什么是深度強化學習? 眾所周知,人類擅長解決各種挑戰性的問題,從低級的運動控制(如:步行、跑步、打網球)到高級的認知任務。
2023-07-01 10:29:50 1002
1002 
本文提出了一種適用于任意數據模態的自監督學習數據增強技術。 ? 自監督學習算法在自然語言處理、計算機視覺等領域取得了重大進展。這些自監督學習算法盡管在概念上是通用的,但是在具體操作上是基于特定的數據
2023-09-04 10:07:04738 
?機器學習按照模型類型分為監督學習模型、無監督學習模型兩大類。 1. 有監督學習 有監督學習通常是利用帶有專家標注的標簽的訓練數據,學習一個從輸入變量X到輸入變量Y的函數映射
2023-09-05 11:45:061161 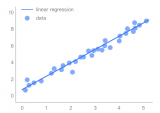
人工智能競爭,從算法模型的研發競爭,轉向數據和數據質量的競爭,這些成功的模型和算法主要是由監督學習推動的,而監督學習對數據極度饑渴,需要海量數據(大數據)支撐來達到應用的精準要求。而人工智能發展更趨
2018-05-11 09:12:0011650 `轉一篇好資料機器學習算法可以分為三大類:監督學習、無監督學習和強化學習。監督學習可用于一個特定的數據集(訓練集)具有某一屬性(標簽),但是其他數據沒有標簽或者需要預測標簽的情況。無監督學習可用
2017-04-18 18:28:36
、謀發展的決定性手段,這使得這一過去為分析師和數學家所專屬的研究領域越來越為人們所矚目。本書第一部分主要介紹機器學習基礎,以及如何利用算法進行分類,并逐步介紹了多種經典的監督學習算法,如k近鄰算法
2017-06-01 15:49:24
的性能。2.機器學習是對能通過經驗自動改進的計算機算法的研究。3.機器學習是用數據或以往的經驗,以此優化計算機程序的性能標準。機器學習算法可以分成下面幾種類別:?監督學習:從給定的訓練數據集中學習出一
2017-06-23 13:51:15
目錄人工智能基本概念機器學習算法1. 決策樹2. KNN3. KMEANS4. SVM5. 線性回歸深度學習算法1. BP2. GANs3. CNN4. LSTM應用人工智能基本概念數據集:訓練集
2021-09-06 08:21:17
強化學習的另一種策略(二)
2019-04-03 12:10:44
人工智能下面有哪些機器學習分支?如何用卷積神經網絡(CNN)方法去解決機器學習監督學習下面的分類問題?
2021-06-16 08:09:03
的不同,機器學習可分為:監督學習,無監督學習,半監督學習,強化學習。在這里我們講2種機器學習的常用方法:監督學習,無監督學習。監督學習是從標記的訓練數據來推斷一個功能的機器學習任務,可分為“回歸”和“分類
2018-07-27 12:54:20
內容2:課程一: TensoRFlow入門到熟練:課程二:圖像分類:課程三:物體檢測:課程四:人臉識別:課程五:算法實現:1、卷積神經網絡CNN2、循環神經網絡RNN3、強化學習DRL4、對抗性生成
2021-01-10 13:42:26
【深度學習基礎-17】非監督學習-Hierarchical clustering 層次聚類-python實現
2020-04-28 10:07:39
無監督學習算法中,我們沒有目標或結果變量來預測。 通常用于不同群體的群體聚類。無監督學習的例子:Apriori 算法,K-means。0.3 強化學習 工作原理: 強化學習(reinforcement
2018-10-23 14:31:12
強化學習在RoboCup帶球任務中的應用_劉飛
2017-03-14 08:00:00 0
0 基于半監督學習的跌倒檢測系統設計_李仲年
2017-03-19 19:11:453 機器學習算法可以分為三個大類:監督學習、無監督學習、強化學習。監督學習對于有屬性(標記)的特定數據集(訓練集)是非常有效的。無監督學習對于在給定未標記的數據集(目標沒有提前指定)上發現潛在關系是非
2017-09-20 11:15:331 機器學習的本質是模式識別。 一部分可以用于預測(有監督學習,無監督學習),另一類直接用于決策(強化學習),機器學習的一個核心任務即模式識別, 我們通常可以用模式識別來對我們未來研究的系統進行歸類, 并預測各種可能的未來結果。
2017-10-13 10:56:431626 
與監督機器學習不同,在強化學習中,研究人員通過讓一個代理與環境交互來訓練模型。當代理的行為產生期望的結果時,它得到正反饋。例如,代理人獲得一個點數或贏得一場比賽的獎勵。簡單地說,研究人員加強了代理人的良好行為。
2018-07-13 09:33:0024321 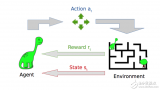
深度強化學習DRL自提出以來, 已在理論和應用方面均取得了顯著的成果。尤其是谷歌DeepMind團隊基于深度強化學習DRL研發的AlphaGo,將深度強化學習DRL成推上新的熱點和高度,成為人工智能歷史上一個新的里程碑。因此,深度強化學習DRL非常值得研究。
2018-06-29 18:36:0027596 薩頓在專訪中(再次)科普了強化學習、深度強化學習,并談到了這項技術的潛力,以及接下來的發展方向:預測學習
2017-12-27 09:07:1510857 針對路徑規劃算法收斂速度慢及效率低的問題,提出了一種基于分層強化學習及人工勢場的多Agent路徑規劃算法。首先,將多Agent的運行環境虛擬為一個人工勢能場,根據先驗知識確定每點的勢能值,它代表最優
2017-12-27 14:32:020 本文提出了一種LCS和LS-SVM相結合的多機器人強化學習方法,LS-SVM獲得的最優學習策略作為LCS的初始規則集。LCS通過與環境的交互,能更快發現指導多機器人強化學習的規則,為強化學習系統
2018-01-09 14:43:490 問題,對半監督學習中的協同訓練算法進行改進,提出了一種基于多學習器協同訓練模型的人體行為識別方法.這是一種基于半監督學習框架的識別算法,該方法首先通過基于Q統計量的學習器差異性度量選擇算法來挑取出協同訓練中基學習
2018-01-21 10:41:091 傳統上,強化學習在人工智能領域占據著一個合適的地位。但強化學習在過去幾年已開始在很多人工智能計劃中發揮更大的作用。
2018-03-03 14:16:563924 and Unsupervised Learning 我們已經學習了許多機器學習算法,包括線性回歸,Logistic回歸,神經網絡以及支持向量機。這些算法都有一個共同點,即給出的訓練樣本自身帶有標記。比如
2018-05-01 17:43:0012211 
強化學習是智能系統從環境到行為映射的學習,以使獎勵信號(強化信號)函數值最大,強化學習不同于連接主義學習中的監督學習,主要表現在教師信號上,強化學習中由環境提供的強化信號是對產生動作的好壞作一種評價
2018-05-30 06:53:001234 在機器學習(Machine learning)領域。主要有三類不同的學習方法:監督學習(Supervised learning)、非監督學習(Unsupervised learning)、半監督學習(Semi-supervised learning)。
2018-05-07 09:09:0113404 無監督學習是機器學習技術中的一類,用于發現數據中的模式。本文介紹用Python進行無監督學習的幾種聚類算法,包括K-Means聚類、分層聚類、t-SNE聚類、DBSCAN聚類等。
2018-05-27 09:59:1329728 
Q Learning算法是由Watkins于1989年在其博士論文中提出,是強化學習發展的里程碑,也是目前應用最為廣泛的強化學習算法。
2018-07-05 14:10:003368 自動駕駛汽車首先是人工智能問題,而強化學習是機器學習的一個重要分支,是多學科多領域交叉的一個產物。今天人工智能頭條給大家介紹強化學習在自動駕駛的一個應用案例,無需3D地圖也無需規則,讓汽車從零開始在二十分鐘內學會自動駕駛。
2018-07-10 09:00:294676 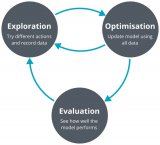
強化學習是人工智能基本的子領域之一,在強化學習的框架中,智能體通過與環境互動,來學習采取何種動作能使其在給定環境中的長期獎勵最大化,就像在上述的棋盤游戲寓言中,你通過與棋盤的互動來學習。
2018-07-15 10:56:3717106 
而這時,強化學習會在沒有任何標簽的情況下,通過先嘗試做出一些行為得到一個結果,通過這個結果是對還是錯的反饋,調整之前的行為,就這樣不斷的調整,算法能夠學習到在什么樣的情況下選擇什么樣的行為可以得到最好的結果。
2018-08-21 09:18:2519123 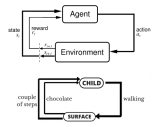
在機器學習中,有一種叫做「沒有免費的午餐」的定理。簡而言之,它指出沒有任何一種算法對所有問題都有效,在監督學習(即預測建模)中尤其如此。
2018-08-24 10:51:075514 強化學習是一種訓練主體最大化獎勵的學習機制,對于目標條件下的強化學習來說可以將獎勵函數設為當前狀態與目標狀態之間距離的反比函數,那么最大化獎勵就對應著最小化與目標函數的距離。
2018-09-24 10:11:006779 之前接觸的強化學習算法都是單個智能體的強化學習算法,但是也有很多重要的應用場景牽涉到多個智能體之間的交互。
2018-11-02 16:18:1521017 根據訓練數據是否有標記,機器學習任務大致分為兩大類:監督學習和非監督學習,監督學習主要包括分類和回歸等,非監督學習主要包括聚類和頻繁項集挖掘等。
2018-11-10 10:55:593765 Darktrace新網絡安全公司與劍橋大學的數學家合作,開發了一種利用機器學習來捕捉內部漏洞的工具。它運用無監督學習方法,查看大量未標記的數據,并找到不遵循典型模式的碎片。這些原始數據匯集到60多種不同的無監督學習算法中,它們相互競爭以發現異常行為。
2018-11-22 16:01:501099 with experience E(一個程序從經驗E中學習解決任務T進行某一任務量度P,通過P測量在T的表現而提高經驗E(另一種定義:機器學習是用數據或以往的經驗,以此優化計算機程序的性能標準。) 不同類型的機器學習算法:主要討論監督學習和無監督學習 監督學習:利用一組已知類別的樣本調整分類器的參數
2018-12-03 17:12:01401 OpenAI 近期發布了一個新的訓練環境 CoinRun,它提供了一個度量智能體將其學習經驗活學活用到新情況的能力指標,而且還可以解決一項長期存在于強化學習中的疑難問題——即使是廣受贊譽的強化算法在訓練過程中也總是沒有運用監督學習的技術。
2019-01-01 09:22:002122 
無監督學習是一種用于在數據中查找模式的機器學習技術。無監督算法給出的數據不帶標記,只給出輸入變量(X),沒有相應的輸出變量。在無監督學習中,算法自己去發現數據中有趣的結構。
2019-01-21 17:23:003915 就目前來看,半監督學習是一個很有潛力的方向。
2019-06-18 17:24:142249 在谷歌最新的論文中,研究人員提出了“非政策強化學習”算法OPC,它是強化學習的一種變體,它能夠評估哪種機器學習模型將產生最好的結果。數據顯示,OPC比基線機器學習算法有著顯著的提高,更加穩健可靠。
2019-06-22 11:17:083374 以機器學習中的監督學習為例,監督學習是從一組帶有標記的數據中學習。
2019-07-04 15:31:49303 在監督學習中,機器在標記數據的幫助下進行訓練,即帶有正確答案標記的數據。而在無監督機器學習中,模型自主發現信息進行學習。與監督學習模型相比,無監督模型更適合于執行困難的處理任務。
2019-09-20 15:01:302999 深度學習作為機器學習的一個分支,其學習方法可以分為監督學習和無監督學習。
2020-01-30 09:29:002924 
強化學習非常適合實現自主決策,相比之下監督學習與無監督學習技術則無法獨立完成此項工作。
2019-12-10 14:34:571092 惰性是人類的天性,然而惰性能讓人類無需過于復雜的練習就能學習某項技能,對于人工智能而言,是否可有基于惰性的快速學習的方法?本文提出一種懶惰強化學習(Lazy reinforcement learning, LRL) 算法。
2020-01-16 17:40:00745 機器學習(ML)是人工智能(AI)的子集,它試圖以幾種不同的方式從數據集“學習”,其中包括監督學習和無監督學習。
2020-03-14 10:50:01564 無監督機器學習是近年才發展起來的反欺詐手法。目前國內反欺詐金融服務主要是應用黑白名單、有監督學習和無監督機器學習的方法來實現。
2020-05-01 22:11:00861 深度學習DL是機器學習中一種基于對數據進行表征學習的方法。深度學習DL有監督和非監督之分,都已經得到廣泛的研究和應用。強化學習RL是通過對未知環境一邊探索一邊建立環境模型以及學習得到一個最優策略。強化學習是機器學習中一種快速、高效且不可替代的學習算法。
2020-05-16 09:20:403150 深度學習DL是機器學習中一種基于對數據進行表征學習的方法。深度學習DL有監督和非監督之分,都已經得到廣泛的研究和應用。強化學習RL是通過對未知環境一邊探索一邊建立環境模型以及學習得到一個最優策略。強化學習是機器學習中一種快速、高效且不可替代的學習算法。
2020-06-13 11:39:405529 無監督學習的好處之一是,它不需要監督學習必須經歷的費力的數據標記過程。但是,要權衡的是,評估其性能的有效性也非常困難。相反,通過將監督學習算法的輸出與測試數據的實際標簽進行比較,可以很容易地衡量監督學習算法的準確性。
2020-07-07 10:18:365308 來“訓練”,通過各種算法從數據中學習如何完成任務。機器學習傳統的算法包括決策樹、聚類、貝葉斯分類等。從學習方法上來分可以分為監督學習、無監督學習、半監督學習、集成學習、深度學習和強化學習。
2020-07-26 11:14:4410904 近期,有不少報道強化學習算法在 GO、Dota 2 和 Starcraft 2 等一系列游戲中打敗了專業玩家的新聞。強化學習是一種機器學習類型,能夠在電子游戲、機器人、自動駕駛等復雜應用中運用人工智能。
2020-07-27 08:50:15715 Viet Nguyen就是其中一個。這位來自德國的程序員表示自己只玩到了第9個關卡。因此,他決定利用強化學習AI算法來幫他完成未通關的遺憾。
2020-07-29 09:30:162429 在機器學習領域,有種說法叫做“世上沒有免費的午餐”,簡而言之,它是指沒有任何一種算法能在每個問題上都能有最好的效果,這個理論在監督學習方面體現得尤為重要。
2020-07-31 16:06:10854 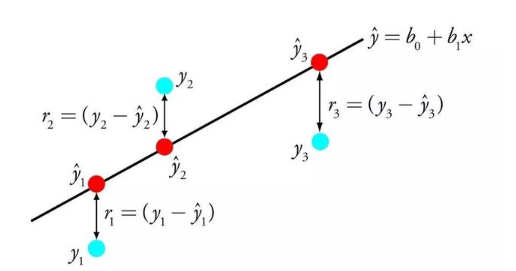
本節概述機器學習及其三個分類(監督學習、非監督學習和強化學習)。首先,與機器學習相關的術語有人工智能(Artificial Intelligence,AI)、機器學習(Machine Learning,ML)、強化學習、深度學習等,這里對這些術語進行簡單的整理。
2020-08-14 12:24:4723092 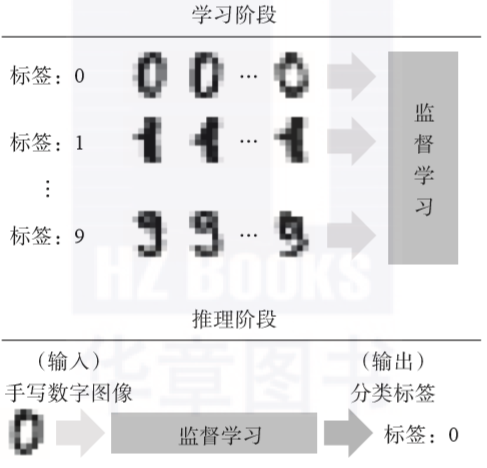
導讀 最基礎的半監督學習的概念,給大家一個感性的認識。 半監督學習(SSL)是一種機器學習技術,其中任務是從一個小的帶標簽的數據集和相對較大的未帶標簽的數據中學習得到的。SSL的目標是要比單獨
2020-11-02 16:08:142344 有趣的方法,用來解決機器學習中缺少標簽數據的問題。SSL利用未標記的數據和標記的數據集來學習任務。SSL的目標是得到比單獨使用標記數據訓練的監督學習模型更好的結果。這是關于半監督學習的系列文章的第2部分,詳細介紹了一些基本的SSL技
2020-11-02 16:14:552651 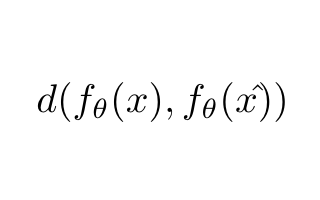
強化學習屬于機器學習中的一個子集,它使代理能夠理解在特定環境中執行特定操作的相應結果。目前,相當一部分機器人就在使用強化學習掌握種種新能力。
2020-11-06 15:33:491552 機器學習的基本過程,羅列了幾個主要流程和關鍵要素;繼而展開介紹機器學習主要的算法框架,包括監督學習算法,無監督學習算法和常用的降維,特征選擇算法等;最后在業務實踐的過程中,給出了一個可行的項目管理流程,可供參考。
2020-11-12 10:28:4810451 為什么半監督學習是機器學習的未來。 監督學習是人工智能領域的第一種學習類型。從它的概念開始,無數的算法,從簡單的邏輯回歸到大規模的神經網絡,都已經被研究用來提高精確度和預測能力。 然而,一個重大突破
2020-11-27 10:42:073610 監督學習是人工智能領域的第一種學習類型。從它的概念開始,無數的算法,從簡單的邏輯回歸到大規模的神經網絡,都已經被研究用來提高精...
2020-12-08 23:32:541096 深度強化學習是深度學習與強化學習相結合的產物,它集成了深度學習在視覺等感知問題上強大的理解能力,以及強化學習的決策能力,實現了...
2020-12-10 18:32:50374 RLax(發音為“ relax”)是建立在JAX之上的庫,它公開了用于實施強化學習智能體的有用構建塊。。報道:深度強化學習實驗室作者:DeepRL ...
2020-12-10 18:43:23499 本文主要介紹深度強化學習在任務型對話上的應用,兩者的結合點主要是將深度強化學習應用于任務型對話的策略學習上來源:騰訊技術工程微信號
2020-12-10 19:02:45781 幾乎所有的機器學習算法都歸結為求解最優化問題。有監督學習算法在訓練時通過優化一個目標函數而得到模型,然后用模型進行預測。無監督學習算法通常通過優化一個目標函數完成數據降維或聚類。強化學習算法在訓練
2020-12-26 09:52:103816 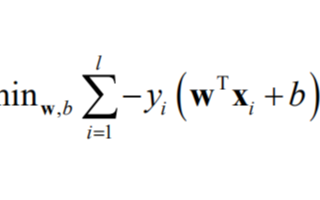
高成本的人工標簽使得弱監督學習備受關注。seed-driven 是弱監督學習中的一種常見模型。該模型要求用戶提供少量的seed words,根據seed words對未標記的訓練數據生成偽標簽,增加
2021-01-18 16:04:272657 機器學習可以分為監督學習,半監督學習,非監督學習,強化學習,深度學習等。監督學習是先用帶有標簽的數據集合學習得到一個模型,然后再使用這個模型對新的標本進行預測。格物斯坦認為:帶標簽的數據進行特征提取
2021-03-12 16:01:272908 聚類算法,迭代地從數據集中篩選出多個中心點,以每個中心點為簇中心進行局部聚類,并以中心點為頂點構建圖,實現基于LGC的半監督學習。實驗結果表明,優化后的LGC方法在D31、 Aggregation等數據集上具有較好的魯棒性,在標注正確率
2021-03-11 11:21:5721 自監督學習讓 AI 系統能夠從很少的數據中學習知識,這樣才能識別和理解世界上更微妙、更不常見的表示形式。
2021-03-30 17:09:355596 
強化學習( Reinforcement learning,RL)作為機器學習領域中與監督學習、無監督學習并列的第三種學習范式,通過與環境進行交互來學習,最終將累積收益最大化。常用的強化學習算法分為
2021-04-08 11:41:5811 深度強化學習(DRL)作為機器學習的重要分攴,在 Alphago擊敗人類后受到了廣泛關注。DRL以種試錯機制與環境進行交互,并通過最大化累積獎賞最終得到最優策略。強化學習可分為無模型強化學習和模型
2021-04-12 11:01:529 當機器人遇見強化學習,會碰出怎樣的火花? 一名叫 Cassie 的機器人,給出了生動演繹。 最近,24 歲的中國南昌小伙李鐘毓和其所在團隊,用強化學習教 Cassie 走路 ,目前它已學會蹲伏走路
2021-04-13 09:35:092164 
一種新型的多智能體深度強化學習算法
2021-06-23 10:42:4736 多Agent 深度強化學習綜述 來源:《自動化學報》,作者梁星星等 摘 要?近年來,深度強化學習(Deep reinforcement learning,DRL) 在諸多復雜序貫決策問題中取得巨大
2022-01-18 10:08:011226 
監督學習|機器學習| 集成學習|進化計算| 非監督學習| 半監督學習| 自監督學習|?無監督學習| 隨著人工智能、元宇宙、數據安全、可信隱私用計算、大數據等領域的快速發展,自監督學習脫穎而出,致力于
2022-01-20 10:52:104518 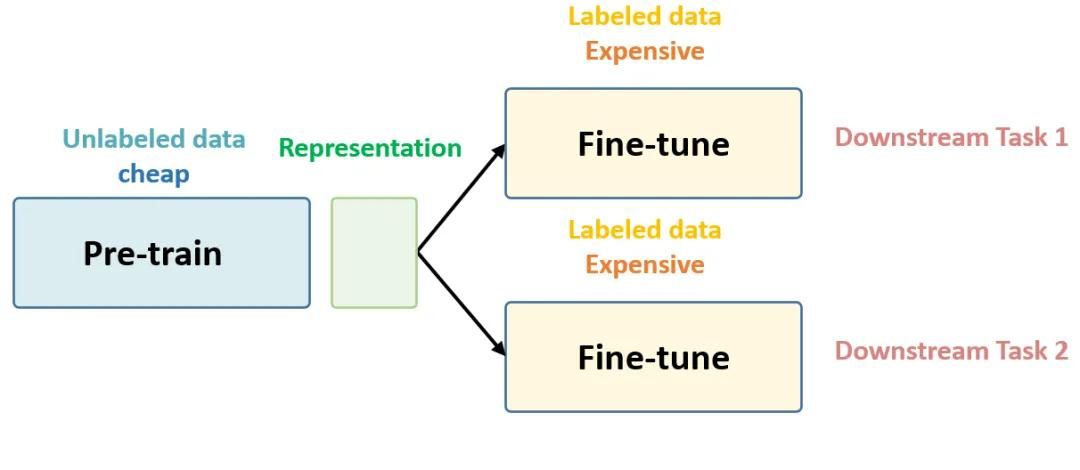
自監督學習的流行是勢在必然的。在各種主流有監督學習任務都做到很成熟之后,數據成了最重要的瓶頸。從無標注數據中學習有效信息一直是...
2022-01-26 18:50:171 融合零樣本學習和小樣本學習的弱監督學習方法綜述 來源:《系統工程與電子技術》,作者潘崇煜等 摘 要:?深度學習模型嚴重依賴于大量人工標注的數據,使得其在數據缺乏的特殊領域內應用嚴重受限。面對數據缺乏
2022-02-09 11:22:371731 
一種基于偽標簽半監督學習的小樣本調制識別算法 來源:《西北工業大學學報》,作者史蘊豪等 摘 要:針對有標簽樣本較少條件下的通信信號調制識別問題,提出了一種基于偽標簽半監督學習技術的小樣本調制方式分類
2022-02-10 11:37:36627 源自:AI知識干貨 根據數據類型的不同,對一個問題的建模有不同的方式。在機器學習或者人工智能領域,人們首先會考慮算法的學習方式。在機器學習領域,有幾種主要的學習方式。將算法按照學習方式分類是一個不錯
2022-08-22 09:57:331446 
當使用監督學習(Supervised Learning)對大量高質量的標記數據(Labeled Data)進行訓練時,神經網絡模型會產生有競爭力的結果。例如,根據Paperswithcode網站統計
2022-10-18 16:28:03939 來源:DeepHub IMBA 強化學習的基礎知識和概念簡介(無模型、在線學習、離線強化學習等) 機器學習(ML)分為三個分支:監督學習、無監督學習和強化學習。 監督學習(SL) : 關注在給
2022-12-20 14:00:02828 作者:Siddhartha Pramanik 來源:DeepHub IMBA 目前流行的強化學習算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。這些算法
2023-02-03 20:15:06747 根據有無標簽,監督學習可分類為:傳統的監督學習(Traditional Supervised Learning)、非監督學習(Unsupervised Learning)、半監督學習(Semi-supervised Learning)。
2023-04-18 16:26:13630 強化學習(RL)是人工智能的一個子領域,專注于決策過程。與其他形式的機器學習相比,強化學習模型通過與環境交互并以獎勵或懲罰的形式接收反饋來學習。
2023-06-09 09:23:23355 3.機器學習谷歌CEO桑達爾·皮查伊在一封致股東信中,把機器學習譽為人工智能和計算的真正未來,可想而知機器學習在人工智能研究領域的重要地位。機器學習的方式包括有監督學習、無監督學習、半監督學習和強化學習
2022-03-22 09:50:11470 
來源:DeepHubIMBA強化學習的基礎知識和概念簡介(無模型、在線學習、離線強化學習等)機器學習(ML)分為三個分支:監督學習、無監督學習和強化學習。監督學習(SL):關注在給定標記訓練數據
2023-01-05 14:54:05419 
作者:SiddharthaPramanik來源:DeepHubIMBA目前流行的強化學習算法包括Q-learning、SARSA、DDPG、A2C、PPO、DQN和TRPO。這些算法已被用于在游戲
2023-02-06 15:06:38665 摘要:基于強化學習的目標檢測算法在檢測過程中通常采用預定義搜索行為,其產生的候選區域形狀和尺寸變化單一,導致目標檢測精確度較低。為此,在基于深度強化學習的視覺目標檢測算法基礎上,提出聯合回歸與深度
2023-07-19 14:35:020 了基于神經網絡的機器學習方法。 深度學習算法可以分為兩大類:監督學習和無監督學習。監督學習的基本任務是訓練模型去學習輸入數據的特征和其對應的標簽,然后用于新數據的預測。而無監督學習通常用于聚類、降維和生成模型等任務中
2023-08-17 16:11:26638 的區別。 1. 機器學習 機器學習是指通過數據使機器能夠自動地學習和改進性能的算法。機器學習是人工智能的一個重要分支,它通過一系列的訓練樣本,讓機器從數據中學習規律,從而得出預測或決策。機器學習算法可以分為有監督學習
2023-08-17 16:11:402734 機器學習算法匯總 機器學習算法分類 機器學習算法模型 機器學習是人工智能的分支之一,它通過分析和識別數據模式,學習從中提取規律,并用于未來的決策和預測。在機器學習中,算法是最基本的組成部分之一。算法
2023-08-17 16:11:48632 機器學習算法總結 機器學習算法是什么?機器學習算法優缺點? 機器學習算法總結 機器學習算法是一種能夠從數據中自動學習的算法。它能夠從訓練數據中學習特征,進而對未知數據進行分類、回歸、聚類等任務。通過
2023-08-17 16:11:50939 機器學習算法入門 機器學習算法介紹 機器學習算法對比 機器學習算法入門、介紹和對比 隨著機器學習的普及,越來越多的人想要了解和學習機器學習算法。在這篇文章中,我們將會簡單介紹機器學習算法的基本概念
2023-08-17 16:27:15569 有許多不同的類型和應用。根據機器學習的任務類型,可以將其分為幾種不同的算法類型。本文將介紹機器學習的算法類型以及分類算法和預測算法。 機器學習的算法類型 1. 監督學習算法 在監督學習算法中,已知標記數據和相應的輸出
2023-08-17 16:30:111245 深度學習作為機器學習的一個分支,其學習方法可以分為監督學習和無監督學習。兩種方法都具有其獨特的學習模型:多層感知機 、卷積神經網絡等屬于監 督學習;深度置信網 、自動編碼器 、去噪自動編碼器 、稀疏編碼等屬于無監督學習。
2023-10-09 10:23:42303 
強化學習是機器學習的方式之一,它與監督學習、無監督學習并列,是三種機器學習訓練方法之一。 在圍棋上擊敗世界第一李世石的 AlphaGo、在《星際爭霸2》中以 10:1 擊敗了人類頂級職業玩家
2023-10-30 11:36:401051 
 電子發燒友App
電子發燒友App









 工商網監
工商網監
評論