 電子發(fā)燒友App
電子發(fā)燒友App


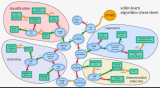
本文是對機器學(xué)習(xí)算法的一個概覽,以及個人的學(xué)習(xí)小結(jié)。通過閱讀本文,可以快速地對機器學(xué)習(xí)算法有一個比較清晰的了解。本文承諾不會出現(xiàn)任何數(shù)學(xué)公式及推導(dǎo),適合茶余飯后輕松閱讀,希望能讓讀者比較舒適地獲取到一點有用的東西。
本文主要分為三部分,第一部分為異常檢測算法的介紹,個人感覺這類算法對監(jiān)控類系統(tǒng)是很有借鑒意義的;第二部分為機器學(xué)習(xí)的幾個常見算法簡介;第三部分為深度學(xué)習(xí)及強化學(xué)習(xí)的介紹。最后會有本人的一個小結(jié)。
1 異常檢測算法
異常檢測,顧名思義就是檢測異常的算法,比如網(wǎng)絡(luò)質(zhì)量異常、用戶訪問行為異常、服務(wù)器異常、交換機異常和系統(tǒng)異常等,都是可以通過異常檢測算法來做監(jiān)控的,個人認(rèn)為這種算法很值得我們做監(jiān)控的去借鑒引用,所以我會先單獨介紹這一部分的內(nèi)容。
異常定義為“容易被孤立的離群點 (more likely to be separated)”——可以理解為分布稀疏且離密度高的群體較遠(yuǎn)的點。用統(tǒng)計學(xué)來解釋,在數(shù)據(jù)空間里面,分布稀疏的區(qū)域表示數(shù)據(jù)發(fā)生在此區(qū)域的概率很低,因而可以認(rèn)為落在這些區(qū)域里的數(shù)據(jù)是異常的。
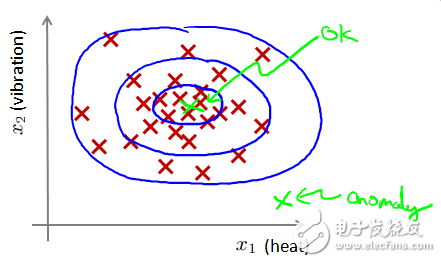
圖1-1離群點表現(xiàn)為遠(yuǎn)離密度高的正常點
如圖1-1所示,在藍(lán)色圈內(nèi)的數(shù)據(jù)屬于該組數(shù)據(jù)的可能性較高,而越是偏遠(yuǎn)的數(shù)據(jù),其屬于該組數(shù)據(jù)的可能性就越低。
下面是幾種異常檢測算法的簡介。
1.1 基于距離的異常檢測算法
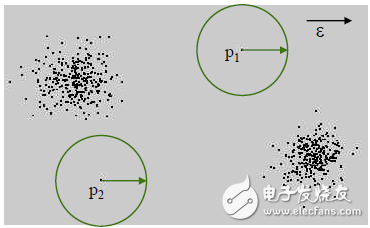
圖1-2 基于距離的異常檢測
思想:一個點如果身邊沒有多少小伙伴,那么就可以認(rèn)為這是一個異常點。
步驟:給定一個半徑r,計算以當(dāng)前點為中心、半徑為r的圓內(nèi)的點的個數(shù)與總體個數(shù)的比值。如果該比值小于一個閾值,那么就可以認(rèn)為這是一個異常點。
1.2 基于深度的異常檢測算法
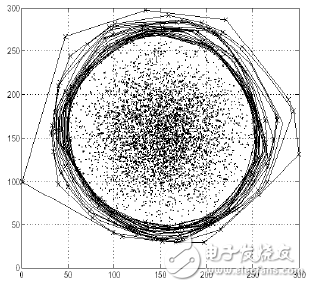
圖1-3 基于深度的異常檢測算法
思想:異常點遠(yuǎn)離密度大的群體,往往處于群體的最邊緣。
步驟:通過將最外層的點相連,并表示該層為深度值為1;然后將次外層的點相連,表示該層深度值為2,重復(fù)以上動作。可以認(rèn)為深度值小于某個數(shù)值k的為異常點,因為它們是距離中心群體最遠(yuǎn)的點。
1.3 基于分布的異常檢測算法
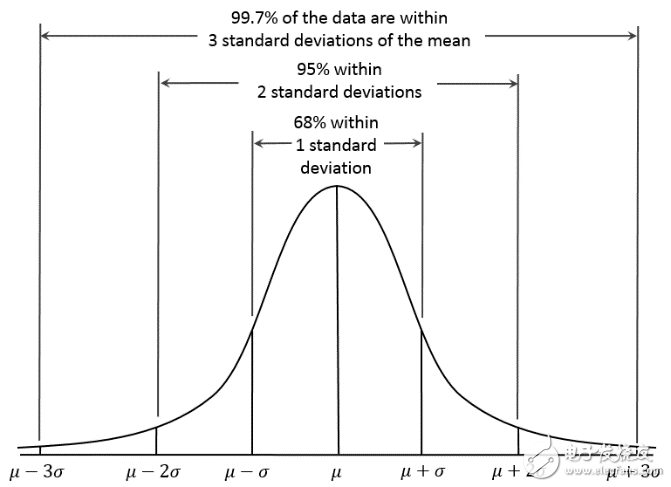
圖1-4 高斯分布
思想:當(dāng)前數(shù)據(jù)點偏離總體數(shù)據(jù)平均值3個標(biāo)準(zhǔn)差時,可以認(rèn)為是一個異常點(偏離多少個標(biāo)準(zhǔn)差可視實際情況調(diào)整)。
步驟:計算已有數(shù)據(jù)的均值及標(biāo)準(zhǔn)差。當(dāng)新來的數(shù)據(jù)點偏離均值3個標(biāo)準(zhǔn)差時,視為異常點。
1.4 基于劃分的異常檢測算法
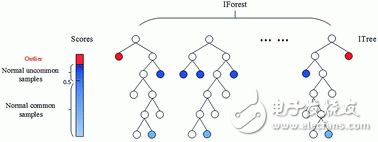
圖1-5孤立深林
思想:將數(shù)據(jù)不斷通過某個屬性劃分,異常點通常能很早地被劃分到一邊,也就是被早早地孤立起來。而正常點則由于群體眾多,需要更多次地劃分。
步驟:通過以下方式構(gòu)造多顆孤立樹:在當(dāng)前節(jié)點隨機挑選數(shù)據(jù)的一個屬性,并隨機選取屬性的一個值,將當(dāng)前節(jié)點中所有數(shù)據(jù)劃分到左右兩個葉子節(jié)點;如果葉子節(jié)點深度較小或者葉子節(jié)點中的數(shù)據(jù)點還很多,則繼續(xù)上述的劃分。異常點表現(xiàn)為在所有孤立樹中會有一個平均很低的樹的深度,如圖1-5中的紅色所示為深度很低的異常點。
2 機器學(xué)習(xí)常見算法
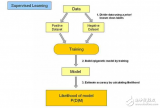
簡單介紹機器學(xué)習(xí)的幾個常見算法:k近鄰、k-means聚類、決策樹、樸素貝葉斯分類器、線性回歸、邏輯回歸、隱馬爾可夫模型及支持向量機。遇到講得不好的地方建議直接跳過。
2.1 K近鄰
圖2-1距離最近的3個點里面有2個點為紅三角,所以待判定點應(yīng)為紅三角
分類問題。對于待判斷的點,從已有的帶標(biāo)簽的數(shù)據(jù)點中找到離它最近的幾個數(shù)據(jù)點,根據(jù)它們的標(biāo)簽類型,以少數(shù)服從多數(shù)原則決定待判斷點的類型。
2.2 k-means聚類
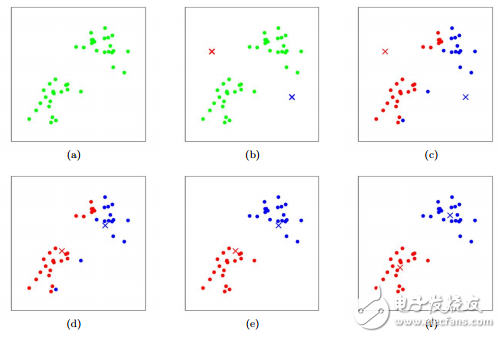
圖2-2不斷迭代完成“物以類聚”
k-means聚類的目標(biāo)是要找到一個分割,使得距離平方和最小。初始化k個中心點;通過歐式距離或其他距離計算方式,求取各個數(shù)據(jù)點離這些中心點的距離,將最靠近某個中心點的數(shù)據(jù)點標(biāo)識為同一類,然后再從標(biāo)識為同一類的數(shù)據(jù)點中求出新的中心點替代之前的中心點,重復(fù)上述計算過程,直到中心點位置收斂不再變動。
2.3 決策樹
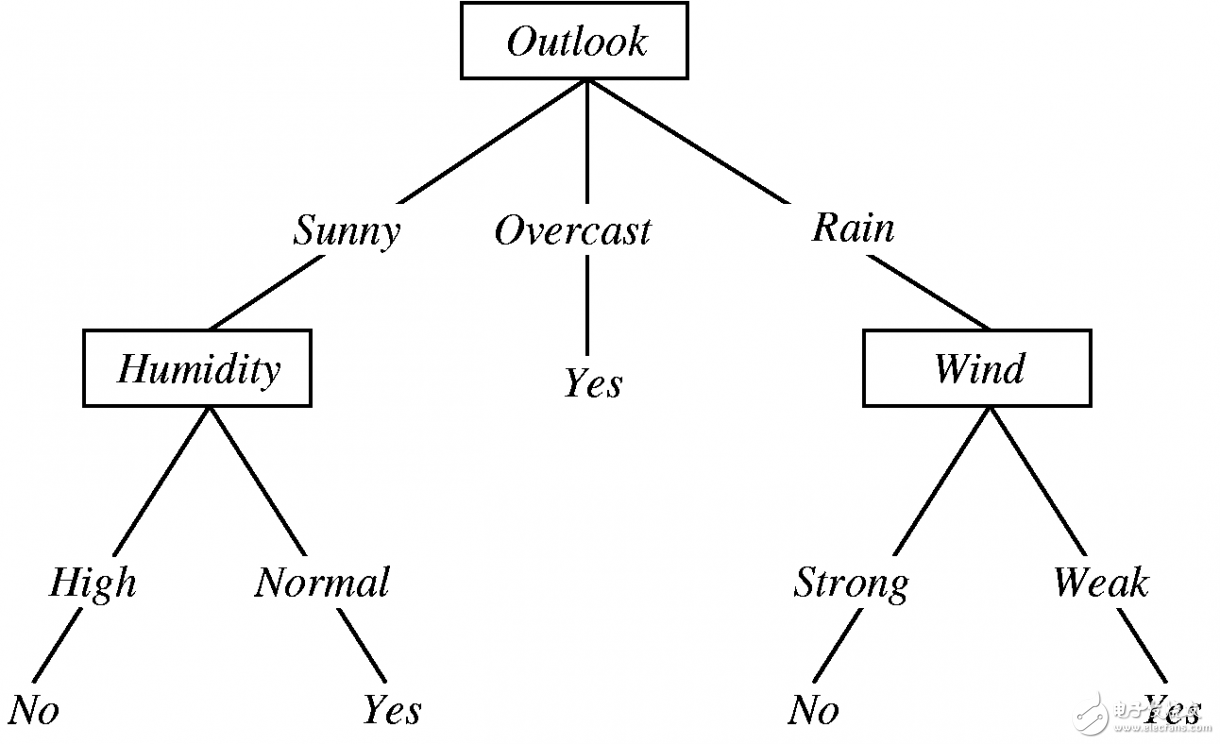
圖2-3 通過決策樹判斷今天是否適合打球
決策樹的表現(xiàn)形式和if-else類似,只是在通過數(shù)據(jù)生成決策樹的時候,需要用到信息增益去決定最先使用那個屬性去做劃分。決策樹的好處是表現(xiàn)力強,容易讓人理解結(jié)論是如何得到的。
2.4 樸素貝葉斯分類器
樸素貝葉斯法師基于貝葉斯定理與特征條件獨立性假設(shè)的分類方法。由訓(xùn)練數(shù)據(jù)學(xué)習(xí)聯(lián)合概率分布,然后求得后驗概率分布。(抱歉,沒圖,又不貼公式,就這樣吧-_-)
2.5 線性回歸
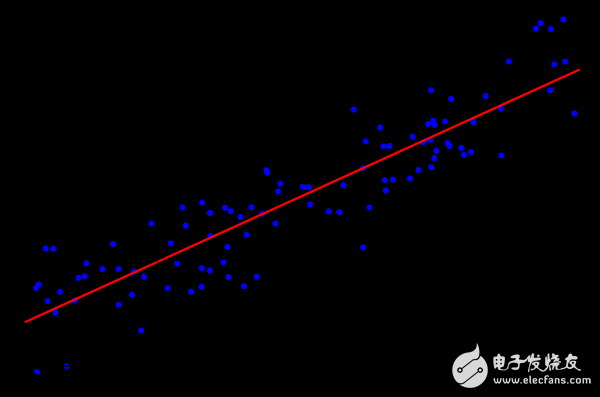
圖2-4 擬一條直線,與所有數(shù)據(jù)點實際值之差的和最小
就是對函數(shù)f(x)=ax+b,通過代入已有數(shù)據(jù)(x,y),找到最合適的參數(shù)a和b,使函數(shù)最能表達(dá)已有數(shù)據(jù)輸入和輸出之間的映射關(guān)系,從而預(yù)測未來輸入對應(yīng)的輸出。
2.6 邏輯回歸
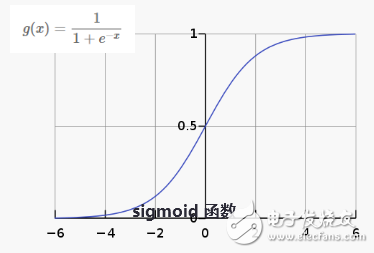
圖2-5 邏輯函數(shù)
邏輯回歸模型其實只是在上述的線性回歸的基礎(chǔ)上,套用了一個邏輯函數(shù),將線性回歸的輸出通過邏輯函數(shù)轉(zhuǎn)化成0到1之間的數(shù)值,便于表示屬于某一類的概率。
2.7 隱馬爾科夫模型
圖2-6 隱藏狀態(tài)x之間的轉(zhuǎn)移概率以及狀態(tài)x的觀測為y的概率圖
隱馬爾科夫模型是關(guān)于時序的概率模型,描述由一個隱藏的馬爾科夫鏈隨機生成不可觀測的狀態(tài)的序列,再由各個狀態(tài)隨機生成一個觀測而產(chǎn)生觀測的序列的過程。隱馬爾科夫模型有三要素和三個基本問題,有興趣的可以單獨去了解。最近看了一篇有意思的論文,其中使用了隱馬爾可夫模型去預(yù)測美國研究生會在哪個階段轉(zhuǎn)專業(yè),以此做出對策挽留某專業(yè)的學(xué)生。公司的人力資源會不會也是通過這個模型來預(yù)測員工會在哪個階段會跳槽,從而提前實施挽留員工的必要措施?(^_^)
2.8 支持向量
圖2-7支持向量對最大間隔的支持
支持向量機是一種二分類模型,它的基本模型是定義在特征空間上的間隔最大的線性分類器。如圖2-7所示,由于支持向量在確定分離超平面中起著關(guān)鍵性的作用,所以將這種分類模型稱為支持向量機。
對于輸入空間中的非線性分類問題,可以通過非線性變換(核函數(shù))將它轉(zhuǎn)換為某個高維特征空間中的線性分類問題,在高維特征空間中學(xué)習(xí)線性支持向量機。如圖2-8所示,訓(xùn)練點被映射到可以容易地找到分離超平面的三維空間。
圖2-8將二維線性不可分轉(zhuǎn)換為三維線性可分
3 深度學(xué)習(xí)簡介
這里將簡單介紹神經(jīng)網(wǎng)絡(luò)的由來。介紹順序為:感知機、多層感知機(神經(jīng)網(wǎng)絡(luò))、卷積神經(jīng)網(wǎng)絡(luò)及循環(huán)神經(jīng)網(wǎng)絡(luò)。
3.1 感知機
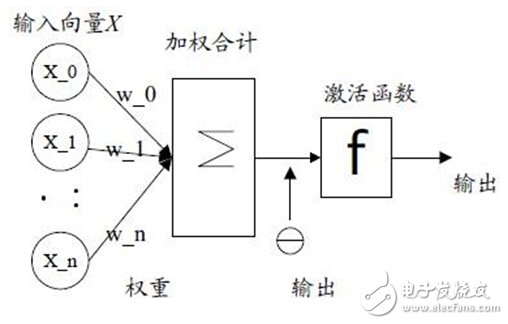
圖3-1輸入向量通過加權(quán)求和后代入激活函數(shù)中求取結(jié)果
神經(jīng)網(wǎng)絡(luò)起源于上世紀(jì)五、六十年代,當(dāng)時叫感知機,擁有輸入層、輸出層和一個隱含層。它的缺點是無法表現(xiàn)稍微復(fù)雜一些的函數(shù),所以就有了以下要介紹的多層感知機。
3.2 多層感知機
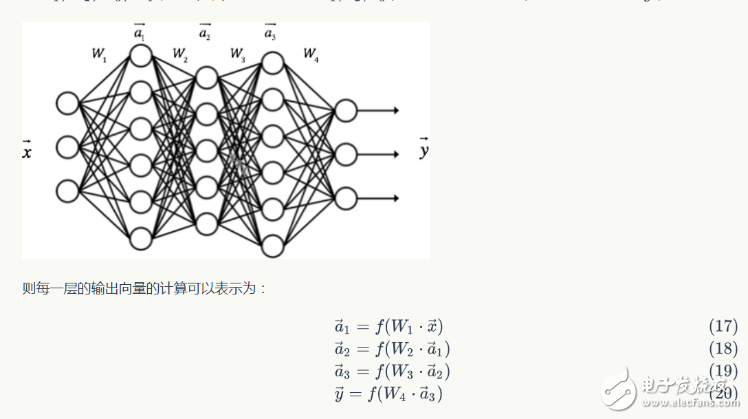
圖3-2多層感知機,表現(xiàn)為輸入與輸出間具有多個的隱含層
在感知機的基礎(chǔ)上,添加了多個隱含層,以滿足能表現(xiàn)更復(fù)雜的函數(shù)的能力,其稱之為多層感知機。為了逼格,取名為神經(jīng)網(wǎng)絡(luò)。神經(jīng)網(wǎng)絡(luò)的層數(shù)越多,表現(xiàn)能力越強,但是隨之而來的是會導(dǎo)致BP反向傳播時的梯度消失現(xiàn)象。
3.3 卷積神經(jīng)網(wǎng)絡(luò)
圖3-3卷積神經(jīng)網(wǎng)絡(luò)的一般形式
全連接的神經(jīng)網(wǎng)絡(luò)由于中間隱含層多,導(dǎo)致參數(shù)數(shù)量膨脹,并且全連接方式?jīng)]有利用到局部模式(例如圖片里面臨近的像素是有關(guān)聯(lián)的,可構(gòu)成像眼睛這樣更抽象的特征),所以出現(xiàn)了卷積神經(jīng)網(wǎng)絡(luò)。卷積神經(jīng)網(wǎng)絡(luò)限制了參數(shù)個數(shù)并且挖掘了局部結(jié)構(gòu)這個特點,特別適用于圖像識別。
3.4 循環(huán)神經(jīng)網(wǎng)絡(luò)
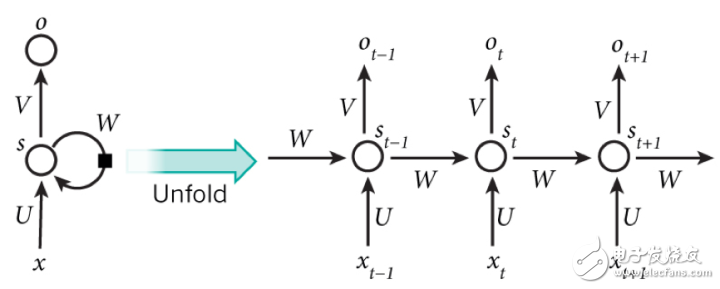
圖3-4 循環(huán)神經(jīng)網(wǎng)絡(luò)可以看成一個在時間上傳遞的神經(jīng)網(wǎng)絡(luò)
循環(huán)神經(jīng)網(wǎng)絡(luò)可以看成一個在時間上傳遞的神經(jīng)網(wǎng)絡(luò),它的深度是時間的長度,神經(jīng)元的輸出可以作用于下一個樣本的處理。普通的全連接神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)對樣本的處理是獨立的,而循環(huán)神經(jīng)網(wǎng)絡(luò)則可以應(yīng)對需要學(xué)習(xí)有時間順序的樣本的任務(wù),比如像自然語言處理和語言識別等。
4 個人小結(jié)
機器學(xué)習(xí)其實是學(xué)習(xí)從輸入到輸出的映射:
即希望通過大量的數(shù)據(jù)把數(shù)據(jù)中的規(guī)律給找出來。(在無監(jiān)督學(xué)習(xí)中,主要任務(wù)是找到數(shù)據(jù)本身的規(guī)律而不是映射)
總結(jié)一般的機器學(xué)習(xí)做法是:根據(jù)算法的適用場景,挑選適合的算法模型,確定目標(biāo)函數(shù),選擇合適的優(yōu)化算法,通過迭代逼近最優(yōu)值,從而確定模型的參數(shù)。
關(guān)于未來的展望,有人說強化學(xué)習(xí)才是真正的人工智能的希望,希望能進(jìn)一步學(xué)習(xí)強化學(xué)習(xí),并且要再加深對深度學(xué)習(xí)的理解,才可以讀懂深度強化學(xué)習(xí)的文章。
最后最后,由于本人也只是抽空自學(xué)了幾個月的小白,所以文中有錯誤的地方,希望海涵和指正,我會立即修改,希望不會誤導(dǎo)到別人。










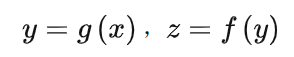







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論