 電子發(fā)燒友App
電子發(fā)燒友App


作者:Xnhyacinth
近年來(lái),大型語(yǔ)言模型(LLMs)在自然語(yǔ)言處理領(lǐng)域取得了顯著的進(jìn)展,如GPT-series(GPT-3, GPT-4)、Google-series(Gemini, PaLM), Meta-series(LLAMA1&2), BLOOM, GLM等模型在各種任務(wù)中展現(xiàn)出驚人的能力。然而,隨著模型規(guī)模的不斷增大和參數(shù)數(shù)量的劇增,這些模型的成功往往伴隨著巨大的計(jì)算和存儲(chǔ)資源消耗,給其訓(xùn)練和推理帶來(lái)了巨大挑戰(zhàn),也在很大程度上限制了它們的廣泛應(yīng)用。因此,研究如何提高LLMs的效率和資源利用,使其在保持高性能的同時(shí)降低資源需求,成為了當(dāng)前領(lǐng)域的熱點(diǎn)問(wèn)題。
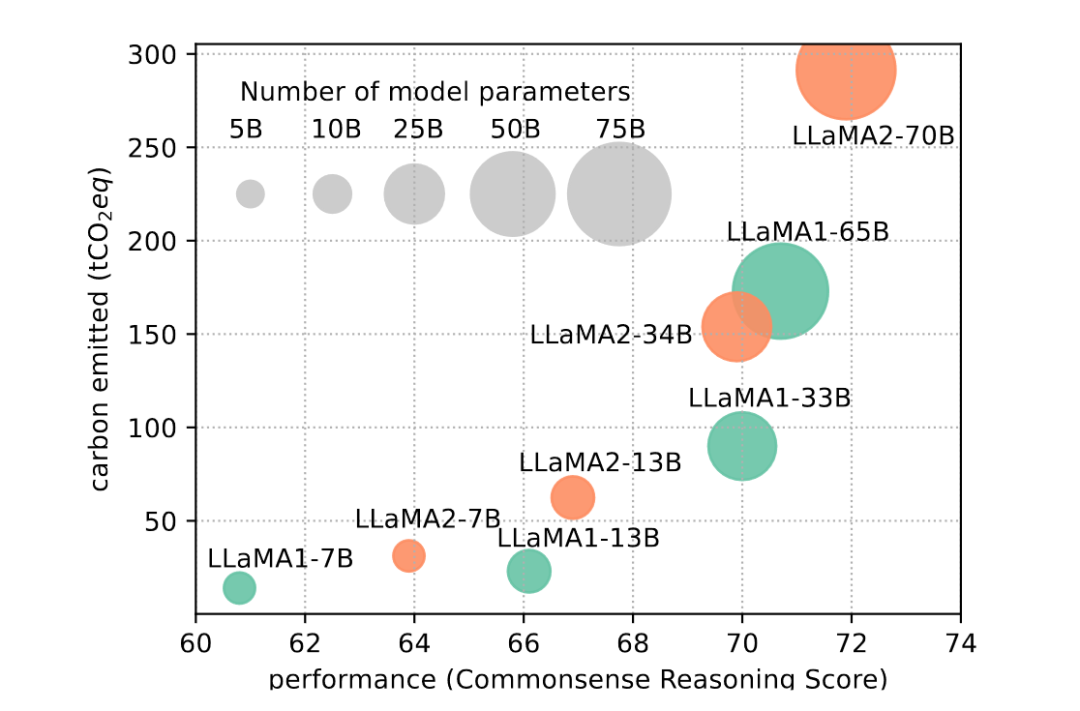
今天這篇工作是一篇survey,旨在全面調(diào)查和總結(jié)提高LLMs效率的最新研究進(jìn)展。工作首先概述了LLMs面臨的挑戰(zhàn),隨著模型規(guī)模的增大,傳統(tǒng)的訓(xùn)練方法難以適應(yīng)龐大的模型參數(shù)和計(jì)算資源需求。接下來(lái),詳細(xì)介紹了從模型為中心、數(shù)據(jù)為中心和框架為中心三個(gè)角度出發(fā)的一系列高效技術(shù)。這些技術(shù)涵蓋了量化、參數(shù)修剪、低秩逼近、知識(shí)蒸餾等模型壓縮方法,推理加速、混合專家訓(xùn)練等高效結(jié)構(gòu)以及數(shù)據(jù)選擇、提示工程等數(shù)據(jù)為中心策略。最后,討論了支持高效訓(xùn)練和推理的LLM框架,為實(shí)際應(yīng)用提供了有力支持。
該工作的目的是為研究人員和從業(yè)者提供一個(gè)關(guān)于高效LLMs技術(shù)的全面了解,以期激發(fā)更多關(guān)于這一重要領(lǐng)域的研究和創(chuàng)新。在這個(gè)信息爆炸的時(shí)代,提高LLMs的效率對(duì)于推動(dòng)自然語(yǔ)言處理技術(shù)的發(fā)展具有重大意義,同時(shí)也將為人工智能的廣泛應(yīng)用奠定堅(jiān)實(shí)基礎(chǔ)。接下來(lái)就讓我們一起探索高效的大型語(yǔ)言模型!
下面將從以模型為中心,包括模型壓縮,高效預(yù)訓(xùn)練,高效微調(diào),高效推理,高效結(jié)構(gòu)設(shè)計(jì)五個(gè)部分;以數(shù)據(jù)為中心,包括數(shù)據(jù)選擇,提示工程兩個(gè)部分;以框架為中心介紹該篇工作。
模型為中心
模型壓縮
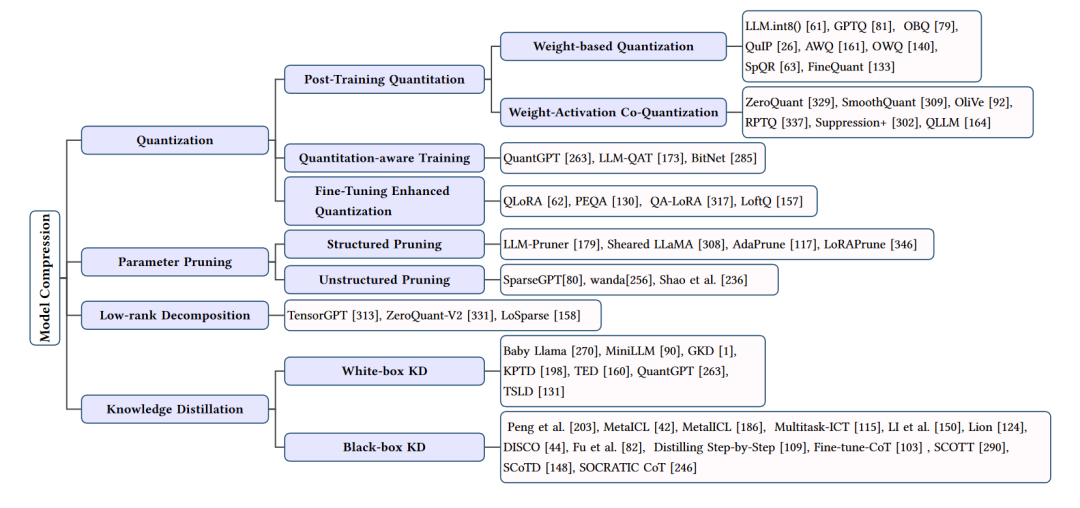
模型壓縮方法的總結(jié)
模型壓縮部分主要關(guān)注于減少大型語(yǔ)言模型(LLMs)的計(jì)算和存儲(chǔ)需求,同時(shí)盡量保持其性能。這部分的技術(shù)主要包括量化、參數(shù)修剪、低秩逼近和知識(shí)蒸餾等方法。下面我們將詳細(xì)介紹這些技術(shù)。
量化
量化是一種通過(guò)減少模型權(quán)重和激活的位寬來(lái)壓縮模型的技術(shù)。常見(jiàn)的量化方法包括權(quán)重量化、激活量化和權(quán)重-激活共量化。量化可以降低計(jì)算和存儲(chǔ)需求,但可能會(huì)帶來(lái)一定的性能損失。為了解決這個(gè)問(wèn)題,研究者們提出了多種量化技術(shù),如動(dòng)態(tài)范圍量化(DRQ)、知識(shí)蒸餾量化(KDQ)等,它們?cè)诒3帜P托阅艿耐瑫r(shí)實(shí)現(xiàn)了高效的壓縮。
參數(shù)修剪
參數(shù)修剪是一種通過(guò)移除模型中不重要的參數(shù)來(lái)減小模型大小的方法。參數(shù)修剪可以分為結(jié)構(gòu)化修剪和非結(jié)構(gòu)化修剪。結(jié)構(gòu)化修剪關(guān)注于移除模型中的整個(gè)子結(jié)構(gòu),如行、列或子塊;非結(jié)構(gòu)化修剪則關(guān)注于移除單個(gè)參數(shù)。參數(shù)修剪可以在一定程度上降低模型復(fù)雜度,但過(guò)度修剪可能導(dǎo)致性能下降。為了解決這個(gè)問(wèn)題,研究者們提出了一些策略,如基于敏感度的修剪、低秩分解修剪等,以實(shí)現(xiàn)性能和壓縮之間的平衡。
低秩逼近
低秩逼近通過(guò)將模型權(quán)重矩陣近似表示為低秩矩陣來(lái)減小模型大小。這種方法可以顯著降低模型的計(jì)算和存儲(chǔ)需求。常見(jiàn)的低秩逼近技術(shù)包括矩陣分解、核方法和秩限制等。為了保持模型性能,研究者們還提出了一些優(yōu)化策略,如迭代訓(xùn)練、低秩補(bǔ)償?shù)取?/p>
知識(shí)蒸餾
知識(shí)蒸餾是一種通過(guò)訓(xùn)練一個(gè)較小的學(xué)生模型來(lái)模仿大型教師模型的行為,從而實(shí)現(xiàn)模型壓縮的方法。知識(shí)蒸餾可以分為白盒知識(shí)蒸餾和黑盒知識(shí)蒸餾。白盒知識(shí)蒸餾利用教師模型的內(nèi)部信息進(jìn)行訓(xùn)練,而黑盒知識(shí)蒸餾僅依賴于教師模型的輸入輸出。為了提高蒸餾效果,研究者們提出了一些改進(jìn)策略,如多任務(wù)學(xué)習(xí)、多階段訓(xùn)練等。
模型壓縮技術(shù)通過(guò)各種方法降低大型語(yǔ)言模型的計(jì)算和存儲(chǔ)需求,使其在實(shí)際應(yīng)用中更具可行性。然而,這些技術(shù)在壓縮模型的同時(shí)也需要權(quán)衡性能損失。未來(lái)的研究將繼續(xù)探索更高效、更精確的模型壓縮方法,以實(shí)現(xiàn)性能與壓縮之間的最佳平衡。
高效預(yù)訓(xùn)練
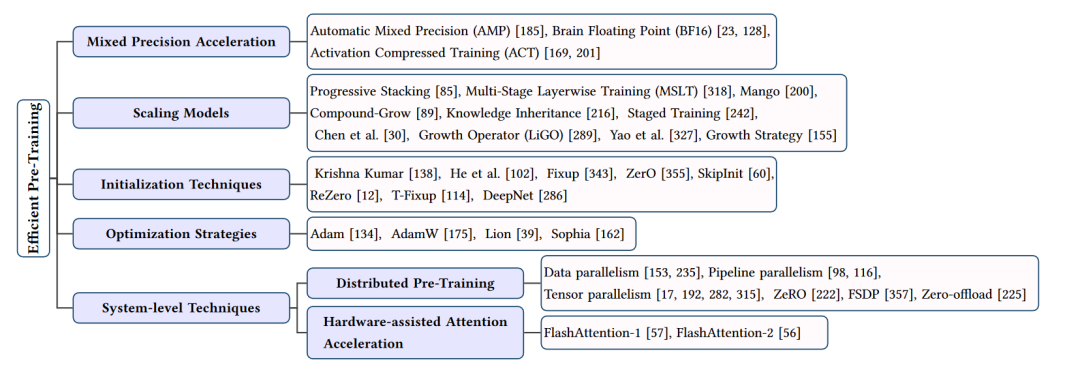
高效預(yù)訓(xùn)練技術(shù)的總結(jié)
在大型語(yǔ)言模型(LLMs)的研究中,預(yù)訓(xùn)練是一個(gè)至關(guān)重要的步驟,它為模型提供了豐富的知識(shí)和表示能力。然而,預(yù)訓(xùn)練過(guò)程通常需要大量的計(jì)算資源和時(shí)間,這對(duì)于許多研究者和從業(yè)者來(lái)說(shuō)是一個(gè)巨大的挑戰(zhàn)。因此,研究者們提出了許多高效預(yù)訓(xùn)練技術(shù),以降低預(yù)訓(xùn)練的成本和復(fù)雜性。下面將從四個(gè)方面介紹這些技術(shù):混合精度加速、模型縮放、初始化技術(shù)和優(yōu)化策略。
混合精度加速
混合精度加速是一種利用低精度數(shù)據(jù)類型(如16位或32位浮點(diǎn)數(shù))進(jìn)行計(jì)算,同時(shí)保持模型的高性能的方法。這種技術(shù)通過(guò)減少數(shù)據(jù)類型的位寬來(lái)降低計(jì)算和存儲(chǔ)需求,從而提高預(yù)訓(xùn)練效率。常見(jiàn)的混合精度加速方法包括自動(dòng)混合精度(AMP)、BF16等。這些方法在保持模型性能的同時(shí),顯著降低了預(yù)訓(xùn)練過(guò)程中的計(jì)算和內(nèi)存開(kāi)銷。
模型縮放
模型縮放技術(shù)通過(guò)利用較小模型的信息來(lái)指導(dǎo)較大模型的預(yù)訓(xùn)練,從而提高預(yù)訓(xùn)練效率。這些方法包括漸進(jìn)式堆疊、多階段層訓(xùn)練(MSLT)、復(fù)合增長(zhǎng)等。它們通過(guò)在預(yù)訓(xùn)練過(guò)程中逐步增加模型的規(guī)模、深度和寬度,實(shí)現(xiàn)了更快的收斂速度和更高的性能。此外,一些研究還利用知識(shí)繼承等技術(shù),通過(guò)教師模型的知識(shí)來(lái)加速學(xué)生模型的預(yù)訓(xùn)練。
初始化技術(shù)
合適的初始化方法對(duì)于預(yù)訓(xùn)練過(guò)程的收斂速度和模型性能至關(guān)重要。一些研究者提出了特定的初始化技術(shù),如函數(shù)保留初始化(FPI)和高級(jí)知識(shí)初始化(AKI),以提高大型模型預(yù)訓(xùn)練的效率。這些方法通過(guò)在預(yù)訓(xùn)練初期為大型模型提供良好的初始狀態(tài),有助于加快收斂速度并提高最終性能。
優(yōu)化策略
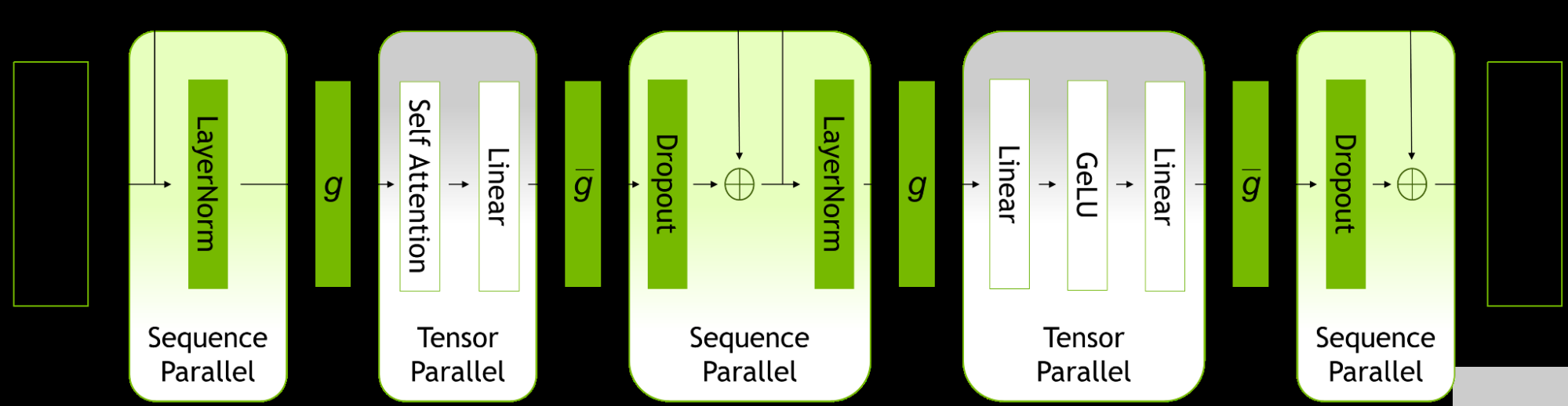
優(yōu)化策略在預(yù)訓(xùn)練過(guò)程中起到了關(guān)鍵作用。一些研究者提出了新的優(yōu)化器,如Lion和Sophia,以提高預(yù)訓(xùn)練效率。這些優(yōu)化器通過(guò)調(diào)整學(xué)習(xí)率、動(dòng)量等超參數(shù),以及引入第二階信息,實(shí)現(xiàn)了更快的收斂速度和更高的內(nèi)存利用率。此外,一些研究還探討了分布式預(yù)訓(xùn)練技術(shù),如數(shù)據(jù)并行、流水線并行和張量并行等,以利用多設(shè)備并行計(jì)算來(lái)加速預(yù)訓(xùn)練過(guò)程。
高效預(yù)訓(xùn)練技術(shù)通過(guò)混合精度加速、模型縮放、初始化技術(shù)和優(yōu)化策略等方法,顯著降低了大型語(yǔ)言模型預(yù)訓(xùn)練過(guò)程中的計(jì)算和時(shí)間成本。這些技術(shù)為L(zhǎng)LMs的研究和應(yīng)用提供了有力支持,有助于推動(dòng)自然語(yǔ)言處理領(lǐng)域的發(fā)展。然而,這些技術(shù)仍然存在一定的局限性,未來(lái)的研究應(yīng)該繼續(xù)探索更高效、更實(shí)用的預(yù)訓(xùn)練方法。
高效微調(diào)
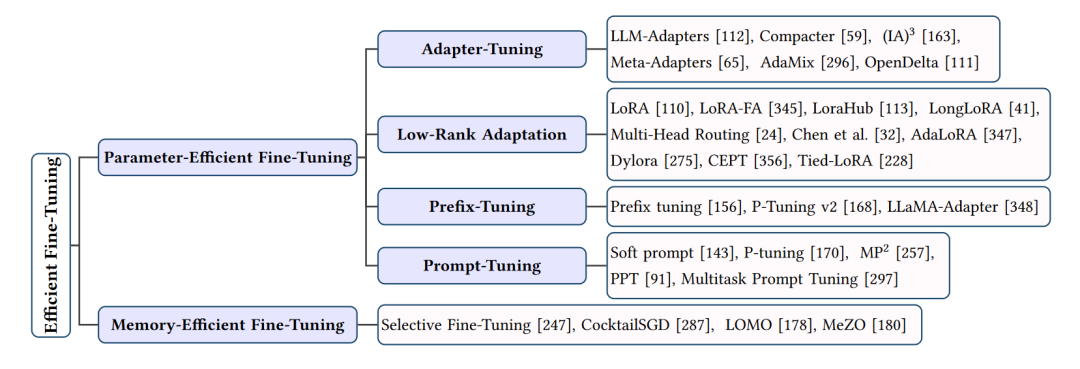
高效微調(diào)方法的總結(jié)
在大型語(yǔ)言模型(LLMs)的應(yīng)用中,微調(diào)是一個(gè)關(guān)鍵步驟,它使模型能夠適應(yīng)特定的任務(wù)和領(lǐng)域。然而,微調(diào)過(guò)程可能會(huì)消耗大量計(jì)算資源和時(shí)間。為了提高微調(diào)效率,研究者們提出了許多高效微調(diào)方法。接下來(lái)將從兩個(gè)方面介紹這些技術(shù):參數(shù)高效微調(diào)和內(nèi)存高效微調(diào)。
參數(shù)高效微調(diào)
參數(shù)高效微調(diào)方法旨在通過(guò)減少模型參數(shù)的更新來(lái)提高微調(diào)效率。這些方法主要包括適配器調(diào)優(yōu)、低秩適應(yīng)和前綴調(diào)優(yōu)等。
1.1 適配器調(diào)優(yōu)(Adapter-Tuning)
適配器調(diào)優(yōu)是一種將適配器模塊集成到LLMs中的方法,這些適配器模塊可以在微調(diào)過(guò)程中更新,而模型的其他部分保持不變。適配器可以是串聯(lián)適配器,每個(gè)LLM層都添加一個(gè)適配器模塊;也可以是并聯(lián)適配器,每個(gè)適配器模塊與LLM層并行。適配器調(diào)優(yōu)的典型技術(shù)包括LLM-Adapters、Compacter、(IA)3、Meta-Adapters等。
1.2 低秩適應(yīng)(Low-Rank Adaptation)
低秩適應(yīng)(LoRA)是一種通過(guò)引入兩個(gè)低秩矩陣來(lái)更新模型參數(shù)的方法。在微調(diào)過(guò)程中,原始模型參數(shù)保持不變,而是更新這兩個(gè)低秩矩陣。LoRA及其變體(如LoRA-FA、LongLoRA等)在保持較高性能的同時(shí),顯著降低了微調(diào)過(guò)程中的計(jì)算和內(nèi)存需求。
1.3 前綴調(diào)優(yōu)(Prefix-Tuning)
前綴調(diào)優(yōu)在LLMs的每一層添加一系列可訓(xùn)練的前綴令牌,這些令牌針對(duì)特定任務(wù)進(jìn)行定制。前綴調(diào)優(yōu)的典型技術(shù)包括Prefix Tuning、P-Tuning v2和LLaMA-Adapter。通過(guò)使用前綴令牌,這些方法可以在微調(diào)過(guò)程中實(shí)現(xiàn)參數(shù)效率和性能提升。
內(nèi)存高效微調(diào)
內(nèi)存高效微調(diào)方法關(guān)注于降低微調(diào)過(guò)程中的內(nèi)存消耗。這些方法主要包括選擇性微調(diào)和分階段微調(diào)等。
2.1 選擇性微調(diào)
選擇性微調(diào)通過(guò)僅更新模型的部分中間激活來(lái)降低內(nèi)存需求。典型的選擇性微調(diào)技術(shù)包括Selective Fine-Tuning、CocktailSGD和LOMO。這些方法在保持較高性能的同時(shí),顯著降低了微調(diào)過(guò)程中的內(nèi)存消耗。
2.2 分階段微調(diào)
分階段微調(diào)將微調(diào)過(guò)程分為多個(gè)階段,每個(gè)階段僅更新部分模型參數(shù)。這種方法可以降低內(nèi)存需求,同時(shí)保持模型性能。典型的分階段微調(diào)技術(shù)包括Staged Training和MeZO。
高效微調(diào)方法通過(guò)參數(shù)高效微調(diào)和內(nèi)存高效微調(diào)等技術(shù),顯著降低了大型語(yǔ)言模型在微調(diào)過(guò)程中的計(jì)算、時(shí)間和內(nèi)存成本。
高效推理
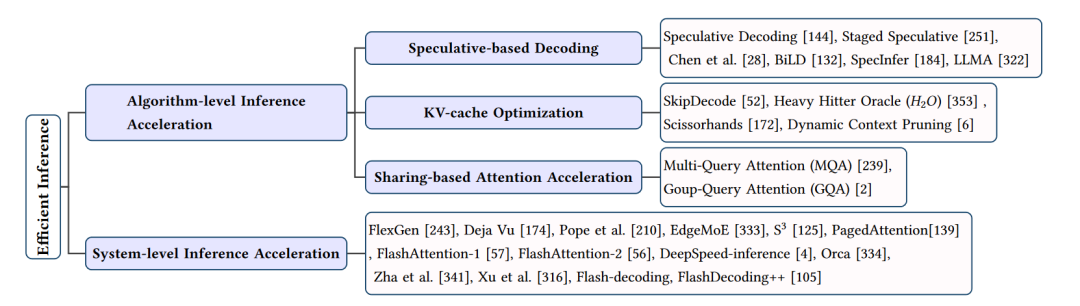
高效推理技巧的總結(jié)
在大型語(yǔ)言模型(LLMs)的應(yīng)用中,高效的推理技巧對(duì)于實(shí)現(xiàn)實(shí)時(shí)響應(yīng)和降低計(jì)算成本至關(guān)重要。接下來(lái)將從算法層面和系統(tǒng)層面兩個(gè)方面介紹高效推理技巧。
一、算法層面的高效推理技巧
投機(jī)解碼
投機(jī)解碼(Speculative Decoding)是一種在解碼過(guò)程中采用多個(gè)候選模型并行計(jì)算的技術(shù)。通過(guò)使用較小的草稿模型創(chuàng)建投機(jī)前綴,然后評(píng)估這些前綴與大型目標(biāo)模型的初步輸出,可以加速解碼過(guò)程。典型的投機(jī)解碼方法包括Chen等人提出的快速自回歸模型(Faster Autoregressive Model) 和BiLD,它們分別采用不同的策略來(lái)提高投機(jī)解碼的性能。
KV-Cache優(yōu)化
KV-Cache優(yōu)化旨在減少LLMs推理過(guò)程中Key-Value(KV)緩存的計(jì)算和存儲(chǔ)開(kāi)銷。一些方法如SkipDecode和Heavy Hitter Oracle(A^2A)通過(guò)跳過(guò)較低層和中間層的計(jì)算來(lái)加速推理過(guò)程。而Dynamic Context Pruning和Scissorhands則利用可學(xué)習(xí)機(jī)制來(lái)識(shí)別和移除非信息性的KV-Cache tokens,從而提高計(jì)算效率和模型可解釋性。
分享式注意力加速
分享式注意力加速通過(guò)不同KV頭共享方案來(lái)加速注意力計(jì)算。例如,多查詢注意力(MQA)和分組查詢注意力(GQA) 分別共享一組KV或多個(gè)KV頭的線性變換,從而減少計(jì)算復(fù)雜度。這些方法在保持較高性能的同時(shí),顯著降低了計(jì)算和內(nèi)存需求。
二、系統(tǒng)層面的高效推理技巧
FlexGen
FlexGen是一個(gè)針對(duì)內(nèi)存受限GPU的高吞吐量推理引擎。通過(guò)集成CPU、GPU和磁盤(pán)的計(jì)算資源,以及采用線性編程搜索策略來(lái)管理硬件組件,F(xiàn)lexGen能夠在有限的硬件資源下實(shí)現(xiàn)高效的LLM推理。
Deja Vu
Deja Vu定義了一種上下文稀疏性概念,并利用預(yù)測(cè)器預(yù)測(cè)這種稀疏性。通過(guò)使用內(nèi)核融合、內(nèi)存合并等技術(shù),Deja Vu能夠在推理過(guò)程中實(shí)現(xiàn)高效的計(jì)算和內(nèi)存優(yōu)化。
EdgeMoE
EdgeMoE是一種針對(duì)LLMs的設(shè)備端處理系統(tǒng),基于Mixture-of-Experts(MoE)結(jié)構(gòu)進(jìn)行內(nèi)存和計(jì)算管理。通過(guò)將模型劃分為不同部分并分配到不同存儲(chǔ)級(jí)別,EdgeMoE能夠在推理過(guò)程中實(shí)現(xiàn)高效的資源利用。
S3
S3系統(tǒng)通過(guò)預(yù)測(cè)輸出序列的長(zhǎng)度并根據(jù)預(yù)測(cè)結(jié)果規(guī)劃生成請(qǐng)求,以優(yōu)化設(shè)備資源的使用。同時(shí),S3能夠處理任何不正確的預(yù)測(cè),實(shí)現(xiàn)高效的推理過(guò)程。
PagedAttention
PagedAttention受到傳統(tǒng)虛擬內(nèi)存和分頁(yè)方法的啟發(fā),為L(zhǎng)LMs設(shè)計(jì)了一個(gè)允許在請(qǐng)求之間高效共享KV-Cache的系統(tǒng)。這種方法有助于降低內(nèi)存消耗并加速高吞吐量推理。
FlashAttention
FlashAttention通過(guò)融合矩陣乘法和softmax操作,以及采用張量核心自動(dòng)調(diào)整和調(diào)度策略,實(shí)現(xiàn)高效的注意力計(jì)算。FlashAttention-1和FlashAttention-2分別針對(duì)不同硬件平臺(tái)進(jìn)行了優(yōu)化,以實(shí)現(xiàn)更快速的推理過(guò)程。
高效結(jié)構(gòu)
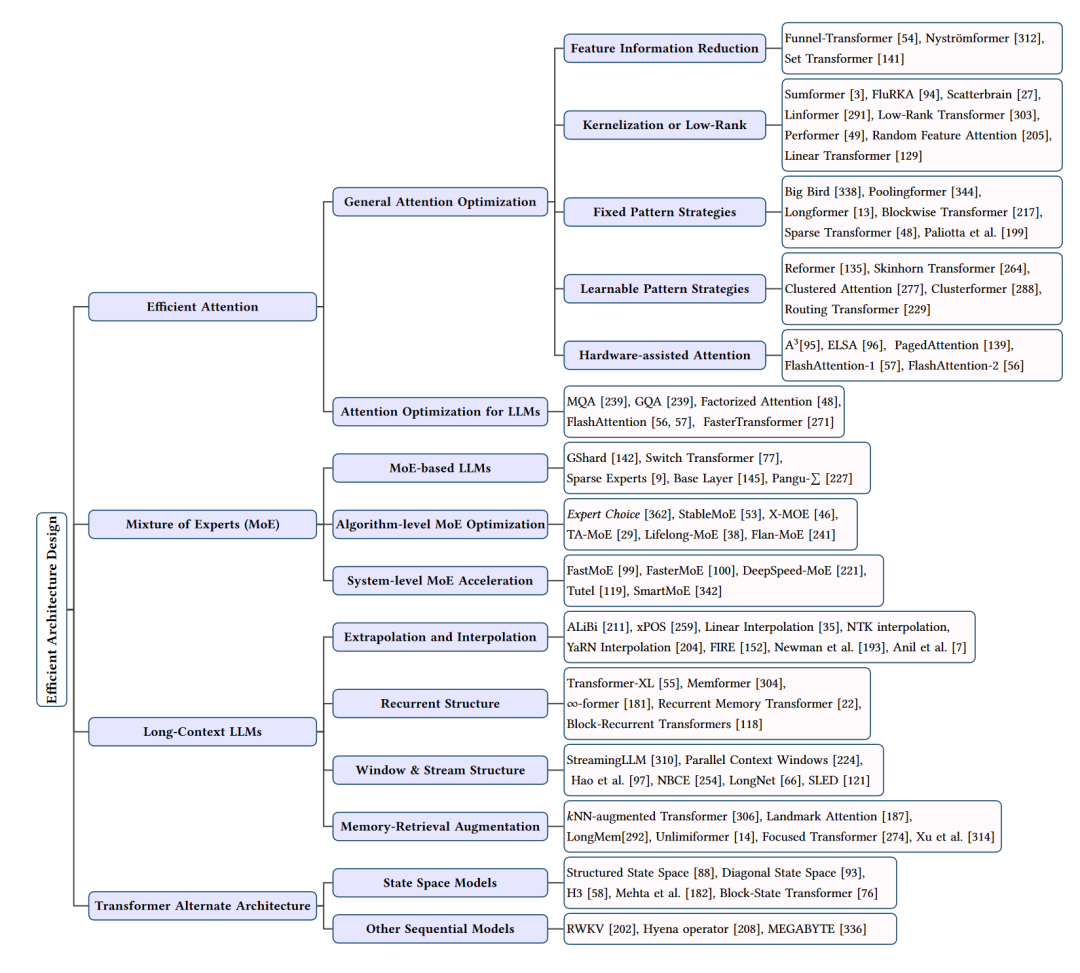
高效架構(gòu)設(shè)計(jì)總結(jié)
在大型語(yǔ)言模型(LLMs)的研究中,高效的結(jié)構(gòu)設(shè)計(jì)對(duì)于提高模型性能和降低計(jì)算成本具有重要意義。接下來(lái)將從四個(gè)方面介紹高效結(jié)構(gòu)設(shè)計(jì):注意力優(yōu)化、混合專家(Mixture of Experts, MoE)模型、長(zhǎng)上下文LLMs和Transformer替代結(jié)構(gòu)。
注意力優(yōu)化
注意力優(yōu)化主要關(guān)注于降低自注意力機(jī)制的計(jì)算復(fù)雜度。這些方法包括:
特征信息縮減:通過(guò)減少序列中的特征信息,如Funnel-Transformer、Nystr?mformer和Set Transformer等,降低計(jì)算需求。
核化或低秩:利用低秩表示或注意力核化技術(shù),如Sumformer、FluRKA、Scatterbrain等,提高計(jì)算效率。
固定模式策略:通過(guò)局部窗口或固定步長(zhǎng)塊模式,如Paliotta等人的方法、Big Bird、Poolingformer等,實(shí)現(xiàn)注意力矩陣的稀疏化。
可學(xué)習(xí)模式策略:通過(guò)學(xué)習(xí)序列的組織方式,如Reformer、Skinhorn Transformer、Clustered Attention等,實(shí)現(xiàn)更高效的注意力計(jì)算。
硬件輔助注意力:通過(guò)定制硬件實(shí)現(xiàn),如A3、ELSA、PagedAttention等,進(jìn)一步提高注意力計(jì)算的效率。
混合專家(Mixture of Experts, MoE)模型
MoE模型將任務(wù)劃分為多個(gè)子任務(wù),并為每個(gè)子任務(wù)訓(xùn)練一個(gè)專家模型。這些專家模型共同為輸入生成輸出。MoE模型可以有效地管理大量參數(shù),降低計(jì)算和內(nèi)存需求。典型的MoE模型包括GShard、Switch Transformer、Sparse Experts等。此外,還有一系列算法層面和系統(tǒng)層面的MoE優(yōu)化技術(shù),如Expert Choice、StableMoE、FastMoE等。
長(zhǎng)上下文LLMs
長(zhǎng)上下文LLMs關(guān)注于處理長(zhǎng)序列輸入。為解決這個(gè)問(wèn)題,研究者們提出了一系列方法,如:
外推和插值:通過(guò)優(yōu)化位置嵌入,實(shí)現(xiàn)對(duì)更長(zhǎng)序列的泛化,如ALiBi、xPOS等。
循環(huán)結(jié)構(gòu):通過(guò)引入記憶單元和循環(huán)機(jī)制,實(shí)現(xiàn)長(zhǎng)序列建模,如∞-former、Recurrent Memory Transformer等。
窗口和流結(jié)構(gòu):通過(guò)設(shè)計(jì)新的窗口機(jī)制和流式處理,降低固定窗口的限制,如StreamingLLM、Parallel Context Windows等。
記憶檢索增強(qiáng):利用最近鄰查找和內(nèi)存增強(qiáng)技術(shù),實(shí)現(xiàn)長(zhǎng)序列的高效處理,如NN-Augmented Transformer、Landmark Attention等。
Transformer替代結(jié)構(gòu)
除了優(yōu)化現(xiàn)有的Transformer結(jié)構(gòu),研究者們還提出了一些替代結(jié)構(gòu),如:
狀態(tài)空間模型:通過(guò)將注意力機(jī)制替換為狀態(tài)空間模型,實(shí)現(xiàn)近線性的計(jì)算復(fù)雜度,如Structured State Space(S4)、Diagonal State Space(DSS)等。
其他序列模型:結(jié)合循環(huán)神經(jīng)網(wǎng)絡(luò)和Transformer的優(yōu)點(diǎn),如RWKV、Hyena Operator等,實(shí)現(xiàn)高效的長(zhǎng)序列處理。
以數(shù)據(jù)為中心
數(shù)據(jù)選擇

數(shù)據(jù)選擇技巧的總結(jié)
在大型語(yǔ)言模型(LLMs)的研究和應(yīng)用中,數(shù)據(jù)選擇對(duì)于提高模型性能和效率具有重要意義。合適的數(shù)據(jù)選擇可以降低訓(xùn)練成本、提高泛化能力,并使模型更適應(yīng)特定任務(wù)。加下來(lái)將從兩個(gè)方面介紹數(shù)據(jù)選擇技巧:高效預(yù)訓(xùn)練數(shù)據(jù)選擇和高效微調(diào)數(shù)據(jù)選擇。
高效預(yù)訓(xùn)練數(shù)據(jù)選擇
預(yù)訓(xùn)練數(shù)據(jù)的選擇對(duì)LLMs的性能至關(guān)重要。高質(zhì)量的預(yù)訓(xùn)練數(shù)據(jù)可以幫助模型學(xué)習(xí)通用的知識(shí)表示,從而提高在各種任務(wù)上的表現(xiàn)。高效預(yù)訓(xùn)練數(shù)據(jù)選擇技巧包括:
數(shù)據(jù)清洗:通過(guò)去除無(wú)關(guān)、重復(fù)或低質(zhì)量的數(shù)據(jù),降低噪聲對(duì)模型學(xué)習(xí)的影響。
數(shù)據(jù)平衡:確保數(shù)據(jù)集中各類樣本的比例均衡,避免模型在某些類別上過(guò)擬合。
數(shù)據(jù)增強(qiáng):通過(guò)對(duì)原始數(shù)據(jù)進(jìn)行擴(kuò)充,如同義詞替換、句子重組等,增加模型的泛化能力。
領(lǐng)域自適應(yīng):選擇與目標(biāo)任務(wù)相關(guān)的數(shù)據(jù),使預(yù)訓(xùn)練模型更適應(yīng)特定領(lǐng)域的任務(wù)。
高效微調(diào)數(shù)據(jù)選擇
微調(diào)數(shù)據(jù)選擇關(guān)注于為特定任務(wù)選取合適的訓(xùn)練數(shù)據(jù)。高效的微調(diào)數(shù)據(jù)選擇可以降低微調(diào)成本,提高模型在目標(biāo)任務(wù)上的性能。高效微調(diào)數(shù)據(jù)選擇技巧包括:
任務(wù)相關(guān)性:選擇與目標(biāo)任務(wù)緊密相關(guān)的數(shù)據(jù),以便模型能快速學(xué)習(xí)任務(wù)特定的知識(shí)。
數(shù)據(jù)篩選:通過(guò)評(píng)估數(shù)據(jù)與目標(biāo)任務(wù)的相似性,篩選出最具代表性和價(jià)值的樣本。
在線學(xué)習(xí):利用在線學(xué)習(xí)策略,根據(jù)模型在驗(yàn)證集上的表現(xiàn)動(dòng)態(tài)調(diào)整微調(diào)數(shù)據(jù)。
少樣本學(xué)習(xí):通過(guò)元學(xué)習(xí)、遷移學(xué)習(xí)等技術(shù),利用少量標(biāo)注數(shù)據(jù)實(shí)現(xiàn)高效的微調(diào)。
其他數(shù)據(jù)選擇技巧
除了預(yù)訓(xùn)練和微調(diào)階段的數(shù)據(jù)選擇,還有一些其他技巧可以提高LLMs的效率:
示范選擇:通過(guò)選擇與目標(biāo)任務(wù)相似的示范數(shù)據(jù),引導(dǎo)模型更快地學(xué)習(xí)任務(wù)。
示范組織:合理組織示范數(shù)據(jù),使其更符合模型的學(xué)習(xí)規(guī)律,提高學(xué)習(xí)效果。
模板格式化:設(shè)計(jì)合適的輸入模板,以便模型能更好地理解任務(wù)需求。
提示工程
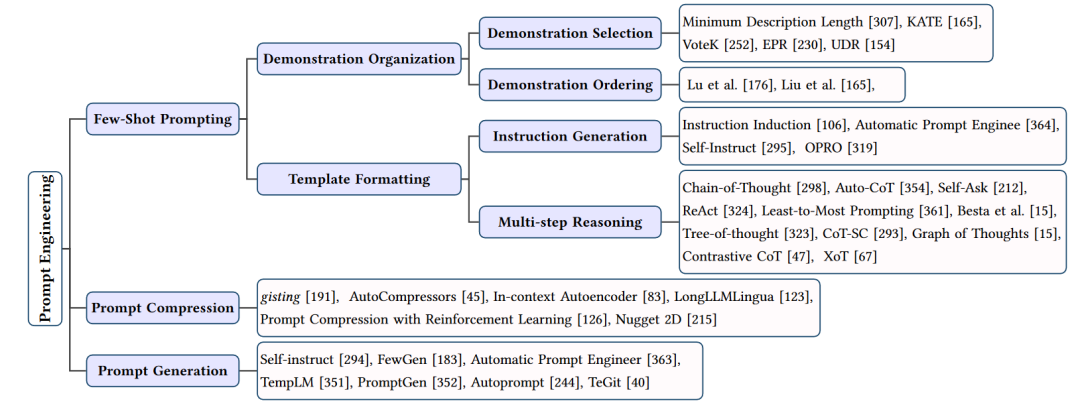
提示工程的總結(jié)
在大型語(yǔ)言模型(LLMs)的應(yīng)用中,提示工程(Prompt Engineering)是一種關(guān)鍵技術(shù),用于引導(dǎo)模型生成特定輸出或執(zhí)行特定任務(wù)。通過(guò)精心設(shè)計(jì)的提示,可以顯著提高LLMs的性能和適用性。本文將介紹提示工程的主要方法和技巧,包括少樣本提示、提示壓縮和提示生成。
少樣本提示
少樣本提示是一種使用有限的示例來(lái)引導(dǎo)LLMs執(zhí)行特定任務(wù)的方法。這些示例被稱為“示范”(Demonstrations)。少樣本提示技術(shù)主要包括:
示范選擇:從訓(xùn)練數(shù)據(jù)中挑選與目標(biāo)任務(wù)最相關(guān)的示例。這些示例應(yīng)該具有代表性,以便模型能夠從中學(xué)習(xí)到任務(wù)的關(guān)鍵特征。
示范組織:合理地組織示范,以便模型能夠更好地理解任務(wù)。這可能包括調(diào)整示范的順序、分組或格式化。
模板格式化:設(shè)計(jì)一個(gè)合適的輸入模板,以便模型能夠清楚地理解任務(wù)需求。模板應(yīng)該簡(jiǎn)潔明了,同時(shí)包含足夠的信息來(lái)引導(dǎo)模型生成正確輸出。
提示壓縮
提示壓縮旨在通過(guò)壓縮提示輸入來(lái)降低LLMs的計(jì)算和存儲(chǔ)需求。主要方法包括:
概要:將長(zhǎng)文本概要為較短的表示,如提取關(guān)鍵信息或使用句子級(jí)別的概要。
壓縮向量:將提示轉(zhuǎn)換為緊湊的向量表示,如使用BERT等模型生成的句子嵌入。
結(jié)構(gòu)化提示:設(shè)計(jì)結(jié)構(gòu)化的提示格式,以便模型能夠更高效地處理輸入。這可能包括使用特定的語(yǔ)法規(guī)則或標(biāo)記。
提示生成
提示生成旨在自動(dòng)創(chuàng)建有效提示,以引導(dǎo)LLMs執(zhí)行特定任務(wù),而無(wú)需人工標(biāo)注數(shù)據(jù)。主要方法包括:
自我指導(dǎo):讓LLMs根據(jù)自己的輸出生成提示,從而實(shí)現(xiàn)自我學(xué)習(xí)和優(yōu)化。
強(qiáng)化學(xué)習(xí):使用強(qiáng)化學(xué)習(xí)技術(shù)訓(xùn)練LLMs生成高質(zhì)量的提示。這通常涉及與環(huán)境(如用戶或其他LLMs)的交互,以便根據(jù)反饋優(yōu)化提示。
生成模型:利用生成模型(如GPT系列)為特定任務(wù)創(chuàng)建提示。這些模型可以根據(jù)輸入的上下文生成合適的提示。
提示工程通過(guò)少樣本提示、提示壓縮和提示生成等技術(shù),提高了LLMs的性能和適用性。這些方法使LLMs能夠在各種任務(wù)中更好地理解和執(zhí)行用戶需求,同時(shí)降低了計(jì)算和存儲(chǔ)成本。然而,提示工程仍然面臨一些挑戰(zhàn),如如何平衡提示的簡(jiǎn)潔性和有效性,以及如何處理多樣化和復(fù)雜的任務(wù)需求。未來(lái)的研究將繼續(xù)探索更高效、更實(shí)用的提示工程技術(shù)。
以框架為中心

在大型語(yǔ)言模型(LLMs)的研究和應(yīng)用中,以框架為中心的方法關(guān)注于構(gòu)建和優(yōu)化支持LLMs的軟件框架。這些框架旨在簡(jiǎn)化LLMs的開(kāi)發(fā)、訓(xùn)練和部署過(guò)程,提高計(jì)算資源的利用率,并支持各種高效算法和技術(shù)。接下來(lái)將介紹幾個(gè)主要的以框架為中心的LLM框架,以及它們的特點(diǎn)和優(yōu)勢(shì)。
DeepSpeed
DeepSpeed是由微軟開(kāi)發(fā)的一個(gè)集成框架,用于訓(xùn)練和部署LLMs。它提供了諸如數(shù)據(jù)并行、模型并行、流水線并行、提示批處理、量化和內(nèi)核優(yōu)化等功能。DeepSpeed Inference模塊是其關(guān)鍵組件之一,其中的ZeRO-Inference技術(shù)可以解決GPU內(nèi)存約束問(wèn)題。DeepSpeed還支持混合精度訓(xùn)練、梯度累積、動(dòng)態(tài)并行和分布式訓(xùn)練等技術(shù),以提高訓(xùn)練效率。
Megatron
Megatron是一個(gè)面向訓(xùn)練和部署LLMs的框架,由NVIDIA和微軟共同開(kāi)發(fā)。它支持?jǐn)?shù)據(jù)并行、模型并行、流水線并行等技術(shù),并提供了自動(dòng)混合精度、選擇性激活重計(jì)算等優(yōu)化方法。Megatron的核心技術(shù)是戰(zhàn)略性地分解模型張量操作,將它們分布式到多個(gè)GPU上,以提高處理速度和內(nèi)存利用率。Megatron還支持BERT、GPT和T5等模型。
Alpa
Alpa是一個(gè)用于訓(xùn)練和部署大型神經(jīng)網(wǎng)絡(luò)的庫(kù),它通過(guò)自動(dòng)并行化技術(shù)來(lái)解決LLMs的計(jì)算和內(nèi)存挑戰(zhàn)。Alpa支持?jǐn)?shù)據(jù)并行、模型并行、流水線并行等技術(shù),并提供了自動(dòng)調(diào)諧框架,以找到最佳的并行策略。Alpa還可以與流行的深度學(xué)習(xí)框架(如PyTorch和TensorFlow)無(wú)縫集成,簡(jiǎn)化LLMs的開(kāi)發(fā)和訓(xùn)練過(guò)程。
ColossalAI
ColossalAI是一個(gè)面向大規(guī)模并行訓(xùn)練的集成深度學(xué)習(xí)系統(tǒng),支持LLMs的訓(xùn)練和部署。它提供了數(shù)據(jù)并行、模型并行、流水線并行等技術(shù),并采用了一種模塊化設(shè)計(jì),以實(shí)現(xiàn)高效的算法和資源管理。ColossalAI還支持混合精度訓(xùn)練、梯度累積、動(dòng)態(tài)并行等優(yōu)化方法,以提高訓(xùn)練效率。此外,它還具有設(shè)備原生AI和用戶友好的工具,以降低AI模型開(kāi)發(fā)的門(mén)檻。
Hugging Face Transformers
Hugging Face Transformers是一個(gè)流行的開(kāi)源庫(kù),提供了大量預(yù)訓(xùn)練的LLMs,如GPT、BERT和T5等。它支持各種高效的推理技術(shù),如令牌級(jí)并行、流水線并行和模型并行。Hugging Face Transformers庫(kù)簡(jiǎn)化了LLMs的部署過(guò)程,使開(kāi)發(fā)者能夠輕松地將這些模型集成到各種應(yīng)用中。
以框架為中心的方法通過(guò)構(gòu)建和優(yōu)化支持LLMs的軟件框架,提高了LLMs的開(kāi)發(fā)、訓(xùn)練和部署效率。這些框架通常提供了一系列并行化技術(shù)、優(yōu)化方法和易用的工具,以滿足不同場(chǎng)景和任務(wù)的需求。隨著LLMs領(lǐng)域的不斷發(fā)展,我們可以期待更多創(chuàng)新的框架和技術(shù)來(lái)支持這些模型的廣泛應(yīng)用。
結(jié)語(yǔ)
本文綜述了大型語(yǔ)言模型(LLMs)的高效學(xué)習(xí)方法,主要包括模型壓縮、高效微調(diào)和推理、數(shù)據(jù)選擇、提示工程和框架優(yōu)化等方面。這些技術(shù)旨在降低LLMs的計(jì)算和存儲(chǔ)需求,提高訓(xùn)練和推理效率,同時(shí)保持或甚至提高模型性能。
模型壓縮部分涵蓋了量化、參數(shù)修剪、低秩逼近和知識(shí)蒸餾等方法,可以有效減小模型大小和計(jì)算復(fù)雜度。數(shù)據(jù)中心方法則關(guān)注數(shù)據(jù)選擇和提示工程,通過(guò)精選訓(xùn)練數(shù)據(jù)和設(shè)計(jì)有效的輸入提示,降低訓(xùn)練成本并提高模型泛化能力。提示工程通過(guò)設(shè)計(jì)合適的輸入提示,引導(dǎo)LLMs更專注于任務(wù)關(guān)鍵信息,從而提高推理效果。最后,框架優(yōu)化部分介紹了支持LLMs的軟件框架,如DeepSpeed、Megatron和Alpa等,它們提供了并行計(jì)算、內(nèi)存管理和優(yōu)化技術(shù),簡(jiǎn)化了LLMs的開(kāi)發(fā)和部署過(guò)程。
這些高效學(xué)習(xí)方法為L(zhǎng)LMs的研究和應(yīng)用提供了有力支持,使這些模型能夠在各種場(chǎng)景中發(fā)揮更大價(jià)值。然而,這些技術(shù)仍然面臨一些挑戰(zhàn),如如何在壓縮和加速過(guò)程中保持模型性能,以及如何適應(yīng)多樣化和復(fù)雜的任務(wù)需求。未來(lái)的研究將繼續(xù)探索更高效、更實(shí)用的技術(shù),以推動(dòng)LLMs領(lǐng)域的發(fā)展。
審核編輯:黃飛
?


























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論