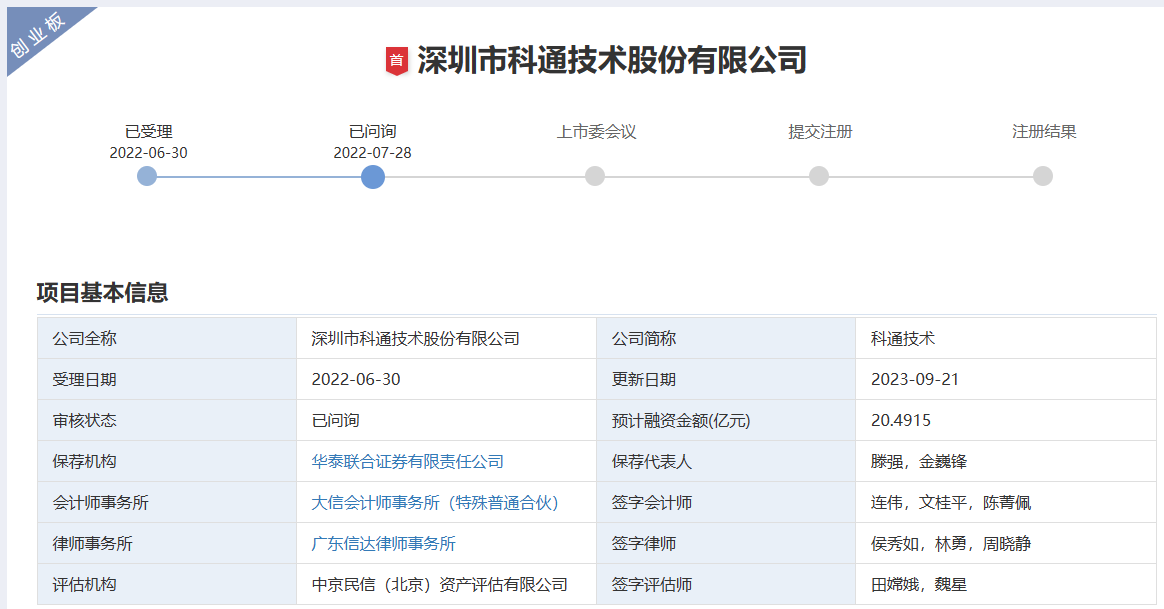
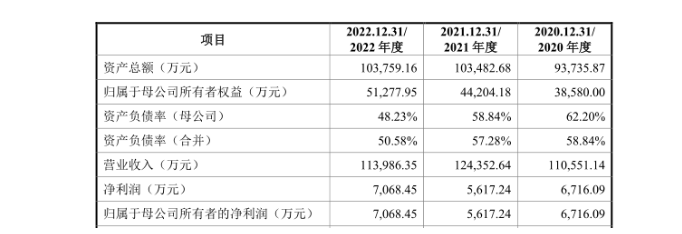
 電子發(fā)燒友App
電子發(fā)燒友App


知識圖譜的最新進展、關(guān)鍵技術(shù)和挑戰(zhàn)
人工智能技術(shù)與咨詢?
本文來自《?工程科學學報?》,作者馬忠貴等
隨著知識的不斷積累和科學的飛速發(fā)展,人類社會進行了多次改變社會結(jié)構(gòu)的重大生產(chǎn)力革命。最近的生產(chǎn)力革命正是由Web技術(shù)發(fā)展引發(fā)的信息革命。伴隨著Web技術(shù)不斷地演進與發(fā)展,人類即將邁向基于知識互聯(lián)的嶄新“Web3.0”時代[1]。受語義網(wǎng)絡(luò)(Semantic network)和語義網(wǎng)(Semantic web)的啟發(fā),Google公司提出了知識圖譜(Knowledge graph)[2],目的是為了提高搜索引擎的智能能力,增強用戶的搜索質(zhì)量和體驗。隨后,這一概念被傳播開來,并廣泛應用于醫(yī)療、教育、金融、電商等行業(yè)中,推動人工智能從感知智能向認知智能跨越。目前,已經(jīng)涌現(xiàn)出一大批知識圖譜,其中國外具有代表性的有YAGO[3]、DBpedia[4]、Freebase[5]、NELL[6]、Probase[7]等;國內(nèi)出現(xiàn)了開放知識圖譜項目OpenKG[8],中文知識圖譜CN-DBpedia[9]、zhishi.me[10]等。知識圖譜的本質(zhì)是連接實體間關(guān)系的圖,即揭示實體之間關(guān)系的語義網(wǎng)絡(luò)[11],普遍采用資源描述框架(Resource description framework,RDF)來描述知識。知識圖譜全生命周期主要包括3種關(guān)鍵技術(shù):(1)從樣本源中獲取數(shù)據(jù),并將其表示為結(jié)構(gòu)化知識的知識抽取與表示技術(shù);(2)融合異源知識的知識融合技術(shù);(3)根據(jù)知識圖譜中已有的知識進行知識推理和質(zhì)量評估。
近幾年,越來越多的學者將目光聚焦在了認知智能上,知識圖譜受到越來越廣泛的關(guān)注。除了知識圖譜的技術(shù)文章爆發(fā)式增長之外,綜述文章也越來越多。文獻[11]針對知識圖譜的相關(guān)技術(shù)進行了全面解析,文獻[12-13]綜述了知識圖譜核心技術(shù)的研究進展以及典型應用,文獻[14]總結(jié)了面向知識圖譜的推理方法并展望了未來的研究方向,文獻[15]定義知識圖譜與本體的關(guān)系并簡述了已開發(fā)的國內(nèi)外知識圖譜。2019年年末和2020年年初,國內(nèi)有3本知識圖譜的專著問世[16-18],我們有了寫作本論文的動機。與已有的綜述文獻相比,本文的主要貢獻如下:梳理了知識圖譜全生命周期技術(shù),從知識抽取與表示、知識融合、知識推理、知識應用4個層面展開綜述,建立方法論思維。限于篇幅,針對知識圖譜的4個關(guān)鍵技術(shù)進行了取舍,重點介紹了知識融合與知識推理技術(shù)的最新進展。同時,簡要介紹了知識圖譜目前的挑戰(zhàn)并展望了未來的發(fā)展方向。
1.?? 知識抽取與表示
對于知識圖譜而言,首要的問題是:如何從海量的數(shù)據(jù)提取有用信息并將得到的信息有效表示并儲存,就是所謂的知識抽取與表示技術(shù)。知識抽取與表示,也可以稱為信息抽取,其目標主要是從樣本源中抽取特定種類的信息,例如實體、關(guān)系和屬性,并將這些信息通過一定形式表達并儲存。對于知識圖譜,一般而言采用RDF描述知識,形式上將有效信息表示為(主語,謂語,賓語)三元組的結(jié)構(gòu),某些文獻中也表示為(頭實體,關(guān)系,尾實體)的結(jié)構(gòu)。針對信息抽取種類的不同,知識抽取又可分為實體抽取、關(guān)系抽取以及屬性抽取。圖1展示了知識圖譜的技術(shù)架構(gòu)。
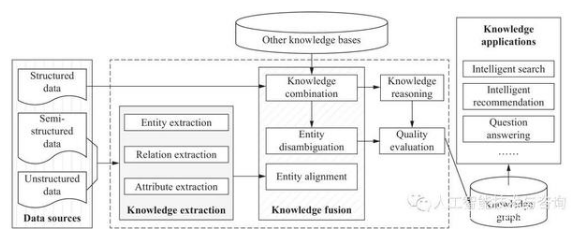
圖? 1? 知識圖譜的技術(shù)架構(gòu)
Figure? 1.? Architecture of the Knowledge Graph
實體抽取也稱為命名實體識別,主要目標是從樣本源中識別出命名實體。實體是知識圖譜最基本的元素,實體抽取的完整性、準確率、召回率將直接影響知識圖譜的質(zhì)量[12]。文獻[19]將實體抽取的方法歸納為3種:(1)基于規(guī)則與詞典的方法。通常需要為目標實體編寫相應的規(guī)則,然后在原始語料中進行匹配,Quimbaya等[20]提出了一個基于詞典的實體抽取方法,并應用于電子健康記錄。(2)基于統(tǒng)計機器學習的方法。主要利用數(shù)據(jù)來對模型進行訓練,然后再利用訓練好的模型去識別實體,Liu等[21]將K近鄰(K-nearest neighbors,KNN)算法和線性條件隨機場(Conditional random fields,CRF)模型結(jié)合來識別實體。(3)面向開放域的抽取方法。主要是針對海量網(wǎng)絡(luò)數(shù)據(jù),Jain與Pennacchiotti[22]提出通過已知實體的語義特征來識別命名實體,并提出實體聚類的無監(jiān)督開放域聚類算法。Zhang與Elhadad[23]提出一個無監(jiān)督的實體抽取方法,利用術(shù)語、語料庫統(tǒng)計信息以及淺層語法知識從生物醫(yī)學中抽取實體。
通過實體抽取獲取的實體之間往往是離散且無關(guān)聯(lián)的。通過關(guān)系抽取,可以建立起實體間的語義鏈接。關(guān)系抽取技術(shù)主要分為3種:(1)基于模板的關(guān)系抽取。使用模板通過人工或者機器學習的方法抽取實體關(guān)系,雖然準確率高且針對性強,但是其也具有不適用于大規(guī)模數(shù)據(jù)集、低召回率、難以維護等缺點。(2)基于監(jiān)督學習的關(guān)系抽取。將大量人工標注的數(shù)據(jù)送入模型中訓練,劉克彬等[24]根據(jù)本體知識庫訓練模型,在開放數(shù)據(jù)集中對關(guān)系進行抽取,取得了極高的準確率。Sun與Han[25]提出了名為FTK(Feature-enriched tree kernel)的模型,利用設(shè)計好的有效特征訓練,計算關(guān)系實例相似度并通過支持向量機對關(guān)系進行分類。(3)基于半監(jiān)督或無監(jiān)督學習的關(guān)系抽取。基于少量人工標注數(shù)據(jù)或者無標注數(shù)據(jù),使用最大期望(Expectation maximization)等算法的半監(jiān)督關(guān)系抽取方法進行關(guān)系抽取。Sun與Grishman[26]提出名為LGCo-Testing的主動學習系統(tǒng),F(xiàn)u與Grishman[27]則進一步優(yōu)化了這個系統(tǒng)。Ji等[28]提出基于句子級注意力和實體描述的神經(jīng)網(wǎng)絡(luò)關(guān)系抽取模型APCNNS。該模型實際采用了多示例學習的策略,將同一關(guān)系的樣例句子組成樣例包,關(guān)系分類是基于樣例包的特征進行的。實驗結(jié)果表明,該模型可以有效地提高遠程監(jiān)督關(guān)系抽取的準確率。在采用多示例學習策略時,有可能出現(xiàn)整個樣例包都包含大量噪聲的情況。針對這一問題,F(xiàn)eng等[29]提出了基于強化學習的關(guān)系分類模型CNN-RL(Convolutional neural networks and reinforcement learning),該模型包括2個重要模塊:樣例選擇器和關(guān)系分類器。實驗結(jié)果表明:該模型獲得了比句子級卷積神經(jīng)網(wǎng)絡(luò)和樣例包級關(guān)系分類模型更好的結(jié)果。最近的工作通過強化學習來處理句子級的去噪,這種學習將來自遠程監(jiān)督的標簽視為事實。然而,很少有工作專注于直接校正噪聲標簽的標簽級降噪。Sun等[30]提出了一種基于強化學習的標簽去噪方法,用于遠程監(jiān)督關(guān)系提取。該模型由兩個模塊組成:抽取網(wǎng)絡(luò)和策略網(wǎng)絡(luò)。標簽去噪的核心是在策略網(wǎng)絡(luò)中設(shè)計一個策略來獲取潛在標簽,可以在其中選擇使用遠距離監(jiān)督標簽或從抽取網(wǎng)絡(luò)預測標簽的操作。實驗結(jié)果表明,強化學習對于噪聲標簽的校正是有效的,并且所提出的方法可以勝過最新的關(guān)系抽取系統(tǒng)。
屬性抽取的目標是補全實體信息,通過從樣本源中獲取實體屬性信息或?qū)傩灾怠嶓w屬性可以看作是屬性值與實體間的一種關(guān)系,因而可以通過關(guān)系抽取的解決思路來獲得。Wu與Weld[31]利用百科類網(wǎng)站的半結(jié)構(gòu)化數(shù)據(jù),訓練抽取模型,之后將抽取模型應用在非結(jié)構(gòu)化數(shù)據(jù)中抽取屬性。Chang等[32]提出了基于張量分解的關(guān)系抽取方法,這一方法也可以應用在屬性抽取中,通過利用關(guān)于實體種類相應的領(lǐng)域知識來更好地獲得實體所缺少的屬性值。
2.?? 知識融合
通過知識抽取與表示,初步獲得了數(shù)量可觀的形式化知識。由于知識來源的不同,導致知識的質(zhì)量參差不齊,知識之間存在著沖突或者重疊。此時初步建立的知識圖譜,知識的數(shù)量和質(zhì)量都有待提高。應用知識融合技術(shù)對多源知識進行處理,一方面提升知識圖譜的質(zhì)量,另一方面豐富知識的存量。Zhao等[33]對最新的知識融合進行了綜述。早期的知識融合是通過傳統(tǒng)的數(shù)據(jù)融合方法完成,Dong等[34]比較了傳統(tǒng)的數(shù)據(jù)融合方法,選擇了幾種方法改良,并應用到知識融合中。隨著知識圖譜的飛速發(fā)展,目前也出現(xiàn)了專門的知識融合方法。下面從實體消歧、實體對齊和知識合并3個方面進行綜述。
2.1?? 實體消歧
對于知識圖譜中的每一個實體都應有清晰的指向,即明確對應某個現(xiàn)實世界中存在的事物。初步構(gòu)建的知識圖譜中,因數(shù)據(jù)來源復雜,存在著同名異義的實體。例如,名稱為“喬丹”的實體既可以指美國著名籃球運動員,也可以指葡萄牙足球運動員,還可以指某個運動品牌。為了確保每一個實體有明確的含義,采用實體消歧技術(shù)來使得同名實體得以區(qū)分。
利用已有的知識庫和知識圖譜中隱含的信息來幫助進行語義消歧,Han與Zhao[35]提出使用維基百科(Wikipedia)作為背景知識,通過利用Wikipedia的語義知識,例如社會關(guān)系來更精確地衡量實體間的相似性,從而提升實體消歧的效果。Sen[36]提出了主題模型,利用知識庫中存在的文本信息,學習共有實體組來實現(xiàn)實體集體消歧。Guo與Barbosa[37]基于語義相似性的自然概念提出了兩個針對集體消歧的方法。通過在知識庫上知識子圖中隨機游走得到的概率分布來表示實體和文檔的語義,之后基于迭代的貪婪逼近算法和學習排序的方法來進行實體消歧任務。Zhu與Iglesias[38]提出了基于語義上下文相似度的命名實體消歧方法,基于上下文和知識圖譜中實體的信息詞之間的語義相似度來進行實體消歧。另外還提出了Category2Vec模型,將目錄也用嵌入向量的形式表示出來。主要思想是候選實體和上下文單詞間應存在語義聯(lián)系,利用該聯(lián)系來幫助選出正確的實體。
在線百科全書由專家和網(wǎng)絡(luò)用戶編寫,有著高覆蓋率和結(jié)構(gòu)信息豐富的特點。Shen等[39]提出LINDEN(A framework for Linking named entities with knowledge base?via?semantic knowledge)模型,同時利用Wikipedia和WordNet,基于文本相似性和主題一致性進行實體消歧。Ratinov等[40]提出名為GLOW(Global and local approaches of Wikipedia)的系統(tǒng),GLOW組合捕捉實體指稱與Wikipedia題目間的相關(guān)性的本地模型和選擇準確歧義語境的方法。統(tǒng)計Wikipedia中實體的頻率作為候選實體的排序依據(jù)。Alokaili與Menai[41]提出了基于支持向量機的集成學習來解決實體消歧問題,使用不同的支持向量機的核函數(shù)來學習不同的集成學習算法,例如bagging、boosing、voting等。具體流程是將命名實體作為輸入,根據(jù)Wikipedia中的知識生成候選實體,構(gòu)造特征向量,最后送入集成學習模塊里完成實體消歧。
值得一提的是,Agarwal等[42]提出了利用時間的實體消歧思路,通過計算實體的時序特征來和輸入的命名實體上下文的時序比較,即使命名實體的上下文提供的信息不充分也可以完成實體消歧任務。Dong[43]將基于相似度特征的隨機森林模型和基于XGBoost、基于邏輯回歸以及基于神經(jīng)網(wǎng)絡(luò)的方法進行比較,隨機森林模型不僅擁有極高的準確率和召回率,且不像XGBoost和神經(jīng)網(wǎng)絡(luò)那樣容易受到超參數(shù)的影響,在實體消歧任務中表現(xiàn)突出。
2.2?? 實體對齊
在現(xiàn)實生活中,一個事物對應著不止一個稱呼,例如,“中華人民共和國”和“中國”都對應于同一個實體。在知識圖譜中也同樣存在著同義異名的實體,通過實體對齊,將這些實體指向同一客觀事物。蘇佳林等[44]提出基于決策樹的自適應屬性選擇的實體對齊方法。通過聯(lián)合學習將實體嵌入表示在一個向量空間后,由信息增益選出最優(yōu)約束屬性,訓練實體對齊模型,計算最優(yōu)約束屬性相似度和實體語義相似度完成實體對齊。
Cheng等[45]提出了一個全自動的實體對齊框架,包括候選實體生成器、選擇器和清理器,利用搜索引擎使用者的查詢信息和查詢后的點擊記錄,計算出實體間的相似度,完成實體對齊任務。Pantel等[46]提出了一個大規(guī)模相似性模型,在MapReduce框架下實施并且部署了超過2000億從互聯(lián)網(wǎng)上爬取得到的單詞。通過計算5億terms得到的相似度矩陣來進行實體對齊任務。Chakrabarti等[47]通過一個同義發(fā)現(xiàn)框架將實體相似性作為輸入生成一個滿足簡單自然屬性的同義詞,提出了兩種新的相似性度量法,并通過在bing系統(tǒng)上實際應用,發(fā)現(xiàn)可以有效識別同義詞。Mudgal等[48]綜述了基于深度學習的實體對齊方法,通過將這些方法分類,分別組合設(shè)計空間中屬性嵌入、屬性相似度表示、分類的各個方法,得到最具代表性的平滑倒詞頻(Smooth inverse frequency,SIF)、循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent neural network,RNN)、Attention和Hybrid共4種解決方案。
針對基于嵌入表示的實體對齊,Sun等[49]提出自舉的方法解決標記訓練數(shù)據(jù)不足的問題。根據(jù)全局最優(yōu)目標來標記可能的對齊,并在迭代中將其加入到訓練數(shù)據(jù)中,不斷訓練嵌入表示模型。Guan等[50]發(fā)現(xiàn)基于監(jiān)督學習的實體對齊方法,普遍在取得標簽數(shù)據(jù)上需要花費大量時間,無監(jiān)督學習方法的表現(xiàn)則很大程度地依賴于驗證集上復雜的相似度衡量方式。Zhang等[51]從實體的多視角出發(fā),利用實體的名稱、實體間的關(guān)系、實體的屬性的組合策略來學習實體的嵌入,并根據(jù)實體的表示來完成實體對齊任務。
2.3?? 知識合并
實體消歧和實體對齊更多的是關(guān)注知識圖譜中的實體,從實體層面上通過各種方法來提升知識圖譜的知識質(zhì)量。知識合并則是從知識圖譜整體層面上進行知識的融合,基于現(xiàn)存的知識庫和知識圖譜來擴大知識圖譜的規(guī)模,豐富其中蘊含的知識。然而現(xiàn)存的知識庫或者知識圖譜都是各種機構(gòu)或者組織根據(jù)自己的需求設(shè)計創(chuàng)建,其中的知識也存在著多樣性和異構(gòu)性,并且存在很多知識上的重復和錯誤,因而需要使用知識合并技術(shù)來解決這些問題[52]。知識圖譜的合并需要解決2個層面的問題:數(shù)據(jù)層的合并和模式層的合并[53]。知識合并過程中可能出現(xiàn)的來自兩個數(shù)據(jù)源的同一實體的屬性值卻不相同的現(xiàn)象,我們稱這種知識合并過程中出現(xiàn)的現(xiàn)象為知識沖突。針對知識沖突問題,可以采用沖突檢測與消解以及真值發(fā)現(xiàn)等技術(shù)進行消除,再將各個來源的知識關(guān)聯(lián)合并為一個知識圖譜。
沖突消解目前的研究方向是利用圖譜自身存在的特征,Trisedya等[54]利用屬性元組生成屬性特征嵌入向量。使用成分函數(shù)來表示屬性。將多個屬性值都轉(zhuǎn)化為單一向量,并將相似的屬性映射為相似的向量表示。利用這些屬性特征嵌入向量將兩個圖譜中的實體嵌入轉(zhuǎn)化到同一個空間中,計算實體的相似性。Chen等[55]針對多語言知識圖譜的合并,提出了利用實體描述的基于嵌入的半監(jiān)督跨語言學習方法,在一個大規(guī)模數(shù)據(jù)集上通過迭代的方式聯(lián)合訓練一個多語言知識圖譜嵌入模型和一個文字描述嵌入模型,訓練模型完成圖譜的合并。Cao等[56]提出多通道圖神經(jīng)網(wǎng)絡(luò)模型,通過多個通道將兩個知識圖譜進行魯棒編碼。在每個通道中通過不同的關(guān)系加權(quán)方案來編碼知識圖譜,使用知識圖譜補全和跨知識圖譜注意力策略來分別修剪每個圖譜中的獨有實體,通過池化技術(shù)組合這些通道。
3.?? 知識推理與質(zhì)量評估
知識推理技術(shù)可以提升知識圖譜的完整性和準確性。傳統(tǒng)的知識推理方法擁有極高的準確率,但無法適配大規(guī)模知識圖譜。針對知識圖譜數(shù)據(jù)量大、關(guān)系復雜的特點,提出了面向大規(guī)模知識圖譜的知識推理方法,并歸納為以下4類[14,?57]:(1)基于圖結(jié)構(gòu)和統(tǒng)計規(guī)則挖掘的推理;(2)基于知識圖譜表示學習的推理;(3)基于神經(jīng)網(wǎng)絡(luò)的推理;(4)混合推理。
3.1?? 基于圖結(jié)構(gòu)和統(tǒng)計規(guī)則挖掘的推理
受傳統(tǒng)推理地啟發(fā),基于知識圖譜的圖結(jié)構(gòu)以及挖掘蘊藏在知識圖譜中的規(guī)則進行推理的方法得以提出,并在知識推理任務上取得一定效果。Lao與Cohen[58]提出了路徑排序算法(Path ranking algorithm,PRA),將實體間的路徑作為特征,通過隨機行走算法來計算實體間是否存在潛在的關(guān)系。Wang等[59]設(shè)計了耦合路徑排序算法(Coupled path ranking algorithm,CPRA),并提出一種全新的逐次聚合的策略,通過這一策略使得具有強相關(guān)度的關(guān)系聚合在一起。使用多任務學習策略預測聚合后的關(guān)系。Xiong等[60]針對多跳關(guān)系路徑的學習提出使用強化學習的框架,設(shè)計了一個具有連續(xù)基于知識圖譜嵌入狀態(tài)的策略Agent,通過Agent在知識圖譜的向量空間中尋找最有潛力的關(guān)系加入路徑完成推理。
Cohen[61]針對如何將知識整合到梯度學習的系統(tǒng)的問題,描述了一個概率演繹的數(shù)據(jù)庫Tensorlog,通過可微分的過程來進行推理。Yang等[62]研究了基于學習一階概率邏輯規(guī)則進行知識庫推理的問題。受到Tensorlog的啟發(fā),提出了名為神經(jīng)邏輯規(guī)劃的框架,將一階邏輯規(guī)則的參數(shù)和結(jié)構(gòu)整合到一個端到端的可微分模型中。設(shè)計了一個帶Attention機制和存儲功能的神經(jīng)控制系統(tǒng)來學習組合那些用于完成推理的規(guī)則。Kampffmeyer等[63]提出深度圖傳播模型,在利用圖結(jié)構(gòu)的便利的同時解決知識過于稀疏的問題。
3.2?? 基于知識圖譜表示學習的推理
表示模型將知識圖譜中相應的實體和關(guān)系用向量、矩陣或者張量的形式表示,表示后進行運算完成知識推理任務。因其簡單高效且適應于大規(guī)模知識圖譜推理的特點而不斷發(fā)展。
3.2.1?? 基于距離的推理模型
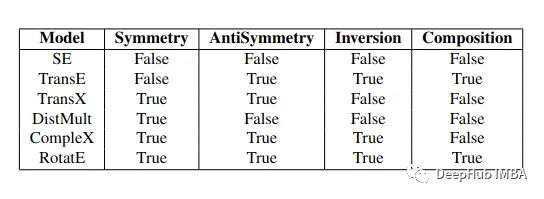
Bordes等[64]提出了TransE模型,將所有的實體和關(guān)系表示為同一個空間下的向量,假設(shè)事實元組中頭實體向量和關(guān)系向量之和應該約等于尾實體的向量。通過隨機替換事實元組中的某一項來構(gòu)建負例。計算元組中頭向量和關(guān)系向量的和向量與尾向量的距離作為候選實體的得分。盡管TransE模型簡單且有效,但其仍然具有許多缺陷,因而衍生出很多基于該模型的方法。Wang等[65]提出TransH模型,每一個關(guān)系都有一個特定的超平面,頭實體向量和尾實體向量投影至特定的關(guān)系超平面計算事實元組得分。Lin等[66]提出TransR模型,針對特定關(guān)系引入了空間。Xiao等[67]提出了ManifoldE模型,引入了特定關(guān)系參數(shù)。尾實體向量有效范圍是以頭實體向量和關(guān)系實體向量的和向量為中心,以特定關(guān)系參數(shù)為半徑的一個超球面。Feng等[68]提出的TransF模型和ManifoldE模型有著相似的思路,放寬了TransE中對實體關(guān)系向量的要求,僅需要頭實體向量位于尾實體向量和負的關(guān)系向量的和向量的方向上,同時尾實體向量也位于頭實體向量和關(guān)系向量的和向量的方向上。
Kzaemi與Poole[69]提出SimplE模型,允許實體擁有兩個獨立學習的向量表示,而關(guān)系由一個向量表示。Ebisu與Ichise[70]提出了TorusE嵌入模型,將TransE的思想應用在李群(Lie group)理論中的圓環(huán)面上,即在圓環(huán)面上計算表示向量間的距離來取得元組得分。Xu與Li[71]提出DihEdral模型,針對性地增強了知識推理的可解釋性,通過離散值將關(guān)系建模成組的元素,顯著地縮小了解空間。Sun等[72]提出RotatE模型,將關(guān)系看作是從頭實體向量向尾實體向量的旋轉(zhuǎn),元組得分通過計算旋轉(zhuǎn)后的頭實體向量和尾實體向量的距離得到Zhang等[73]引入超復數(shù)的概念,提出了QuatE模型,通過一個擁有三個虛部的超復數(shù)來表示知識圖譜中的實體和關(guān)系。與RotatE想法類似,QuatE模型將關(guān)系看作超復數(shù)平面下頭實體到尾實體的旋轉(zhuǎn)。
3.2.2?? 基于語義匹配的推理模型
Nickel等[74]提出的RESCAL模型將實體和向量聯(lián)系起來,從而捕捉其中隱含的語義,潛在因子間的相互作用建模后得到關(guān)系表示矩陣,計算實體向量與關(guān)系矩陣的乘積來得到元組得分。Yang等[75]提出DistMult模型,每一個關(guān)系都表示為向量,再將向量轉(zhuǎn)化為對角矩陣,通過計算頭尾實體向量與關(guān)系對角矩陣的乘積得到元組的得分。Trouillon等[76]提出Complex模型,引入復數(shù)嵌入針對不對稱關(guān)系建模。在Complex模型中,實體和關(guān)系都由復平面中的向量表示,計算頭實體向量和根據(jù)關(guān)系向量建立的對角矩陣以及尾實體向量的共軛這三者的乘積,結(jié)果的實部作為元組的得分。Liu等[77]提出ANALOGY模型,利用實體和關(guān)系的類比性質(zhì)來建模,實體由嵌入空間中的向量表示,將關(guān)系矩陣處理得到一系列稀疏的對角矩陣,減少了關(guān)系矩陣的參數(shù)。將頭尾實體向量與關(guān)系矩陣的積作為元組得分。
Balazevic等[78]提出了基于KKT(Karush Kuhn Tucker)分解的tuckER模型,將所有實體和關(guān)系分別表示為行向量嵌入矩陣,從這兩個矩陣中取出頭尾實體向量和關(guān)系向量,將這些向量和一個核心張量相乘得到元組的得分。針對大部分現(xiàn)存的基于知識圖譜嵌入的模型,Kristiadi等[79]研究了如何將文字信息整合到現(xiàn)存的表示模型中去,提出了LiteralE模型,在實體的嵌入表示上加入文字信息,用實體表示和文字信息的聯(lián)合表示取代原本模型的單獨的實體表示。Zhang等[80]提出了CrossE模型,基于向量表示實體和關(guān)系,生成多個元組的特定嵌入即交互嵌入。由交互表示和尾實體的嵌入表示的匹配程度給出元組得分。
基于表示學習的知識推理模型的比較如表1所示。
表? 1? 部分基于表示學習的知識推理模型
Table? 1.? Some knowledge reasoning models based on representation learning
| Method | Scoring function | The entity representations | The relation representation |
|---|---|---|---|
| TransE |
?∥h+t?r∥1/2?‖h+t?r‖1/2 |
h,t∈Rdh,t∈Rd |
r∈Rdr∈Rd |
| ManifoldE |
?(∥h+t?r∥22?θ2r)2?(‖h+t?r‖22?θr2)2 |
h,t∈Rdh,t∈Rd |
r∈Rdr∈Rd |
| SimplE |
12(?hei,vr,tej?+?hej,vr?1,tei?)12(?hei,vr,tej?+?hej,vr?1,tei?) |
he,te∈Rdhe,te∈Rd |
vr∈Rdvr∈Rd |
| RotatE |
∥h°r?t∥‖h°r?t‖ |
h,t∈Cdh,t∈Cd |
r∈Cdr∈Cd |
| QuatE |
h?r|r|?th?r|r|?t |
h,t∈Hdh,t∈Hd |
r∈Hdr∈Hd |
| RESCAL |
hTMrthTMrt |
h,t∈Rdh,t∈Rd |
Mr∈Rd×dMr∈Rd×d |
| DistMult |
hTdiag(r)thTdiag(r)t |
h,t∈Rdh,t∈Rd |
r∈Rdr∈Rd |
| ComplEx |
Re(hTdiag(r)tˉ)Re(hTdiag(r)tˉ) |
h,t∈Cdh,t∈Cd |
r∈Cdr∈Cd |
| ANALOGY |
hTMrthTMrt |
h,t∈Rdh,t∈Rd |
Mr∈Rd×dMr∈Rd×d |
| CrossE |
σ(tanh(cr°h+cr°h°r+b)tT)σ(tanh(cr°h+cr°h°r+b)tT) |
h,t∈Rdh,t∈Rd |
r∈Rdr∈Rd |
3.3?? 基于神經(jīng)網(wǎng)絡(luò)的推理
基于神經(jīng)網(wǎng)絡(luò)的推理方法將知識圖譜中事實元組表示為向量形式送入神經(jīng)網(wǎng)絡(luò)中,通過訓練神經(jīng)網(wǎng)絡(luò)不斷提高事實元組的得分,最終通過輸出得分選擇候選實體完成推理。Socher等[81]提出適應于實體間關(guān)系推理的神經(jīng)張量網(wǎng)絡(luò)(Neural tensor networks,NTN)模型,用雙線性張量層取代神經(jīng)網(wǎng)絡(luò)層,實體通過連續(xù)的詞向量平均表示進而提升模型的表現(xiàn)。Neelakantan等[82]使用循環(huán)神經(jīng)網(wǎng)絡(luò)來建模知識圖譜中的分布式語義的多跳路徑。Das等[83]主要是將符號邏輯推理中豐富的多步推理與神經(jīng)網(wǎng)絡(luò)的泛化能力相結(jié)合。通過學習實體、關(guān)系和實體的種類來聯(lián)合推理,并使用神經(jīng)注意力建模來整合多跳路徑。在單層RNN中分享參數(shù)來表示所有關(guān)系的邏輯組成。Graves等[84]建立了可微神經(jīng)計算機模型,將神經(jīng)網(wǎng)絡(luò)和記憶系統(tǒng)結(jié)合起來,將通過樣本學習到的知識儲存起來并進行快速知識推理。
Dettmers等[85]針對知識圖譜中大規(guī)模與過擬合的問題,設(shè)計了參數(shù)簡潔且計算高效的二維卷積神經(jīng)網(wǎng)絡(luò)(Convolutional 2D,ConvE)模型。Vashishth等[86]基于特征排列、新的特征變形以及循環(huán)卷積提出InteractE模型。InteractE模型通過使用多種排列輸入,更簡單的特征變形方法以及循環(huán)卷積來取得比ConvE更顯著的效果。
3.4?? 混合推理
對于上面的幾類知識推理的方法,各有其優(yōu)勢與缺點,于是考慮結(jié)合多種方法的優(yōu)勢來提升推理效果,進而提出了混合推理方法。Guo等[87]提出學習規(guī)則增強關(guān)系來補全知識圖譜的方法,使用規(guī)則來進一步改善傳統(tǒng)關(guān)系學習得到的推理結(jié)果,提升知識推理的準確性。Lu等[88]提出了基于強化學習建模的邏輯概率的知識表示和推理模型,同時在已知的知識和由強化學習整合的經(jīng)驗上進行推理來訓練強化學習的Agent。Xie等[89]提出一種利用實體描述的知識表示學習的方法,使用了連續(xù)詞袋模型和深度卷積模型來編碼實體的描述語義。之后進一步學習通過三元組和三元組中實體的描述來學習表示知識。并利用學習到的知識來完成知識推理任務。Wang[90]提出規(guī)則嵌入神經(jīng)網(wǎng)絡(luò)(The rule-embedded neural network,ReNN)。ReNN基于局部的推理檢測局部模式,由局部模式領(lǐng)域知識的規(guī)則來生成規(guī)則調(diào)制映射。針對規(guī)則引起的優(yōu)化問題,采用兩階段優(yōu)化策略。引入規(guī)則解決了傳統(tǒng)神經(jīng)網(wǎng)絡(luò)必須受限于數(shù)據(jù)集的問題,從而提升了推理的準確率。
Zhang等[91]提出了一個名為IterE的迭代學習嵌入和規(guī)則的框架,目標是同時學習實體嵌入表示和規(guī)則,并利用它們各自的優(yōu)勢來彌補對方的不足。Nie與Sun[92]組合了隱形特征和圖特征的優(yōu)勢提出了一個名為文本強化型知識圖譜嵌入(Text-enhanced knowledge graph embedding,TKGE)的組合模型,通過實體、關(guān)系和文本來提升推理的表現(xiàn)。Guan等[93]基于一個常識圖的常識概念信息提出了一個常識伴隨的知識圖譜嵌入(Knowledge graph embedding with concepts,KEC)模型,將來自于知識圖譜的事實元組通過常識概念信息修正,從而使得模型不僅僅關(guān)注實體間的關(guān)聯(lián)性還有實體存在的常識概念。因此這個模型具有明確的語義性。
4類知識推理方法對比如表2所示。
表? 2? 4類知識推理方法對比
Table? 2.? Comparisons of 4 kinds of knowledge reasoning methods
| Reasoning methods | Advantage | Disadvantage | Typical model |
|---|---|---|---|
| Knowledge reasoning based on graph structure and statistical rule mining | The advantages of graph structure and rules can significantly improve the accuracy of knowledge reasoning |
Large-scale knowledge graphs have complex graph structures and rules are not easy to obtain; noise rules can mislead knowledge reasoning |
PRA AMIE TensoLog |
| Knowledge reasoning based on representation learning |
Simple and efficient, suitable for large-scale knowledge graph |
Does not consider the deeper information in the knowledge graph, which limits its accuracy of reasoning | RESCAL TransE |
|
Knowledge reasoning based on the neural network |
Outstanding learning ability and reasoning ability |
High complexity, huge number of parameters, and poor interpretability | NTN |
|
Knowledge reasoning based on hybrid methods |
Combines the advantages of several inference methods, so its performance is excellent |
Most methods are just shallow fusion, not taking full advantage of their respective methods |
TKGE |
3.5?? 質(zhì)量評估
通過質(zhì)量評估技術(shù)來對新知識進行篩選,是構(gòu)建知識圖譜中必不可少的環(huán)節(jié)。Mendes等[94]提出了Sieve,用于簡化生成高質(zhì)量數(shù)據(jù)的任務,并整合進了鏈接數(shù)據(jù)整合框架(Linked data integration framework,LDIF)中,包括一個質(zhì)量評估模型和一個數(shù)據(jù)融合模型。質(zhì)量評估主要利用用戶選擇的質(zhì)量因子,通過用戶配置的得分函數(shù)生成質(zhì)量得分。數(shù)據(jù)融合使用質(zhì)量得分來處理用戶設(shè)置的沖突消解任務。Fader等[95]基于來自網(wǎng)絡(luò)或Wikipedia的1000個句子中人工標注的實例來訓練ReVerb系統(tǒng)的置信函數(shù),通過一個邏輯回歸分類器來評估每一個通過ReVerb系統(tǒng)抽取得到的實例的置信度。Google的Knowledge vault項目[96],通過統(tǒng)計全球網(wǎng)絡(luò)中抽取數(shù)據(jù)的頻率作為評估信息可信度的依據(jù),并通過已有知識庫中的知識來修正可信度,這一方法有效降低了評估數(shù)據(jù)結(jié)果的不確定性,從而提升了知識的質(zhì)量水平。Tan等[97]提出了一個名為CQUAL(Contribution quality predictor)的方法來自動預測用戶提交至知識庫的知識的質(zhì)量,主要依據(jù)提交用戶的領(lǐng)域、提交歷史、以及歷史準確率等數(shù)據(jù)。實驗表明這一方法擁有很高的準確率和召回率。
4.?? 知識圖譜應用
知識圖譜技術(shù)提出之后,因其具有的語義處理和開放互聯(lián)的能力,以及其簡潔靈活的表達方式等優(yōu)勢,受到了廣泛關(guān)注。知識圖譜技術(shù)的發(fā)展得益于自然語言處理、互聯(lián)網(wǎng)等技術(shù)的發(fā)展,而不斷完善的知識圖譜技術(shù)也可以應用到自然語言處理、智能問答系統(tǒng)、智能推薦系統(tǒng)等技術(shù)中,進一步促進這些技術(shù)的發(fā)展,而這些技術(shù)以及知識圖譜技術(shù)又可以進一步應用在諸如醫(yī)療、金融、電商等垂直行業(yè)或領(lǐng)域內(nèi),幫助促進行業(yè)發(fā)展[16-17]。
構(gòu)建完備的知識圖譜可以幫助自然語言理解技術(shù)發(fā)展。針對文本分類問題,Wang等[98]首先利用知識庫中的知識將短文本概念化,獲得短文本的嵌入表示后送入卷積神經(jīng)網(wǎng)絡(luò)中進行分類。Lagon等[99]提出了知識圖譜語言模型,一種擁有從知識圖譜中選擇和復制知識的神經(jīng)語言模型。
智能問答系統(tǒng)可以依靠知識圖譜中的知識來回答查詢。Bauer等[100]利用關(guān)系路徑從常識網(wǎng)絡(luò)中獲取背景常識知識,之后利用多注意力機制完成多跳推理并通過一個指針生成譯碼器來合成問題的答案。朱宗奎等[101]針對中文知識圖譜問答系統(tǒng),將BERT(Bidirectional encoder representations from transformers)模型和雙向長短期記憶網(wǎng)絡(luò)結(jié)合,之后通過條件隨機場模型來預測字符標簽,從而識別出問題中的實體并鏈接到知識網(wǎng)絡(luò)中,最后完成答案的搜索。
知識圖譜可作為外部信息整合至推薦系統(tǒng)中,使得推薦系統(tǒng)獲得推理能力。通過利用知識圖譜中諸如實體、關(guān)系的信息,許多研究進一步基于嵌入正則化來提升推薦效果。Wang等[102]將圖注意網(wǎng)絡(luò)應用于實體–關(guān)系和用戶–物品圖的協(xié)作知識圖譜上,提出了名為知識圖譜注意力網(wǎng)絡(luò)的模型,在端到端的模式下通過嵌入傳播和基于注意的聚合對建模知識圖譜中的高階連通性建模。
在垂直行業(yè)或領(lǐng)域內(nèi),知識圖譜已開始應用。在醫(yī)療領(lǐng)域,通過提供更加精確規(guī)范的行業(yè)數(shù)據(jù)以及更加豐富的表達,幫助非行業(yè)相關(guān)人員獲取醫(yī)療知識的同時也幫助行業(yè)人員更直觀快捷獲取所需醫(yī)療知識。在金融領(lǐng)域,借助知識圖譜檢測數(shù)據(jù)的不一致性,來識別潛在的欺詐風險。同時,利用知識圖譜技術(shù)分析招股書、年報、公司公告等金融報告,建立公司和人物的關(guān)系,在此基礎(chǔ)上做更進一步的研究和更優(yōu)的決策。在電商領(lǐng)域,阿里巴巴已經(jīng)通過應用知識圖譜,建立商品間的關(guān)聯(lián)信息,為用戶提供更全面的商品信息和更智能化的推薦,從而提升用戶的購物服務與體驗。同時,知識圖譜也在教育、科研、軍事等領(lǐng)域中廣泛應用。
5.?? 知識圖譜在知識融合、推理與應用中的挑戰(zhàn)與展望
自谷歌提出知識圖譜概念至今,這項技術(shù)一直受到廣泛的關(guān)注。隨著深度學習、自然語言處理等相關(guān)領(lǐng)域的發(fā)展,知識圖譜的研究熱度不斷增加。不可忽略的是,知識圖譜發(fā)展至今,知識融合、知識推理等知識圖譜關(guān)鍵技術(shù)以及知識圖譜的應用仍面臨許多挑戰(zhàn)。
知識融合技術(shù)是知識圖譜的關(guān)鍵技術(shù)之一。知識融合主要任務是將新獲得的知識融入知識圖譜中。保證知識圖譜知識準確率的前提下高效地引入新知識,是知識融合的關(guān)鍵。存在的挑戰(zhàn)如下:(1)為了保證融合后知識圖譜的質(zhì)量,首先要提升知識評估的能力。現(xiàn)存的知識評估方法大都是針對靜態(tài)知識進行評估,缺少動態(tài)知識評估手段是目前知識評估面臨的一大挑戰(zhàn)。(2)要解決由自然語言的特殊性引發(fā)的知識冗余和缺失問題。當知識圖譜不能準確將具有同義異名的實體對齊或?qū)⑼惲x的實體消歧就會導致知識圖譜中出現(xiàn)知識冗余或缺失。(3)目前,因自然語言的復雜性,在單一語言的背景下實體對齊和實體消歧的準確率仍然有待提高,針對多語言實體對齊或消歧更是一大挑戰(zhàn)。
知識推理技術(shù)也是知識圖譜的關(guān)鍵技術(shù)之一,通過已知的知識推理獲得新知識來完善知識圖譜。存在的挑戰(zhàn)如下:(1)知識推理的主要對象多是二元關(guān)系,通常處理多元關(guān)系的方法是將其拆分為二元關(guān)系進行推理,然而將多元關(guān)系拆分會損失結(jié)構(gòu)信息,如何盡可能完整地利用多元關(guān)系中復雜的隱含信息推理是知識推理的一大挑戰(zhàn)。(2)現(xiàn)有的知識推理往往都是基于大量高質(zhì)量的數(shù)據(jù)集訓練推理模型,在相應的測試集中測試優(yōu)化模型來完成推理。除了數(shù)據(jù)集獲取成本高的問題,通過數(shù)據(jù)集訓練的模型的泛化能力也極為有限,而現(xiàn)實世界中人類通過少量樣本學習即可完成推理。如何模仿人腦機制實現(xiàn)小樣本或零樣本學習知識推理也是一大挑戰(zhàn)。(3)知識圖譜中知識的有效性往往受到時間空間等動態(tài)因素約束,如何合理利用知識的動態(tài)約束信息完成動態(tài)推理也是知識推理的一大挑戰(zhàn)。
知識的表達、存儲與查詢將是貫穿知識圖譜應用始終的問題。存在的挑戰(zhàn)如下:(1)目前,應用在行業(yè)領(lǐng)域的知識圖譜因為很大程度上依賴人工的參與構(gòu)建,成本高昂。大多數(shù)研究工作主要針對知識圖譜的半自動構(gòu)建[103],如何自動構(gòu)建高質(zhì)量知識圖譜是知識圖譜應用所面臨的一大挑戰(zhàn)。(2)知識擁有指導功能,利用知識圖譜中的知識引導機器學習中的數(shù)據(jù)學習,從而降低數(shù)據(jù)依賴打破數(shù)據(jù)紅利損耗殆盡后的僵局,是知識圖譜應用面臨的一大挑戰(zhàn)。(3)利用人類易懂的符號化知識圖譜,解釋各類機器學習特別是深度學習的過程,補足其在可解釋性方面的短板,也是知識圖譜應用面臨的一大挑戰(zhàn)。(4)未來,能否應用知識圖譜中的知識,作為已知的經(jīng)驗,通過訓練構(gòu)建人工智能層面上的心智模型,同樣是知識圖譜應用的一大挑戰(zhàn)。
知識圖譜意在模仿人類的認知方式,構(gòu)建屬于機器的知識庫,是實現(xiàn)機器認知智能的關(guān)鍵技術(shù),也是網(wǎng)絡(luò)大數(shù)據(jù)時代中利用大數(shù)據(jù)的關(guān)鍵技術(shù)。本文從知識圖譜構(gòu)建過程中的關(guān)鍵技術(shù)出發(fā),簡略研究了知識的抽取與表示,重點分析了知識融合和知識推理技術(shù)的研究成果。然而眾多研究成果實用性不強,知識圖譜雖然已經(jīng)出現(xiàn)了諸如Magi[104]這樣的理論實踐者,但距離知識圖譜成為機器大腦知識庫、實現(xiàn)機器認知智能的終極目標還有不小的距離。未來的研究中,基于網(wǎng)絡(luò)數(shù)據(jù)自動構(gòu)建的知識圖譜將成為主流。因而需要進一步提高知識抽取、知識融合和知識推理技術(shù)的準確性,確保獲取知識的質(zhì)量;同時提高這些技術(shù)的效率,從而保證面對大規(guī)模數(shù)據(jù)量級時的實用性。同時,知識圖譜雖然已經(jīng)在公安情報分析、反金融欺詐等實際問題中開始應用,但是其具有的巨大潛力仍有待挖掘,如何將知識圖譜技術(shù)應用在生活中的各個方面,也將是未來的主要研究方向。除此之外,目前存在著的大量知識圖譜,大多有著結(jié)構(gòu)或者語言上的差異,這種差異增大了知識圖譜應用的難度,制定行業(yè)規(guī)范、整合各個知識圖譜、構(gòu)建通用知識圖譜,也是未來知識圖譜研究的方向之一。
?【轉(zhuǎn)載聲明】轉(zhuǎn)載目的在于傳遞更多信息。如涉及作品版權(quán)和其它問題,請在30日內(nèi)與本號聯(lián)系,我們將在第一時間刪除!
編輯:fqj










































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論