(輸入輸出單元)分開,一個用7nm,一個用14nm工藝制造,最后再封裝到一起,英特爾現在也有這種玩法,叫EMIB混合封裝,把不同的Die分開,再整合。
璧韌之前宣傳自己超過英偉達同類產品,也是利用這個思路,用112G的高速SerDes直連HBM,最大程度發揮其性能。
3、系統級集成
系統級集成又包含軟集成和硬集成兩個概念。
軟集成包含系統級軟件和操作系統以及總線互聯標準,它是把芯片設計從更高的系統角度去看,來重新定義一款芯片的誕生,軟集成是指打通底層軟件和系統。
硬集成是指的2D/2.5D/3D封裝,用先進封裝技術把他們整合一起,是先進封裝技術的再升級。
其中2D理解成同一個基板上集成,2.5D在中間層通孔硅上集成,3D真正的chip on chip的堆疊,芯片與芯片的直連。
為了幫助大家更好理解Chiplet,筆者畫了一個圖,應該更容易看懂。

關于這個系統級集成,再擴大一點概念。
以英特爾2.0的的戰略規劃為例,英特爾表面上看要干代工,但是實質上我們剖析后認為,英特爾的棋是這么下的。
從現有手中的資源來看,英特爾擁有完整的x86構架的IP,這是它的底蘊,而且,英特爾又掌控了PCIe技術聯盟標準的制定,而PCIe基礎上發展起來的CXL聯盟和UCle標準也是由英特爾主導,相當于英特爾既掌握了核心X86 IP,又掌握了非常關鍵的高速SerDes技術和標準。
有了高速SerDes的接口以及x86CPU構架,英特爾可利用它們更好地推出使用圍繞CPU做Chiplet的定制化組合,更好更快的推出新的高性能,高算力的芯片。而且,英特爾的先進工藝,和先進混合封裝技術的能力并不弱,是有希望通過商業模式創新,并打造出一個全新的英特爾2.0時代,繼續保持其強大的江湖地位。
谷歌、亞馬遜這種互聯網巨頭,這些年由于布局算力中心,數據中心,云存儲中心,投入并不少,并且也開始自研各種芯片,如AI芯片,算力芯片,加速計算芯片諸如此類的東西。
筆者認為英特爾和他們是有雙贏合作的可能性。
從商業邏輯上來講,英特爾放開x86 CPU構架給亞馬遜,讓亞馬遜圍繞自己的CPU內核做定制化改進,增減各種功能模塊,并且利用PCIe高速接口互聯把亞馬遜自研芯片的IP部分整合進來,同時英特爾又有代工能力和系統級整合能力,可以提供一站式服務。
比如wafer上切割下小芯粒后,可以利用英特爾的混合封裝能力,把各個不同的小芯粒以及高性能內存顆粒直接封裝到一起,再通過改進信號線路和供電線路的PowerVia技術,變相增加互聯密度以及控制功耗,最終得到一個基于英特爾CPU為基礎,亞馬遜特制高階定制版的HPC高性能芯片,用于他們自己的服務器和數據計算中心。
是不是看起來比給AMD代工靠譜一點?應該說算是一個比較完美的商業方案,這樣做的好處有三條:
第一,英特爾通過授權X86構架的CPU IP和PCIe技術,有利于保持英特爾CPU領域的市場份額,聯合亞馬遜自研芯片體系,最快推出產品,頂住英偉達的蠶食。
第二、有利于UCle標準的推廣,因為UCIe技術在自己手里,英特爾可以通過UCIe相關控制虛擬內存資源,將CPU內存資源開放,但是必須通過UCle來搞,這么一來,UCle標準也推出去了。
第三、英特爾提供完整平臺來解決流片、封裝的問題,提供一站式服務,形成最終英特爾深入參與的亞馬遜版本Chiplet方案芯片。
前后可以更多的利潤,還把自己主導的IP和標準推向了市場,一舉多得。
從這個角度看,英特爾2.0戰略還有點意思,至少邏輯上行得通,至于實際上怎么做,讓我們拭目以待。
06結尾
所以Chiplet完整的概念是異構架小芯粒系統級集成,Chiplet是從整體系統效率出發,兼顧成本和工藝制造的一種新的解決思路,先進封裝只是其中一部分,并不代表全部,用先進封裝去套Chiplet概念是不完整的。
對于中國而言,發展Chiplet好處很多,至少筆者認為從底層邏輯來講在性能,制造成本,時間成本之間找平衡,從未來發展角度而言,教會中國公司,如何從系統高度來看問題,來學習如何定義一款芯片,這其中會牽涉到很多新技術,新理念,正好是中國產業鏈一次自我學習,自我升級的機會。
2個14nm堆疊出7nm芯片,只是一個理想狀態,只有眾多前提條件約束,不能認為這個方案適用所有芯片。
最后再復習一遍下面這張圖。
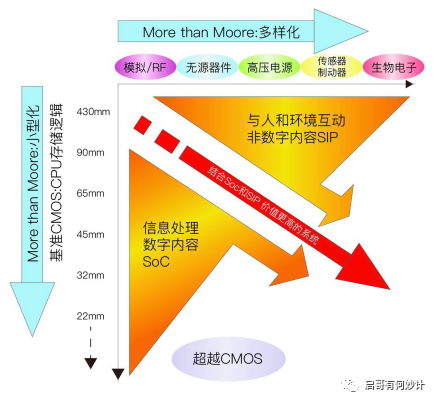
縱軸這條上依然按照傳統摩爾定律走追求更小的晶體管尺寸和更高的密度,更強的性能。
橫軸上是把不同的模擬,射頻,高壓,傳感器等不同的芯片整合到一起,追求的是多功能,高效靈活設計,異構集成,平衡性能,功能和成本之間的關系,
兩者共同組成了后摩爾時代。
審核編輯 :李倩
-
摩爾定律
+關注
關注
4文章
638瀏覽量
79745 -
晶體管
+關注
關注
77文章
9996瀏覽量
141044 -
chiplet
+關注
關注
6文章
453瀏覽量
12916
原文標題:深入淺出的聊聊摩爾定律、后摩爾時代以及Chiplet概念(萬字長文)
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
跨越摩爾定律,新思科技掩膜方案憑何改寫3nm以下芯片游戲規則
電力電子中的“摩爾定律”(1)

淺談Chiplet與先進封裝
瑞沃微先進封裝:突破摩爾定律枷鎖,助力半導體新飛躍

Chiplet:芯片良率與可靠性的新保障!

2.5D集成電路的Chiplet布局設計
混合鍵合中的銅連接:或成摩爾定律救星

石墨烯互連技術:延續摩爾定律的新希望
摩爾定律是什么 影響了我們哪些方面
對話郝沁汾:牽頭制定中國與IEEE Chiplet技術標準,終極目標“讓天下沒有難設計的芯片”

后摩爾定律時代,提升集成芯片系統化能力的有效途徑有哪些?
高密度互連,引爆后摩爾技術革命
高算力AI芯片主張“超越摩爾”,Chiplet與先進封裝技術迎百家爭鳴時代






 工商網監
工商網監
評論