 電子發燒友App
電子發燒友App


師姐1個月攻下LLM的所有知識的捷徑
How do Large Language Models Handle Multilingualism?

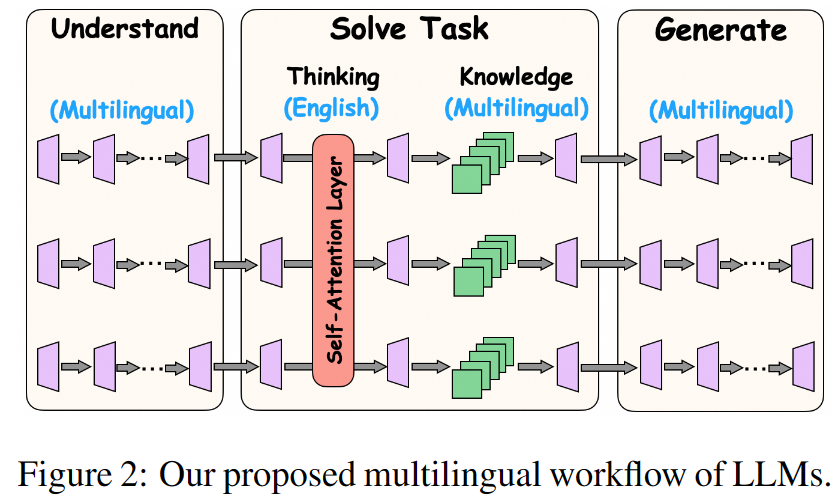
摘要:大語言模型(LLM)在各種語言中都表現出了卓越的性能。在這項工作中,我們將深入探討以下問題:大語言模型如何處理多語言問題?我們引入了一個框架,描述 LLMs 處理多語言輸入的過程:在前幾層,LLMs 理解問題,將多語言輸入轉換為英語,以幫助任務解決階段。在中間層,語言學習者分別利用自我注意結構和前饋結構,通過用英語思考和結合多語言知識來獲取事實內容,從而參與問題解決。在最后幾層,LLMs 生成與query的語言一致的回復。 此外,我們還研究了在處理某種語言時是否存在特定語言神經元。為了檢測由輸入語言激活的神經元(即使沒有標簽),我們創新性地設計了并行語言特異性神經元檢測 PLND 方法,該方法能有效量化不同神經元在處理多語言輸入時的重要性。通過deactivate不同層和結構的神經元進行綜合消融分析,我們驗證了我們提出的框架。此外,我們還證明了利用這種框架可以在無需大量訓練的情況下有效提高模型多語言能力。
https://arxiv.org/abs/2402.18815
Q1: 這篇論文試圖解決什么問題?
A:這篇論文探討了大語言模型(LLMs)如何處理多語言輸入的問題。具體來說,研究者們提出了一個框架來描述LLMs在處理多語言輸入時的內部處理過程,并探討了模型中是否存在特定于語言的神經元。為了驗證這一框架,研究者們設計了一種名為并行語言特定神經元檢測(PLND)的方法,用于檢測在處理特定語言輸入時被激活的神經元。此外,論文還研究了通過微調這些語言特定神經元來增強LLMs的多語言能力的可能性。

Q2: 有哪些相關研究?
A:論文中提到了以下幾類相關研究:
多語言能力研究: 一些研究專注于探索語言模型的多語言能力,包括跨語言性能和語言之間的結構共性。
模型架構與能力關系研究:為了理解特定能力與模型架構(尤其是主導的Transformer架構)之間的關系,一些研究探索了LLMs的自注意力層的推理能力。
前饋層研究:其他研究關注前饋層,將其視為存儲事實知識的鍵值記憶。
可解釋性研究:傳統的可解釋性研究調查輸入特征與其相應輸出的重要性。在LLMs時代,一些研究致力于理解知識存儲,例如研究前饋層作為知識庫。
多語言處理研究:包括構建基準測試、通過翻譯提升性能、對齊表示、提示等方法的研究,這些工作強調了使LLMs在多種語言中有效運行的重要性和復雜性。
Q3: 論文如何解決這個問題?
A:論文通過以下步驟來解決大型語言模型(LLMs)如何處理多語言輸入的問題:
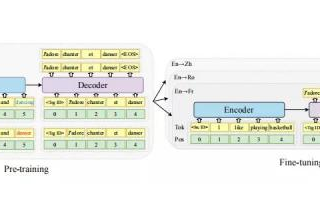
提出處理框架:研究者們提出了一個框架來描述LLMs在處理多語言輸入時的內部處理過程。這個框架包括以下幾個階段:
在前幾層,LLMs將多語言輸入轉換為英語,以便于任務解決階段。
在中間層,LLMs通過英語思考并結合多語言知識來解決問題,分別利用自注意力和前饋結構。
在最后幾層,LLMs生成與查詢原始語言相一致的響應。
設計PLND方法:為了檢測在處理特定語言時被激活的神經元,研究者們創新性地設計了并行語言特定神經元檢測(PLND)方法。這種方法可以在沒有標簽的情況下有效地衡量神經元在處理多語言輸入時的重要性。
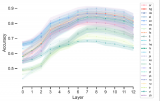
進行消融分析:通過選擇性地關閉不同層和結構中的神經元組,研究者們進行了全面的消融分析來驗證他們提出的框架。這包括在理解、任務解決和生成階段分別關閉語言特定神經元,并觀察對模型性能的影響。
增強多語言能力:研究者們展示了如何通過微調語言特定神經元來有效提升LLMs的多語言能力,即使用較少的訓練數據。這通過在特定語言的文本語料庫上進行微調來實現,從而提高了模型在多語言任務上的表現。
實驗驗證:研究者們通過實驗驗證了他們的假設,包括在不同的多語言任務(如推理、自然語言理解、知識問答和自然語言生成)上進行實驗,并觀察關閉語言特定神經元對模型性能的影響。
Q4: 論文做了哪些實驗?
A:論文中進行了一系列的實驗來驗證提出的框架和PLND方法,具體包括:
PLND方法驗證:通過PLND方法,研究者們檢測了在處理特定語言輸入時被激活的神經元。他們通過向模型輸入特定語言的文本語料庫,并觀察哪些神經元在響應中持續激活,從而識別出語言特定的神經元。
消融分析:研究者們通過選擇性地關閉不同層和結構中的神經元組,觀察這些操作對LLMs在多語言任務上的性能影響。這包括:
在理解層關閉語言特定神經元。
在任務解決層關閉語言特定神經元。
在生成層關閉語言特定神經元。
多語言任務性能測試:研究者們在多種多語言任務上測試了LLMs的性能,包括:
推理任務(MGSM)。
自然語言理解(NLU)任務(XQuAD)。
自然語言生成(NLG)任務(XLSum)。
知識問答任務(X-CSQA)。
多語言能力增強:研究者們通過微調語言特定神經元來增強LLMs的多語言能力。他們使用特定語言的文本語料庫進行微調,并評估了微調前后模型在多語言任務上的性能提升。
不同多語言LLMs的分析:研究者們還分析了其他類型的多語言LLMs,如BLOOMZ(一個支持46種語言的超多語言LLM)和Chinese Llama(一個專注于英語和中文的雙語LLM),以驗證提出的框架的普適性。
Q5: 有什么可以進一步探索的點?
A:盡管論文提出了一個關于LLMs處理多語言輸入的框架,并進行了一系列的實驗驗證,但仍有一些領域可以進一步探索:
更深入的神經網絡解釋:研究LLMs內部的更深層次機制,例如如何精確地在不同語言之間轉換和編碼信息,以及不同層之間是如何協同工作的。
跨語言知識遷移:探索LLMs如何在不同語言之間遷移和共享知識,以及這種遷移對模型性能的影響。
多語言數據集的構建:開發更大規模和更多樣化的多語言數據集,以便更好地訓練和評估LLMs的多語言能力。
多任務學習:研究LLMs在執行多種語言任務時的表現,以及如何優化模型以提高跨任務的泛化能力。
語言特定神經元的功能:深入研究語言特定神經元在模型中的具體作用,以及它們如何影響模型對特定語言的理解和生成能力。
模型壓縮和優化:研究如何通過減少模型大小和計算需求來保持或提高多語言性能,這對于資源受限的環境尤為重要。
跨語言評估指標:開發和標準化跨語言評估指標,以便更公平地比較不同模型在多語言任務上的性能。
多語言模型的可解釋性:提高LLMs的可解釋性,以便更好地理解模型是如何做出決策的,特別是在處理多語言輸入時。
多語言模型的倫理和社會影響:研究LLMs在多語言環境中可能產生的偏見和歧視問題,以及如何設計更公平、更包容的多語言模型。
實際應用場景:將LLMs應用于實際的多語言場景,如跨語言對話系統、翻譯服務和多語言教育工具,以評估和改進模型在現實世界中的有效性。
Q6: 總結一下論文的主要內容?
A:這篇論文的主要內容包括:
問題提出:探討大型語言模型(LLMs)如何處理多語言輸入的問題,特別是在理解和生成文本時的語言轉換機制。
處理框架:提出了一個處理多語言輸入的框架,描述了LLMs在不同層級上如何將非英語輸入轉換為英語,利用英語進行問題解決,并最終生成與原始查詢語言相一致的響應。
PLND方法:創新性地設計了并行語言特定神經元檢測(PLND)方法,用于檢測在處理特定語言輸入時被激活的神經元,即使在沒有明確標簽的情況下。
消融分析:通過關閉不同層和結構中的神經元組,進行了全面的消融分析,以驗證提出的處理框架。實驗結果表明,關閉語言特定神經元會顯著影響LLMs在非英語任務上的性能。
多語言能力增強:展示了如何通過微調語言特定神經元來提升LLMs的多語言能力,即使在訓練數據較少的情況下也能有效提高模型性能。
實驗驗證:在多個多語言任務上進行了實驗,包括推理、自然語言理解、知識問答和自然語言生成任務,以驗證模型在處理多語言輸入時的表現。
進一步探索:提出了未來研究方向,包括更深入的神經網絡解釋、跨語言知識遷移、多語言數據集構建、多任務學習、模型壓縮和優化等。
結論:論文得出結論,LLMs通過將查詢翻譯成英語、使用英語進行思考和解決問題,然后再將響應翻譯回原始語言來處理多語言輸入。同時,通過微調語言特定神經元,可以有效地提升模型的多語言處理能力。
審核編輯:黃飛
?




















 工商網監
工商網監
評論