") 英偉達力推SOCAMM內(nèi)存量產(chǎn):可插拔、帶寬比肩HBM
英偉達力推SOCAMM內(nèi)存量產(chǎn):可插拔、帶寬比肩HBM

電子發(fā)燒友網(wǎng)報道(文/梁浩斌)近日有消息稱,英偉達正在與三星、SK海力士等存儲巨頭合作,推動自家SOCAMM內(nèi)存標準的商業(yè)化落地。SOCAMM即Space-Optimized CAMM空間優(yōu)化內(nèi)存模組技術(shù),是由英偉達主導(dǎo)研發(fā)的面向AI計算、HPC、數(shù)據(jù)中心等領(lǐng)域的高密度內(nèi)存解決方案,旨在通過緊湊的設(shè)計實現(xiàn)最大化存儲容量,保持極佳的性能,并使用可拆卸的設(shè)計,便于用戶可以對內(nèi)存模塊靈活進行升級和更換。
在CES2025上,英偉達推出的緊湊型超算Project DIGITS,就有望將使用SOCAMM內(nèi)存實現(xiàn)小體積。
高密度內(nèi)存是AI算力的關(guān)鍵
在AI大模型的訓(xùn)練和推理中,內(nèi)存都起到十分關(guān)鍵的作用,在訓(xùn)練過程中,輸入的數(shù)據(jù)需要在計算芯片與內(nèi)存之間頻繁傳輸;同時今天的AI大模型參數(shù)規(guī)模已經(jīng)達到數(shù)百億甚至萬億級別,大量的參數(shù)帶來的是巨大的內(nèi)存需求,比如DeepSeek R1(671B版本)的全量模型文件大小達到720GB,需要512GB以上的DDR4內(nèi)存。
而在內(nèi)存需求不斷增加的當(dāng)下,在設(shè)備有限的體積以及有限的成本內(nèi),如何容納更高容量的內(nèi)存也成為一個難題。
另外根據(jù)一些測試,影響大模型本地部署處理速度的主要是內(nèi)存總帶寬,高帶寬內(nèi)存可以減少數(shù)據(jù)搬運時間,加快處理速度。帶寬決定了單位時間內(nèi)內(nèi)存與處理器之間的最大數(shù)據(jù)交換量。例如,訓(xùn)練千億參數(shù)模型時,帶寬不足會導(dǎo)致GPU利用率低于50%。
在AI場景中,通常需要 >1 TB/s的帶寬,所以近幾年HBM內(nèi)存隨著AI計算的需求而得到業(yè)界廣泛關(guān)注,但HBM高昂的價格,也讓其只應(yīng)用在一些價格昂貴的高端算力卡上。
內(nèi)存延遲過高也會導(dǎo)致處理器閑置,降低計算效率。例如,10ns的延遲差異可使推理吞吐量下降15%。一般來說,AI內(nèi)存的隨機訪問延遲需控制在 50ns以內(nèi),而性能較強的HBM3可以實現(xiàn)30ns的延遲。
在能效方面,AI服務(wù)器系統(tǒng)中,內(nèi)存的功耗往往占到整個系統(tǒng)總功耗的20%-40%,尤其是在GPU服務(wù)器中HBM的功耗可以高達300W。
前面也提到內(nèi)存的需求不斷增加,所以對于AI數(shù)據(jù)中心等應(yīng)用來說,能夠支持靈活的內(nèi)存擴展也是一個重要的考量。于是面向未來的AI應(yīng)用,新的內(nèi)存需要支持可拆卸的設(shè)計,方便用戶更換。英偉達在SOCAMM上自然也采用了可拆卸的設(shè)計。
SOCAMM:更低成本實現(xiàn)HBM性能
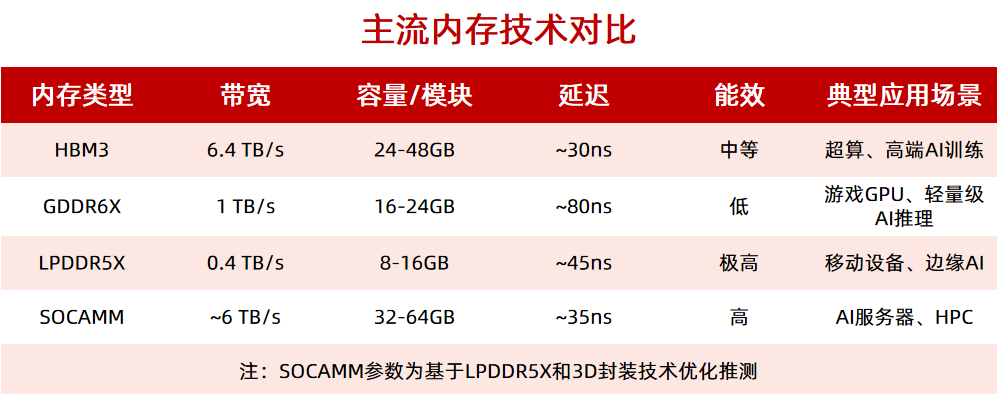
具體來說,SOCAMM首先是利用高I/O密度和先進封裝來實現(xiàn)極高的帶寬。根據(jù)現(xiàn)有信息,SOCAMM的 694個I/O端口,遠超傳統(tǒng)內(nèi)存模塊(如DDR5的64-128個),同時采用了3D封裝技術(shù)實現(xiàn)高密度互連,提供接近于HBM3的帶寬。SOCAMM顯著緩解處理器與內(nèi)存間的數(shù)據(jù)瓶頸問題,尤其適用于需要高吞吐量的AI計算場景。
SOCAMM接口目前基于LPDDR5X,理論帶寬可以達到6TB/s,已經(jīng)接近于HBM3的水平,但成本上要大大低于HBM3。同時基于LPDDR5本身具備的低功耗特性,集成高效的電壓調(diào)節(jié)單元,可以根據(jù)工作負載實時調(diào)整供電策略,盡可能降低能耗,因此SOCAMM的能效水平相比HBM3甚至是GDDR6X更高。
高速信號傳輸方面,SOCAMM據(jù)稱采用了高速差分對和優(yōu)化的布線布局,能夠在高密度環(huán)境下保持穩(wěn)定的信號。
在英偉達的設(shè)計中,SOCAMM的重要特性就是緊湊體積,模塊體積接近成人中指大小,可以推測其采用了chiplet設(shè)計和混合鍵合技術(shù),將DRAM裸片與邏輯控制器集成在單一封裝內(nèi)。
如果能夠?qū)OCAMM成功推廣,那么除了AI服務(wù)器等應(yīng)用外,SOCAMM小體積的特性,還將使其適用于AI PC、自動駕駛等場景上,未來應(yīng)用的前景將非常廣泛。
寫在最后
AI計算對內(nèi)存的要求可歸納為:高帶寬、大容量、低延遲、高能效。傳統(tǒng)DRAM技術(shù)已接近物理極限,而HBM、SOCAMM等新型內(nèi)存通過3D集成和接口優(yōu)化逐步成為AI硬件的核心。英偉達主導(dǎo)的SOCAMM脫離了當(dāng)前內(nèi)存接口主流的JEDEC規(guī)范,并希望借助AI的趨勢以及英偉達GPU的強勢地位,來推動自有內(nèi)存接口協(xié)議的應(yīng)用,打造獨立的接口生態(tài),未來SOCAMM的發(fā)展值得持續(xù)關(guān)注。
-
英偉達
+關(guān)注
關(guān)注
22文章
3939瀏覽量
93533
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論