 電子發(fā)燒友App
電子發(fā)燒友App


作者注記
我是2017年11月開始接觸深度學(xué)習(xí),至今剛好五年。2019年10月入職上海交大,至今三年,剛好第一階段考核。2022年8月19號,我在第一屆中國機(jī)器學(xué)習(xí)與科學(xué)應(yīng)用大會做大會報(bào)告,總結(jié)這五年的研究以及展望未來的方向。本文是該報(bào)告里關(guān)于理論方面的研究總結(jié)(做了一點(diǎn)擴(kuò)展)。
我理解的深度學(xué)習(xí)
我原本是研究計(jì)算神經(jīng)科學(xué)的,研究的內(nèi)容,宏觀來講是從數(shù)學(xué)的角度理解大腦工作的原理,具體來說,我的研究是處理高維的神經(jīng)元網(wǎng)絡(luò)產(chǎn)生的脈沖數(shù)據(jù),嘗試去理解這些信號是如何處理輸入的信號。但大腦過于復(fù)雜,維度也過于高,我們普通大腦有一千億左右個(gè)神經(jīng)元,每個(gè)神經(jīng)元還和成千上萬個(gè)其它神經(jīng)元有信號傳遞,我對處理這類數(shù)據(jù)并沒有太多信心,那階段也剛好讀到一篇文章,大意是把現(xiàn)階段計(jì)算神經(jīng)科學(xué)的研究方法用來研究計(jì)算機(jī)的芯片,結(jié)論是這些方法并不能幫助我們理解芯片的工作原理。另一個(gè)讓我覺得非常難受的地方是我們不僅對大腦了解很少,還非常難以獲得大腦的數(shù)據(jù)。于是,我們當(dāng)時(shí)思考,能否尋找一個(gè)簡單的網(wǎng)絡(luò)模型,能夠?qū)崿F(xiàn)復(fù)雜的功能,同時(shí)我們對它的理解也很少的例子,我們通過研究它來啟發(fā)我們對大腦的研究。
當(dāng)時(shí)是2017年底,深度學(xué)習(xí)已經(jīng)非常流行,特別是我的同學(xué)已經(jīng)接觸深度學(xué)習(xí)一段時(shí)間,所以我們迅速了解到深度學(xué)習(xí)。其結(jié)構(gòu)和訓(xùn)練看起來足夠簡單,但能力不凡,而且與其相關(guān)的理論正處在萌芽階段。因此,我進(jìn)入深度學(xué)習(xí)的第一個(gè)想法是把它當(dāng)作研究大腦的簡單模型。?顯然,在這種“類腦研究”的定位下,我們關(guān)心的是深度學(xué)習(xí)的基礎(chǔ)研究。這里,我想?yún)^(qū)分深度學(xué)習(xí)的“理論”和“基礎(chǔ)研究”。我認(rèn)為“理論”給人一種全是公式和證明的感覺。而“基礎(chǔ)研究”的范圍聽起來會更廣闊一些,它不僅可以包括“理論”,還可以是一些重要的現(xiàn)象,直觀的解釋,定律,經(jīng)驗(yàn)原則等等。這種區(qū)分只是一種感性的區(qū)分,實(shí)際上,我們在談?wù)撍鼈兊臅r(shí)候,并不真正做這么細(xì)致的區(qū)分。盡管是以深度學(xué)習(xí)為模型,來研究大腦為何會有如此復(fù)雜的學(xué)習(xí)能力,但大腦和深度學(xué)習(xí)還是有明顯的差異。而我從知識儲備、能力和時(shí)間上來看,都很難同時(shí)在這兩個(gè)目前看起來距離仍然很大的領(lǐng)域同時(shí)深入。
于是我選擇全面轉(zhuǎn)向深度學(xué)習(xí),研究的問題是,深度學(xué)習(xí)作為一個(gè)算法,它有什么樣的特征。“沒有免費(fèi)的午餐”的定理告訴我們,當(dāng)考慮所有可能的數(shù)據(jù)集的平均性能時(shí),所有算法都是等價(jià)的,也就是沒有哪一種算法是萬能的。我們需要厘清深度學(xué)習(xí)這類算法適用于什么數(shù)據(jù),以及不適用于什么數(shù)據(jù)。?事實(shí)上,深度學(xué)習(xí)理論并不是處于萌芽階段,從上世紀(jì)中葉,它剛開始發(fā)展的時(shí)候,相關(guān)的理論就已經(jīng)開始了,也有過一些重要的結(jié)果,但整體上來說,它仍然處于初級階段。對我而言,這更是一個(gè)非常困難的問題。于是,我轉(zhuǎn)而把深度學(xué)習(xí)當(dāng)作一種“玩具”,通過調(diào)整各類超參數(shù)和不同的任務(wù),觀察它會產(chǎn)生哪些“自然現(xiàn)象”。設(shè)定的目標(biāo)也不再高大上,而是有趣即可,發(fā)現(xiàn)有趣的現(xiàn)象,然后解釋它,也許還可以用它來指導(dǎo)實(shí)際應(yīng)用。在上面這些認(rèn)識下,我們從深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練中的一些有趣的現(xiàn)象開始。于我個(gè)人,我是從頭開始學(xué)習(xí)寫python和tensorflow,更具體是,從網(wǎng)上找了幾份代碼,邊抄邊理解。
神經(jīng)網(wǎng)絡(luò)真的很復(fù)雜嗎?
在傳統(tǒng)的學(xué)習(xí)理論中,模型的參數(shù)量是指示模型復(fù)雜程度很重要的一個(gè)指標(biāo)。當(dāng)模型的復(fù)雜度增加時(shí),模型擬合訓(xùn)練數(shù)據(jù)的能力會增強(qiáng),但也會帶來在測試集上過擬合的問題。馮·諾依曼曾經(jīng)說過一句著名的話,給我四個(gè)參數(shù),我能擬合一頭大象,五個(gè)參數(shù)可以讓大象的鼻子動起來。
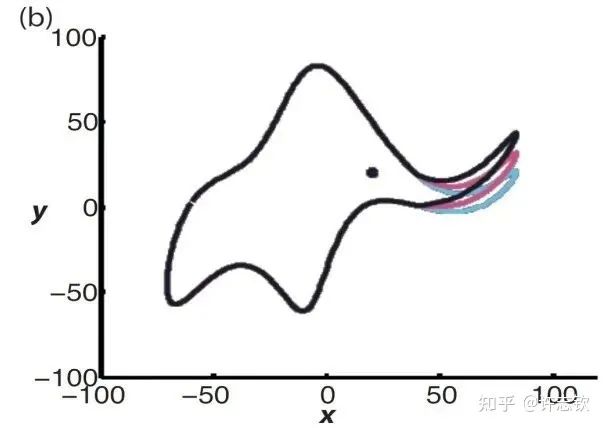
因此,傳統(tǒng)建模相關(guān)的研究人員在使用神經(jīng)網(wǎng)絡(luò)時(shí),經(jīng)常會計(jì)算模型參數(shù)量,以及為了避免過擬合,刻意用參數(shù)少的網(wǎng)絡(luò)。然而,今天神經(jīng)網(wǎng)絡(luò)能夠大獲成功,一個(gè)重要的原因正是使用了超大規(guī)模的網(wǎng)絡(luò)。網(wǎng)絡(luò)的參數(shù)數(shù)量往往遠(yuǎn)大于樣本的數(shù)量,但卻不像傳統(tǒng)學(xué)習(xí)理論所預(yù)言的那樣過擬合。這便是這些年受到極大關(guān)注的泛化迷團(tuán)。實(shí)際上,在1995年,Leo Breiman在一篇文章中就已經(jīng)指出了這個(gè)問題。在神經(jīng)網(wǎng)絡(luò)非常流行和重要的今天,這個(gè)迷團(tuán)愈加重要。我們可以問:帶有大量參數(shù)的神經(jīng)網(wǎng)絡(luò)真的很復(fù)雜嗎?
答案是肯定的!上世紀(jì)八十年代末的理論工作證明當(dāng)兩層神經(jīng)網(wǎng)絡(luò)(激活函數(shù)非多項(xiàng)式函數(shù))足夠?qū)挄r(shí),它可以以任意精度逼近任意連續(xù)函數(shù),這也就是著名的“萬有逼近”定理。實(shí)際上,我們應(yīng)該問一個(gè)更加有意義的問題:在實(shí)際訓(xùn)練中,神經(jīng)網(wǎng)絡(luò)真的很復(fù)雜嗎??逼近論證明的解在實(shí)際訓(xùn)練中幾乎不可能遇到。實(shí)際的訓(xùn)練,需要設(shè)定初始值、優(yōu)化算法、網(wǎng)絡(luò)結(jié)構(gòu)等超參數(shù)。對我們實(shí)際要有指導(dǎo)作用,我們就不能脫離這些因素來考慮泛化的問題,因?yàn)榉夯旧砭褪且蕾噷?shí)際數(shù)據(jù)的問題。

兩種簡單偏好的現(xiàn)象
在學(xué)習(xí)與訓(xùn)練神經(jīng)網(wǎng)絡(luò)的過程中,我們很容易發(fā)現(xiàn),神經(jīng)網(wǎng)絡(luò)的訓(xùn)練有一定的規(guī)律。在我們的研究中,有兩種現(xiàn)象很有趣,在研究和解釋它們的過程中,我們發(fā)現(xiàn)它們同樣是很有意義的。我先簡單介紹,然后再詳細(xì)分別介紹。第一,我們發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)在擬合數(shù)據(jù)的過程中經(jīng)常會先學(xué)習(xí)低頻,而后慢慢學(xué)習(xí)高頻。我們把這個(gè)現(xiàn)象命名為頻率原則(Frequency Principle, F-Principle)[1, 2],也有其它工作把它稱為Spectral bias。第二,我們發(fā)現(xiàn)在訓(xùn)練過程,有很多神經(jīng)元的輸入權(quán)重(向量)的方向會保持一致。我們稱之為凝聚現(xiàn)象。這些輸入權(quán)重一樣的神經(jīng)元對輸入的處理是一樣的,那它們就可以簡化成一個(gè)神經(jīng)元,也就是一個(gè)大網(wǎng)絡(luò)可以簡化成小網(wǎng)絡(luò)[3, 4]。這兩種現(xiàn)象都體現(xiàn)神經(jīng)網(wǎng)絡(luò)在訓(xùn)練過程中有一種隱式的簡單偏好,低頻偏好或者有效小網(wǎng)絡(luò)偏好。低頻偏好是非常普遍的,但小網(wǎng)絡(luò)偏好是要在非線性的訓(xùn)練過程中才會出現(xiàn)的特征。
頻率原則
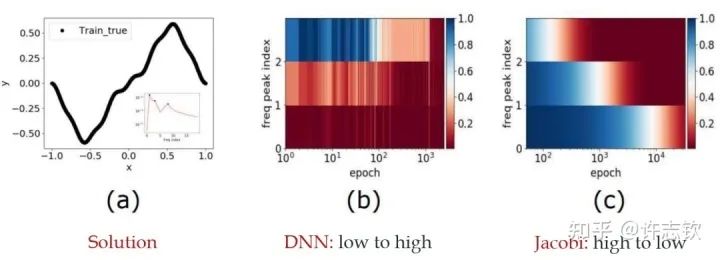
我早期在匯報(bào)頻率原則相關(guān)的工作的時(shí)候,做計(jì)算數(shù)學(xué)的老師同學(xué)非常有興趣,因?yàn)樵趥鹘y(tǒng)的迭代格式中,例如Jacobi迭代,低頻是收斂得非常慢的。多重網(wǎng)格方法非常有效地解決了這個(gè)問題。我們在實(shí)驗(yàn)中,也驗(yàn)證了神經(jīng)網(wǎng)絡(luò)和Jacobi迭代在解PDE時(shí)完全不一樣的頻率收斂順序(如下圖)[2, 5]。
頻率原則有多廣泛呢??頻率原則最開始是在一維函數(shù)的擬合中發(fā)現(xiàn)的。我在調(diào)參的過程中發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)似乎總是先抓住目標(biāo)函數(shù)的輪廓信息,然后再是細(xì)節(jié)。頻率是一種非常適合用來刻畫輪廓和細(xì)節(jié)的量。于是,我們在頻率空間看神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)過程,發(fā)現(xiàn)非常明顯地從低頻到高頻的順序。
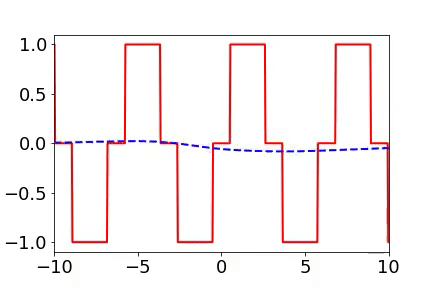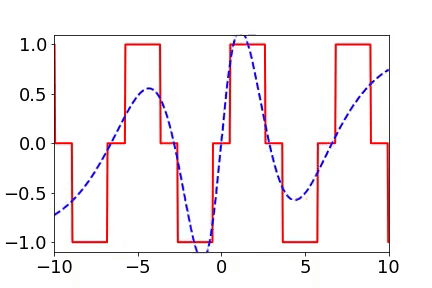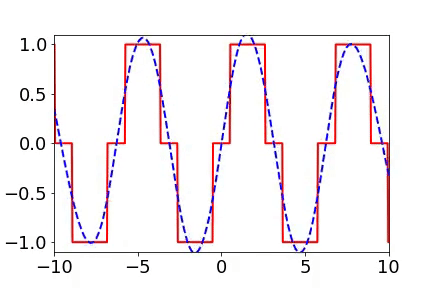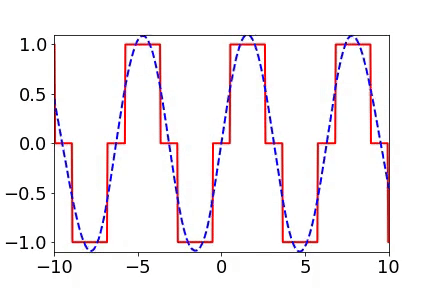 實(shí)域空間擬合(紅色為目標(biāo)函數(shù),藍(lán)色為DNN)
實(shí)域空間擬合(紅色為目標(biāo)函數(shù),藍(lán)色為DNN) 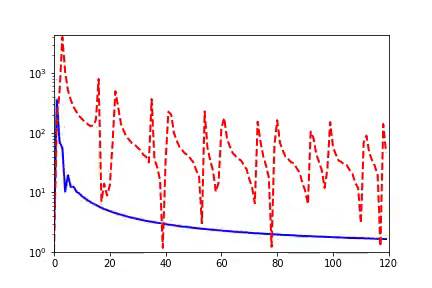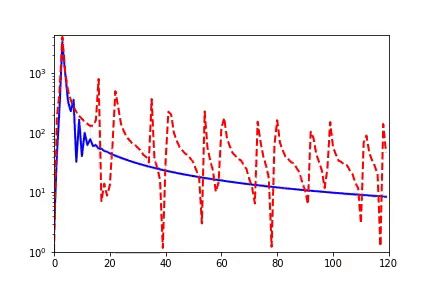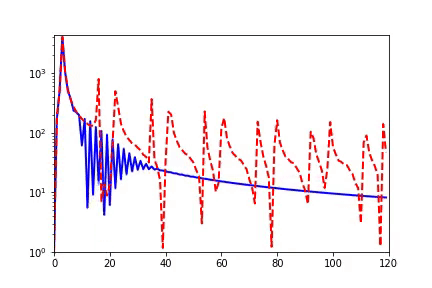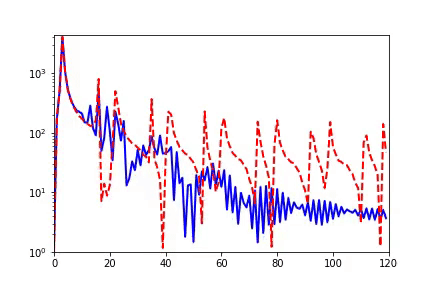 頻域空間擬合(紅色為目標(biāo)函數(shù),藍(lán)色為DNN)
頻域空間擬合(紅色為目標(biāo)函數(shù),藍(lán)色為DNN)
對于兩維的函數(shù),以圖像為例,用神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)從兩維位置到灰度值的映射。神經(jīng)網(wǎng)絡(luò)在訓(xùn)練過程會慢慢記住更多細(xì)節(jié)。

對于更高維的例子,傅里葉變換是困難的,這也是不容易在高維的圖像分類任務(wù)中發(fā)現(xiàn)頻率原則的一個(gè)原因。我們的貢獻(xiàn)還有一點(diǎn)就是用一個(gè)例子論證針對簡單的低維問題的研究可以啟發(fā)深度學(xué)習(xí)的基礎(chǔ)研究。高維問題的頻率需要多說兩句。本質(zhì)上,高頻指的是輸出對輸入的變化非常敏感。比如在圖片分類任務(wù)中,當(dāng)一張圖片被修改一點(diǎn)點(diǎn),輸出就發(fā)生變化。顯然,這說的正是對抗樣本。關(guān)于高維中驗(yàn)證頻率原則,我們采用了降維和濾波的辦法。一系列的實(shí)驗(yàn)都驗(yàn)證了頻率原則是一個(gè)廣泛存在的現(xiàn)象。
為什么會有頻率原則呢??事實(shí)上,在自然界中大部分信號都有一個(gè)特征,強(qiáng)度隨頻率增加而衰減。一般我們見到的函數(shù)在頻率空間也都有衰減的特征,特別是函數(shù)越光滑,衰減越快,連常見的ReLU函數(shù)在頻率空間也是關(guān)于頻率二次方衰減。在梯度下降的計(jì)算中,很容易得到低頻信號對梯度的貢獻(xiàn)要大于高頻,所以梯度下降自然就以消除低頻誤差為主要目標(biāo)[2]。對于一般的網(wǎng)絡(luò),我們有定性的理論證明[6],而對于線性NTK區(qū)域的網(wǎng)絡(luò),我們有嚴(yán)格的線性頻率原則模型揭示頻率衰減的機(jī)制[7, 8, 9]。有了這個(gè)理解,我們也可以構(gòu)造一些例子來加速高頻的收斂,比如在損失函數(shù)中增加輸出關(guān)于輸入的導(dǎo)數(shù)項(xiàng),因?yàn)榍髮?dǎo)在頻率空間看,相當(dāng)于在強(qiáng)度上乘以了一個(gè)其對應(yīng)的頻率,可以緩解高頻的困難。這在求解PDE中很常見。
了解頻率原則對我們理解神經(jīng)網(wǎng)絡(luò)有什么幫助嗎??我們舉兩個(gè)例子。第一個(gè)是理解提前停止這個(gè)技巧。實(shí)際的訓(xùn)練中,一般都能發(fā)現(xiàn)泛化最好的點(diǎn)并不是訓(xùn)練誤差最低的,通常需要在訓(xùn)練誤差還沒降得很低的時(shí)候,提前停止訓(xùn)練。實(shí)際數(shù)據(jù)大部分都是低頻占優(yōu),而且基本都有噪音。噪音對低頻的影響相對比較小,而對高頻影響相對比較大,而神經(jīng)網(wǎng)絡(luò)在學(xué)習(xí)過程先學(xué)習(xí)低頻,所以通過提前停止可以避免學(xué)習(xí)到過多被污染的高頻而帶來更好的泛化性能。另一個(gè)例子是,我們發(fā)現(xiàn)圖像分類問題中,從圖像到類別的映射通常也是低頻占優(yōu),所以可以理解其良好的泛化。但對于定義在d維空間中的奇偶函數(shù),其每一維的值只能取1或者-1。顯然任何一維被擾動后,輸出都會發(fā)生大的變化。這個(gè)函數(shù)可以被證明是高頻占優(yōu)的,而實(shí)際訓(xùn)練中,神經(jīng)網(wǎng)絡(luò)在這個(gè)問題中完全沒有預(yù)測能力。我們還利用頻率原則解釋了為什么在實(shí)驗(yàn)中會觀察到深度可以加快訓(xùn)練,核心的原因是越深的網(wǎng)絡(luò)把目標(biāo)函數(shù)變成一個(gè)越低頻的函數(shù),使學(xué)習(xí)變得容易 [10]。
除了理解,頻率原則能對我們實(shí)際設(shè)計(jì)和使用神經(jīng)網(wǎng)絡(luò)產(chǎn)生什么指導(dǎo)嗎?頻率原則揭示了神經(jīng)網(wǎng)絡(luò)中存在高頻災(zāi)難,這也引起了很多研究人員的注意,包括求解PDE、生成圖像、擬合函數(shù)等。高頻災(zāi)難帶來的訓(xùn)練和泛化困難很難通過簡單的調(diào)參來緩解。我們組提出了多尺度神經(jīng)網(wǎng)絡(luò)的方法來加速高頻的收斂[11]。基本的想法是把目標(biāo)函數(shù)在徑向進(jìn)行不同尺度的拉伸,嘗試將不同頻率的成分都拉伸成一致的低頻,達(dá)到一致的快速收斂。實(shí)現(xiàn)也是非常之容易,僅需在第一隱藏層的神經(jīng)元的輸入乘以一些固定的系數(shù)即可。我們的一些工作發(fā)現(xiàn)調(diào)整激活函數(shù)對網(wǎng)絡(luò)的性能影響很大[12],用正弦余弦函數(shù)做第一個(gè)隱藏層的基可以有比較好的效果[13]。這個(gè)算法被華為的MindSpore所采用。徑向拉伸的想法在很多其它的算法中也被采用,包括在圖片渲染中非常出名的NerF(神經(jīng)輻射場)。
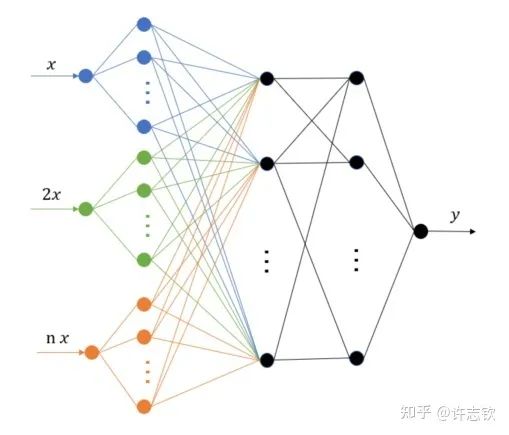 多尺度網(wǎng)絡(luò)結(jié)構(gòu)
多尺度網(wǎng)絡(luò)結(jié)構(gòu)
頻率原則還有很多未解的問題需要被探索。?在非梯度下降訓(xùn)練的過程,比如粒子群算法怎么證明頻率下降[14]?如何在理論上論證多尺度神經(jīng)網(wǎng)絡(luò)對高頻的加速效果?是否有更穩(wěn)定更快的高頻加速算法?小波可以更細(xì)致的描述不同局部的頻率特征,能否用小波更細(xì)節(jié)地理解神經(jīng)網(wǎng)絡(luò)的訓(xùn)練行為?數(shù)據(jù)量、網(wǎng)絡(luò)深度、損失函數(shù)怎么影響頻率原則?頻率原則可以指導(dǎo)算法設(shè)計(jì)的理論,為訓(xùn)練規(guī)律提供一種“宏觀”描述。對于“微觀”機(jī)制,我們需要進(jìn)一步研究。同樣是低頻到高頻的學(xué)習(xí)過程,參數(shù)的演化可以非常不一樣,比如一個(gè)函數(shù)可以用一個(gè)神經(jīng)元表示,也可以用10個(gè)神經(jīng)元(每個(gè)神經(jīng)元的輸出權(quán)重為原輸出權(quán)重的1/10)一起表示,從輸入輸出函數(shù)的頻率來看,這兩種表示完全沒有差別,那神經(jīng)網(wǎng)絡(luò)會選擇哪一種表示,以及這些表示有什么差別?下面我們就要更細(xì)致地看參數(shù)演化中的現(xiàn)象。
參數(shù)凝聚現(xiàn)象
為了介紹參數(shù)凝聚現(xiàn)象我們有必要介紹一下兩層神經(jīng)元網(wǎng)絡(luò)的表達(dá)
W是輸入權(quán)重,它以內(nèi)積的方式提取輸入在權(quán)重所在的方向上的成分,可以理解為一種特征提取的方式,加上偏置項(xiàng),然后再經(jīng)過非線性函數(shù)(也稱為激活函數(shù)),完成單個(gè)神經(jīng)元的計(jì)算,然后再把所有神經(jīng)元的輸出加權(quán)求和。為了方便,我們記
對于ReLU激活函數(shù),我們可以通過考慮輸入權(quán)重的角度和神經(jīng)元的幅度來理解每個(gè)神經(jīng)元的特征:, 其中?。考慮用上面的兩層神經(jīng)網(wǎng)絡(luò)來擬合四個(gè)一維的數(shù)據(jù)點(diǎn)。結(jié)合輸入權(quán)重和偏置項(xiàng),我們所關(guān)心的方向就是兩維的方向,因此可以用角度來表示其方向。下圖展示了,不同初始化下,神經(jīng)網(wǎng)絡(luò)的擬合結(jié)果(第一行),以及在訓(xùn)練前(青色)和訓(xùn)練后(紅色)特征分布的圖(第二行)
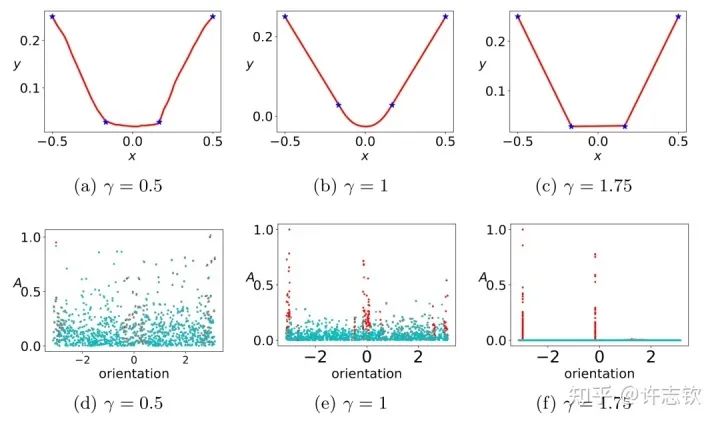 不同初始化的擬合結(jié)果
不同初始化的擬合結(jié)果
顯然,隨初始化尺度變小(從左到右,初始化尺度不斷變小),神經(jīng)網(wǎng)絡(luò)的擬合結(jié)果差異很大,在特征分布上,當(dāng)尺度很大(這里使用NTK的初始化),神經(jīng)網(wǎng)絡(luò)特征幾乎不變,和random feature這類線性模型差不多,而隨初始化變小,訓(xùn)練過程出現(xiàn)明顯的特征變化的過程。最有意思的是,這些特征的方向聚集在兩個(gè)主要的方向。我們把這種現(xiàn)象稱為參數(shù)凝聚。?大量的實(shí)際問題告訴我們神經(jīng)網(wǎng)絡(luò)比線性的方法要好很多,那非線性過程所呈現(xiàn)的參數(shù)凝聚有什么好處嗎??如下圖展示的一個(gè)極端凝聚的例子,對于一個(gè)隨機(jī)初始化的網(wǎng)絡(luò),經(jīng)過短暫的訓(xùn)練后,每個(gè)隱藏層神經(jīng)元的輸入權(quán)重是完全一致的,因此這個(gè)網(wǎng)絡(luò)可以等效成僅有一個(gè)隱藏層神經(jīng)元的小網(wǎng)絡(luò)。一般情況下,神經(jīng)元會凝聚到多個(gè)方向。
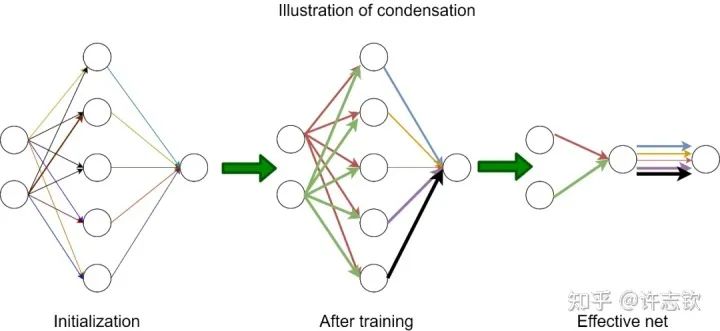 凝聚現(xiàn)象的例子
凝聚現(xiàn)象的例子
回顧在我們前面最開始提到的泛化迷團(tuán),以及我們最開始提出的問題“在實(shí)際訓(xùn)練中,神經(jīng)網(wǎng)絡(luò)真的很復(fù)雜嗎?”,在參數(shù)凝聚的情況下,對于一個(gè)表面看起來很多參數(shù)的網(wǎng)絡(luò),我們自然要問:神經(jīng)網(wǎng)絡(luò)實(shí)際的有效參數(shù)有多少??比如我們前面看到的兩層神經(jīng)網(wǎng)絡(luò)凝聚在兩個(gè)方向的例子,實(shí)際上,這個(gè)網(wǎng)絡(luò)的有效神經(jīng)元只有兩個(gè)。因此凝聚可以根據(jù)實(shí)際數(shù)據(jù)擬合的需求來有效地控制模型的復(fù)雜度。
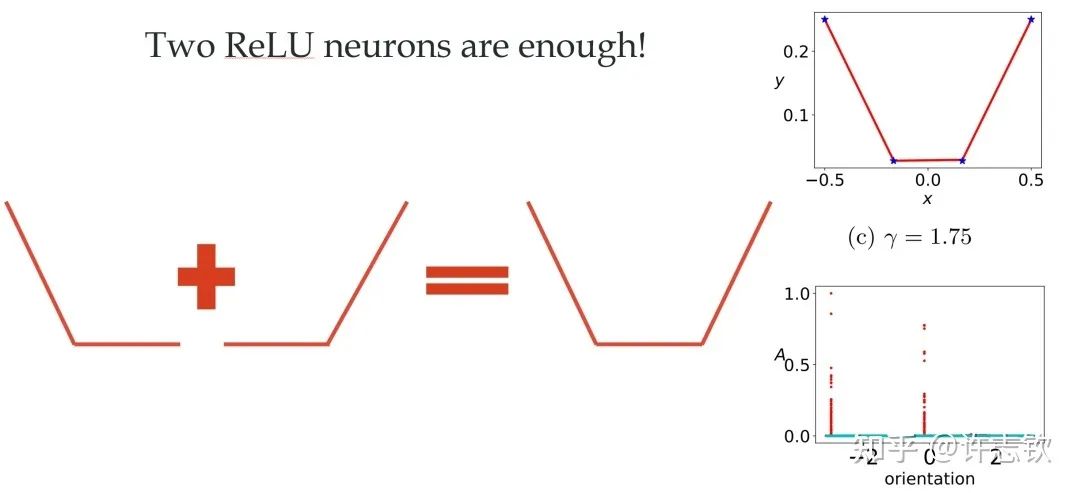
前面,我們只是通過一個(gè)簡單的例子來呈現(xiàn)凝聚現(xiàn)象,接下來重要的問題是:參數(shù)凝聚是非線性過程中普遍的現(xiàn)象嗎??在統(tǒng)計(jì)力學(xué)相圖的啟發(fā)下,我們在實(shí)驗(yàn)發(fā)現(xiàn)并理論推導(dǎo)出了兩層無限寬ReLU神經(jīng)網(wǎng)絡(luò)的相圖。基于不同的初始化尺度,以參數(shù)在訓(xùn)練前后的相對距離在無限寬極限下趨于零、常數(shù)、無窮作為判據(jù),相圖劃分了線性、臨界、凝聚三種動力學(xué)態(tài)(dynamical regime)。領(lǐng)域內(nèi)的一系列理論研究(包括NTK,mean-field等)都可以在我們的相圖中找到對應(yīng)的位置[3]。
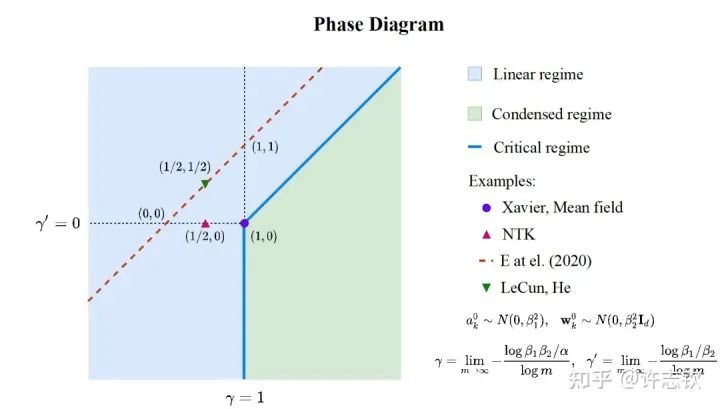 兩層ReLU網(wǎng)絡(luò)的相圖
兩層ReLU網(wǎng)絡(luò)的相圖
在三層無窮寬[15]的全連接網(wǎng)絡(luò)中,我們實(shí)驗(yàn)證明在所有非線性的區(qū)域,參數(shù)凝聚都是一種普遍的現(xiàn)象。理論上,我們證明當(dāng)初始化尺度足夠小的時(shí)候,在訓(xùn)練初始階段就會產(chǎn)生凝聚[4] 。有趣的是,我們在研究Dropout算法的隱式正則化的時(shí)候,發(fā)現(xiàn)Dropout算法會明顯地促進(jìn)參數(shù)凝聚地形成。?Dropout算法的想法是Hinton提出的,在神經(jīng)網(wǎng)絡(luò)的訓(xùn)練中,以一定概率p保留神經(jīng)元,是一種常用的技巧,對泛化能力的提升有明顯的幫助。我們首先來看一下擬合結(jié)果。下面左圖是沒有用Dropout的例子,放大擬合的函數(shù),可以看到明顯的小尺度的波動,右圖是用了Dropout的結(jié)果,擬合的函數(shù)要光滑很多。
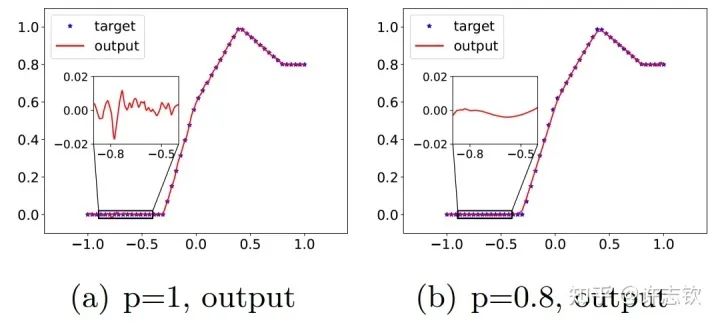 Dropout(右)使輸出更光滑
Dropout(右)使輸出更光滑
仔細(xì)看他們的特征分布時(shí),可以看到訓(xùn)練前(藍(lán)色)和訓(xùn)練后(橙色)的分布在有Dropout的情況下會明顯不同,且呈現(xiàn)出明顯地凝聚效應(yīng),有效參數(shù)變得更少,函數(shù)復(fù)雜度也相應(yīng)變得簡單光滑。
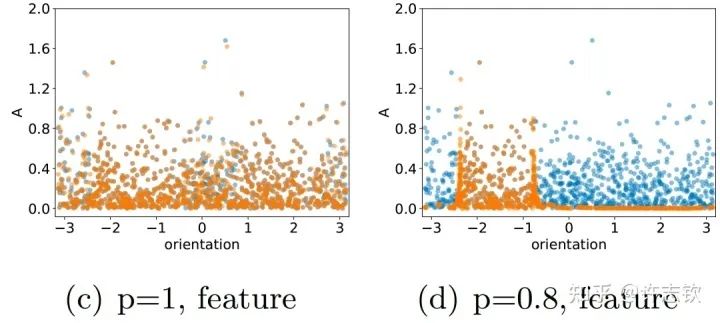 Dropout(右)使參數(shù)凝聚
Dropout(右)使參數(shù)凝聚
進(jìn)一步,我們分析為什么Dropout會帶來凝聚效應(yīng)。我們發(fā)現(xiàn)Dropout的訓(xùn)練會帶來一項(xiàng)特殊的隱式正則效應(yīng)。我們通過下面的例子來理解這個(gè)效應(yīng)。下面黃色和紅色兩種情況都能合成一個(gè)相同的向量,Dropout要求兩個(gè)分向量的模長平方和要最小,那顯然只有當(dāng)兩個(gè)向量的方向一致的時(shí)候,并且完全相等的時(shí)候,它們的模長平方和才能最小,對于w來說,這就是凝聚。

到目前,我們談了參數(shù)凝聚使得神經(jīng)網(wǎng)絡(luò)的有效規(guī)模變得很小,那為什么我們不直接訓(xùn)練一個(gè)小規(guī)模的網(wǎng)絡(luò)?大網(wǎng)絡(luò)和小網(wǎng)絡(luò)有什么差異??首先,我們用不同寬度的兩層網(wǎng)絡(luò)來擬合同一批數(shù)據(jù),下圖展示了它們的損失下降的過程。
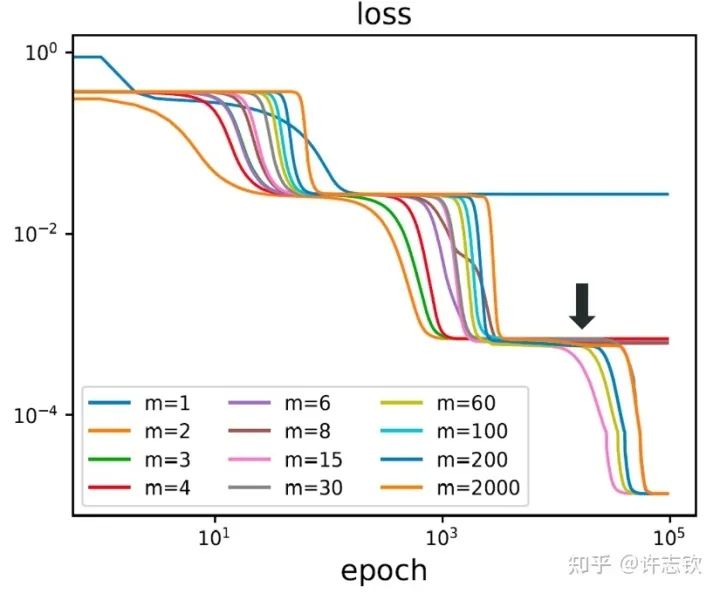
不同寬度的網(wǎng)絡(luò)的損失函數(shù)表現(xiàn)出了高度的相似性,它們會在共同的位置發(fā)生停留。那在共同的臺階處有什么相似性呢?下面左圖可以看到,對于上述箭頭指示的臺階,不同寬度網(wǎng)絡(luò)的輸出函數(shù)非常靠近。更進(jìn)一步看它們的特征圖(下右圖),它們都發(fā)生了強(qiáng)烈的凝聚現(xiàn)象。這些體現(xiàn)了它們的相似性。
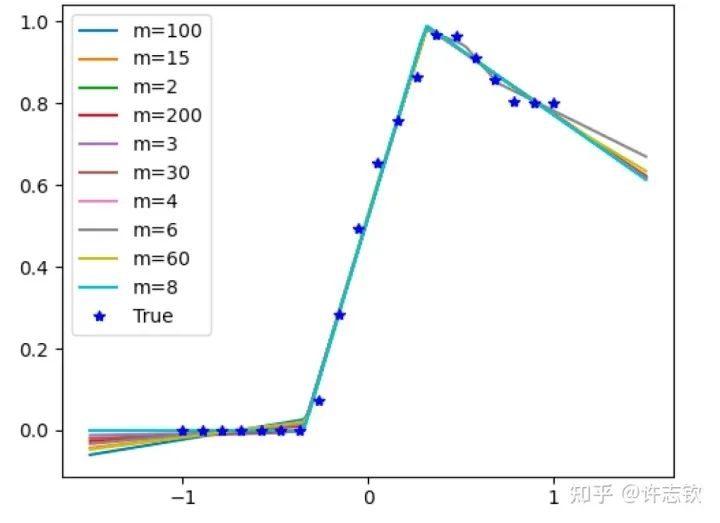
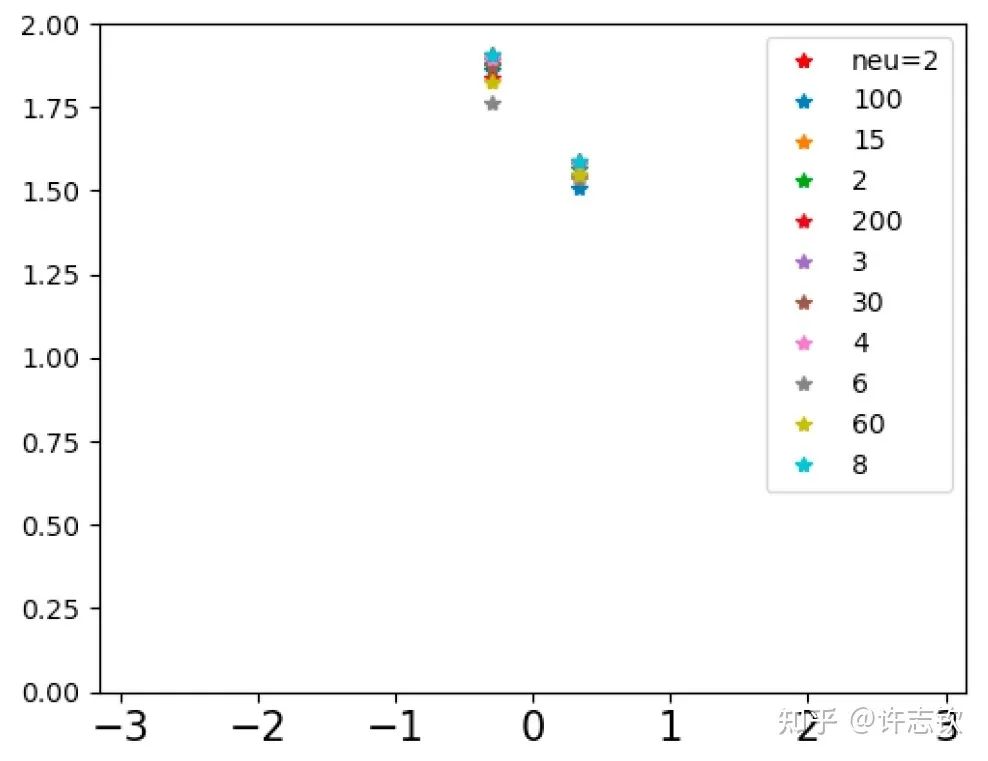
如果再仔細(xì)觀察他們的損失圖,可以發(fā)現(xiàn)當(dāng)寬度增加的時(shí)候,網(wǎng)絡(luò)的損失函數(shù)更容易下降,比如前面箭頭指的地方,相對小的網(wǎng)絡(luò)就停留在臺階上,大的網(wǎng)絡(luò)的損失才繼續(xù)下降。從實(shí)驗(yàn)上可以看出,大網(wǎng)絡(luò)凝聚時(shí)雖然和小網(wǎng)絡(luò)在表達(dá)能力類似,但看起來大網(wǎng)絡(luò)更容易訓(xùn)練。怎么解釋不同寬度的網(wǎng)絡(luò)的相似性以及大網(wǎng)絡(luò)的優(yōu)勢??在一個(gè)梯度下降的訓(xùn)練過程,出現(xiàn)平臺的原因很可能是因?yàn)橛?xùn)練路徑經(jīng)歷某個(gè)鞍點(diǎn)(附近有上升方向也有下降方向的極值點(diǎn))附近。不同寬度的網(wǎng)絡(luò)似乎會經(jīng)歷相同的鞍點(diǎn)。但參數(shù)量不同的網(wǎng)絡(luò),它們各自的鞍點(diǎn)生活在不同維度的空間,怎么會是同一點(diǎn)呢?
我們證明了不同寬度的網(wǎng)絡(luò)的損失景觀的極值點(diǎn)存在一個(gè)嵌入原則(Embedding Principle)[16], 即一個(gè)神經(jīng)網(wǎng)絡(luò)的損失景觀中 “包含”所有更窄神經(jīng)網(wǎng)絡(luò)損失景觀的所有臨界點(diǎn)(包括鞍點(diǎn)、局部最優(yōu)點(diǎn)和全局最優(yōu)點(diǎn)等)。簡單地說,就是一個(gè)網(wǎng)絡(luò)處理臨界點(diǎn)時(shí),通過一些特定的嵌入方式,可以把這個(gè)網(wǎng)絡(luò)嵌入到一個(gè)更寬的網(wǎng)絡(luò)中,嵌入過程能夠保持網(wǎng)絡(luò)輸出不變以及寬網(wǎng)絡(luò)仍然處于臨界點(diǎn)。最簡單的嵌入方式正是凝聚的逆過程,比如下圖是一種一步嵌入方式。更一般的嵌入方式我們在Journal of Machine Learning第一期的文章里[17]有詳細(xì)討論。
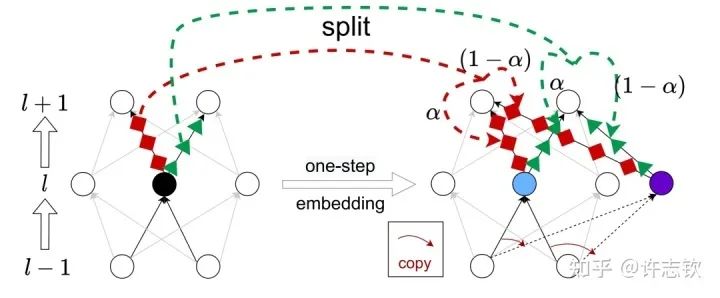
嵌入原則揭示了不同寬度網(wǎng)絡(luò)的相似性,當(dāng)然也提供了研究它們差異性的手段。由于在嵌入的過程中有自由參數(shù),因此在更大網(wǎng)絡(luò)的臨界點(diǎn)的退化程度越大。同樣的,一個(gè)大網(wǎng)絡(luò)的損失景觀里的臨界點(diǎn),如果它來源于更簡單的網(wǎng)絡(luò)的臨界點(diǎn)的嵌入,那么它的退化程度也越大(直觀可以理解它占的空間越大)。我們就可以猜測這些越簡單的臨界點(diǎn)越有可能被學(xué)習(xí)到。
另外,我們在理論上證明,在嵌入的過程中,臨界點(diǎn)附近的下降方向、上升方向都不會變少。這告訴我們,一個(gè)鞍點(diǎn)被嵌入到一個(gè)更大的網(wǎng)絡(luò)以后,它不可能變成一個(gè)極小值點(diǎn),但一個(gè)極小值點(diǎn)被嵌入到大網(wǎng)絡(luò)以后,它很有可能會變成鞍點(diǎn),產(chǎn)生更多的下降方向。我們在實(shí)驗(yàn)上也證明了嵌入過程會產(chǎn)生更多下降方向。
因此,我們有理由相信,大網(wǎng)絡(luò)盡管凝聚成有效的小網(wǎng)絡(luò),但它會比小網(wǎng)絡(luò)更容易訓(xùn)練。也就是大網(wǎng)絡(luò)既可以控制模型的復(fù)雜度(可能帶來更好的泛化),又可以使訓(xùn)練更容易。?我們的工作還發(fā)現(xiàn)了在深度上神經(jīng)網(wǎng)絡(luò)損失景觀的嵌入原則[18]。關(guān)于凝聚現(xiàn)象,同樣還有很多問題值得繼續(xù)深入。下面是一些例子。除了初始訓(xùn)練外,訓(xùn)練過程中的凝聚現(xiàn)象產(chǎn)生的機(jī)制是什么?不同的網(wǎng)絡(luò)結(jié)構(gòu)是否有凝聚現(xiàn)象?凝聚的過程和頻率原則有什么聯(lián)系?凝聚怎么定量地和泛化建立聯(lián)系?
總結(jié)
過去五年,在深度學(xué)習(xí)的基礎(chǔ)研究方面,我們主要圍繞頻率原則和參數(shù)凝聚兩類現(xiàn)象展開工作。從發(fā)現(xiàn)它們,意識到他們很有趣,再到解釋它們,并在一定程度上基于這些工作去理解深度學(xué)習(xí)的其它方面和設(shè)計(jì)更好的算法。未來五年,我們將在深度學(xué)習(xí)的基礎(chǔ)研究和AI for Science方面深入鉆研。
參考文獻(xiàn)
[1] Zhi-Qin John Xu*, Yaoyu Zhang, and Yanyang Xiao, Training behavior of deep neural network in frequency domain, arXiv preprint: 1807.01251, (2018), ICONIP 2019.
[2] Zhi-Qin John Xu* , Yaoyu Zhang, Tao Luo, Yanyang Xiao, Zheng Ma, Frequency Principle: Fourier Analysis Sheds Light on Deep Neural Networks, arXiv preprint: 1901.06523, Communications in Computational Physics (CiCP).
[3]Tao Luo#,Zhi-Qin John Xu #, Zheng Ma, Yaoyu Zhang*, Phase diagram for two-layer ReLU neural networks at infinite-width limit, arxiv 2007.07497 (2020), Journal of Machine Learning Research (2021)
[4]Hanxu Zhou, Qixuan Zhou, Tao Luo, Yaoyu Zhang*, Zhi-Qin John Xu*, Towards Understanding the Condensation of Neural Networks at Initial Training. arxiv 2105.11686 (2021), NeurIPS2022.
[5] Jihong Wang,Zhi-Qin John Xu*, Jiwei Zhang*, Yaoyu Zhang, Implicit bias in understanding deep learning for solving PDEs beyond Ritz-Galerkin method, CSIAM Trans. Appl. Math.
[6] Tao Luo, Zheng Ma,Zhi-Qin John Xu, Yaoyu Zhang, Theory of the frequency principle for general deep neural networks, CSIAM Trans. Appl. Math., arXiv preprint, 1906.09235 (2019).
[7] Yaoyu Zhang, Tao Luo, Zheng Ma,Zhi-Qin John Xu*, Linear Frequency Principle Model to Understand the Absence of Overfitting in Neural Networks. Chinese Physics Letters, 2021.
[8] Tao Luo*, Zheng Ma,Zhi-Qin John Xu, Yaoyu Zhang, On the exact computation of linear frequency principle dynamics and its generalization, SIAM Journal on Mathematics of Data Science (SIMODS) to appear, arxiv 2010.08153 (2020).
[9]Tao Luo*, Zheng Ma, Zhiwei Wang, Zhi-Qin John Xu, Yaoyu Zhang, An Upper Limit of Decaying Rate with Respect to Frequency in Deep Neural Network, To appear in Mathematical and Scientific Machine Learning 2022 (MSML22),
[10] Zhi-Qin John Xu* , Hanxu Zhou, Deep frequency principle towards understanding why deeper learning is faster, AAAI 2021, arxiv 2007.14313 (2020)
[11] Ziqi Liu, Wei Cai,Zhi-Qin John Xu* , Multi-scale Deep Neural Network (MscaleDNN) for Solving Poisson-Boltzmann Equation in Complex Domains, arxiv 2007.11207 (2020) Communications in Computational Physics (CiCP).
[12] Xi-An Li,Zhi-Qin John Xu* , Lei Zhang, A multi-scale DNN algorithm for nonlinear elliptic equations with multiple scales, arxiv 2009.14597, (2020) Communications in Computational Physics (CiCP).
[13] Xi-An Li,Zhi-Qin John Xu, Lei Zhang*, Subspace Decomposition based DNN algorithm for elliptic type multi-scale PDEs. arxiv 2112.06660 (2021)
[14]Yuheng Ma,Zhi-Qin John Xu*, Jiwei Zhang*, Frequency Principle in Deep Learning Beyond Gradient-descent-based Training, arxiv 2101.00747 (2021).
[15]Hanxu Zhou, Qixuan Zhou, Zhenyuan Jin, Tao Luo, Yaoyu Zhang,Zhi-Qin John Xu*, Empirical Phase Diagram for Three-layer Neural Networks with Infinite Width. arxiv 2205.12101 (2022), NeurIPS2022.
[16]Yaoyu Zhang*, Zhongwang Zhang, Tao Luo,Zhi-Qin John Xu*, Embedding Principle of Loss Landscape of Deep Neural Networks. NeurIPS 2021 spotlight, arxiv 2105.14573 (2021)
[17] Zhongwang Zhang,Zhi-Qin John Xu*, Implicit regularization of dropout. arxiv 2207.05952 (2022)
[18]Zhiwei Bai, Tao Luo,Zhi-Qin John Xu*, Yaoyu Zhang*, Embedding Principle in Depth for the Loss Landscape Analysis of Deep Neural Networks. arxiv 2205.13283 (2022)
編輯:黃飛
?






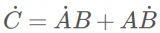






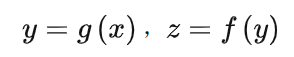
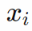








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論