") 為什么說AI推理芯片大有可為?
為什么說AI推理芯片大有可為?
近年來科技熱潮一波接一波,2013年、2014年開始倡議物聯(lián)網(wǎng)、穿戴式電子,2016年開始人工智能,2018年末則為5G。人工智能過往在1950年代、1980年代先后熱議過,但因多項技術(shù)限制與過度期許而回復(fù)平淡,2016年隨云端資料日多與影音辨識需求再次走紅(圖1)。
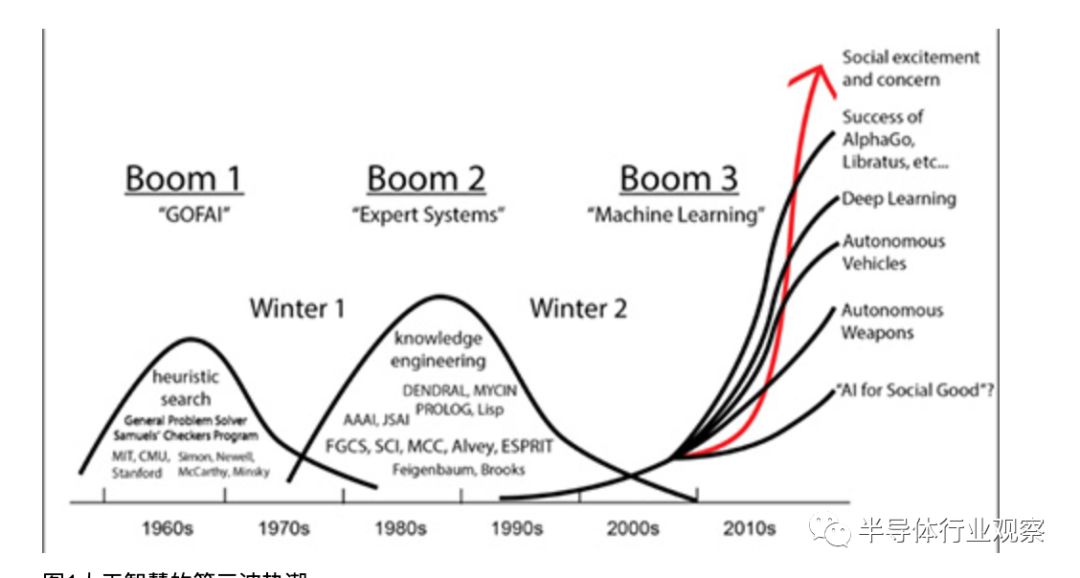
圖1人工智能的第三波熱潮。
人工智能的運用分成兩個階段,一是學習訓練階段,二是推理階段,此與應(yīng)用程序相類似,程序開發(fā)階段即為學習訓練階段,程序正式上線執(zhí)行運作則為推理階段。開發(fā)即是船艦在船塢內(nèi)打造或維修,執(zhí)行則為船艦出海航行作業(yè)執(zhí)勤(圖2)。
圖2人工智能訓練與推理的差別。
訓練與推理階段對運算的要求有所不同,訓練階段需要大量繁復(fù)的運算,且為了讓人工智能模型獲得更佳的參數(shù)調(diào)整數(shù)據(jù),運算的精準細膩度較高,而推理階段則相反,模型已經(jīng)訓練完成,不再需要龐大運算量,且為了盡快獲得推理結(jié)果,允許以較低的精度運算。
例如一個貓臉辨識應(yīng)用,訓練階段要先提供成千上萬張各種帶有貓臉的照片來訓練,并從中抓出各種細膩辨識特點,但真正設(shè)置在前端負責辨識來者是否為貓的推理運算,只是辨識單張臉,運算量小,且可能已簡化特征,只要簡單快速運算即可得到結(jié)果(是貓或不是)。
推理專用芯片需求顯現(xiàn)
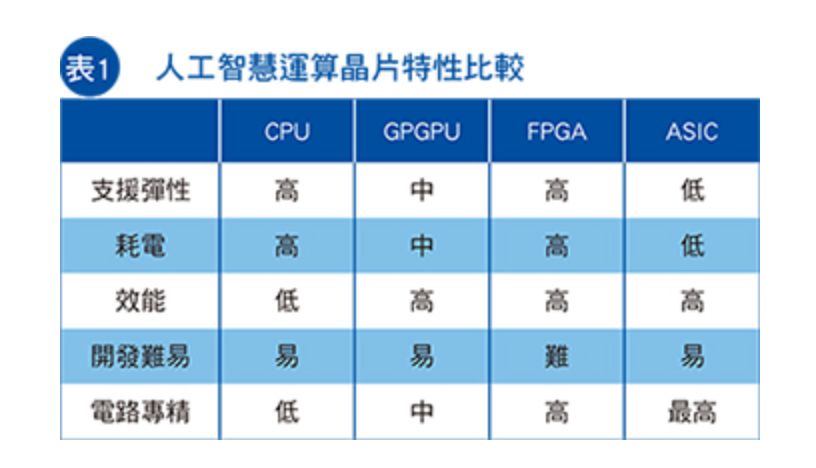
對于人工智能的訓練、推理運算,近年來已普遍使用CPU之外的芯片來加速,例如GPGPU、FPGA、ASIC等,特別是GPGPU為多,原因在于GPGPU的高階軟體生態(tài)較為完備、可支援多種人工智能框架(Framework),相對的FPGA需要熟悉低階硬體電路者方能開發(fā),而ASIC通常只針對限定的軟體或框架最佳化(表1)。雖然FPGA與ASIC較有難度與限制,但仍有科技大廠愿意投入,如Microsoft即主張用FPGA執(zhí)行人工智能運算,Google則針對TensorFlow人工智能框架開發(fā)ASIC,即Cloud TPU芯片。
人工智能模型的開發(fā)(訓練)與執(zhí)行(推理)過往多使用同一芯片,用該芯片執(zhí)行訓練運算后也用該芯片執(zhí)行推理運算。但近1、2年來隨著訓練成果逐漸增多,成熟的人工智能模型逐漸普及,以相同芯片負責推理運算的缺點逐漸浮現(xiàn)。以GPGPU而言,芯片內(nèi)具備大量的平行運算單元是針對游戲繪圖、專業(yè)繪圖或高效能運算而設(shè)計,可運算32、64位元浮點數(shù),這在人工智能模型訓練階段亦適用,但到推理階段,可能只需16位元浮點、16位元整數(shù)、8位元整數(shù)等運算即可求出推理結(jié)果,甚至是4位元整數(shù)便足夠。如此過往的高精度大量平行運算單元便大材小用,電路與功耗均有所浪費,所以需要人工智能的推理專用處理芯片。
半導(dǎo)體廠紛發(fā)展推理芯片
推理芯片的需求在人工智能重新倡議后的2年開始浮現(xiàn),但在此之前已有若干產(chǎn)品,如2014年Google對外揭露的探戈專案(Project Tango)即使用Movidius公司的Myriad芯片(圖3)。
圖3 Intel Movidius Myriad X芯片
Movidius之后于2016年推出Myriad 2芯片,同樣也在2016年,Intel購并Movidius取得Myriad 1/2系列芯片,并接續(xù)推出Myriad X芯片。Google除探戈專案外其他硬體也采用Intel/Movidius芯片,如2017年的Google Clips人工智能攝影機、2018年Google AIY Vision人工智能視覺應(yīng)用開發(fā)套件等。
不過真正受業(yè)界矚目的仍在2018年,包含NVIDIA推出T4芯片(嚴格而論是已帶芯片的加速介面卡)(圖4)、Google推出Edge TPU芯片(圖5),以及Amazon Web Services在2018年11月宣告將在2019年推出Inferentia芯片,均為推理型芯片。
圖4 NVIDIA展示T4介面卡
圖5 Google Edge TPU小于一美分銅板。
另外,臉書(Facebook)也已經(jīng)意識到各形各色的推理型芯片將會在未來幾年內(nèi)紛紛出籠,為了避免硬體的多元分歧使軟體支援困難,因此提出Glow編譯器構(gòu)想,期望各人工智能芯片商能一致支援該編譯標準,目前Intel、Cadence、Marvell、Qualcomm、Esperanto Technologies(人工智能芯片新創(chuàng)業(yè)者)均表態(tài)支持。
與此同時,臉書也坦承開發(fā)自有人工智能芯片中,并且將與Intel技術(shù)合作;目前臉書技術(shù)高層已經(jīng)表示其芯片與Google TPU不相同,但是無法透露更多相關(guān)的技術(shù)細節(jié)。而Intel除了在2016年購并Movidius之外,在同一年也購并了另一家人工智能技術(shù)業(yè)者Nervana System,Intel也將以Nervana的技術(shù)發(fā)展推理芯片。
推理芯片不單大廠受吸引投入新創(chuàng)業(yè)者也一樣積極,Habana Labs在2018年9月對特定客戶提供其推理芯片HL-1000的工程樣品,后續(xù)將以該芯片為基礎(chǔ)產(chǎn)制PCIe介面的推理加速卡,代號Goya。Habana Labs宣稱HL-1000是目前業(yè)界最快速的推理芯片(圖6)。
圖6 Habana Labs除推出HL-1000推理芯片Goya外也推出訓練芯片Gaudi。
云端機房/快速反應(yīng)推理芯片可分兩種取向
透過前述可了解諸多業(yè)者均已投入發(fā)展推理芯片,然嚴格而論推理芯片可分成兩種取向,一是追求更佳的云端機房效率,另一是更快速即時反應(yīng)。前者是將推理芯片安置于云端機房,以全職專精方式執(zhí)行推理運算,與訓練、推理雙用型的芯片相比,更省機房空間、電能與成本,如NVIDIA T4。
后者則是將推理芯片設(shè)置于現(xiàn)場,例如配置于物聯(lián)網(wǎng)閘道器、門禁攝影機內(nèi)、車用電腦上,進行即時的影像物件辨識,如Intel Movidius Myriad系列、Google Edge TPU等。
設(shè)置于機房內(nèi)的推理芯片由于可自電源插座取得源源不絕的電能,因此仍有數(shù)十瓦用電,如NVIDIA T4的TDP(Thermal Design Power)達70瓦,相對的現(xiàn)場設(shè)置的推理芯片必須適應(yīng)各種環(huán)境可能,例如僅以電池供電運作,因此盡可能節(jié)約電能,如Google Edge TPU的TDP僅1.8瓦。現(xiàn)場型目前觀察僅有車用例外,由于汽車有蓄電瓶可用,電能充沛性居于電池與電源插座間,因此芯片功耗表現(xiàn)可高些。
為能快速反應(yīng)推理芯片精度須調(diào)整
如前所述,推理芯片為能即時快速求解,通常會采較低精度進行運算,過去過于高效能運算的64位元雙精度浮點數(shù)(Double Precision, DP),或用于游戲與專業(yè)繪圖的32位元單精度浮點數(shù)(Single Precision, SP)可能都不適用,而是降至(含)16位元以下的精度。
例如Intel Movidius Myriad X原生支援16位元浮點數(shù)(新稱法為半精度Half-Precision, HP)與8位元整數(shù);Google Edge TPU則只支援8位元、16位元整數(shù),未支援浮點數(shù);NVIDIA T4則支援16與32位元浮點數(shù)外,也支援8位元與4位元整數(shù)。
進一步的,推理芯片可能同時使用兩種以上的精度運算,例如NVIDIA T4可同時執(zhí)行16位元浮點數(shù)與32位元浮點數(shù)的運算,或者尚未推出的AWS Inferentia宣稱將可同時執(zhí)行8位元整數(shù)與16位元浮點數(shù)的運算(圖7),同時使用兩種以上精度的作法亦有新詞,稱為混精度(Mixed Precision, MP)運算。
圖7 AWS預(yù)告2019年將推出自家推理芯片Inferentia,將可同時推算整數(shù)與幅點數(shù)格式。圖片來源:AWS
上述不同位元表達長度的整數(shù)、浮點數(shù)格式,一般寫成INT4(Integer)、INT8、FP16、FP32(Float Point)等字樣,另也有強調(diào)可針對不帶正負表達,單純正整數(shù)表達的格式運算,如Habana Labs的HL-1000強調(diào)支援INT8/16/32之余,也支援UINT8/16/32格式,U即Unsigned之意。
推理芯片雖然支援多種精度格式,然精度愈高運算效能也會較低,以NVIDIA T4為例,在以INT4格式推算下可以有260 TOPS的效能,亦即每秒有260個Tera(10的12次方)運算,而改以INT8格式時則效能減半,成為130 TOPS,浮點格式也相同,以FP16格式運算的效能為65 TFOPS(F=Float),而以FP32格式運算則降至8.1 TFLOPS,浮點格式的位元數(shù)增加一倍效能退至1/8效能,比整數(shù)退減程度高。
推理芯片前景仍待觀察芯片商須步步為營
推理芯片是一個新市場,重量級芯片業(yè)者與新興芯片商均積極投入發(fā)展,但就數(shù)個角度而言其后續(xù)發(fā)展難以樂觀,主要是超規(guī)模(Hyperscale)云端機房業(yè)者自行投入發(fā)展。
例如Google在云端使用自行研發(fā)的Cloud TPU芯片,針對Google提出的人工智能框架TensorFlow最佳化,如此便限縮了Intel、NVIDIA的機會市場(雖然2019年1月NVIDIA T4已獲Google Cloud采用并開放Beta服務(wù))。而Google也在2018年提出針對人工智能框架TensorFlow Lite最佳化的Edge TPU,如此也可能排擠過往已使用的Intel Movidius芯片。
類似的,臉書過去使用NVIDIA Tesla芯片,但隨著臉書力主采行PyTorch技術(shù),以及與Intel合作發(fā)展人工智能芯片,未來可能減少購置NVIDIA芯片。而Intel與臉書合作開發(fā),也意味著臉書無意購置Intel獨立自主發(fā)展的人工智能芯片,即便Intel于此合作中獲得收益,也比全然銷售完整芯片來得少,Intel須在技術(shù)上有所讓步妥協(xié),或提供客制服務(wù)等。
AWS方面也相同,AWS已宣告發(fā)展自有推理芯片,此意味著NVIDIA T4的銷售機會限縮,其他業(yè)者的推理芯片也失去一塊大商機。AWS同樣有其人工智能技術(shù)主張,如MXNet。
如此看來,人工智能芯片的軟體技術(shù)主導(dǎo)權(quán)與芯片大買家,均在超規(guī)模機房業(yè)者身上,芯片商獨立研發(fā)、獨立供應(yīng)人工智能芯片的機會將降低,未來遷就超規(guī)模機房業(yè)者,對其提供技術(shù)合作與客制的可能性增高。因此推理芯片會以企業(yè)為主要市場,多數(shù)企業(yè)面對芯片商并無議價能力、技術(shù)指導(dǎo)能力,仍會接受芯片商自主研發(fā)銷售的芯片。
訓練/推理兩極化
除了推理芯片市場外,人工智能的訓練芯片市場也值得觀察,由于人工智能應(yīng)用的開發(fā)、訓練、參數(shù)調(diào)整等工作并非時時在進行,通常在歷經(jīng)一段時間的密集開發(fā)訓練后回歸平淡,直到下一次修改調(diào)整才再次進入密集運算。類似船只多數(shù)時間出海航行,僅少數(shù)時間進入船塢整修,或軟體多數(shù)時間執(zhí)行,少數(shù)時間進行改版修補。
因此,企業(yè)若為了人工智能應(yīng)用的開發(fā)訓練購置大量的伺服器等運算力,每次訓練完成后,大量的伺服器將閑置無用,直到下一次參數(shù)調(diào)整、密集訓練時才能再次顯現(xiàn)價值。鑒于此,許多企業(yè)傾向?qū)⒚芗柧毜倪\算工作交付給云端服務(wù)供應(yīng)商,依據(jù)使用的運算量、運算時間付費,而不是自行購置與維護龐大運算系統(tǒng),如此訓練芯片的大買家也會是云端服務(wù)商。
不過企業(yè)須要時時運用人工智能的推理運算,如制造業(yè)的生產(chǎn)良率檢測、醫(yī)療業(yè)的影像診斷等,部份推理運算不講究即時推算出結(jié)果,亦可拋丟至云端運算,之后再回傳運算結(jié)果,但追求即時反應(yīng)者仍須要在前端現(xiàn)場設(shè)置推算芯片,此即為一可爭取的市場,除了獨立的芯片商Intel、NVIDIA積極外,云端業(yè)者也在爭取此市場,如Google已宣布Edge TPU不僅自用也將對外銷售,國內(nèi)的工控電腦業(yè)者已有意配置于物聯(lián)網(wǎng)閘道器中。
由此看來,人工智能軟體技術(shù)的標準走向、訓練芯片的大宗買家、訓練的運算力服務(wù)等均為超規(guī)模業(yè)者,加上推理芯片的自主化,推理與訓練的前后整合呼應(yīng)等,均不利芯片商的發(fā)展,芯片商與超規(guī)模業(yè)者間在未來數(shù)年內(nèi)必須保持亦敵亦友的態(tài)勢,一方面是大宗芯片的買家,另一方面是技術(shù)的指導(dǎo)者、潛在的芯片銷售競爭者。
所以,未來的企業(yè)將會減少購置訓練用的人工智能芯片,并盡可能的使用云端運算力進行短暫且密集的訓練;而對于時時與現(xiàn)場營運連結(jié)的部份,則會配置推理用芯片,且以即時反應(yīng)、低功耗的推理芯片為主。至于機房端的推理芯片,仍然會是云端業(yè)者為主要采購者,次之為大企業(yè)為自有機房而添購,以增進機房運算效率為主。
由上述來看似乎云端服務(wù)商占足優(yōu)勢,不過科技持續(xù)變化中,目前已有人提出供需兩端均分散的作法,即家家戶戶釋出閑置未用的CPU、GPU運算力,匯集成龐大的單一運算力,供有密集訓練需求的客戶使用。
此作法甚至導(dǎo)入區(qū)塊鏈技術(shù),供需雙方采代幣系統(tǒng)運作,需要運算力者購買數(shù)位代幣,釋出運算力者可獲得代幣,代幣再透過市場交易機制與各地的法定發(fā)行貨幣連結(jié),如此可跳略過云端供應(yīng)商,一樣在短時間獲得密集運算力。
不過,完全零散調(diào)度型的作法,仍有可能無法即時湊得需求運算力,或因為在全球各地調(diào)度運算力,反應(yīng)速度恐有不及,且發(fā)展者多為小型新創(chuàng)業(yè)者,現(xiàn)階段仍難對AWS、Google等大型云端服務(wù)商競爭,僅能若干削弱其價值,追求穩(wěn)定充沛效能者仍以AWS、Google為首選。
面對完全分散化的趨勢,國際大型云端業(yè)者亦有所因應(yīng),例如AWS原即有EC2 Spot Instance服務(wù),對于機房閑置未租出去的運算效能,或有人臨時退租退用所釋出的效能,能夠以折扣方式再賣或轉(zhuǎn)讓,類似客機即將起飛,未賣盡的座位票價較低廉,或飯店將入夜的空房折扣租出等,以便減少固定成本的負擔。
不過,Spot Instance這類的超折扣機會可遇不可求,或有諸多限制(最高僅能連續(xù)運算6個小時),以便維持正規(guī)租用者的質(zhì)感,如此與前述完全分散化的運算調(diào)度服務(wù)相去不遠,均帶有較高的不確定性。
-
芯片
+關(guān)注
關(guān)注
459文章
52267瀏覽量
437210 -
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2927文章
45981瀏覽量
388993 -
AI
+關(guān)注
關(guān)注
88文章
34457瀏覽量
275862 -
5G
+關(guān)注
關(guān)注
1360文章
48746瀏覽量
570795
原文標題:為什么說AI推理芯片大有可為
文章出處:【微信號:iawbs2016,微信公眾號:寬禁帶半導(dǎo)體技術(shù)創(chuàng)新聯(lián)盟】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
輕量化、低功耗,邊緣計算芯片在儲能中大有可為
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命

谷歌新一代 TPU 芯片 Ironwood:助力大規(guī)模思考與推理的 AI 模型新引擎?
AI推理帶火的ASIC,開發(fā)成敗在此一舉!

黑芝麻智能芯片加速DeepSeek模型推理
使用NVIDIA推理平臺提高AI推理性能

解析DeepSeek MoE并行計算優(yōu)化策略
生成式AI推理技術(shù)、市場與未來

炬芯科技:混合AI架構(gòu)大有可為,2025端側(cè)AI是IoT設(shè)備關(guān)鍵

芯和半導(dǎo)體:國產(chǎn)EDA大有可為
蘇茨克維預(yù)測:推理型AI將帶來不可預(yù)測性
AI推理CPU當?shù)溃珹rm驅(qū)動高效引擎

AMD助力HyperAccel開發(fā)全新AI推理服務(wù)器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論